[주석번역,해석]수백만 개의 자산을 위한 확장 도구
역자의 말.
대규모 데이터를 다루는 프로젝트를 수행 해 본 경험이 있다면 이러한 주제에 대해서 무척 관심이 있을 것이라고 생각되네요. 10년 전에 비해서 데이터의 크기는 2배 4배 8배 로 늘어났으며 다운로드 게임임에도 100기가를 훌쩍 넘어선지 이미 몇년이 지났습니다. 이러한 시대에 살면서 관심을 둬야하는 분야가 있는데요.
게임회사 내부의 데브옵스와 인프라스트럭처팀 등에 대한 것이 바로 그것입니다. 2011년 이후부터 2023년까지 주로 모바일 플레폼 게임들이 주류를 이루웠던 국내 상황을 보면 주변에 100기가가 넘는 콘텐트를 다루워 본 분들이 흔치 않다는 것을 알게 되었습니다.
저 또한 그럴 기회는 많지 않았지만 중국에서 근무 하면서 500억원을 들여서 개발한 PC 엠엠오 프로젝트(자체엔진)부터 300억원이 훌쩍 넘는 모바일 엠엠오 알피지등을 주로 개발했었지만 100 기가바이트가 넘어가는 프로젝트는 흔치 않았던 것으로 기억 됩니다.
간접적으로나마 호라이즌 제로 던 포비든 웨스트 사례를 복기 하면서 우리에게도 당면 할 수 있는 가능성이 농후한 향후 문제점들을 미리 살펴보고 그들이 어떤 개념으로 그것들을 극복 해 나갔는지 보면서 2024년에는 개발하고 있는 게임의 지속적이면서 빠른 반복 개발에 대한 깊은 개념을 회사에 도입할 수 있길 바랍니다.
한글 변환 된 PPT 다운로드
Google Slides 로드 중
Google Slides에서 "David Marcelis - Scaling Tools for Millions of Assets.pptx" 파일을 엽니다. 몇 분 정도 소요될 수 있습니다.
docs.google.com

수백만 개의 자산을 위한 확장 도구에 대한 강연에 오신 여러분을 환영합니다. 시작하기 전에 휴대폰을 무음으로 설정하는 것을 잊지 마세요.

간단한 시나리오부터 시작하겠습니다. 여러분이 아티스트라고 상상해 보세요(프로그래머가 대부분인 공간에서는 어려울 수 있습니다)... 하지만! 여러분은 환경 아티스트로서 콘셉트 아트를 살펴보며 아이디어를 찾고 있습니다.
이전 프로젝트의 모든 작업을 막 끝내고 다음 게임을 시작할 생각에 들떠 있습니다.
하지만 SSD에 하나의 프로젝트만 저장할 수 있다는 사실을 깨달았습니다.그래서 먼저 이전 프로젝트를 삭제합니다. 삭제가 끝나면 새 브랜치의 모든 에셋을 가져오기 위해 8시간 동안 동기화를 시작합니다.
다음 날, 레벨 에디터를 불러와 에셋 브라우저에서 "Oseram" 에셋을 검색합니다.
결과를 기다리는 동안 커피를 마시고, 소셜 미디어를 확인하고, 엄마에게 전화합니다.
커피를 마시고 레벨을 로드하고 에셋을 표시하면 드디어 작업할 준비가 된 것입니다.
그런데 프로듀서가 중요한 버그를 수정하기 위해 이전 프로젝트로 돌아가야 한다고 말하면서 다시 모든 과정을 거쳐야 합니다...
포비든 웨스트가 시작될 때 저희 툴이 처한 상황이 바로 이런 것이었습니다.

이제 1분 이내에 프로젝트를 전환하고, 추가 다운로드 없이 게임에 접속할 수 있으며, 모든 에셋을 실시간으로 사용할 수 있다면 어떨까요? 이 강연에서는 그 방법을 설명하겠습니다.

저에 대해 조금 소개합니다:제 이름은 데이비드 마르셀리스입니다.
지난 4.5년 동안 게릴라에서 툴 프로그래머로 일했습니다.
인프라 팀의 일원으로 호라이즌 포비든 웨스트의 소스 컨트롤, 빌드 시스템, 패키징 및 기타 툴 관련 작업을 담당했습니다.
호라이즌 제로 던의 PC 버전 출시도 지원했습니다.
Guerrilla는 처음에는 Killzone 시리즈로 유명했지만, 최근에는 Horizon 시리즈와 최신작인 Horizon Forbidden West로 유명해졌습니다.
이러한 게임을 개발하는 동안 수십 명으로 시작한 게릴라는 현재 400명이 넘는 직원을 거느리는 회사로 성장했습니다.
호라이즌 포비든 웨스트의 용량은 95GB로 이전 게임의 두 배에 달하며, PS5 패키지 용량 제한을 간신히 넘깁니다. 게임 세계가 더 커졌을 뿐만 아니라 인구 밀도가 더 높아졌습니다.
더 세밀해진 배경과 세트장, 더 많은 플레이 가능한 콘텐츠가 있습니다.
평균적으로 게임을 완료하는 데 약 90시간이 소요되며, 2시간이 넘는 시네마틱 영상과 풀 퍼포먼스 캡처로 가득 차 있습니다.
참고:총 오브젝트 수, 사람, 텍스처 데이터, 사운드 파일과 비교한 수치입니다.
17개의 메인 퀘스트.
28개의 사이드 퀘스트.
심부름 퀘스트 20개.
얼굴과 몸 전체가 캡처된 총 24시간 분량의 시네마틱이 포함되어 있습니다.
5개의 톨넥사냥터.
4개의 유적지.
5개의 반란군 캠프.
5개의 아레나 도전 과제’
근접 전투지역 4개.
건틀렛 레이스 4개.
17개의 구조 계약.
16개의 반란군 전초 기지.
8개의 유물 유적.
총 활동 수 = 72개수집품 49개로봇 43개(+텍스처 변형)180개 이상의 명명된 캐릭터22개의 정착지메인 스토리 30시간완주자 90시간평균 65시간
목록 비압축 압축 비율
Assets 25,643,132,008 14,632,590,157 57.06%
English 2,186,500,068 2,077,953,423 95.04%
French 2,116,104,832 1,910,756,788 90.30%
Spanish 2,186,503,576 1,950,640,009 89.21%
German 2,155,121,132 2,133,473,412 99.00%
Italian 2,135,385,216 2,047,454,217 95.88%
Portuguese 2,127,572,356 1,969,698,319 92.58%
Russian 2,170,766,680 2,163,029,152 99.64%
Polish 2,152,297,148 2,146,042,906 99.71%
Arabic 2,258,755,664 2,191,257,365 97.01%
TextureMIPS 65,036,578,940 41,349,272,473 63.58%
SoundWaveData 7,669,317,872 7,197,354,677 93.85%
VisualMeshData 20,337,421,608 9,989,094,878 49.12%
MovieResource 3,582,397,028 3,579,217,826 99.91%
AnimationData 384,696,200 273,535,296 71.10%
Various 534,247,684 74,644,761 13.97%
Total 142,676,798,012 95,686,015,659 67.06%
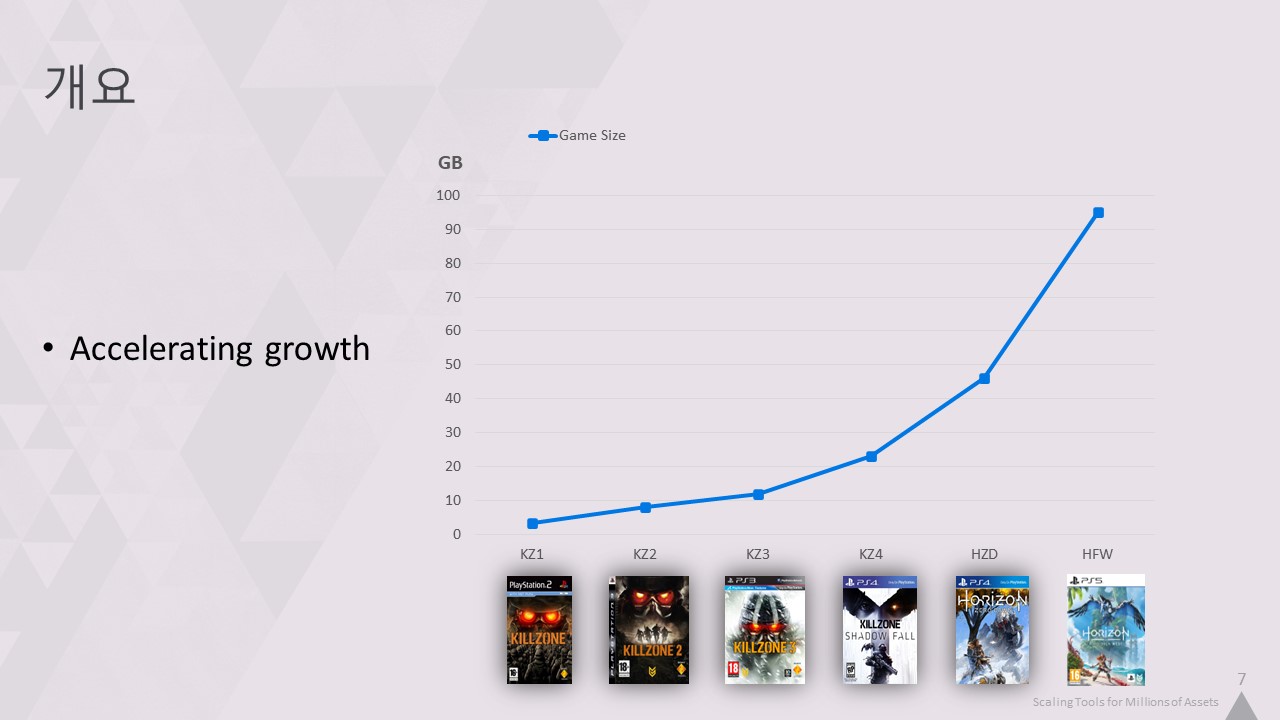
포비든 웨스트가 지금까지 가장 큰 게임이라는 사실은 플레이어와 개발자로서 눈여겨보셨을 트렌드의 최신 데이터 포인트일 뿐입니다.
게임이 점점 더 커지고 있다는 사실, 하지만 게임의 규모가 커지고 있을 뿐만 아니라 성장 속도도 빨라지고 있습니다.
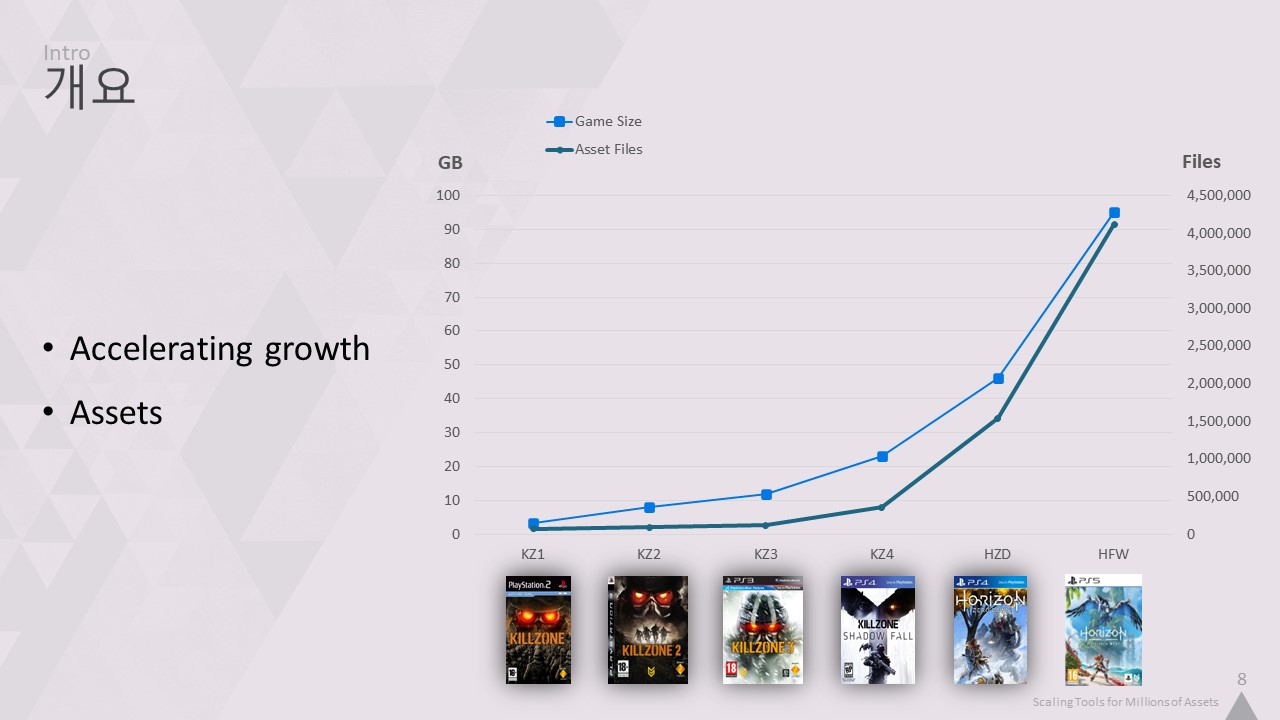
텍스처의 해상도만 높아지는 것이 아니라 관련된 에셋의 수도 증가하고 있습니다. 에셋이 점점 더 많이 추가되고 관련 파일이 많아지면 툴의 속도가 느려지고 프로젝트 작업도 번거로워집니다.
만약 모든 아티스트가 게임 내 모든 바위에 초고화질 이끼를 추가하지 않는다면 프로그래머로서의 삶이 훨씬 더 쉬워질 것입니다.
하지만 다행히도 그런 일은 일어나지 않았기 때문에 우리는 계속 기술을 발전시켜야 하고 멋진 GDC 강연을 할 수 있습니다.
이번 강연에서는 저희 툴링의 핵심 인프라를 개선하여 4백만 개의 에셋을 손쉽게 작업할 수 있도록 개선한 방법을 설명하겠습니다.

규모 증가로 인해 특히 어려움을 겪었던 두 가지 주요 시스템에 대해 다뤄보겠습니다:

먼저 이렇게 많은 에셋을 처리하는 방법부터 살펴보겠습니다. 사용자(여기서는 제작자)는 작업 중인 콘텐츠에 대한 정보를 알고 싶어 합니다.
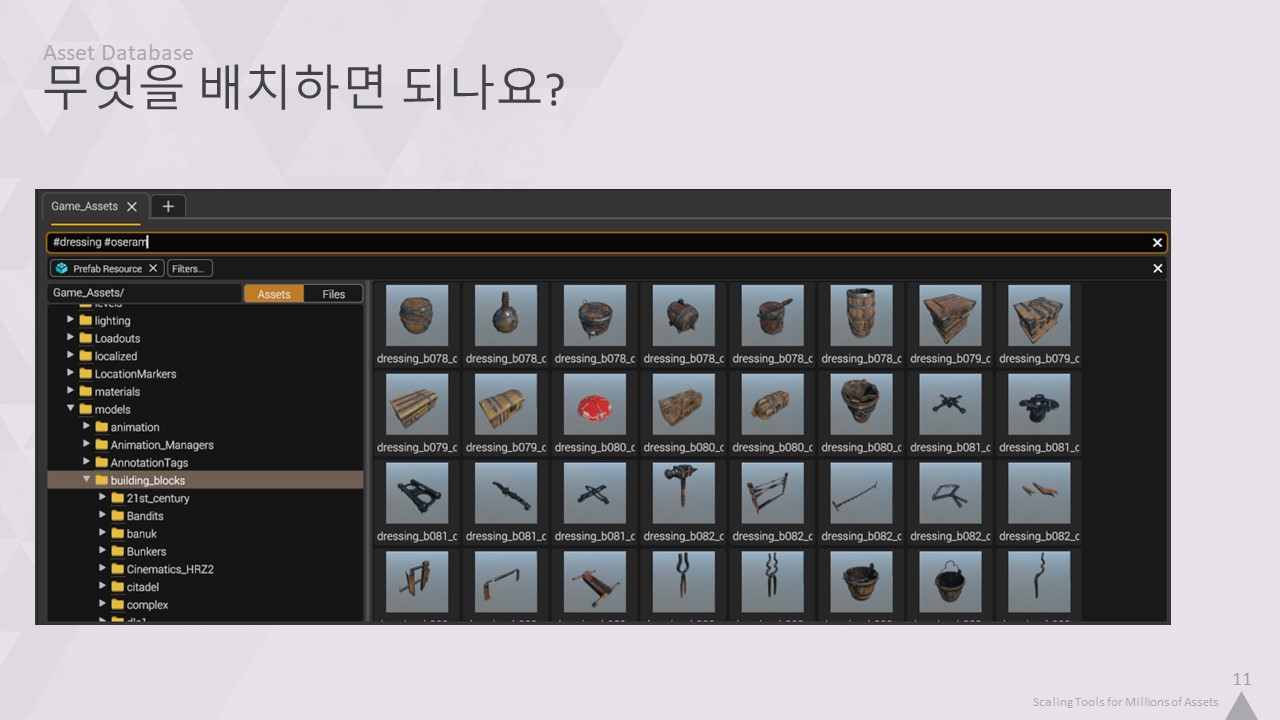
예를 들어 세트 드레싱이나 레벨 디자인을 할 때 현재 작업과 일치하는 필터를 기반으로 월드에 배치할 수 있는 모든 오브젝트를 보고 싶을 수 있습니다.
이 에셋 브라우저는 모든 레벨 에디터에서 매우 일반적이고 기본적인 기능입니다.
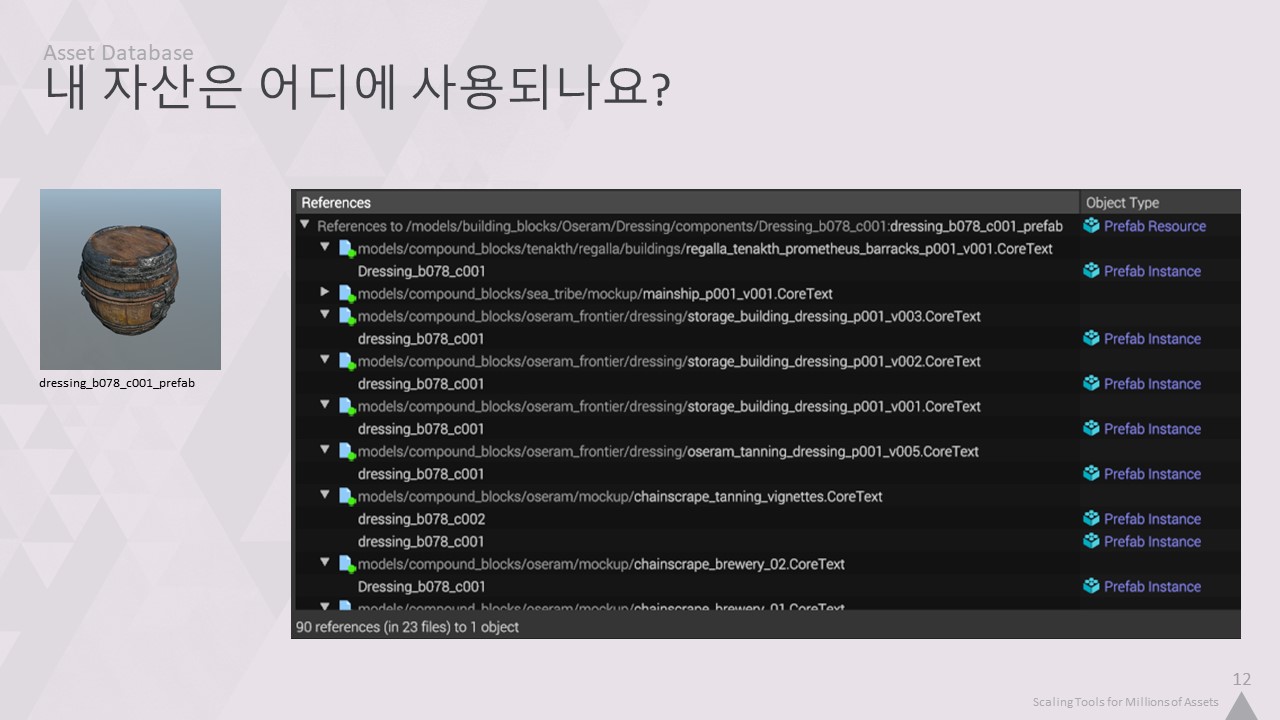
하지만 "이 에셋이 사용된 적이 있는가?" 또는 더 구체적으로 "이 에셋이 어디에 사용되는가?"를 알고 싶을 수도 있습니다.
참조 뷰어는 이 배럴과 같이 특정 에셋과 연결된 모든 장소의 전체 목록을 제공합니다.

다음은 모든 자산에 대한 지식이 있어야만 확실한 답변을 제공할 수 있는 쿼리의 두 가지 예입니다. 수백만 개의 파일을 매번 읽어내어 원하는 개체를 찾는 것은 불가능합니다.
최신 NVMe 드라이브는 선형 읽기에서 5GiB/s를 넘을 수 있지만, 작은 파일을 많이 처리하는 경우에는 OS 커널 오버헤드가 제한 요인이 되기 때문에 의외의 결과일 수 있습니다. Windows에서 NTFS를 사용한 테스트 사례에서 초당 25,000개의 파일을 열 수 있었는데, 이는 데이터를 읽지 않고 400만 개의 파일을 모두 여는 데만 2.5분이 걸린다는 의미입니다.
따라서 이를 위해 어떤 종류의 데이터베이스가 필요하다는 것은 분명합니다. 포비든 웨스트 개발 초기에는 이미 SQLite 데이터베이스를 기반으로 하는 이전 솔루션이 있었습니다. 이 솔루션은 에셋 브라우저에서만 사용되었는데, 에셋 브라우저는 충분히 잘 작동했지만 누락된 에셋이 나타나길 바라며 데이터베이스를 버리고 강제로 재구축하는 일이 빈번하게 발생할 정도로 성능이 떨어지고 안정적이지 못했습니다.
다음 게임에는 큰 야망이 있었습니다. 훨씬 더 큰 규모의 게임이 될 예정이었기 때문에 툴의 성능과 안정성이 매우 중요했습니다. 이 기술이 우리의 발목을 잡고 있었기 때문에 완전히 다시 작성하기 시작했습니다.

그래서 '자산 인덱서'를 만들었습니다. 이름에서 알 수 있듯이, 1억 개가 넘는 모든 개체에 대한 인덱스를 제공하고 파일을 열지 않고도 콘텐츠를 추론할 수 있는 로컬 데이터베이스입니다.
각 워크스테이션에서 실행되어 사용자 디스크의 파일을 스캔하고 해당 파일의 변경 사항을 모니터링하는 서비스입니다.
자산 인덱서는 맞춤형 사내 데이터베이스를 사용합니다. 이 강연을 들으면서 알게 되겠지만, 저희는 자체 기술을 만드는 것을 정말 좋아합니다. 따라서 완전히 사용자 정의된 솔루션을 만들면 프로그래머로서 조금 더 행복해집니다. 하지만 특정 데이터의 구조에 대한 지식을 활용하여 기성품보다 더 빠르고 간결하게 만들기 위한 여러 가지 트릭을 적용할 수도 있습니다.
이것은 모든 도구가 실행되는 핵심 데이터베이스가 되었습니다. 파일, 객체 또는 객체 간의 연결에 대해 알고자 하는 모든 도구는 이 데이터베이스에 요청합니다. 여기에는 에디터, DCC 패키지, 파이썬 스크립트, 심지어 게임 자체도 포함됩니다.
에셋인덱서의 세부 사항과 이를 통해 수행할 수 있는 작업을 이해하려면 먼저 콘텐츠가 어떻게 설정되는지에 대한 배경 지식이 필요합니다.
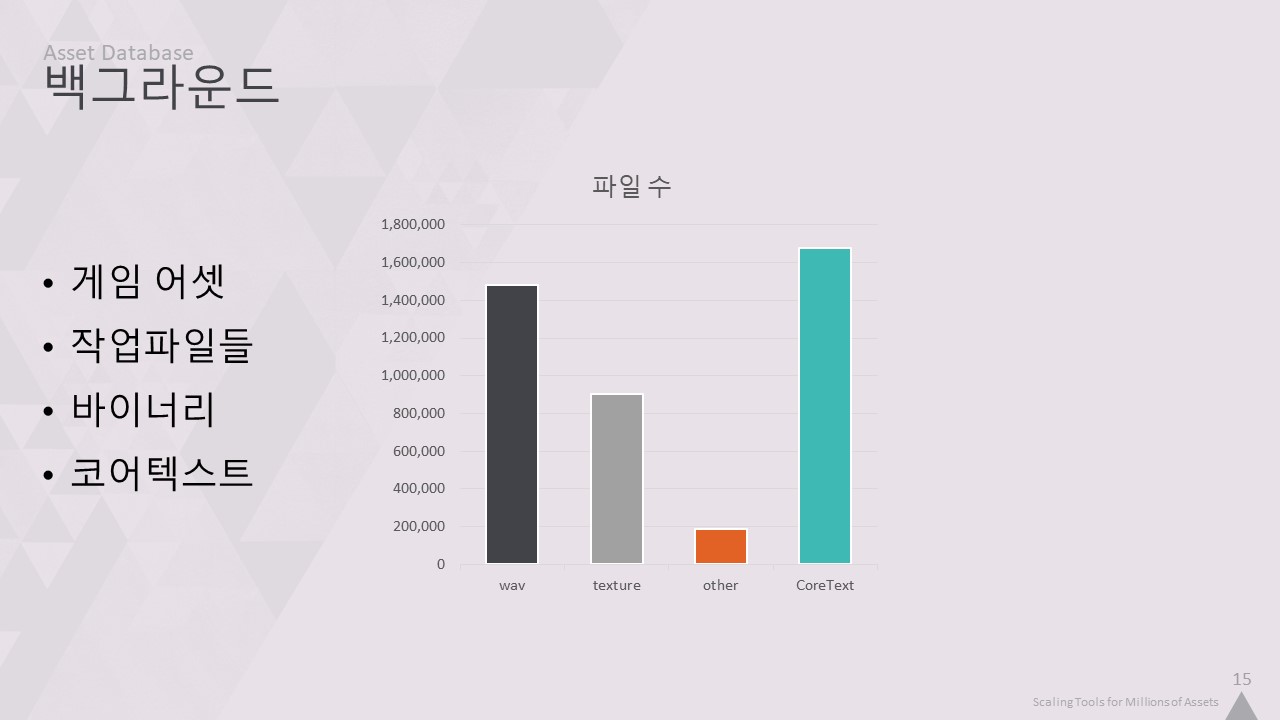
우리는 게임 작업이나 출시 가능한 빌드를 제작하는 데 필요한 모든 파일을 '게임 에셋'이라고 합니다. 앞서 언급한 400만 개의 에셋은 약 2TB의 데이터입니다.
Work_Files라고 부르는 또 다른 400만 개의 파일도 있습니다. 여기에는 모델을 위한 Maya 파일이나 텍스처를 위한 포토샵 파일과 같이 Game_Assets로 익스포트되는 원본 데이터가 포함되어 있습니다. 이 강연의 범위에서는 Game_Assets에 있는 모든 것에만 집중하겠습니다.
여기에는 오디오 wav 파일, dds 및 png 텍스처와 같은 바이너리 데이터와 bink 동영상과 같은 기타 느슨한 파일도 있습니다.하지만 게임의 실제 구조는 코어텍스트에 저장됩니다.
코어텍스트는 메시, 퀘스트 스크립트, 파티클 시스템 등 여러분이 생각할 수 있는 모든 에셋을 저장하는 JSON과 유사한 텍스트 형식입니다.

이를 설명하기 위해 콘텐츠의 예시를 살펴보겠습니다. 여기서는 게임에 미리 구워진 리플렉션 데이터를 제공하는 환경 프로브를 사용하겠지만, 그 세부적인 기능은 중요하지 않습니다.

여기에는 Probes.CoreText가 있습니다. 이 파일은 하나의 오브젝트인 환경 프로브가 포함된 CoreText 파일입니다.
모든 CoreText 파일에는 여러 개의 객체 블록이 포함되어 있습니다.
객체 블록은 타입명으로 시작합니다. 이는 런타임에 인스턴스를 생성할 수 있도록 노출된 C++ 코드의 클래스와 일치합니다.
그러면 모든 객체에는 UUID와 이름이 있어야 합니다.
다음은 캡처하는 조명 유형 및 트랜스폼과 같은 유형별 속성입니다. 보시다시피 모든 속성 값은 문자열로 저장됩니다. 트랜스폼, 부울, 열거형과 같은 각 유형에는 코드에 정의된 고유한 문자열 표현이 있습니다.
예외적으로 모든 유형이 공유하는 고정된 형식으로 저장되는 다른 객체에 대한 링크는 예외입니다. 이러한 링크는 다른 속성과 구별되는 꺾쇠 괄호를 사용하는 다른 구문을 사용합니다.
여기에는 베이크된 데이터가 포함된 세 개의 텍스처 객체에 대한 링크가 표시됩니다. 이러한 텍스처 객체는 자체 파일에 있습니다. 링크 중 하나를 따라가 보겠습니다.
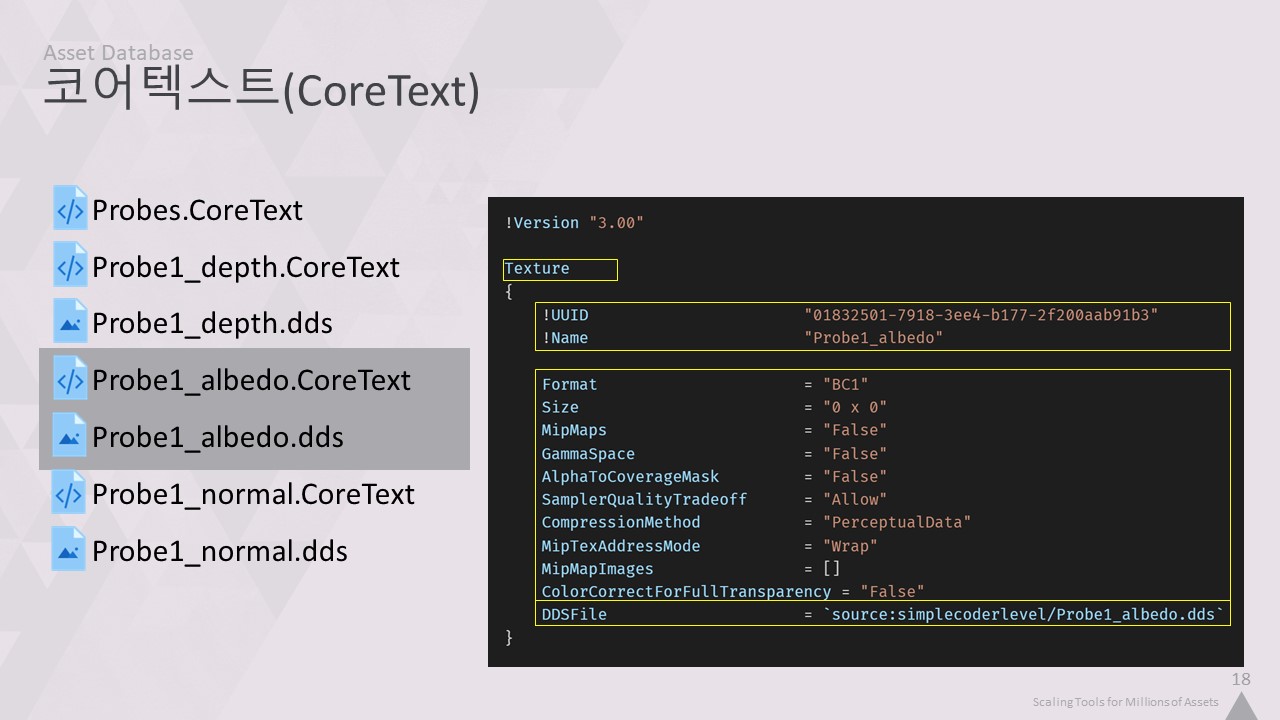
해당 링크를 따라 EnvironmentProbe_albedo.CoreText로 이동합니다,
다시 개체의 유형명이 표시됩니다,
UUID와 오브젝트 이름이 표시됩니다,
압축 형식 및 해상도와 같은 일부 텍스처 설정이 다시 문자열로 저장됩니다,
그리고 마지막으로 실제 데이터가 저장된 dds 파일에 대한 링크입니다. 이는 객체 링크와는 다른 링크 형식이지만, 다시 엄격하게 정의되어 있고 백틱으로 표시된 다른 구문을 사용합니다. 이를 통해 객체와 바이너리 파일 간의 관계를 추론할 수 있습니다.
물론 우리가 하루 종일 텍스트 파일을 편집하지는 않지만, 그건 10년 전 이야기입니다.

이를 위해 에디터가 있습니다. 이 보기는 CoreText 파일을 검사하기 위한 기본 보기입니다.
개체는 노드로 표시되고 개체 간의 링크는 선으로 표시됩니다. 이전에는 파일당 하나의 오브젝트만 표시되었지만, 환경 프로브를 사용하여 같은 파일에 있는 모든 텍스처를 그룹화하는 등 특정 콘텐츠에 적합한 방식으로 자유롭게 구성할 수 있습니다.
이제 모든 문자열 값이 유형에 따라 숫자나 드롭다운과 같은 특수 필드가 표시되는 속성 편집기에 표시됩니다.
텍스처 개체에 대한 링크가 데이터 미리 보기와 함께 표시됩니다.

요약하자면, 모든 CoreText 파일에는 여러 개의 객체가 들어 있습니다. 그리고 모든 객체에는 유형, UUID, 이름 및 일부 링크가 있으며, 이 모든 것이 색인됩니다.
또한 인덱싱 되지 않는 유형별 속성도 있습니다.
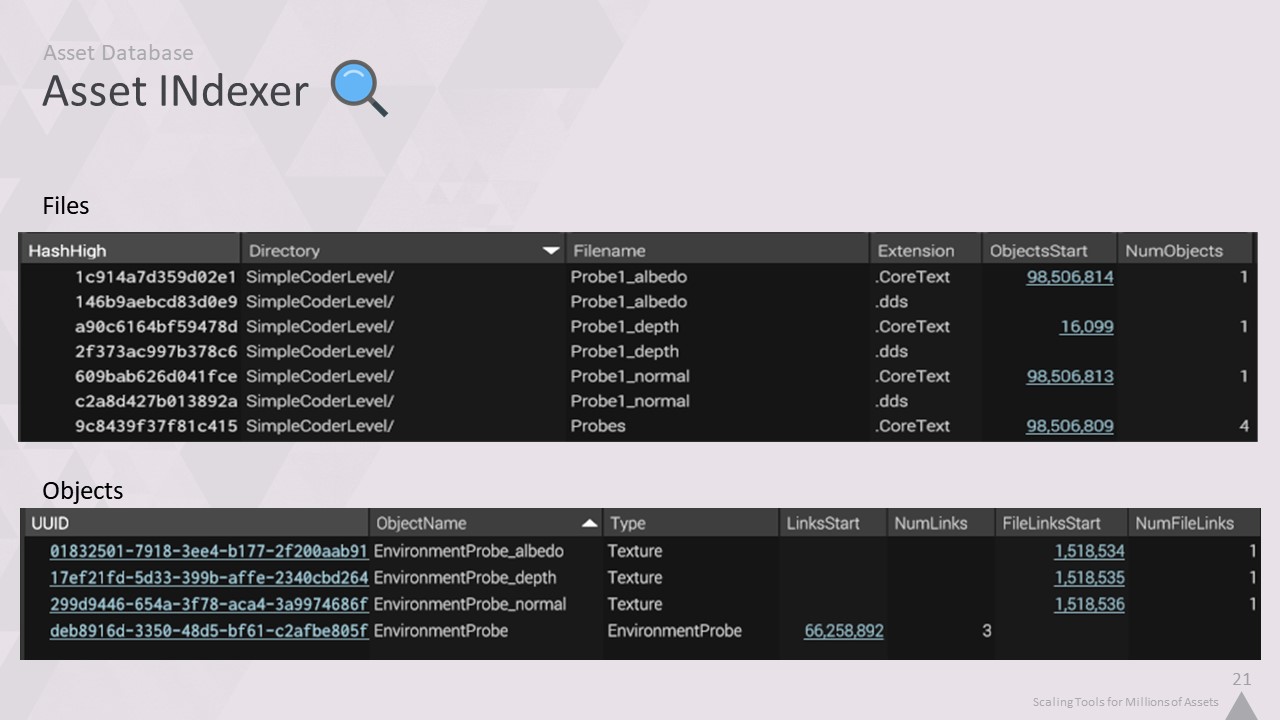
자산 인덱서로 다시 가져와서 모든 유형 간에 공통되는 데이터를 정확히 인덱싱합니다. 이 데이터를 파일 테이블과 오브젝트 테이블에 효율적으로 저장할 수 있습니다.
코어텍스트 형식은 엔진의 모든 유형에 유효하기 때문에 누군가 전체 라이트 리플렉션 또는 엔티티 시스템을 다시 작성해도 이 데이터베이스 형식에 여전히 맞습니다.
즉, 게임 전체의 모든 콘텐츠에 적용할 수 있는 놀랍도록 최적화된 툴과 데이터 구조를 만들 수 있습니다.

이제 400만 개의 파일, 1억 개의 개체, 2억 개의 링크가 모두 색인된 상태에서 어떤 종류의 쿼리에 대한 답을 얻을 수 있는지 살펴봅시다.

예를 들어 Game_Assets 폴더에 있는 모든 환경 프로브를 찾아보겠습니다. 2.8ms 안에 3721개의 환경 프로브를 모두 찾습니다.
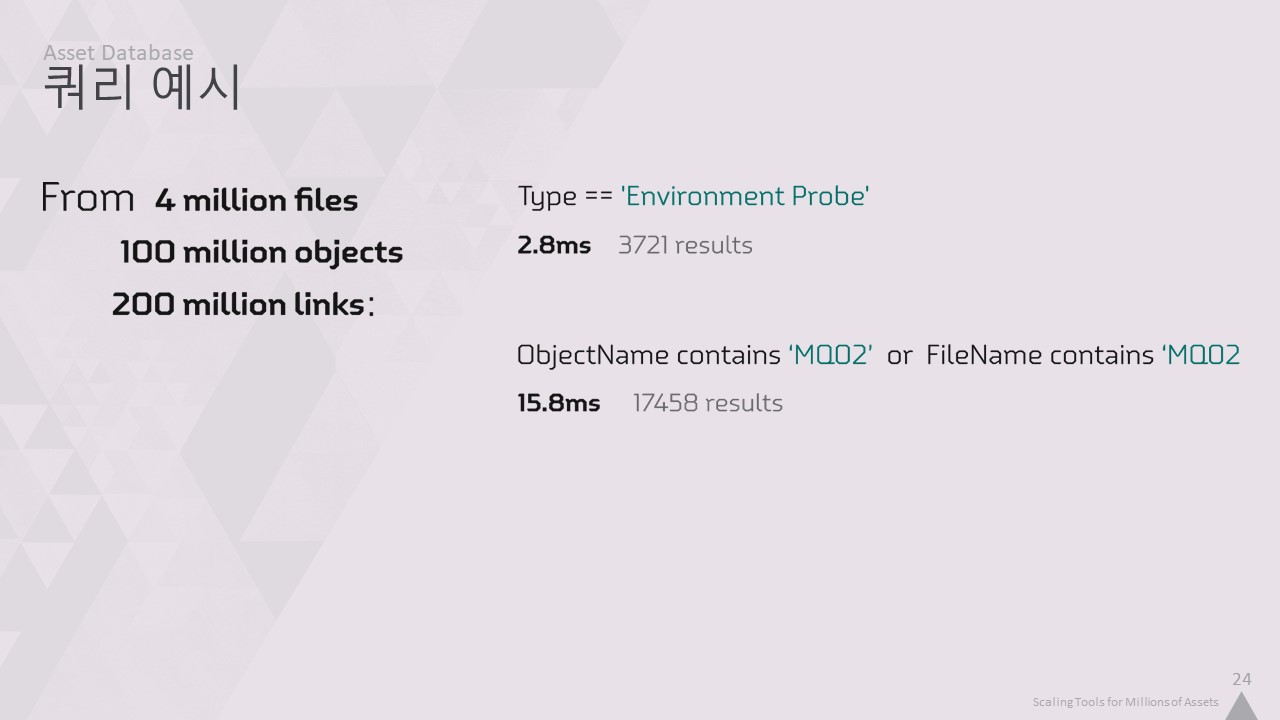
또는 개체와 파일 이름에 메인 퀘스트 2가 포함된 모든 개체를 찾아보겠습니다. 문자열을 비교하는 데 시간이 조금 더 걸리지만 16초 만에 17000개를 찾았습니다.
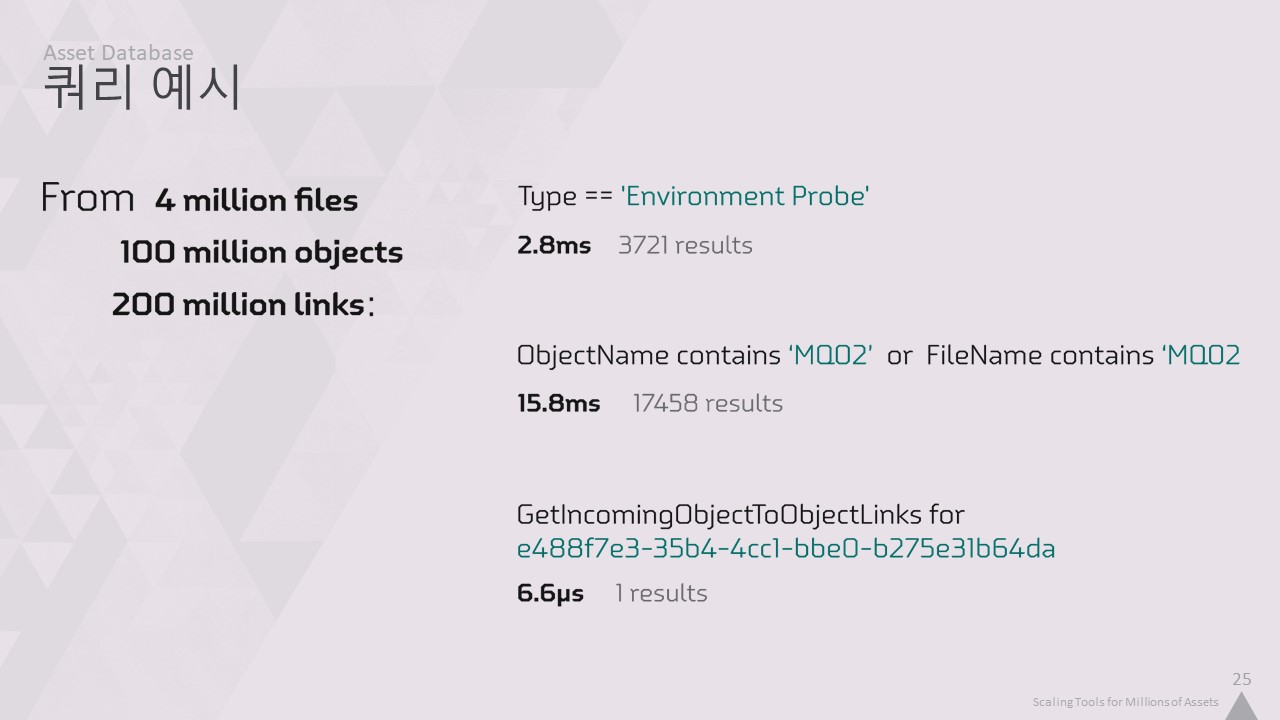
이러한 결과 중 하나에 대해 참조된 적이 있는지 알고 싶을 수도 있습니다.
이때 사용자 지정 데이터베이스가 큰 도움이 되는데, 가속도 테이블이 있어 6마이크로초마다 한 번씩 참조되었는지 여부를 확인할 수 있기 때문입니다.
이는 기존 시스템보다 훨씬 빠른 속도입니다.

"이름에 MQ02가 포함된 모든 개체 쿼리"와 같은 일반적인 작업은 각 파일을 여는 데 최소 2.5분이 걸립니다.
기존 SQLite 솔루션에서는 이 작업이 10초 정도 걸렸습니다.
하지만 자산 인덱서를 사용하면 이 시간이 16ms로 단축됩니다.
이는 사람들이 에셋 브라우저에서 매일 사용하는 실제 사례입니다.
이는 커피를 마시기 위해 걸어가는 사람과 실시간 인터랙션의 차이입니다.
속도가 훨씬 빨라졌을 뿐만 아니라 2TB의 입력 데이터를 위한 데이터베이스의 크기가 25GB에서 5GB로 줄어들었습니다.
이는 이제 메모리에 보관할 수 있다는 것을 의미하며, 이러한 고성능을 달성하는 데 도움이 되는 요소 중 하나입니다.

자산 인덱서에서 수행한 몇 가지 흥미로운 작업을 살펴보겠습니다.
작은 크기를 구현하기 위해 경로 컴포넌트를 여러 문자열 풀로 분할하고 데이터를 비트 패킹 했습니다.
이를 설명하기 위해 예제를 살펴보겠습니다.
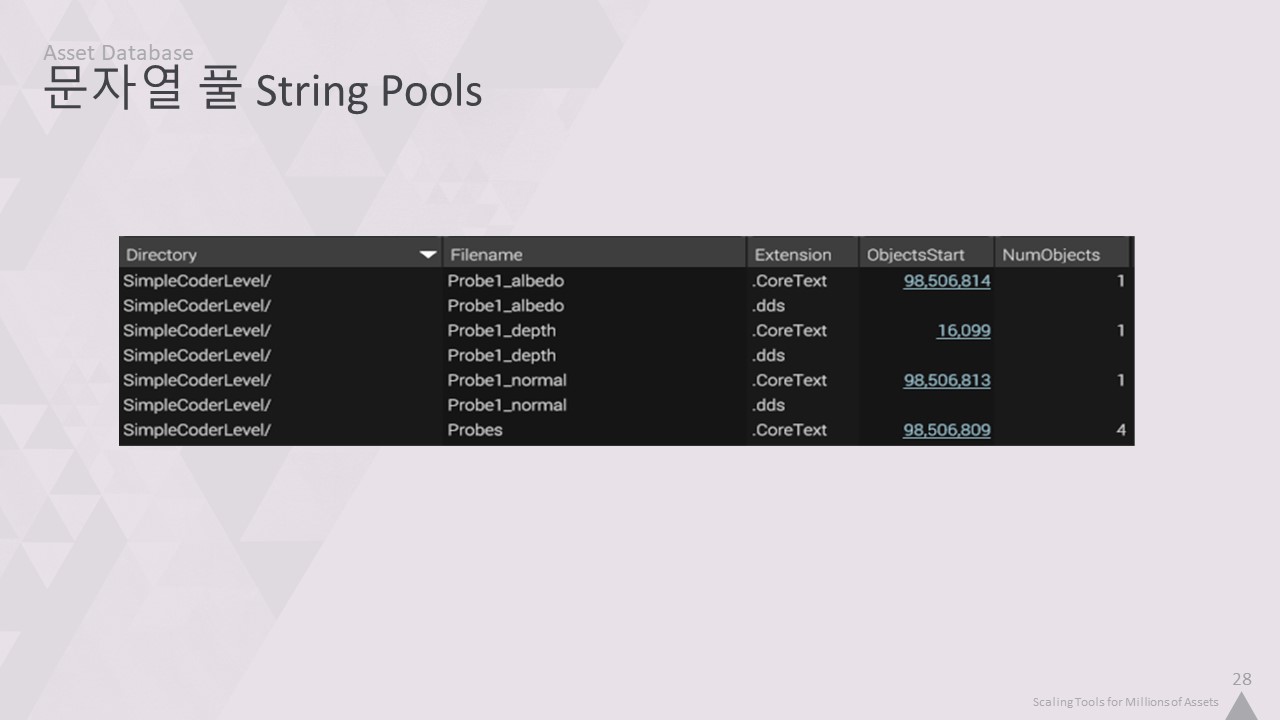
여기에는 앞서의 파일이 있습니다.
보시다시피 이 파일들은 모두 같은 디렉터리를 공유하며, 확장자는 2개 뿐입니다.

따라서 이렇게 중복 제거하여 문자열 풀에 넣으면 메모리를 절약할 수 있습니다.
각 풀에는 고유한 문자열이 포함됩니다.

그리고 각 셀에는 이러한 풀 중 하나에 대한 인덱스만 포함됩니다.
이 예제에서는 총 문자 수를 271개에서 81개로 줄였습니다.
70%가 절약됩니다!

하지만 이러한 인덱스도 저장해야 하기 때문에 완전히 공평하지는 않습니다.
모든 유형의 대용량 데이터를 처리하기 위해 데이터베이스는 64비트 정수를 사용하지만, 이제 인덱스에 168바이트를 사용하게 됩니다.
거의 모든 절감 효과가 다시 사라집니다!
그래서 비트 패킹이 필요한 것입니다.

한 열에 있는 여러 셀을 함께 그룹화하면 최적의 패킹을 결정할 수 있습니다.
이 예에서는 모든 파일이 같은 디렉터리에 있습니다,
따라서 모든 셀의 디렉터리를 인덱싱하기 위해 단일 비트를 저장하기만 하면 됩니다.
파일 이름은 더 많은 변수가 있으므로 모든 셀에 파일 이름을 인덱싱하기 위해 2비트가 필요합니다.
확장자의 경우 셀당 1비트만 필요합니다.
즉, 모든 인덱스를 저장하는 데 총 3바이트만 필요합니다!
이 패킹을 결정하는 실제 알고리즘은 훨씬 더 복잡합니다.
셀 페이지에 데이터를 저장하는데, 페이지마다 조회 테이블과 특정 범위 내의 오프셋이 있을 수 있지만 기본 원리는 동일하게 유지됩니다.

그리고 이것은 실제 세계를 상당히 대표하며, 확장은 실제로 셀당 2비트로만 줄어듭니다!
이 수치는 데이터의 변화에 따라 크게 달라진다는 점에 주목할 필요가 있습니다.
데이터베이스를 잘 압축할 수 있도록 배치했지만 일부 데이터는 전혀 압축되지 않습니다.
64비트 해시는 중복된 파일이 많거나 해시에 문제가 있는 경우가 아니라면 더 작은 크기로 압축되지 않습니다.
디렉토리 셀당 7.49비트 셀당 11바이트 문자열(88비트)
파일명 셀당 15.31비트 셀당 18바이트 문자열(144비트)
셀당 확장 2.05비트 셀당 문자열 0.017바이트(0.136비트)
셀당 오브젝트 시작 9.70비트
셀당 객체 수 3.48비트
.CoreText를 4백만 번 저장하면 36MiB가 되지만, 지금은 1MiB가 됩니다.디렉토리 ~420MiB 대 50MiB

따라서 문자열 풀과 비트 패킹은 데이터베이스를 매우 컴팩트하게 만드는 데 큰 역할을 합니다.
우리가 한 다른 일들을 간략히 살펴봅니다:

안정성과 관련하여 한 가지 중요한 점은 에셋을 로드하는 엔진의 모든 코드가 콘텐츠의 링크를 통해 로드되도록 해야 한다는 것입니다. 이를 설명하기 위해 이 가상의 예시를 살펴보겠습니다.
다음은 퀘스트 이름과 설명이 포함된 Quest_01.CoreText 파일과 스크립트 로직이 포함된 Quest_01_Script.CoreText 파일 두 개입니다.
이전에는 코드가 경로를 가져왔습니다,
특수 문자열을 추가한 다음
해당 에셋을 로드합니다.
이 두 파일 간의 종속성은 파일 자체에 표현되지 않고 퀘스트 코드의 깊은 곳에만 표현됩니다.
외부 코드에서 이 오브젝트가 마술처럼 나타나기 때문에 우리는 이를 농담으로 '문자열 마법'이라고 부릅니다.
따라서 우리가 만드는 모든 도구는 이와 같은 모든 예외에 대해 알고 있어야 합니다.
최신 코드에서는 퀘스트 객체에 해당 스크립트를 가리키는 링크 속성을 만듭니다.
이제 코드에서 해당 링크를 로드할 수 있으며, 모든 일반 도구에서 이 두 파일이 서로 연관되어 있음을 알 수 있습니다.
개별 사례를 모두 수정하는 대규모 프로젝트였지만, 전체 엔진과 툴을 이 개념에 기반할 수 있다는 점에서 매우 중요한 작업이었습니다.

이제 안정적이고 성능이 뛰어난 에셋 데이터베이스를 통해 편리하게 사용할 수 있는 에셋 브라우저와 레퍼런스 뷰어를 만들 수 있게 되었습니다.
그렇다면 또 어떤 멋진 기능이 있을까요?

여러분 모두에게 익숙한 시나리오 중 하나는 누군가 파일을 제출하는 것을 잊어버려 빌드가 깨지는 경우입니다. 저희에게는 이것이 가장 흔한 빌드 중단 중 하나였습니다. 예를 들어 누군가 새 파일에 링크를 추가하는 경우입니다,
새 파일은 제출하지 않고 링크만 제출한 경우를 예로 들 수 있습니다. 이전 시스템에서는 이런 경우의 유효성을 검사하는 데 몇 분이 걸릴 수 있고 100% 신뢰할 수 없었습니다. 따라서 이 기능은 선택 사항이었으며 매우 신중한 사용자만 사용했습니다.
자산 인덱서에서 이 모든 데이터를 사용할 수 있으므로 1초 이내에 이러한 경우를 확인할 수 있으며 결과에 대한 확신을 가질 수 있습니다.
이 덕분에 이제 유효성 검사를 강화하고 문제가 발견되면 사용자의 제출을 차단할 수도 있습니다. 이로써 이러한 유형의 빌드 실패가 거의 사라졌습니다. 이제 빌드를 망쳤다고 불평하는 화난 빌드 마스터의 연락을 받지 않게 되어 제출자를 포함한 모든 사람이 매우 기뻐하고 있습니다.
유효성 검사에 조금 지나친 부분이 있었다는 점은 인정해야겠습니다. 이제 제출하는 파일의 Diff를 수행하고 빌더의 에셋 인덱서와 통신하여 헤드 리비전 시 오브젝트가 삭제되었는지 여부를 확인합니다. 하지만 저희는 이 기능이 가능하다는 것을 알았기 때문에 실행에 옮겼습니다. 그리고 그 덕분에 모두의 삶이 정말 좋아졌습니다.

여기서 한 걸음 더 나아가 두 개의 개별 오브젝트 간의 관계뿐만 아니라 전체 게임 콘텐츠에 대해 추론할 수 있습니다.
오브젝트가 어떤 레벨에 연결되어 있는지, 어떤 방식으로 연결되어 있는지 파악할 수 있습니다.
앞의 예시를 계속 이어서, 여기에는 신뢰할 수 있는 환경 프로브와 그 텍스처가 있습니다.
타일에 연결하여 플레이어 주변에 있는 콘텐츠만 로드할 수 있습니다.
그런 다음 이 타일을 레벨에 연결합니다.
레벨에 도달할 때까지 오브젝트의 링크를 따라가면 게임에서 오브젝트가 로드되는 방식에 대한 계층 구조를 만들 수 있습니다. 이를 통해 콘텐츠에 대한 신속한 정적 분석과 유효성 검사를 수행하여 "모든 타일에 환경 프로브가 있는가" 또는 "어떤 타일에 특정 오브젝트가 포함되어 있는가"와 같은 질문에 답할 수 있습니다. 이 모든 것은 코어텍스트 파일을 열지 않고도 AssetIndexer의 데이터베이스만으로 분석할 수 있습니다.
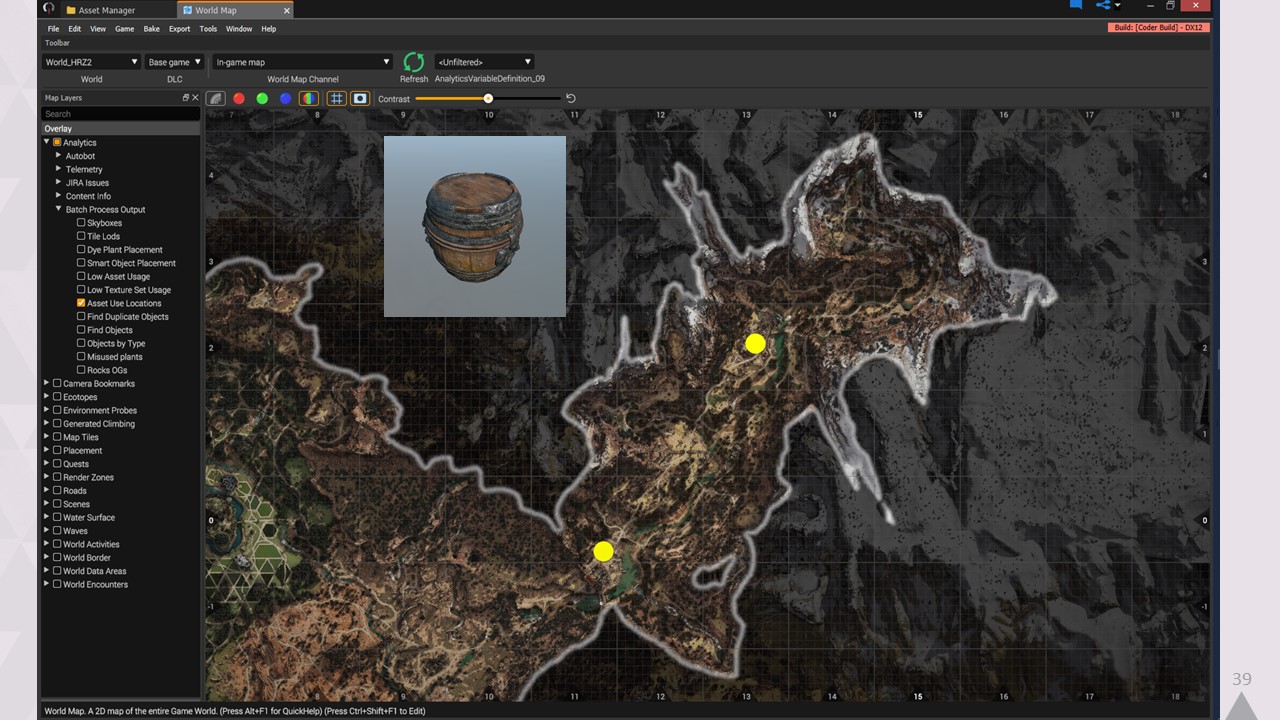
그런 다음 세계 지도를 가져와 각 환경 프로브의 링크 체인을 따라가서
지도에 표시할 수 있습니다.
이를 통해 조명 팀은 특정 영역이 충분히 커버되는지 빠르게 확인할 수 있습니다.여기서 더 나아가 더 복잡한 로직을 실행할 수 있습니다.
예를 들어 특정 영역에 한 번만 배치되는 고가의 메시를 찾을 수 있습니다.
이를 맵에 표시하면 데이터가 다른 인스턴스와 공유되지 않기 때문에 메모리 비용이 많이 드는 단일 오브젝트를 찾을 수 있습니다.
또는 아까의 배럴을 플로팅할 수도 있습니다!
이 예제에서는 이 영역에 인스턴스가 2개밖에 없는 오브젝트를 선택했으므로 콘텐츠 최적화를 위해 테크 아트에 참여해야 할 것 같습니다...

요약하자면, 저희는 이 기술에 매우 만족하고 있습니다. 많은 워크플로우의 속도가 빨라졌고 이전에는 안정성이나 성능 문제로 인해 불가능했던 작업을 수행할 수 있게 되었습니다.이 기술은 매우 성공적이어서 모든 개발 도구의 핵심이 되었습니다.
오브젝트나 링크가 에셋-인덱서에 알려지지 않은 경우 게임에 반영되지 않습니다.

이제 다음 섹션으로 넘어가겠습니다. 지금까지 에셋에 대한 추론에 대해 이야기했습니다. 하지만 개발의 또 다른 큰 부분은 콘텐츠를 게임에 로드하는 것입니다.
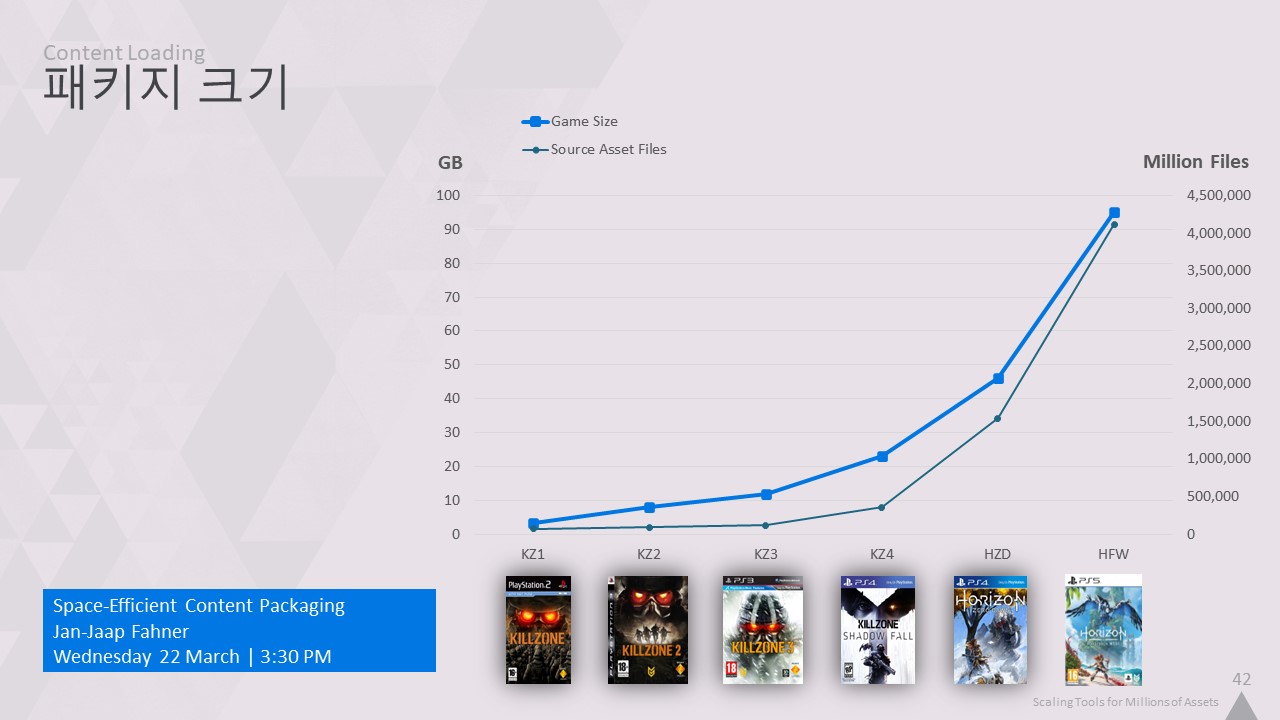
그리고 여기에 기하급수적으로 증가하는 또 다른 숫자가 있습니다: 바로 패키지 크기입니다.
앞서 말씀드렸듯이 PS5 blu-ray에 넣기에는 너무 큰 크기입니다.
패키징에 대한 완전히 새로운 접근 방식에 대한 Jan-Jaap의 강연을 오늘 오후에 확인해 보시길 적극 추천합니다.
하지만 이 강연은 툴에 관한 이야기입니다.
95GB는 소비자용 패키지이며, 개발용 패키지는 디버그 데이터까지 포함하기 때문에 더 큰 용량입니다.
개발 중에 콘텐츠가 로드되는 방식을 완전히 재설계하여 이제 20초 만에 빌드를 시작할 수 있는 방법에 대해 설명할 예정입니다.
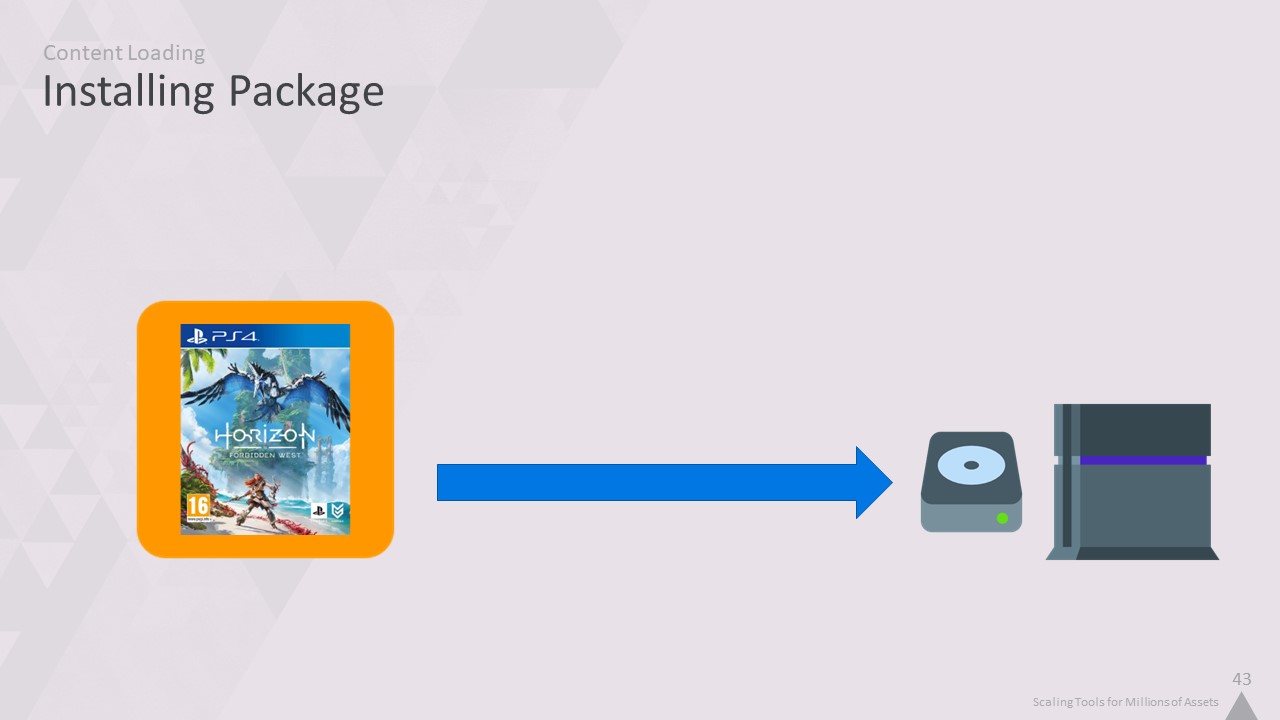
하지만 호라이즌 제로 던 이전부터 시작해서 이 시스템의 역사를 살펴봅시다.
100GB가 넘는 패키지를 설치하는 것은 반복 작업에 절대적으로 끔찍한 일입니다.
저희의 경우 생성하는 데 1시간 정도 걸리고 설치하는 데 30분이 더 걸렸습니다.
데브킷에서 변경 사항을 테스트하기 위해 1시간 반을 기다리는 것은 좋지 않습니다.
그래서 저희는 다른 방식으로 접근했습니다.

개발 중에는 설치된 패키지에서 게임을 로드하지 않고 개별 콘텐츠를 로드했습니다. 반복 작업은 점점 더 세분화할수록 속도가 빨라집니다. 저희는 코어 텍스트 파일 단위로 반복했습니다.
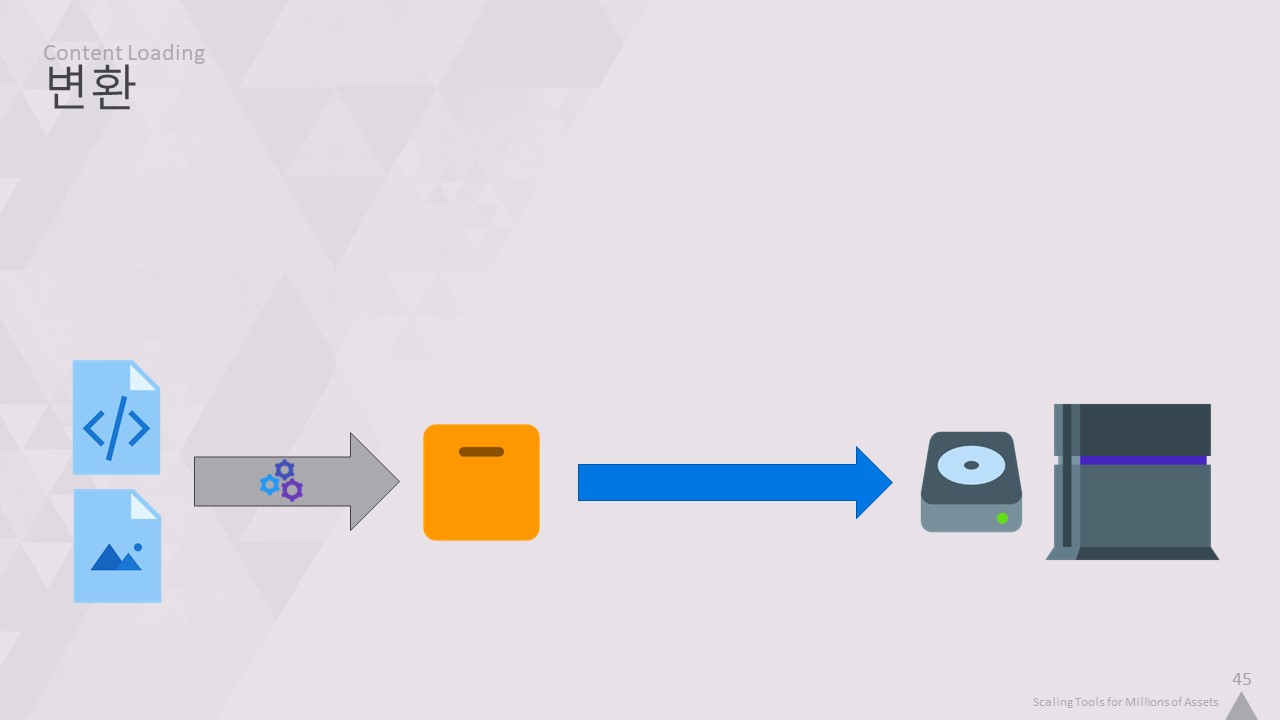
텍스처 압축 설정을 변경하면 해당 코어 텍스트 파일만 다시 처리됩니다.
짐작할 수 있듯이 JSON과 같은 텍스트와 PNG 파일은 런타임 게임에 최적화되어 있지 않기 때문에 그 사이에 소스 데이터를 게임에서 읽을 수 있는 바이너리 형식으로 변환하는 프로세스가 있습니다.
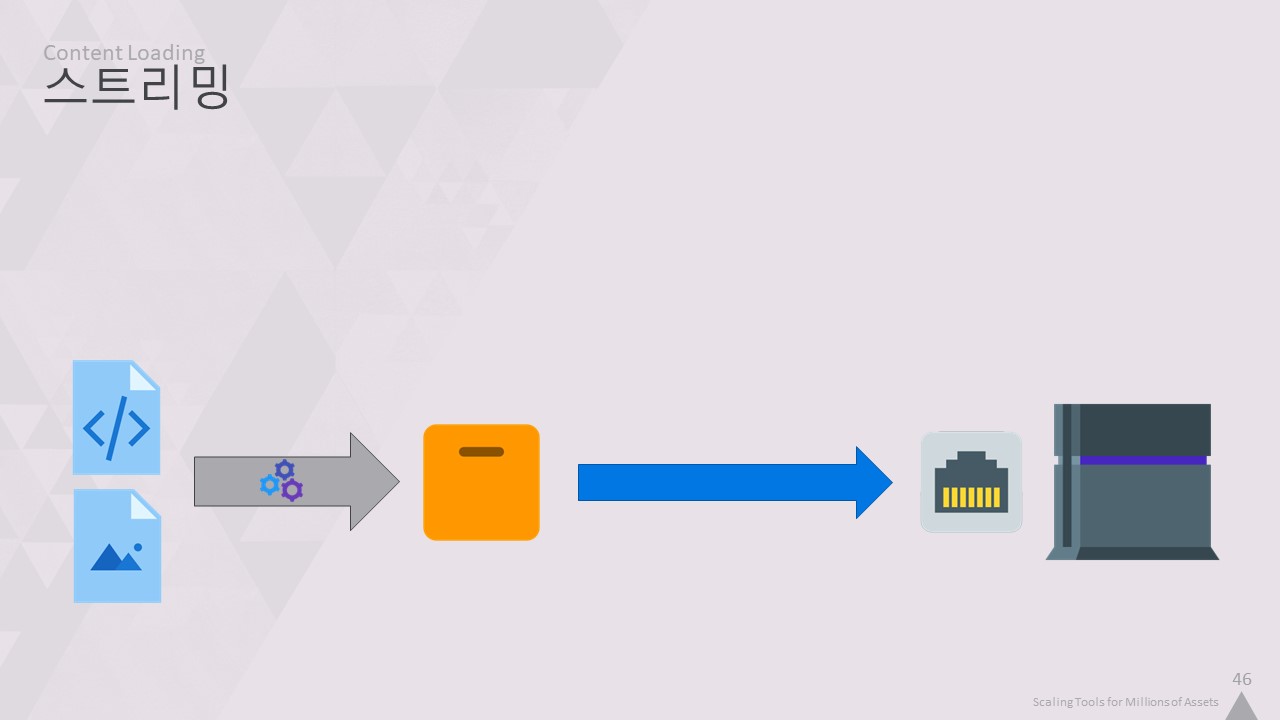
PS4 데브킷에는 구식 회전식 디스크가 있습니다. 디스크 읽기 및 쓰기 속도가 엄청나게 느리기 때문에
결과를 디스크에 복사하는 대신 네트워크를 통해 워크스테이션의 SSD에서 데브킷에서 실행되는 게임으로 스트리밍했습니다.
이를 통해 PS4에서 가장 빠른 초당 1Gbit 네트워크에 도달할 수 있었습니다.
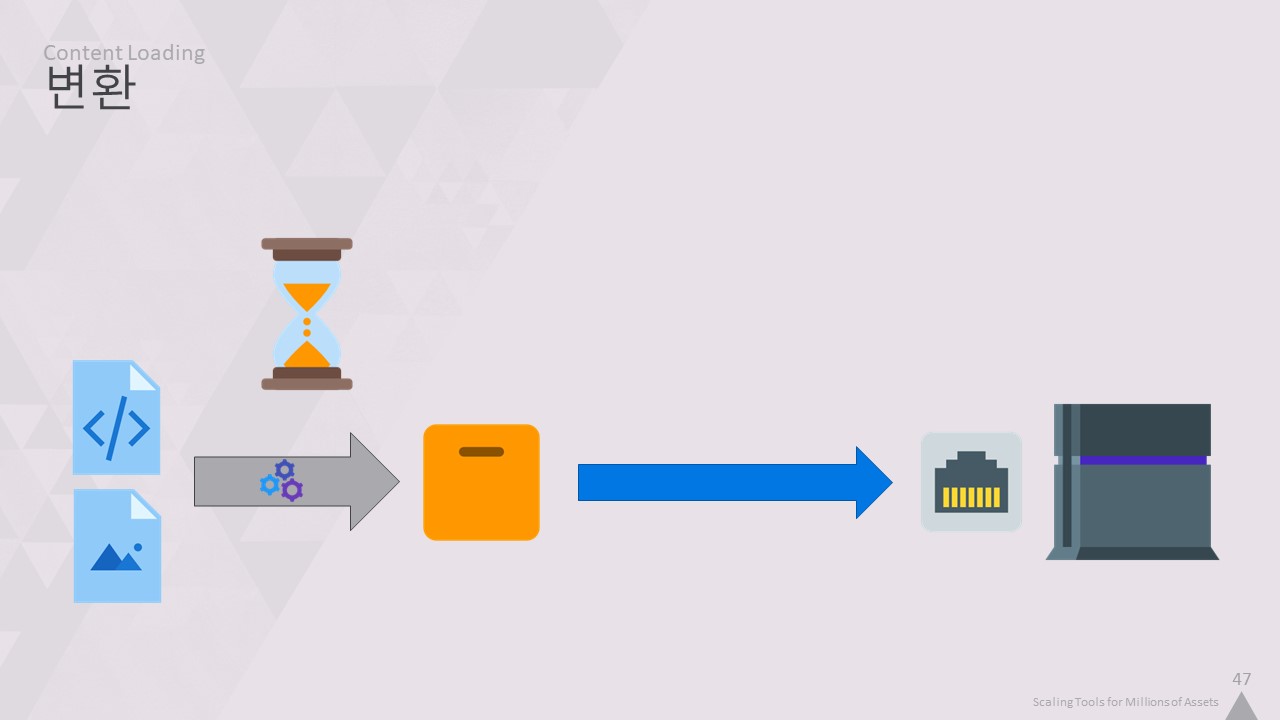
하지만 여전히 워크스테이션에서 코어텍스트의 에셋을 바이너리 형식으로 변환하는 데 많은 시간을 소비하고 있었습니다.
여기에는 텍스처 압축, 셰이더 컴파일, 오디오 압축 등이 포함되며 모두 시간이 오래 걸릴 수 있습니다.
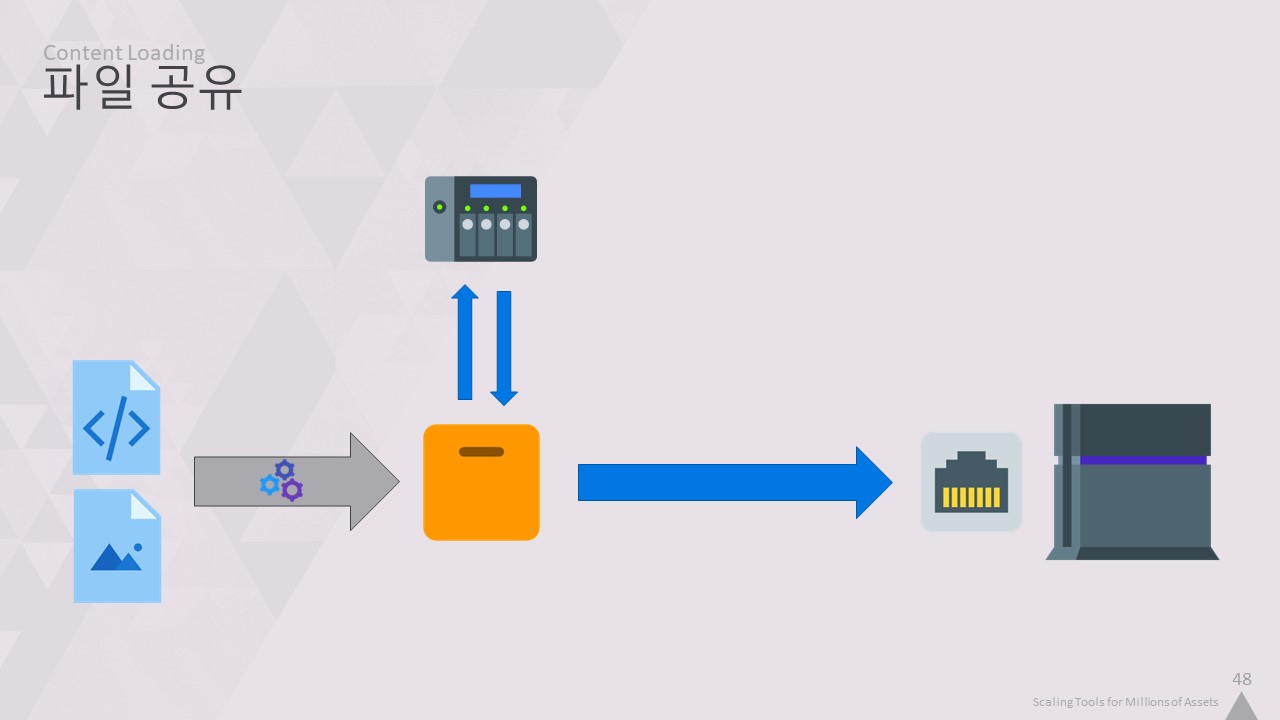
대부분의 사람들이 콘텐츠의 극히 일부만 편집하기 때문에 네트워크 공유에 결과를 캐시할 수 있었습니다.
사용자의 워크스테이션은 이미 변환된 콘텐츠를 거기에서 다운로드한 다음 게임으로 스트리밍하면 됩니다.
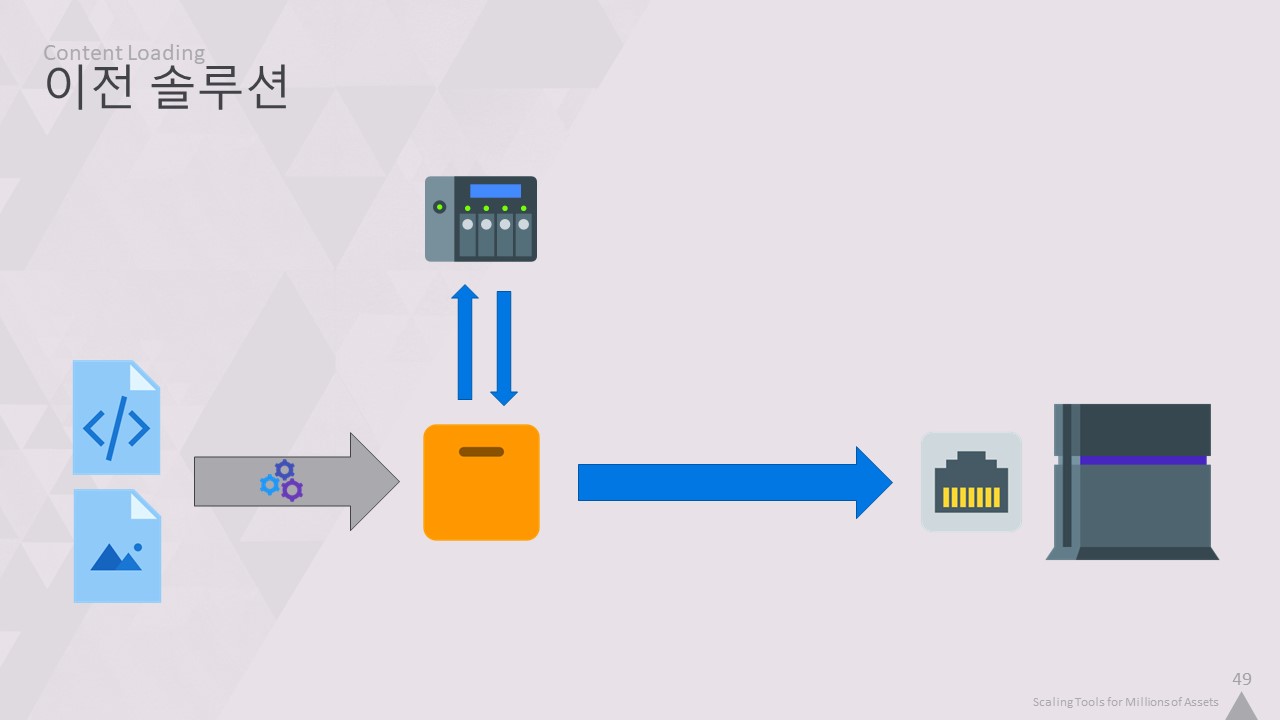
호라이즌 제로 던을 개발하던 당시의 모습입니다.
CPU의 과중한 작업을 모두 공유하고 결과를 캐싱하며, 느린 PS4 HDD에 아무것도 저장하지 않는 완벽한 기능의 솔루션입니다.
하지만 여전히 우리가 원하는 만큼 빠르지는 않습니다. 최신 버전으로 동기화한 후 게임을 로딩하기 전에 새로 변환된 콘텐츠를 모두 워크스테이션에 다운로드하는 데 15분 정도 걸립니다.
앞서 언급했듯이 파일 시스템은 많은 작은 파일을 좋아하지 않으며, 네트워크 파일 공유는 이 문제를 더욱 악화시킵니다.
현재 SMB 공유에서 작은 파일을 읽으면 로컬 파일 시스템의 25,000개 파일에 비해 초당 700개 정도밖에 읽지 못합니다.
네트워크 스택은 이 작업을 완벽하게 수행할 수 있으므로 2015년에 다양한 솔루션으로 몇 가지 테스트를 수행했습니다.
Windows의 SMB, Linux의 Apache, 전용 하드웨어를 사용해 보았지만 어느 것도 기대에 미치지 못했습니다.
그래서 우리는 이런 상황에서 우리가 좋아하는 일을 직접 해보았습니다.

GlobalStore는 메모리에 대량의 데이터를 저장하고 간단한 가져오기/내보내기 프로토콜을 통해 액세스할 수 있는 키/값 서버입니다.
파일 시스템이라기보다는 네트워크에 연결된 해시맵이라고 생각하면 됩니다.
Windows에서 실행되며, 파이프라인 요청을 통해 데이터를 네트워크로 전송하기 위해 I/O 완료 포트와 DirectMemoryAccess로 고도로 최적화되어 있습니다.
소규모 읽기의 경우 NVMe에서 NTFS보다 약 3배 빠릅니다.
GS는 로컬 디스크의 25,000개에 비해 초당 75,000개의 파일을 관리합니다.
이 시스템은 고도의 병렬 액세스를 위해 설계된 단일 스레드에 불과합니다.
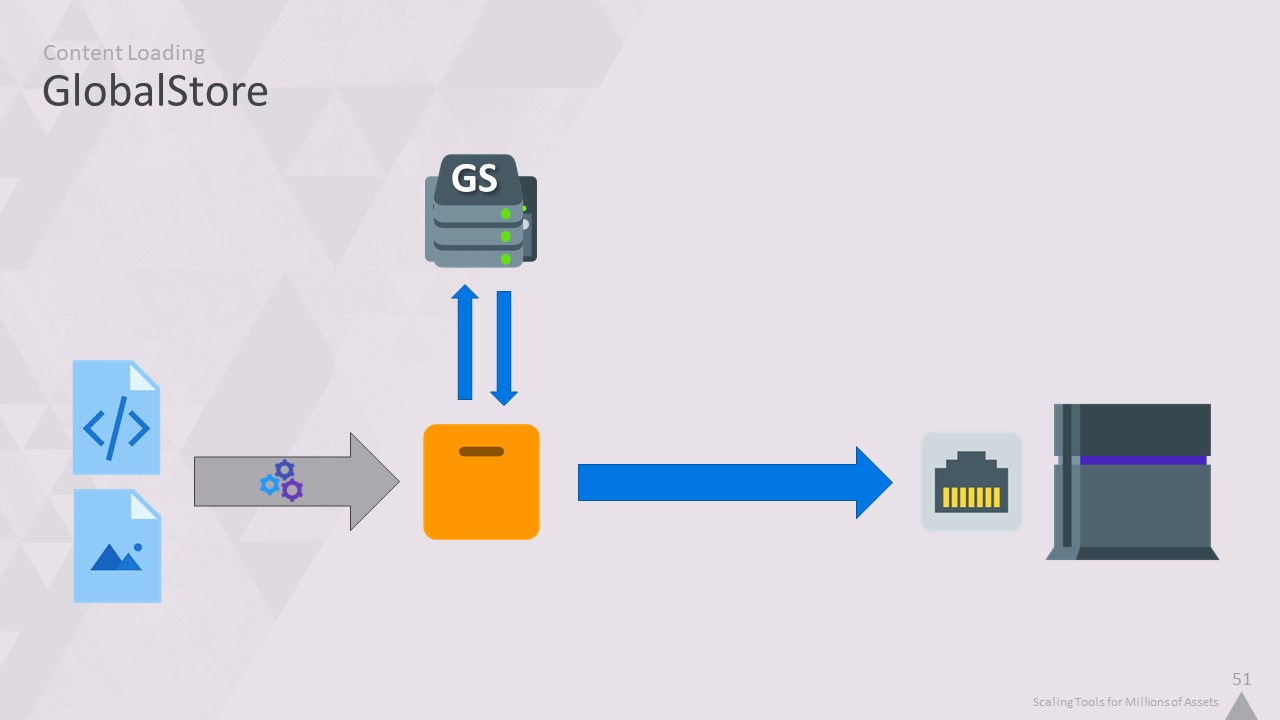
캐시를 SMB에서 GlobalStore로 교체한 결과 훨씬 더 나은 결과를 얻었습니다.
일반적인 액세스의 경우 GlobalStore가 SMB 공유보다 100배 더 빠릅니다.
정말 대단하죠! 하지만 동기화할 때마다 변환된 모든 콘텐츠를 다운로드하는 데 여전히 많은 시간을 소비하고 있으며, 이 모든 시간은 다시 OS 오버헤드입니다....
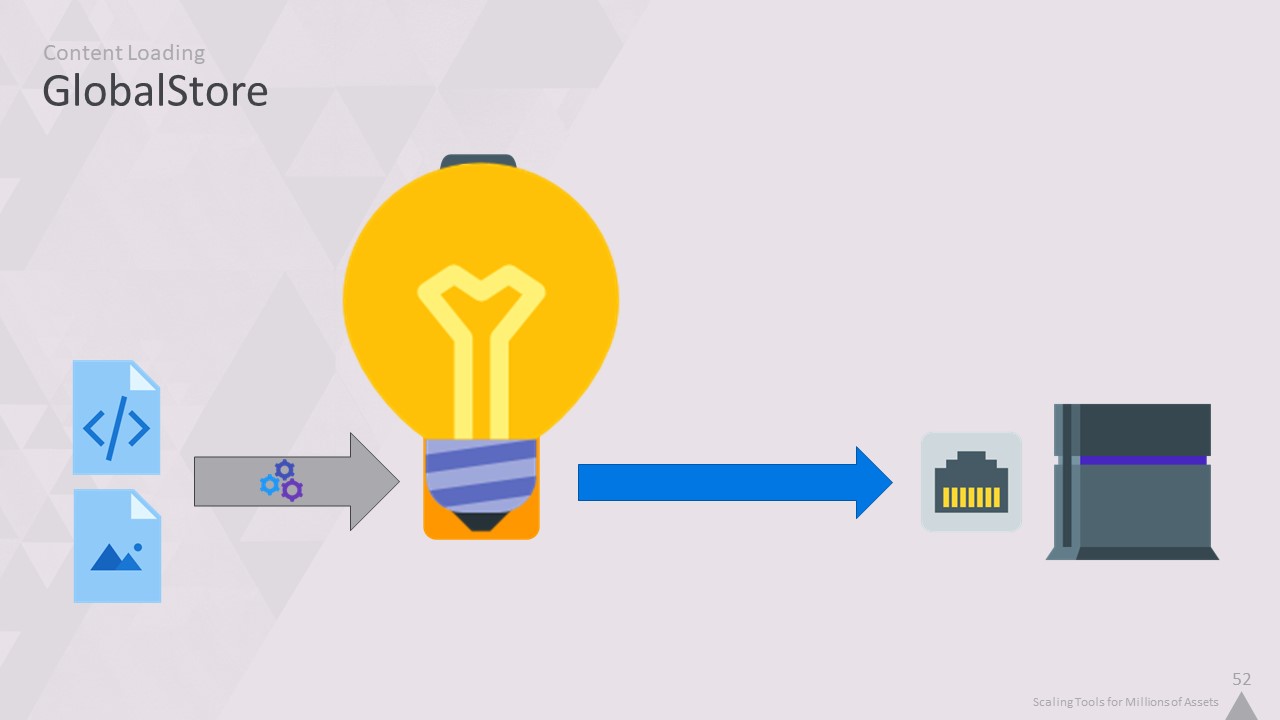
그리고 여기서 전구가 켜졌습니다. 초당 수백만 건의 요청을 처리할 수 있는 서버를 보유하고 있으며, 게임은 이미 네트워크를 통해 모든 데이터를 스트리밍하고 있습니다.
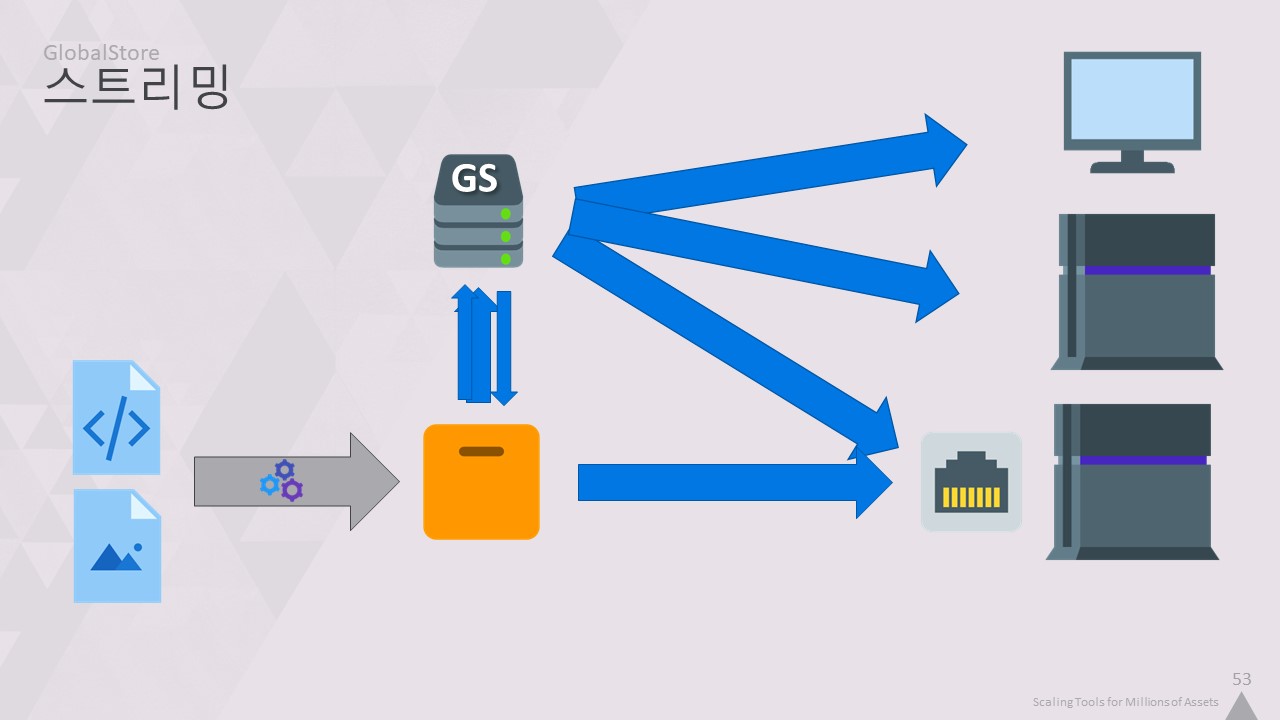
중간 단계를 없애면 어떨까요? 콘텐츠가 변환되면 디스크에 기록되지 않고 GlobalStore에 업로드됩니다.
워크스테이션의 프로세스가 게임에 무엇을 로드할지 알려주면 게임은 이 서버에서 네트워크를 통해 모든 것을 로드합니다.
이 시스템은 현재 모든 곳에서 사용하고 있으며, 저희에게는 매우 잘 작동하고 있습니다.
이 하나의 서버가 모든 개발 키트, 워크스테이션, 빌드 머신에 데이터를 제공합니다.
사용자는 더 이상 게임을 시작하기 전에 모든 데이터가 로컬에 캐시되는 동안 약 20분을 기다릴 필요가 없습니다.
로딩 속도도 10~20% 빨라집니다.
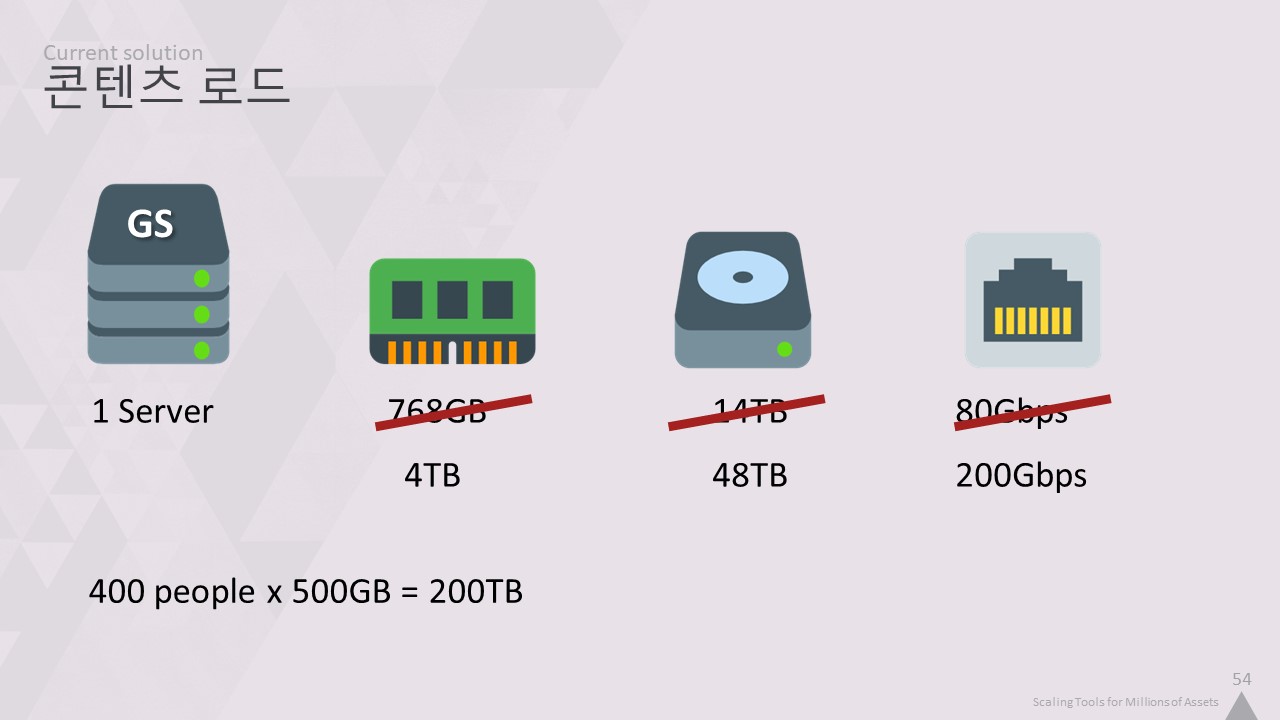
포비든 웨스트의 경우 768GB RAM, 14TB 스토리지, 80Gbps 네트워크를 갖춘 단일 서버로 약 350명에게 서비스를 제공했습니다.
이를 다른 시각으로 보면, 모든 변환된 콘텐츠를 모든 데브킷과 워크스테이션에 복제하고 모든 개발자를 위해 추가로 500GB SSD에 투자하는 대신 스토리지가 '단지' 14TB인 대형 머신 1대에 투자한 것입니다.
이후 머신을 업그레이드하여 현재는 무려 4TB의 RAM을 사용하고 있습니다.
이 한 대의 컴퓨터로 회사 전체와 수많은 빌드 머신에 서비스를 제공할 수 있습니다.
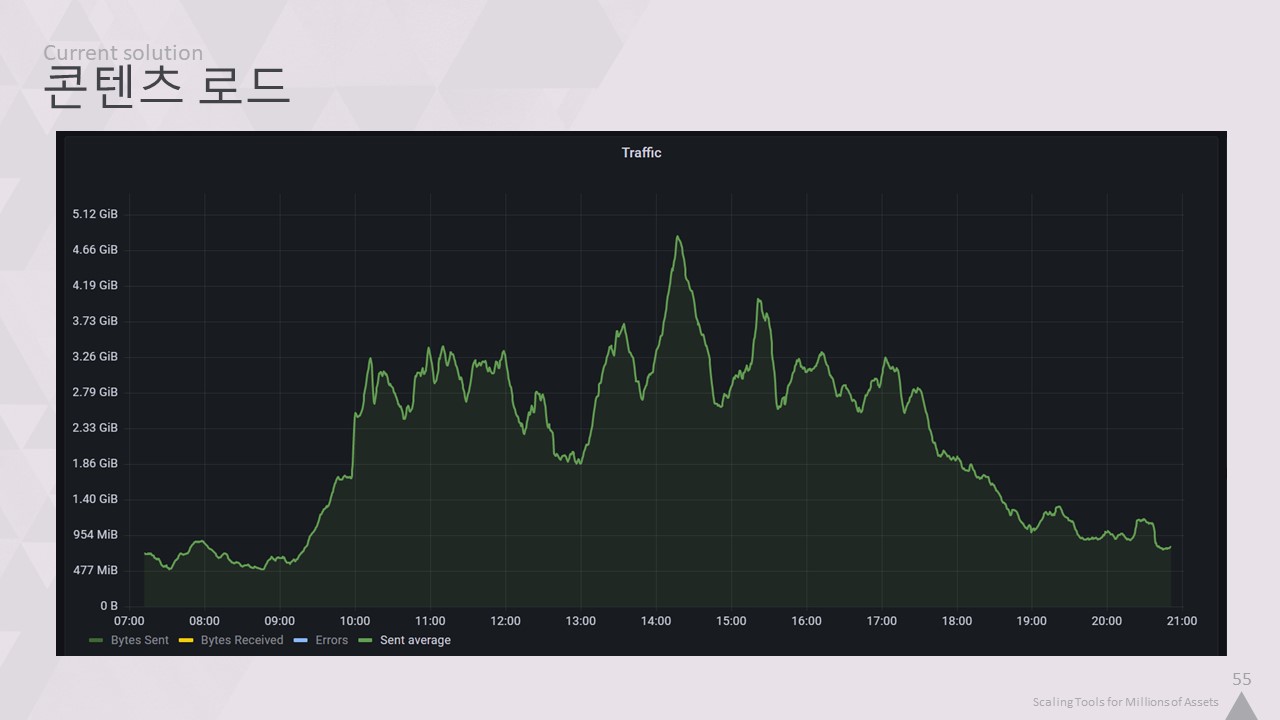
하루 종일 평균 약 2.5GB, 초당 25만 건의 요청이 발생합니다.
사람들이 출근할 때 트래픽이 확실히 증가하지만 점심 무렵에는 감소하고 오후 6시 이후에는 감소합니다.
그리고 이 모든 작업을 약 5%의 CPU 부하로 수행합니다.
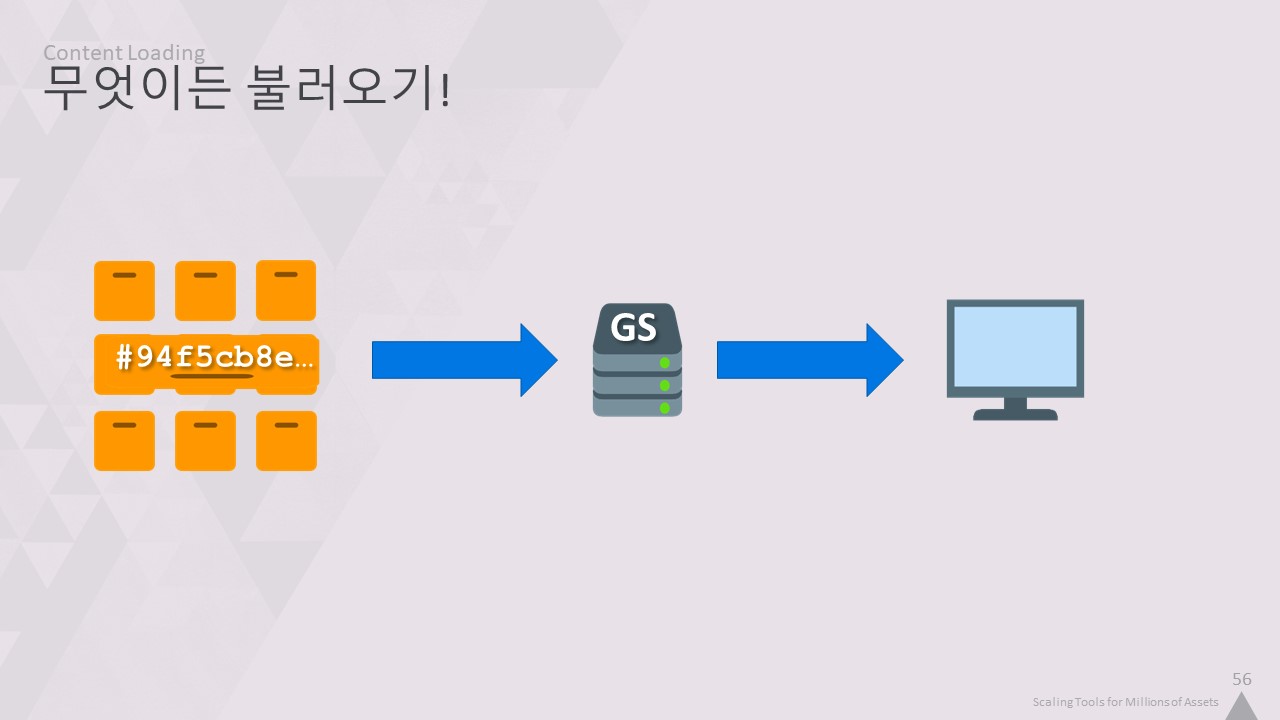
하지만 이제부터가 시작입니다!
이제 모든 데이터가 중앙 서버에서 스트리밍되는 시스템을 갖추었으므로 로컬 버전의 게임을 로드하는 것은 다른 빌드를 로드하는 것과 다르지 않습니다.
빌드는 여러 에셋으로 구성됩니다.
모든 에셋은 글로벌 스토어에서 변환된 결과에 매핑됩니다.
빌드의 모든 에셋에 대해 단일 매핑을 생성하고 이 매핑 자체를 글로벌 스토어에 업로드하면 해당 매핑에 대한 단일 식별자만으로 전체 빌드를 처리할 수 있습니다.
우리의 빌드 머신은 10분마다 새로운 빌드를 생성합니다. 이러한 빌드 중 어느 빌드에든 그대로 로드할 수 있습니다.

레벨 런처를 예로 들어 설명하겠습니다.
변경 사항이 없는 동일한 버전과 변경 사항을 비교하고 싶다고 가정해 보겠습니다.
빌드 목록을 열고 동기화할 리비전을 선택한 다음 실행을 클릭합니다.
런처가 먼저 실행 파일을 다운로드한 다음 게임을 시작합니다.
오늘 아침이나 지난주 빌드를 선택할 수도 있습니다. 또는 동료가 작업 중인 빌드를 선택하여 간단한 링크로 공유할 수도 있습니다.
이 모든 것이 동기화하거나 변경 사항을 되돌릴 필요 없이 가능합니다.
그리고 20초 이내에 로컬 상태와 완전히 다른 상태로 로드됩니다.
이 프레젠테이션을 테스트 실행한 후 수석 기술 프로듀서와 채팅을 하고 있었습니다.
채팅을 하면서 그는 레벨 런처를 사용하여 여러 시네마틱을 로드하고 있었습니다.
1분 정도밖에 걸리지 않은 이 대화에서 그는 3개의 시네마틱에 성능 및 시각적 문제가 있는지 확인했습니다.
누군가 수정 사항을 제출하면 다른 빌드를 선택하기만 하면 20초 후에 수정 사항이 적용되었는지 확인하고 목록에서 해당 항목을 표시할 수 있었습니다.
이 모습을 보면서 "이걸 더 빠르게 만들 수 있겠구나"라는 생각이 들었습니다. 하지만 적어도 커피를 마시는 것보다 훨씬 빠르긴 하잖아요!

앞서 잠깐 언급했듯이, 작업 중인 모든 내용을 동료들과 공유할 수도 있습니다.
로컬 변경 사항에 대한 식별자 중 하나를 생성하여 회사 내 모든 사람과 공유할 수 있는 링크를 만들면 클릭 한 번으로 20초 안에 정확한 변경 사항을 실행할 수 있습니다.
이 기능은 프로토타입에 대한 피드백을 받거나 QA가 변경 사항을 테스트하는 데 매우 유용합니다.
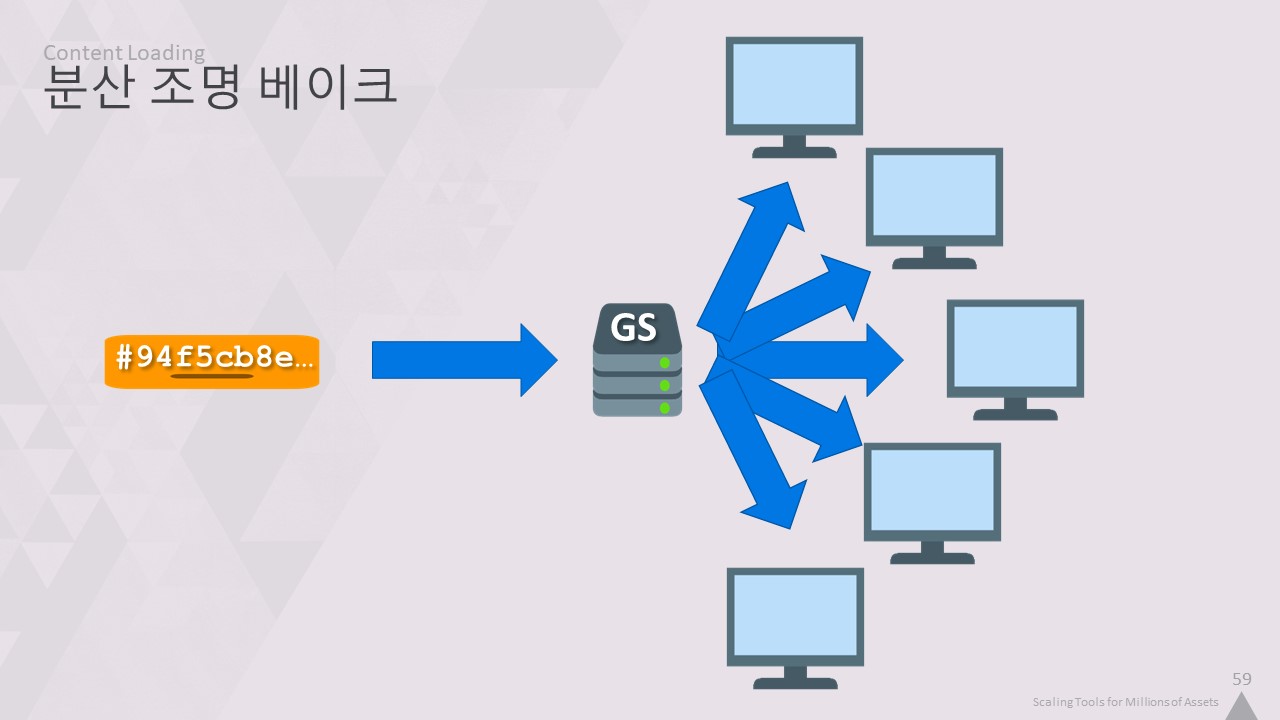
이 시스템의 강력한 성능을 보여주는 또 다른 예는 라이트 베이크를 배포할 수 있다는 점입니다.
전체 사무실의 모든 유휴 워크스테이션을 단 몇 분 만에 동일한 버전의 게임으로 로드할 수 있습니다.
라이트 베이크는 GPU 렌더링을 포함한 전체 게임 로직을 실행해야 하는 고비용 프로세스입니다.
이전에는 빌드 머신이 특정 리비전에 동기화하고, 누군가의 변경 사항을 취소하고, 콘텐츠를 변환한 다음 오랜 시간이 걸리는 베이크 프로세스를 시작했습니다.
이로 인해 프로젝트 막바지에 서버 팜에 상당한 스트레스가 가해졌습니다.
밤에는 유휴 워크스테이션이 많은데 누군가의 동기화 상태를 변경하고, 변경 사항을 되돌리고, 다른 사람의 작업을 적용하는 것은 미친 짓이며 분명 문제가 발생할 수 있습니다.
따라서 글로벌 스토어 스트리밍을 사용하면 하나의 실행 파일을 해당 머신에 넣으면 로컬 상태를 변경할 필요 없이 모든 것을 스트리밍할 수 있습니다.
이를 통해 모든 유휴 워크스테이션에 라이트 베이크를 배포할 수 있으므로 사용자의 상태를 변경하지 않고도 정확히 동일한 내용을 베이킹할 수 있습니다.
이를 통해 엄청난 컴퓨팅 성능을 확보할 수 있었습니다.

우리는 모놀리식 패키지에서 세분화된 콘텐츠 로딩으로 전환하여 반복 시간을 대폭 개선했습니다. 또한 더 이상 모든 데브킷이나 워크스테이션에 중복 데이터를 저장하지 않고 네트워크를 통해 모든 것을 스트리밍함으로써 작업 중인 데이터와 게임 크기를 분리했습니다. 로컬 변경 사항, 지난 주 빌드, 동료가 공유한 프로토타입을 모두 빠르게 로드할 수 있습니다. 따라서 완전히 새로운 워크플로가 가능합니다.

이제 고성능 키 값 저장소에서 모든 것을 스트리밍하는 콘텐츠 로딩 시스템과 파일을 읽을 필요가 없는 에셋 데이터베이스를 갖추게 되었습니다.
이러한 시스템은 매우 강력한 방식으로 시너지를 발휘합니다.
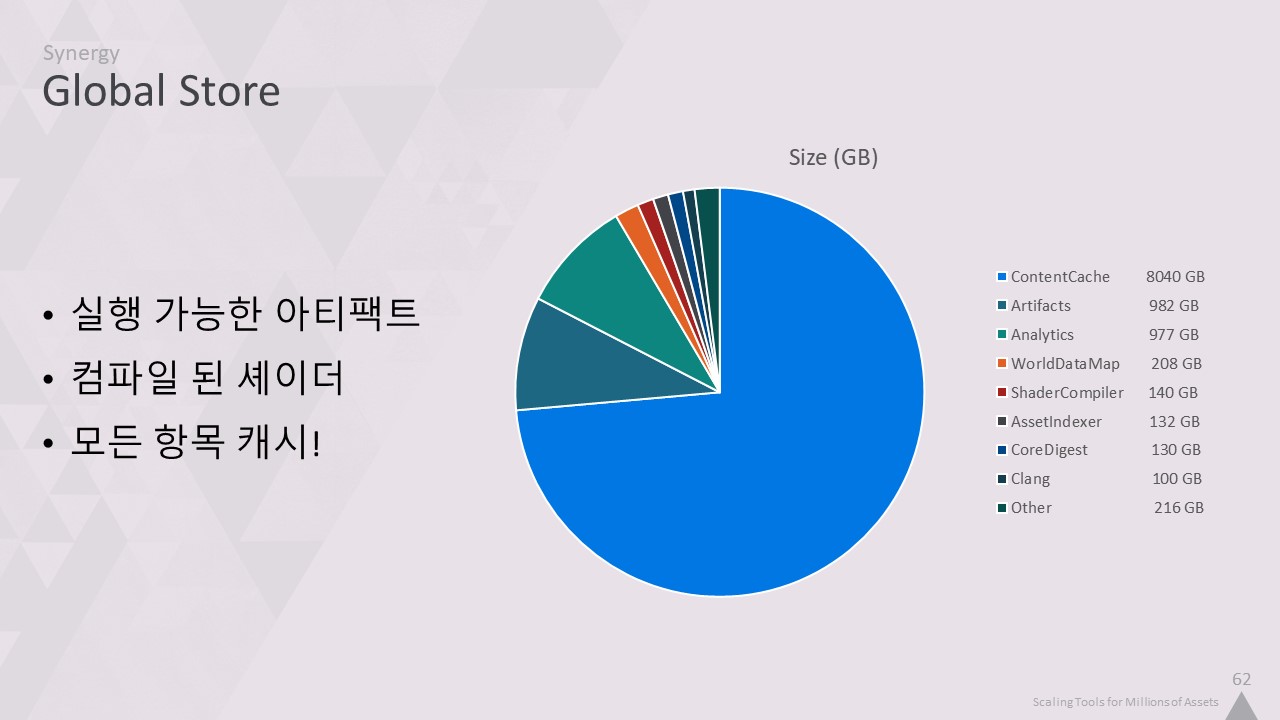
앞서 언급했듯이 변환된 콘텐츠는 GlobalStore에 저장합니다.
하지만 이는 캐싱할 수 있는 것의 한 예일 뿐입니다.
빌드 머신의 실행 가능한 아티팩트도 저장하므로 Perforce에 체크인할 필요가 없습니다.
또는 변환 속도를 높이는 데 도움이 되는 셰이더 컴파일러 캐시도 있습니다.
인프라에 잘 통합된 고성능 저장소가 있기 때문에 코드 몇 줄만 추가하면 새 캐시를 추가할 수 있습니다.

그 좋은 예로 Asset-Indexer를 들 수 있습니다.
이 인덱서는 게임 에셋의 파일에서 데이터베이스를 구축합니다.
이를 위해서는 수백만 개의 파일을 모두 읽고 파싱하여 색인된 데이터를 추출해야 합니다.
하지만 모든 워크스테이션이 이 작업을 수행해야 하며, 극소수의 로컬 변경 사항을 제외하고는 모두 똑같은 파일을 파싱합니다.
파일 경로, 파일 크기, 수정 시간 등 메타데이터에 따라 각 파일의 추출을 GlobalStore에 저장할 수 있습니다.
그러면 AssetIndexer는 파일을 열지 않고도 메타데이터를 가져올 파일만 나열하고 GlobalStore에서 추출을 다운로드하여 데이터베이스를 구축할 수 있습니다.
GlobalStore는 수백만 건의 소규모 요청에 최적화되어 있기 때문에 파일 자체를 읽고 파싱하는 것보다 훨씬 빠릅니다.
즉, 파일을 하나도 열지 않고도 게임 내 모든 파일에 대한 데이터베이스를 약 5분 만에 구축할 수 있습니다.
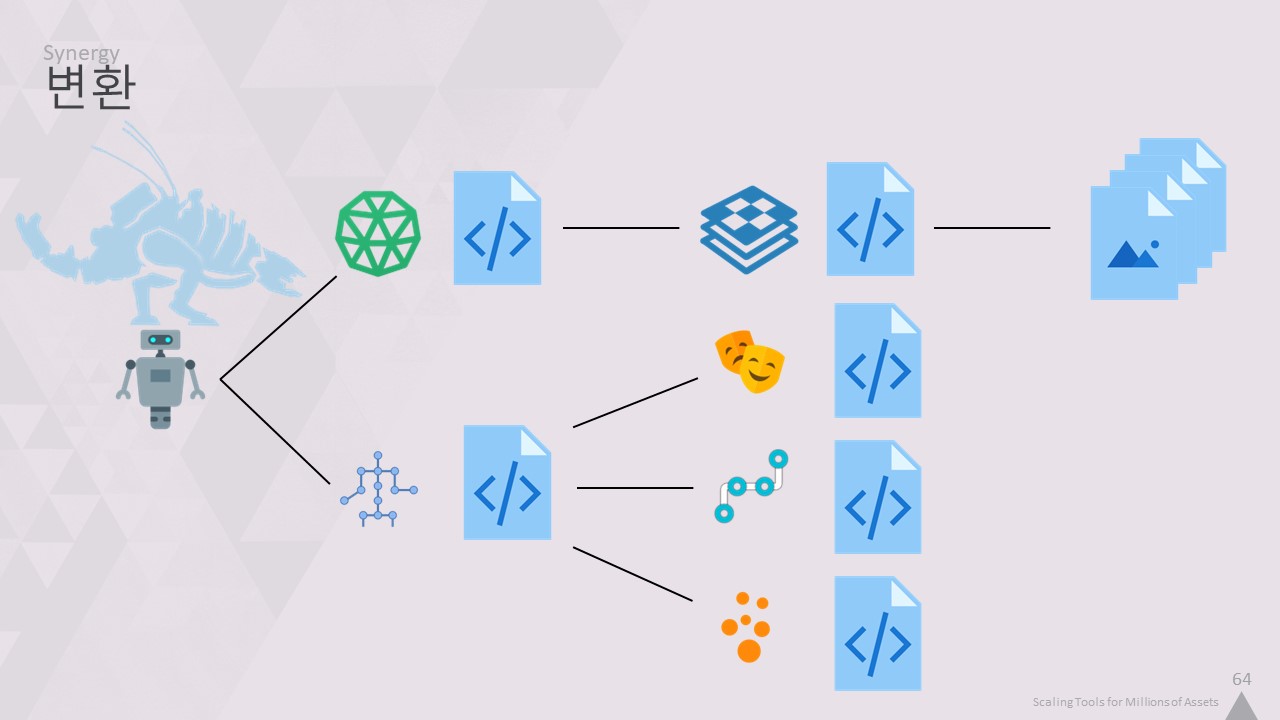
이러한 시너지 효과의 또 다른 예는 변환 중입니다. 로봇 엔티티와 같은 것을 로드할 때
해당 메시, 텍스처, 애니메이션 등도 로드해야 합니다.
이러한 파일은 별도의 코어 텍스트 또는 바이너리 파일에 저장되어 있을 수 있으므로 이러한 모든 파일에 대한 변환된 결과를 GlobalStore에서 찾기 위해
변환 프로세스는 오브젝트와 파일 간의 링크를 재귀적으로 따라가며 로드해야 할 항목의 그래프를 생성합니다.
이를 종속성 검사라고 합니다.
이전에는 링크 구조를 파악하고 비교를 위해 해시를 계산하기 위해 디스크에서 파일을 읽었습니다. 이는 게임에서 무언가를 로드할 때마다 수천 개의 파일을 열어야 한다는 것을 의미했습니다.
하지만 Asset-Indexer를 사용하면 이 모든 데이터를 메모리 매핑된 데이터베이스에 이미 저장할 수 있습니다. 지금부터 왜 이 방법이 훨씬 빠른지 좀 더 자세히 살펴보겠습니다.

많은 파일을 열 때 발생하는 문제점은 모든 파일에 대해 커널 호출을 수행하여 핸들을 가져오고 다시 닫으려면 또 다른 커널을 호출해야 한다는 것입니다. 다른 디스크 액세스가 없더라도 CPU는 모든 파일에 대해 커널 모드로 전환했다가 다시 사용자 모드로 두 번 전환해야 합니다. 또한 파일 시스템은 프로세스 간 파일 일관성을 보장해야 하므로 대부분의 호출이 내부 잠금에서 직렬화됩니다.

공유 메모리의 경우
에셋 인덱서 데이터베이스를 변환기의 프로세스 공간에 매핑하기 위해 커널 호출을 한 번만 수행하면 되고,
리더 잠금을 얻기 위해 한 번 더 호출하면 됩니다.
이제 두 번의 커널 호출로 프로세스 메모리의 다른 데이터와 마찬가지로 4백만 개의 파일에 대한 인덱싱된 정보에 액세스할 수 있습니다.
매핑 후 파일의 해시를 조회하는 데 1.2마이크로초밖에 걸리지 않습니다.

공유 메모리의 경우
에셋 인덱서 데이터베이스를 변환기의 프로세스 공간에 매핑하기 위해 커널 호출을 한 번만 수행하면 되고,
리더 잠금을 얻기 위해 한 번 더 호출하면 됩니다.
이제 두 번의 커널 호출로 프로세스 메모리의 다른 데이터와 마찬가지로 4백만 개의 파일에 대한 인덱싱된 정보에 액세스할 수 있습니다.
매핑 후 파일의 해시를 조회하는 데 1.2마이크로초밖에 걸리지 않습니다.
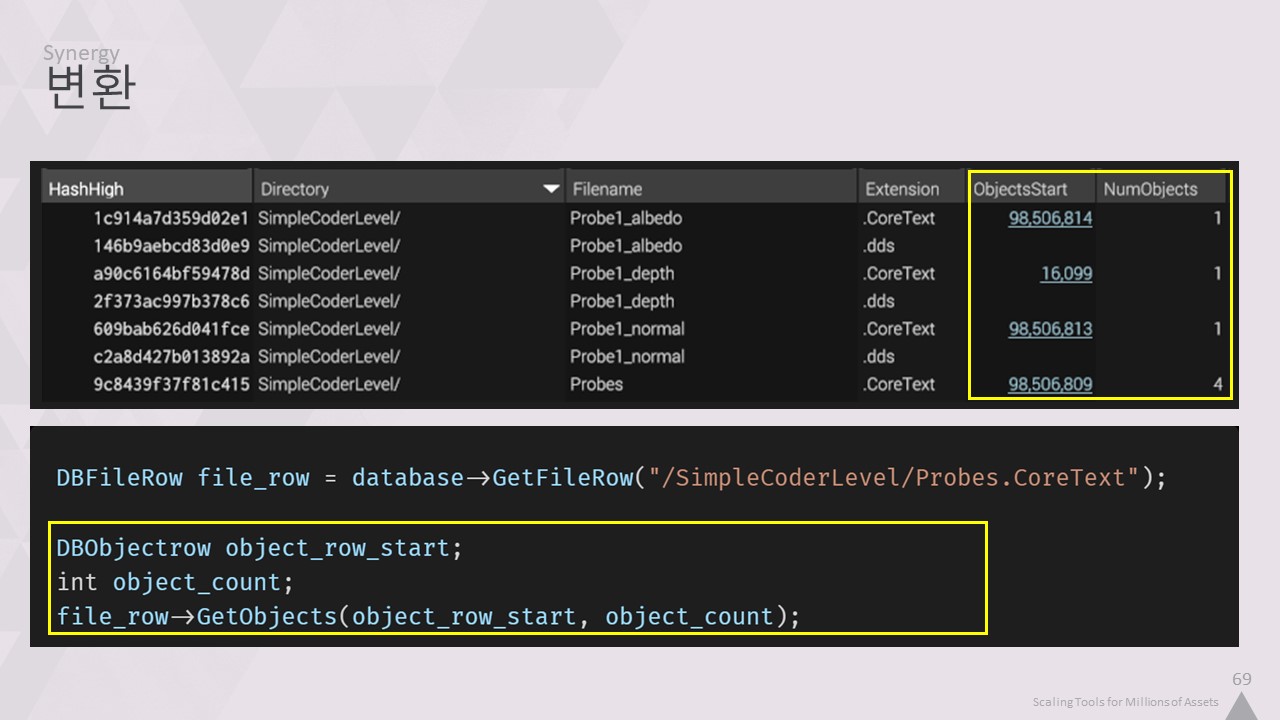
여기서 말하는 메모리 매핑 데이터베이스는 단순히 SQLite 파일을 메모리 매핑하고 쿼리를 수행하는 것을 의미하지 않습니다.
데이터베이스는 콘텐츠를 위해 설계된 실제 데이터 구조입니다.파일과 객체는 효율적인 저장을 위해 별도의 테이블에 저장되지만, 데이터 구조를 탐색하는 작업은 여전히 고성능을 발휘합니다.
파일 항목에는 개체 테이블에 대한 직접 인덱스가 있어 해당 파일의 개체를 포함하는 인접한 행을 가리킵니다.
관련 데이터를 찾기 위해 복잡한 쿼리를 실행하거나 모든 행을 반복할 필요가 없습니다. 링크도 마찬가지입니다.

즉, 링크 그래프를 만들고, 해시를 비교하고, 다른 검사를 수행하면 40초 만에 게임 내 코어 텍스트 파일 백만 개가 모두 변환되었는지 확인할 수 있습니다.
따라서 종속성 검사를 에셋 인덱서를 사용하도록 전환함으로써 전체 프로세스가 훨씬 빨라졌습니다.
하지만 더 중요한 것은 디스크에서 코어텍스트 파일을 하나도 읽지 않고도 게임에 로드할 수 있다는 점입니다.
데이터베이스에 대한 종속성 검사를 수행하고 글로벌 스토어에서 변환된 콘텐츠를 스트리밍하기 때문입니다.
그리고 이것은 나중에 더욱 중요해질 것입니다.
거의 정확히 3년 전인 2020년 3월, 모든 사람이 갑자기 재택근무를 시작하고 싶다는 강한 열망을 가졌기 때문입니다.

이 모든 설계는 사무실 네트워크를 염두에 두고 만들어졌습니다.
즉, 모든 워크스테이션에 10Gbps와 1ms 미만의 지연 시간을 제공합니다.
우리는 완전한 워크스테이션을 집으로 보내기로 결정했기 때문에 최악의 경우 20Mbps 연결을 통해 작업하는 사람도 있었습니다.
이는 저희 사무실보다 500배나 느린 속도입니다.
이런 연결에서 95GB 용량의 패키지를 다운로드하려면 하루 종일 걸렸을 것입니다.
하지만 앞서 설명한 대로 인터넷을 통한 스트리밍도 당연히 작동하지 않았습니다.

그래서 모든 WFH PC에 GlobalStore 프록시를 설정했습니다.
아이러니하게도 이제 로컬 GlobalStore가 생겼습니다.
디스크에서 읽어야 하는 중복된 데이터가 있는 모든 워크스테이션으로 돌아가야 했기 때문에 이 방법은 이상적이지는 않았습니다.
하지만 우리가 한 모든 작업은 여전히 매우 가치가 있었습니다.
데이터를 더 작은 덩어리로 분할하고 필요한 데이터만 로드하도록 함으로써 사람들은 매일 95GB 전체를 다운로드할 필요가 없었습니다.
대신 최신 개정판을 받은 후에는 마지막 동기화 이후 변환된 콘텐츠의 델타만, 그리고 작업 중인 영역에서만 다운로드합니다.
또한 자체 GS 프록시는 이러한 소규모 요청에 대해 네트워크 파일 공유보다 훨씬 높은 처리량을 달성합니다.

이 시점에서 가장 큰 병목 현상은 퍼포스의 게임 에셋을 동기화하는 것이었습니다.
사용자들은 매일 10~40GB를 다운로드해야 했는데, 변환된 콘텐츠와 마찬가지로 그 중 대부분은 실제로 사용하지 않는 것이었습니다.
다행히도 업계 친구들의 도움으로 가장 뛰어난 가상 파일 시스템을 사용할 수 있었습니다.
요약하면, 사용자나 프로그램에는 파일이 있는 것처럼 보이지만 실제로 파일을 읽을 때만 콘텐츠가 다운로드되는 것입니다.
자세한 내용은 작년 GDC에서 Brandon Moro가 이 주제에 대해 훌륭한 강연을 했습니다.
이 기능은 모든 사용자에게 배포되어 집에 있는 사람들의 동기화 시간을 몇 시간에서 몇 분으로 단축하고 사무실에 있는 사람들의 동기화 시간도 개선했습니다.

가상 파일 시스템은 트라이포스의 마지막 조각이었습니다.
에셋인덱서 및 글로벌 스토어와 결합하여 디스크에 콘텐츠를 하나도 저장하지 않고도 게임 작업을 시작할 수 있습니다.
필요한 콘텐츠만 필요할 때 다운로드하면 됩니다.
이 모든 것을 종합하기 위해 파일의 수명을 살펴봅시다.

누군가 Perforce에 파일을 제출하는 것으로 시작됩니다.
그런 다음 다른 사람이 가상 파일 시스템을 사용하여 파일을 동기화합니다.
Perforce는 파일이 있는 것처럼 위장할 수 있는 충분한 메타데이터를 제공합니다.
에셋 인덱서는 이 새 파일을 인식하고 메타데이터를 기반으로 글로벌 스토어에서 오브젝트, UUID 등이 포함된 추출을 가져옵니다.

그런 다음 사용자는 에디터에서 에셋 브라우저를 열고 에셋 인덱서에게 오브젝트 목록을 요청하며, 여기에는 이제 새 파일이 포함됩니다.
사용자가 파일을 열면 전체 콘텐츠가 가상 파일 시스템에 의해 퍼포스에서 온디맨드 방식으로 가져옵니다.
그런 다음 사용자는 몇 가지 편집을 할 수 있으며, 저장 시 에셋 인덱서가 새로운 변경 사항이 포함된 파일을 다시 스캔합니다.

변경 사항을 테스트하기 위해 사용자가 게임을 시작하면 변환 프로세스도 시작됩니다.
그러면 에셋 인덱서에 디스크 상태를 요청합니다.
아직 변환되지 않은 로컬 변경 사항이 있으면 이를 변환하여 글로벌 스토어에 업로드합니다.
그런 다음 게임에서 새 에셋을 스트리밍합니다.

그리고 변경 사항에 만족하면 파일을 다시 소스 제어에 제출하여 주기를 완료합니다.
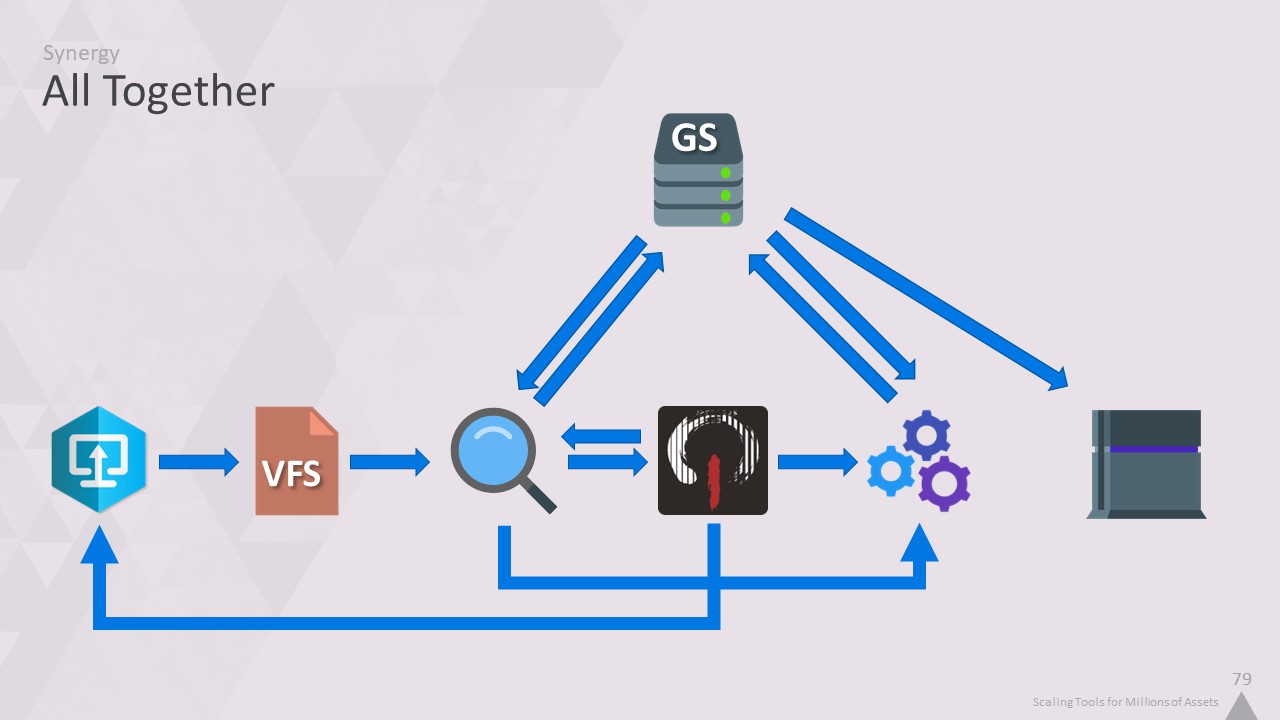
이 스파게티 차트도 여전히 다소 단순화되어 있지만, 이러한 모든 시스템이 함께 작동하기 때문에 꼭 필요한 데이터만 로컬에 저장할 수 있습니다.

덕분에 새 브랜치에서 게임을 동기화하고 시작하는 데 8시간 이상 걸리던 시간이 20분이면 충분해졌습니다.
또한 더 이상 모든 게임 에셋과 변환된 콘텐츠가 필요하지 않으므로 저장 공간 부족 없이 여러 브랜치를 쉽게 동기화할 수 있으므로 프로젝트 간 전환이 단 몇 초 만에 이루어집니다.

결론적으로, 모든 게임 콘텐츠에 대한 정보를 빠르게 제공할 수 있는 로컬 에셋 데이터베이스를 구축하면 됩니다,
네트워크를 통해 모든 데이터를 스트리밍하는 로딩 시스템이 필요합니다,
그리고 이 두 시스템을 스마트하게 결합하여이를 통해 대기 시간을 크게 줄이고 수백만 개의 에셋을 손쉽게 작업할 수 있습니다.
커피 머신이 너무 외롭지 않았으면 좋겠네요.
할일: 좀 더 설명해 주시겠어요? 다른 슬라이드에 각 부품과 그 장점을 간략하게 요약해서 보여드릴게요.

게릴라의 모든 훌륭한 동료들에게 큰 박수를 보내고 싶습니다.
특히 이 프레젠테이션을 지원하고, 기발한 아이디어를 제시하고, 제가 말씀드린 많은 것들을 실제로 만들어준 이 분들께 감사드립니다.
그리고 여러분 모두의 관심에 감사드립니다!한 가지 더 말씀드리자면

"채용 중입니다" 슬라이드입니다! 저희는 아직 많은 아이디어를 가지고 있으니, 이 기술을 더욱 발전시키는 데 함께하고 싶다면 저와 상담하거나 웹사이트에서 지원하세요!
