[번역] Hierarchical-Z map based occlusion culling ( Old Post )
역자의 말.
넷이즈 광저우에 위치한 젠 사업부에 테크아트 라인2 리더(뭔가 중국의 보직이 참...P 와 M 을 겸직하도록 승인이 되서)로 근무 할 때 음양사 차세대 버전 개발팀에서 함께 일 했던 동료 그래픽스 프로그래머인 내원군(중국인 이겠죠 당연히.. )의 깃허브 리포를 오랫만에 다시 보게 되었는데요. 참고 레퍼런스가 있어서 간략히 포스팅으로 올려봤습니다. 여전히 한국 게임사는 자체엔진이라든가 특별히 그래픽스 프로그래밍 부서가 있거나 하는 경우가 극히 드물어서 관련 된 이야기등을 할 만한 엔지니어를 귀국 후 1년간 만나보질 못했네요. 중국에선 2018년 부터 2023년 까지 GPU DRIVEN 에 대한 수많은 토론을 해 왔었거든요. 어떻게 하면 모바일 플레폼의 하드웨어를 극복하고 최대 성능 최대 퀄리티까지 끌어 올릴 것인지에 대해서 말이죠. 한국에 귀국 한 이후 대부분의 게임개발사에는 전문적인 엔진 팀이 없는데다가 굳이 그렇게 모바일 하드웨어에서 동작하는 게임 그래픽을 상향 시키고자 하는 의지도 없더라고요. 확실히 중국과는 다르네요. 아무튼... 이제 유니티6.0 에 GPU Driven 개념이 본격적으로 도입되기 시작 했으니 기대를 해 보면서... 개인적으로도 구현할 것들이 많은 관계로... 점심시간에 짬 내서 올려 봅니다.
GitHub - sienaiwun/Unity_GPU_Driven_Particles: GPU Driven Particles Rendeing using Unity's SRP
GPU Driven Particles Rendeing using Unity's SRP. Contribute to sienaiwun/Unity_GPU_Driven_Particles development by creating an account on GitHub.
github.com

DISCLAIMER:
이 글은 원래 이곳에서 호스팅되던 기존 개인 기술 블로그에서 옮겨온 것이므로 원래 게시물과 형식 및 내용상의 차이가 있을 수 있습니다. 또한 기술적으로 부정확한 내용, 작성자가 더 이상 동의하지 않는 의견, 잘못된 영어 사용 등이 포함되어 있을 가능성이 높습니다. 이 글은 결함에도 불구하고 유용하다고 생각하시는 분들을 위해 공개 상태로 유지됩니다.
Hierarchical-Z(계층적-Z)는 최신 GPU의 잘 알려진 표준 기능으로, 온칩 메모리에 있는 뎁스 버퍼의 축소 및 압축 버전을 사용하여 들어오는 대규모 조각 그룹을 Discard 함으로써 뎁스 테스트 속도를 높일 수 있습니다. 이 문서에서 소개하는 기법은 동일한 기본 아이디어를 사용하여 기존 오클루전 쿼리에서 피할 수 없는 CPU 개입 없이 지오메트리 셰이더를 사용하여 많은 양의 개별 오브젝트에 대한 일괄 오클루전 컬링을 허용합니다. 이 문서에서는 수천 개의 오브젝트 인스턴스를 컬링하는 데 이 기술을 사용하는 OpenGL 4.0 마운틴 데모 형태의 레퍼런스 구현도 제공합니다.
소개
오클루전 컬링은 뷰 볼륨에 있지만 오클루전으로 인해 화면에 표시되지 않는 오브젝트를 식별하는 데 사용되는 가시성 결정 알고리즘입니다. 즉, 카메라에 더 가까이 있는 오브젝트에 의해 가려진다는 의미입니다.
여러 세대에 걸쳐 GPU는 하드웨어 가속 메서드를 통해 오클루전 쿼리 형태로 오클루전 컬링을 수행할 수 있습니다. OpenGL은 ARB_occlusion_query라는 확장자를 통해 이 기능을 제공합니다. 오클루전 쿼리는 매우 간단합니다. 오클루전 쿼리가 활성화된 상태에서 오브젝트를 그리면 쿼리는 깊이 테스트를 통과한 샘플 수를 반환합니다(또는 OpenGL 확장 ARB_occlusion_query2에서 제공하는 것처럼 오브젝트의 샘플이 깊이 테스트를 통과했는지 여부에 따라 참 또는 거짓을 반환합니다).
따라서 실제로 오클루전 쿼리를 사용하여 오클루전 컬링을 수행한다는 것은 간단히 다음과 같습니다:
- 오클루전 쿼리가 활성화된 상태에서 개체를 그립니다.
- 쿼리 결과 개체가 표시되면 개체를 그립니다.
처음에는 물체가 보이는지 아닌지를 알기 위해 물체를 그려야 하므로 어리석게 들릴 수 있습니다. 하지만 실제로 오클루전 쿼리를 사용하면 GPU의 작업을 크게 줄일 수 있습니다. 수천 개의 삼각형으로 이루어진 복잡한 물체가 있다고 생각해 보세요. 오클루전 쿼리를 사용하여 오브젝트의 가시성을 확인하려면 예를 들어 오브젝트의 경계 상자를 렌더링하고 경계 상자가 보이면(오클루전 쿼리가 일부 샘플을 통과했다고 반환하면) 오브젝트 자체가 보일 가능성이 높다는 뜻입니다. 이렇게 하면 대량의 지오메트리를 불필요하게 처리하지 않고도 GPU를 절약할 수 있습니다.
오클루전 쿼리는 정확한 결과가 아니라 개체의 가시성 여부에 대한 보수적인 추정치만 제공하기 때문에 여기서 의도적으로 "대부분 가시적"이라는 표현을 사용했다는 점을 언급해야 합니다. 이는 바운딩 박스가 원래 지오메트리와 화면에서 다른(더 큰) 부분을 차지하기 때문입니다. 따라서 오클루전 컬링 알고리즘에서 기대하는 것은 물체가 보이지 않거나 물체가 보일 가능성이 가장 높은 결과 중 하나를 제공하는 것입니다. 이 확률이 클수록 오클루전 컬링 효과가 더 좋습니다.
오클루전 컬링 알고리즘이 항상 최대한 효과적이기를 바라지만, 일반적으로는 효과와 효율성 사이에서 절충점을 찾아야 합니다. 위의 예에서 100%의 효율성을 원한다면 전체 오브젝트를 그려야 하며 이는 오클루전 컬링의 대부분의 목표를 달성하지 못하게 됩니다. 이 문서에 제시된 알고리즘은 다소 보수적이지만 훨씬 더 큰 데이터 세트에 오클루전 컬링을 사용할 수 있습니다.
동기 부여
하드웨어 가속 오클루전 쿼리는 가시성 결정에 사용할 수 있는 강력한 도구이지만, 오클루전 쿼리의 비동기적 특성을 고려할 때 오클루전 쿼리를 관리하고 그 결과를 기반으로 오브젝트를 그리는 것은 애플리케이션에 상당한 부담을 안겨주게 됩니다. 오클루전 쿼리를 가장 순진하게 사용하는 방법은 오브젝트를 그리기 직전에 쿼리를 실행하는 것입니다. 이는 실현 가능한 아이디어처럼 보이지만 쿼리 결과를 사용할 수 있을 때까지 CPU가 멈춰 있어야 하고 GPU의 빈 사이클도 포함되므로 실제로는 성능이 좋지 않습니다. 이 문제를 해결하기 위해 애플리케이션은 쿼리 실행과 쿼리 결과에 따른 객체 그리기 사이의 시간을 채워야 합니다. 이를 달성하기 위한 기술이 있지만 구현이 더 복잡해짐에 따라 비용이 발생합니다..
앞서 언급한 문제는 OpenGL 3에 도입된 조건부 렌더링(NV_conditional_render 확장 기능)을 사용하면 어느 정도 해결됩니다. 그러나 이 확장 기능은 쿼리 결과를 아직 사용할 수 없는 경우에는 오브젝트의 표시 여부에 관계없이 단순히 오브젝트를 그리기만 합니다. 이렇게 하면 렌더링 파이프라인이 멈추는 것을 피할 수 있고 확장 기능을 사용할 수 없는 경우 소프트웨어에서 수행할 수 있지만 오클루전 컬링의 목적에 다소 어긋납니다.
오클루전 쿼리를 사용할 때의 또 다른 단점은 오브젝트의 가시성을 결정하기 위해 여전히 CPU의 개입이 필요하다는 점입니다. 적절한 일괄 처리가 렌더러의 가장 중요한 측면 중 하나인 오늘날의 하드웨어에서는 이러한 접근 방식이 다소 비효율적입니다.
이 글에서 소개하는 오클루전 컬링 기법은 모든 렌더러에 통합하기 매우 간단하고 렌더러에 부담을 거의 주지 않으며 오브젝트의 가시성을 전적으로 GPU에서 결정하는 구현을 제공함으로써 이 두 가지 문제를 모두 해결합니다.
알고리즘
저와 다른 사람들이 제시한 다른 많은 GPU 기반 컬링 알고리즘의 경우와 마찬가지로 계층적-Z 맵 기반 오클루전 컬링은 지오메트리 셰이더의 기능을 사용하여 최종 렌더링에서 보이지 않는 것으로 판단되는 프리미티브의 방출을 거부합니다. 셰이더는 보이는 오브젝트에 대해서만 데이터를 방출하고 이 데이터는 트랜스폼 피드백을 사용하여 버퍼 오브젝트로 스트리밍됩니다.
알고리즘 자체는 최신 GPU에서 구현되는 계층적 Z 테스트와 유사합니다. 씬의 모든 오클루더를 렌더링한 후 뎁스 버퍼에서 계층적 뎁스 이미지를 구성하며, 이를 Hi-Z 맵이라고 합니다. 이 텍스처 맵은 밉 매핑된 화면 해상도 이미지로, 밉 레벨 i의 각 텍셀에는 밉 레벨 i-1에 해당하는 모든 텍셀의 최대 깊이가 포함됩니다. 이 뎁스 정보는 오클루딩 오브젝트에 대한 메인 렌더링 패스 중에 수집할 수 있으므로 동일한 해상도의 텍스처가 필요하므로 별도의 뎁스 패스가 필요하지 않습니다. 이 작업은 OpenGL 프레임버퍼 오브젝트를 사용하여 간단히 수행할 수 있습니다.
Hi-Z 맵을 구성한 후에는 오브젝트의 바운딩 볼륨의 깊이 값과 Hi-Z 맵에 저장된 깊이 정보를 비교하여 오클루전 컬링을 수행할 수 있습니다. 이 경우 특정 밉 레벨에서 직접 샘플링하여 텍스처 페치 횟수를 줄이면서 보수적인 깊이 비교를 수행할 수 있으므로 Hi-Z 맵의 계층적 밉 매핑 구조가 유용하게 사용됩니다.
이것이 바로 '최대 깊이 저장' 정책을 사용하여 Hi-Z 맵을 구축한 이유입니다. 이는 깊이 비교 함수가 GREATER 또는 GEQUAL인 일반적인 깊이 버퍼 설정에서 작동합니다. 역방향 뎁스 버퍼의 경우 '최소 뎁스 저장' 정책을 사용해야 합니다.
Hi-Z map construction
단일 샘플 렌더링의 경우, 장면 렌더링을 위한 기본 뎁스 버퍼로 Hi-Z 맵을 사용할 수 있습니다. 이 기술은 멀티샘플 렌더링으로도 확장되지만 이 경우 멀티샘플 뎁스 버퍼에서 각 개별 샘플의 최대 뎁스를 계산하여 단일 샘플링된 Hi-Z 맵에 저장하려면 별도의 전체 화면 쿼드 패스가 필요합니다. 이는 OpenGL 3.2부터 또는 확장 기능인 ARB_texture_multisample을 사용하면 가능합니다. 이 추가 단계 외에 알고리즘은 동일하게 유지됩니다.
이전 밉 레벨은 입력 텍스처로, 현재 밉 레벨은 렌더 타깃으로 바인딩되는 각 밉 레벨에 대해 전체 화면 쿼드 패스를 렌더링하여 OpenGL 프레임버퍼 오브젝트를 사용하여 Hi-Z 맵을 구성할 수 있습니다. OpenGL은 읽기와 쓰기 모두 동일한 밉 레벨에 액세스하지 않는 한 동일한 텍스처 오브젝트에서 렌더링할 수 있으므로 알고리즘은 다음과 같이 간단합니다:
// bind depth texture
glBindTexture(GL_TEXTURE_2D, depthTexture);
// calculate the number of mipmap levels for NPOT texture
int numLevels = 1 + (int)floorf(log2f(fmaxf(SCREEN_WIDTH, SCREEN_HEIGHT)));
int currentWidth = SCREEN_WIDTH;
int currentHeight = SCREEN_HEIGHT;
for (int i=1; i<numLevels; i++) {
// calculate next viewport size
currentWidth /= 2;
currentHeight /= 2;
// ensure that the viewport size is always at least 1x1
currentWidth = currentWidth > 0 ? currentWidth : 1;
currentHeight = currentHeight > 0 ? currentHeight : 1;
glViewport(0, 0, currentWidth, currentHeight);
// bind next level for rendering but first restrict fetches only to previous level
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_BASE_LEVEL, i-1);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAX_LEVEL, i-1);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT,
GL_TEXTURE_2D, depthTexture, i);
// draw full-screen quad
............
}
// reset mipmap level range for the depth image
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_BASE_LEVEL, 0);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAX_LEVEL, numLevels-1);반올림 문제로 인해 2의 거듭제곱이 아닌 텍스처의 경우 뷰포트 크기가 항상 최소 1×1이 되도록 하는 단계를 잊지 않는 것이 매우 중요합니다. 저는 이 단계를 깜빡하고 마지막 밉 레벨이 채워지지 않아 한 시간 동안 고민했습니다.
전체 화면 쿼드 패스를 수없이 반복하는 이 기술이 어떻게 효율적일 수 있는지 의아해할 수도 있지만, 실제로는 매우 효율적이며 0.2밀리초 이내에 제 Radeon HD5770에서 Hi-Z 맵을 구성합니다. OpenGL 타이머 쿼리를 사용하여 측정했기 때문에 상당히 정확할 것입니다(확장자 ARB_timer_query 참조).
Hi-Z 맵 구성에 사용되는 조각 셰이더는 한 가지를 제외하고는 매우 간단합니다. 창의 종횡비 때문에 NPOT 깊이 텍스처를 사용하며, NPOT 텍스처는 "바닥" 규칙을 사용하여 후속 밉 레벨의 크기를 결정하므로(확장자 ARB_texture_non_power_of_two 참조) 홀수 크기의 밉 레벨에서 축소하는 경우 에지 텍셀을 잊지 않도록 예측된 페치가 필요하기 때문입니다:
#version 400 core
uniform sampler2D LastMip;
uniform ivec2 LastMipSize;
in vec2 TexCoord;
void main(void) {
vec4 texels;
texels.x = texture(LastMip, TexCoord).x;
texels.y = textureOffset(LastMip, TexCoord, ivec2(-1, 0)).x;
texels.z = textureOffset(LastMip, TexCoord, ivec2(-1,-1)).x;
texels.w = textureOffset(LastMip, TexCoord, ivec2( 0,-1)).x;
float maxZ = max(max(texels.x, texels.y), max(texels.z, texels.w));
vec3 extra;
// if we are reducing an odd-width texture then fetch the edge texels
if (((LastMipSize.x & 1) != 0) && (int(gl_FragCoord.x) == LastMipSize.x-3)) {
// if both edges are odd, fetch the top-left corner texel
if (((LastMipSize.y & 1) != 0) && (int(gl_FragCoord.y) == LastMipSize.y-3)) {
extra.z = textureOffset(LastMip, TexCoord, ivec2(1, 1)).x;
maxZ = max(maxZ, extra.z);
}
extra.x = textureOffset(LastMip, TexCoord, ivec2(1, 0)).x;
extra.y = textureOffset(LastMip, TexCoord, ivec2(1, -1)).x;
maxZ = max(maxZ, max(extra.x, extra.y));
} else
// if we are reducing an odd-height texture then fetch the edge texels
if (((LastMipSize.y & 1) != 0) && (int(gl_FragCoord.y) == LastMipSize.y-3)) {
extra.x = textureOffset(LastMip, TexCoord, ivec2( 0, 1)).x;
extra.y = textureOffset(LastMip, TexCoord, ivec2(-1, 1)).x;
maxZ = max(maxZ, max(extra.x, extra.y));
}
gl_FragDepth = maxZ;
}텍스처 수집 룩업을 사용하여 텍스처 페치 횟수를 조각당 4~7회에서 1~3회로 줄이는 실험을 해봤는데(확장자 ARB_texture_gather 참조), 이미지가 선형적으로 샘플링되는 경우에만 텍스처 수집이 작동하고 렌더링 중에 필터링 상태를 전환해야 하는 추가적인 부담을 피하기 위해 단순한 텍스처 룩업을 사용해도 Hi-Z 맵의 구성 시간에 눈에 보이는 효과가 나타나지 않아서 텍스처 수집 룩업을 고수하기로 결정했습니다.

마운틴 데모에는 디버깅 및 데모 목적으로 Hi-Z 맵의 다양한 밉 레벨의 콘텐츠를 표시하는 기능이 내장되어 있습니다. 이 기능은 Hi-Z 맵 기반 오클루전 컬링이 활성화된 상태에서 F2 키를 누르면 사용할 수 있습니다. 키 + 및 -를 사용하여 밉 레벨을 전환할 수 있습니다.
뎁스 버퍼의 뎁스 정보를 더 잘 시각화하기 위해 [GeeXLab] GLSL에서 뎁스 버퍼를 시각화하는 방법에 제시된 대로 뎁스 텍스처에 저장된 비선형 뎁스 값을 선형 뎁스 값으로 변환했습니다.
Culling with the Hi-Z map
Hi-Z 맵을 구성한 후에는 가시성을 결정해야 하는 오브젝트의 바운딩 볼륨이 차지하는 화면 영역에 해당하는 2×2 텍셀 이웃을 가져와서 실제 오클루전 컬링을 수행할 수 있습니다. 데모에서는 바운딩 박스를 사용했지만 다른 바운딩 볼륨도 사용할 수 있습니다(예: 바운딩 구체는 일반적으로 이 기술에 충분히 정확합니다).
먼저 바운딩 볼륨의 클립 공간 바운딩 사각형을 계산해야 합니다. 바운딩 박스의 경우 바운딩 박스 정점을 클립 공간으로 변환한 다음 최소 및 최대 X와 Y 좌표를 계산하면 됩니다. 이 바운딩 사각형은 두 가지 용도로 사용됩니다. Hi-Z 맵 룩업에 사용할 텍스처 좌표를 정의하고 텍스처 룩업에 적합한 LOD를 결정하는 데 도움이 됩니다.
가져올 텍스처 LOD를 결정하려면 앞서 결정한 클립 공간 경계 사각형에 해당하는 경계 사각형의 화면 공간 크기를 계산해야 합니다. 클립 공간에서 경계 사각형의 너비와 높이를 계산한 다음 이를 화면 공간으로 변환하면 간단히 수행할 수 있습니다:
float ViewSizeX = (BoundingRect[1].x-BoundingRect[0].x) * Transform.Viewport.y;
float ViewSizeY = (BoundingRect[1].y-BoundingRect[0].y) * Transform.Viewport.z;그 후 다음 공식을 사용하여 텍스처 LOD를 간단히 계산할 수 있습니다:
float LOD = ceil(log2(max(ViewSizeX, ViewSizeY) / 2.0));마지막으로 텍스처 좌표(클립 공간 경계 사각형의 꼭지점)와 텍스처 LOD가 있으므로 이 매개 변수를 사용하여 Hi-Z 맵에서 4개의 텍스처 룩업을 만들고, 반환된 4개의 깊이 값 중 최대값을 계산하여 오브젝트에 해당하는 깊이 값(바운딩 박스의 클립 공간 좌표에서도 나오는 오브젝트의 가장 앞쪽 점의 깊이 값)과 비교하기만 하면 됩니다. 오브젝트 깊이가 참조 깊이보다 크면 오브젝트가 가려지므로 평소와 같이 지오메트리 셰이더에 의해 컬링됩니다.
참조 깊이 값을 계산할 때 2×2 텍셀 풋프린트를 사용하는 이유는 다음 밉 레벨을 한 번만 가져오면 되지 않느냐고 질문할 수 있습니다(Hi-Z 맵 구성 방식으로 인해 2×2 텍셀 풋프린트의 최대값도 얻을 수 있기 때문입니다). 저도 처음에 의문이 들었지만 곧 그 이유를 알아냈습니다(아래 그림 참조).
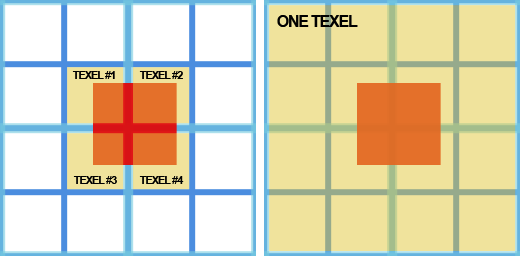
텍셀이 4개인 경우 텍스처 LOD를 결정하는 것이 훨씬 쉬울 뿐만 아니라 실제 오브젝트 경계 사각형을 더 잘 포괄할 수 있습니다. 하나의 텍스처를 가져오는 경우 텍스처 LOD 계산이 더 복잡하고 비용이 많이 들지만 가장 큰 문제는 더 큰 LOD를 가져와야 하며 항상 4개의 가져온 값에 1을 더한 값으로 결정되는 것이 아니라는 점입니다. 가장 극단적인 상황(경계 사각형이 화면 중앙에 있는 경우)에서는 가장 큰 LOD를 가져와야 할 수도 있습니다. 이 경우 잘못된 컬링이 발생하지는 않지만 컬링의 효율성이 심각하게 저하됩니다.
물론 더 복잡한 화면 공간 경계 폴리곤과 더 많은 페치를 사용할 수도 있지만, 추가 부담과 작업 비용에 비해 컬링의 효과는 훨씬 떨어집니다.
Conclusion
오클루전 쿼리를 사용하여 기존의 하드웨어 오클루전 컬링이 어떻게 작동하는지 살펴봤습니다. 또한 때로는 CPU 개입 없이 많은 양의 오브젝트에 대해 오클루전 컬링을 수행하는 더 나은 알고리즘이 필요하다는 점을 논의했습니다.
이 글에서는 계층적-Z 맵과 지오메트리 셰이더를 사용하여 이러한 오클루전 컬링 알고리즘을 구현하는 방법도 설명했습니다. 또한 데모에 대한 주요 기사 끝에 있는 링크를 사용하여 전체 소스 코드와 함께 다운로드할 수 있는 마운틴이라는 데모 형태의 참조 구현을 제공했습니다.
이 알고리즘은 현재 하드웨어에서 실제로 매우 잘 작동합니다. Hi-Z 맵 구성은 0.2밀리초도 채 걸리지 않으며 실제 컬링은 수천 개의 오브젝트에서도 거의 비용이 들지 않습니다. 계층형-Z 맵 기반 오클루전 컬링을 사용한 렌더링과 사용하지 않은 렌더링의 성능 비교에 대한 자세한 내용은 OpenGL 4.0 마운틴 데모에 대한 문서를 참조하세요.
데모에서는 동일한 오브젝트의 인스턴스를 컬링하는 데에만 이 기술을 사용하지만, 실제 컬링 알고리즘은 오브젝트 단위로 작동하고 실제 지오메트리 렌더링에 사용되는 방법과는 전혀 무관하므로 이 기술은 이기종 오브젝트 집합에 적용하도록 쉽게 확장할 수 있습니다.
이 기술은 완전한 GPU 기반 가시성 결정 및 장면 관리 시스템을 향한 다음 단계로 생각할 수 있습니다.
이 작업에 영감을 준 제레미 쇼프, 조슈아 바르작, 크리스토퍼 오트, 나탈리아 타타르추크와 그들의 SIGGRAPH 2008 강의 노트에 감사를 표합니다.
원문
Hierarchical-Z map based occlusion culling – RasterGrid
DISCLAIMER: This article was migrated from the legacy personal technical blog originally hosted here, and thus may contain formatting and content differences compared to the original post. Additionally, it likely contains technical inaccuracies, opinions t
www.rastergrid.com
엮인 글
[번역]천애명월도 모바일 게임 엔진 책임자: 최고 수준의 그래픽을 구현하기 위해 해결한 과제는
역자의 말. 최근... 아니 사실 거의 10년 전부터 텐센트 북극광의 엔지니어링 기술은 일본을 제외 하고는 아시아에서 원탑에 속하고 있었습니다. 워낙 국내에서 중국에 관심이 없을 시절 그러니
techartnomad.tistory.com
[번역]Engine architecture overview
2023.07.14 - [GRAPHICS PROGRAMMING] - [번역]GPU DRIVEN RENDERING OVERVIE [번역]GPU DRIVEN RENDERING OVERVIE GPU Driven Rendering Overview Practical guide to vulkan graphics programming vkguide.dev GPU Driven Rendering GPU Driven Rendering Overview 튜
techartnomad.tistory.com
[번역]GPU DRIVEN RENDERING OVERVIE
GPU Driven Rendering OverviewPractical guide to vulkan graphics programmingvkguide.devGPU Driven RenderingGPU Driven Rendering Overview튜토리얼 코드 베이스, 메인 뷰 및 셰도우 뷰에서 처리 및 제거된 객체 수는 125,000개이며, FP
techartnomad.tistory.com
[번역]Efficient GPU Rendering for Dynamic Instances in Game Development
역자의 말. 아트디렉터 경험부터 테크니컬 아티스트 경험까지 다양한 경험을 갖고 있는 Kacper Szwajka 의 흥미롭고 실험적인 두 개의 토픽을 소개 하려고 합니다. 원문. Efficient GPU Rendering for Dynamic I
techartnomad.tistory.com