
5년 전 쯤에 중국 게임개발사에서는 디퍼드 렌더링을 모바일에 접목하기 보다는 포워드 렌더링 기반에서 아티스트의 수요 즉 Many lights 라는 문제를 해결 하는것에 집중이 되어있었습니다.
당시에는 클러스터드 기반의 포워드 플러스 렌더링이 유니티에 없었기 때문에.... 대부분 직접 구현을 했었구요.
거인 네트워크. 신동 네트워크. 퍼펙트 월드 등등... 텐센트는 물론이구요.
아래 기사는 제가 중국에 있을 때 깊이 Z 에 대한 클러스터링 데이터를 어떻게 공간 셀을 형성하고 TBDR 의 2차원 타일 환경에서 라이트 인덱스를 관리 했었는지 간략히 소개하고 있습니다.
2019년 10월.
아래 글은 오래전 중국어로 작성 된 토픽을 다시 한국어로 바꾼거에요. ㅜㅜ

본 기사는 해결 된 문제, 실현 원리, 실천의 세 부분으로 나뉜다.
문제 해결
조명을 할당하는 방법.
다시 말해, 조각 셰이더가 조명 계산을 수행 할 때 어떤 조명을 계산해야하는지 어떻게 알 수 있습니까?
앞으로
전통적인 포워드 렌더링에서 계산해야 할 빛은 빛으로 그릴 각 객체를 판단하여 얻습니다. 그러나 이러한 종류의 개체 별 조명 자르기는 두 가지 문제를 일으 킵니다.
- 큰 물체는 작은 빛의 영향을 받고, N 램프의 계산을 위해 빛의 영향을받지 않더라도 물체의 모든 요소를 계산해야하므로 중복 계산이 발생합니다. (보통 우리는 가능한 한 많은 객체를 그려야하므로 종종이 중복성을 증가시킵니다)
- 많은 작은 물체는 하나의 헤드 라이트에 영향을받으며 많은 교차 작업이 필요합니다. 배광은 장면 복잡성과 관련이 있습니다.

조명 수가 적을 때는 이러한 문제가 명확하지 않으므로 장면의 최대 조명 수가 LWRP에서 제한됩니다. 더 많은 조명 효과를 원하면 심각한 성능 문제가 발생할 수 있습니다.
지연렌더링.
지연 렌더링에서, 빛의 분포는 각 빛을 래스터 화하여 타일이 빛의 영향을 받도록하고 타일에서 조명 계산을 수행합니다.
이 가벼운 자르기 방법의 장점은 장면의 복잡성과 무관하며 중복 계산이 없다는 것입니다.
그러나 단점은 조명 계산을 수행 할 때마다 Gbuffer를 읽고 써야하므로 빛이 많을 때 많은 대역폭 압력이 발생한다는 것입니다 . 그리고 대역폭은 점차 휴대 전화의 성능 병목 현상이되고 있습니다.

클러스터의 원리
지연렌더링은 조명처리를 위한 좋은 생각입니다. 화면 공간의 조명은 장면의 복잡성과 분리되어 중복 컴퓨팅 문제를 해결합니다.
대역폭 압력은 조명이 순회 될 때마다 GBuffer를 읽고 쓸 필요가 있기 때문에 발생합니다 순회 순서를 수정하고 프래그먼트의 빛을 순회 하는 경우 아래와 같이 GBuffer를 한 번만 읽고 쓸 수 있습니다.

따라서 초기 질문으로 돌아가서 각 칩에 대해 어떤 조명을 계산해야하는지, 무례한 관행을 어떻게 알 수 있습니까?
- 라이트 클리핑을 사용하지 말고 모든 라이트를 사용하십시오. (계산 중복성, 성능 저하)
- 라이트리스트를 픽셀 단위로 저장하십시오. (배광 계산이 너무 복잡하고 저장 메모리가 높음)
인접한 픽셀들이 동일한 광에 의해 영향을 받기 쉽기 때문에, 픽셀 그룹에 접근하는 방법이 제안되었다. 자르기는 그룹에 따라 그룹화되어 그룹에 영향을주는 라이트 목록을 가져 오며 클립은 그룹의 라이트 목록을 사용하여 조명 계산을 수행합니다.
클러스터
군집은 XYZ의 3 차원으로보기 원뿔을 그룹화 한 것으로 각 군은 1 군집입니다.

각 클러스터는 조명과 교차하여 그룹에 영향을주는 조명 목록을 얻습니다. 단편에서, 조명 계산은 클러스터가 위치한 클러스터에 따라 수행됩니다.
클러스터 조명 분포는 지연 렌더링뿐만 아니라 정방향 렌더링에도 적합합니다.
라이트리스트 저장 구조
각 클러스터 절단 후 얻은 조명 목록을 어떻게 저장합니까?
3 층 구조

- 라이트리스트는 모든 라이팅 데이터를 저장합니다
- Light Index List는 각 클러스터의 조명 인덱스를 저장합니다
- Light Grid는 Light Index List에 각 클러스터의 시작과 끝을 저장합니다
2 층 구조
- 라이트리스트는 모든 라이팅 데이터를 저장합니다
- Light Grid는 각 클러스터의 조명 및 인덱스 수를 저장합니다 (고정 길이 스토리지, 특정 공간이 낭비 됨)
구조 선택
3 계층 구조에는 공간 낭비가 없지만 샘플링이 하나 더 있습니다.
다음은 라이트리스트 저장을위한 2 계층 구조입니다.
실습
Unity의 LWRP 렌더링 파이프 라인은 사용자 정의가 가능하고 수정하기 쉽습니다. 다음은 LWRP의 포워드 렌더링에 클러스터 조명 분배 체계를 추가하여 여러 동적 조명을 지원하는 방법을 설명합니다. 주로 다음 단계로 나뉩니다.
1. 프로젝트 별 기본 기본 개체 별 광원 자르기를 끄고 기본 광원 설정을 취소하십시오.
2. Cluster Light Distribution Scheme을 사용하여 각 클러스터의 조명 목록을 가져옵니다.
3. 조각 조명 계산에서 클러스터가 위치한 클러스터를 계산하고 조명 계산을위한 조명 목록을 가져옵니다.
1과 3은 주로 조명 분포에 대해 말할 것이 없습니다.
GPU 조명 분배
먼저 Compute Shader로 계산해보십시오. 각 클러스터는 하나의 스레드에 해당하며 조명은 병렬로 절단됩니다.
각 클러스터는 모든 조명과 교차하여 영향을받는 조명 목록을 가져 오는 작은 육면체입니다.
테스트를 통해 Compute Shader 조명 할당의 오버 헤드가 높지 않아이 부분에 대한 과도한 최적화가없는 것으로 나타났습니다. 주요 성능 오버 헤드는 조명이 많은 경우 조명 계산에 있으며 조명 모델을 단순화하여 계산이 개선되었습니다 (PBR 대신 Lambert 사용). 효율성.

StructBuffer 대 텍스처
라이트리스트 정보를 저장할 때 StruttBuffer와 Textrue는 각각 성능을 테스트하는 데 사용되며, 결과적으로 Texture를 사용하면 성능이 향상됩니다.
또한 휴대폰은 Texture를 더 잘 지원하며 일부 휴대폰은 StructBuffer를 잘 지원하지 않습니다.
GPU 솔루션 테스트 요약
GPU 조명 분배 체계의 성능 병목 현상은 GPU에 있으며 다음과 같은 측면에서 성능을 향상시킬 수 있습니다.
- 기본이 아닌 소스의 조명 계산 복잡성을 단순화합니다.
- 데이터 읽기 및 쓰기에 텍스처를 사용하십시오.
- 클러스터 절단 점수를 적절하게 증가시켜 절단 정확도를 높이고 조명 계산 중복성을 줄입니다.
발생한 문제
- Compute Shader의 numthreads (그룹 스레드)는 가능한 크고 빠릅니다 (하나의 설명은 하드웨어에 최소 스레드 수가 있다는 것입니다.이 수보다 낮은 경우 GPU를 완전히 사용할 수 없습니다. 다른 그룹에있는 스레드가 많을수록 더 많은 메모리 히트가 발생합니다. 높음).
- Huawei Mali의 GPU 성능이 약하고 (권장 CPU 솔루션) Compute Shader에서 numthreads가 지원하는 최대 X * Y * Z가 더 낮습니다 Mali-G76에서는 32 * 16 = 512가 지원되지 않습니다 (Qualcomm의 GPU는 모두 지원됨). 지원), 16 * 8 = 128 수 있습니다.
- 장치가 CS (OpenGL ES 3.1)를 지원하는지 여부 및 Float 유형 텍스처 형식 (Huawei Mate7에서 지원되지 않음)을 지원하는지 확인합니다.
- GPU의 성능을 테스트 할 때는 GPU 하단의 셰이더 계산 최적화에주의를 기울여야합니다 (예 : 반복 계산 또는 사용되지 않은 계산이 최적화 됨). CPU에서 작성한 코드가 실행되는 동안에는 그렇지 않습니다. 잘못된 결론은 시험 방향에 영향을 미칩니다.
CPU 배광
Light Distribution 계산에 멀티 스레딩을 사용하는 경우 Unity의 Job 시스템이 사용되며 Burst 컴파일러는 성능을 향상시키는 데 사용됩니다.
작업 시스템은 다중 스레드 작업을 캡슐화하며 실행 큐에 작업 (작업) 만 추가하면되며 엔진은 예약, 리소스 경합 처리 및 다중 스레드 할당을 담당합니다.
버스트 컴파일러는 c # 코드를 대상 플랫폼에 최적화 된 기계 코드로 변환합니다. 그러나 작업에서 관리되는 힙 메모리를 할당 할 수 없습니다.
알고리즘 최적화
CPU 배광에서의 성능 병목 현상이 배광 알고리즘이므로 많은 최적화 시도가 이루어졌습니다.
- 클러스터 컷 수를 32 * 16 * 32에서 16 * 8 * 32로 줄입니다. 성능은 향상되었지만 절삭 정밀도의 희생으로 인해 GPU 성능이 향상되는 경우가 있습니다.
- 교차로 알고리즘 단순화 : 교차로 계산을 위해 육면체 대신 구형 바운딩 박스를 사용하는 것도 절단 성능을 희생시켜 특정 성능을 향상시키는 아이디어입니다.
- 계산을 위해 여러 클러스터를 결합하고, 조명 순회 수를 줄이고, 거친 컬링을 통해 알고리즘의 효율성을 개선하면 성능 개선 효과가 분명합니다.
요약 : 1과 2는 모두 절단 정확도를 희생하고 CPU 압력을 줄이며 때로는 GPU 압력을 높이므로 적절하게 사용할 수 있습니다. 병합 된 클러스터의 대략적인 컬링은 성능 향상에 이상적입니다.
발생한 문제
- 데이터 경쟁을 방지하기 위해 JobSystem은 Blittable 유형 데이터에만 액세스 할 수 있습니다 (IJobParallel은 NativeArray에 데이터 쓰기 제한) 데이터 구조는 struct 만 사용할 수 있습니다. 데이터의 양이 많으면 struct copy는 큰 성능 오버 헤드를 생성하고 멤버 변수에 직접 액세스합니다. 데이터 복사를 줄이는 방법이지만 코드를 잘 읽을 수 없습니다.
- NativeArray는 매우 느리게 읽기 때문에 배열로 변환하면 성능이 크게 향상 될 수 있습니다.
요약
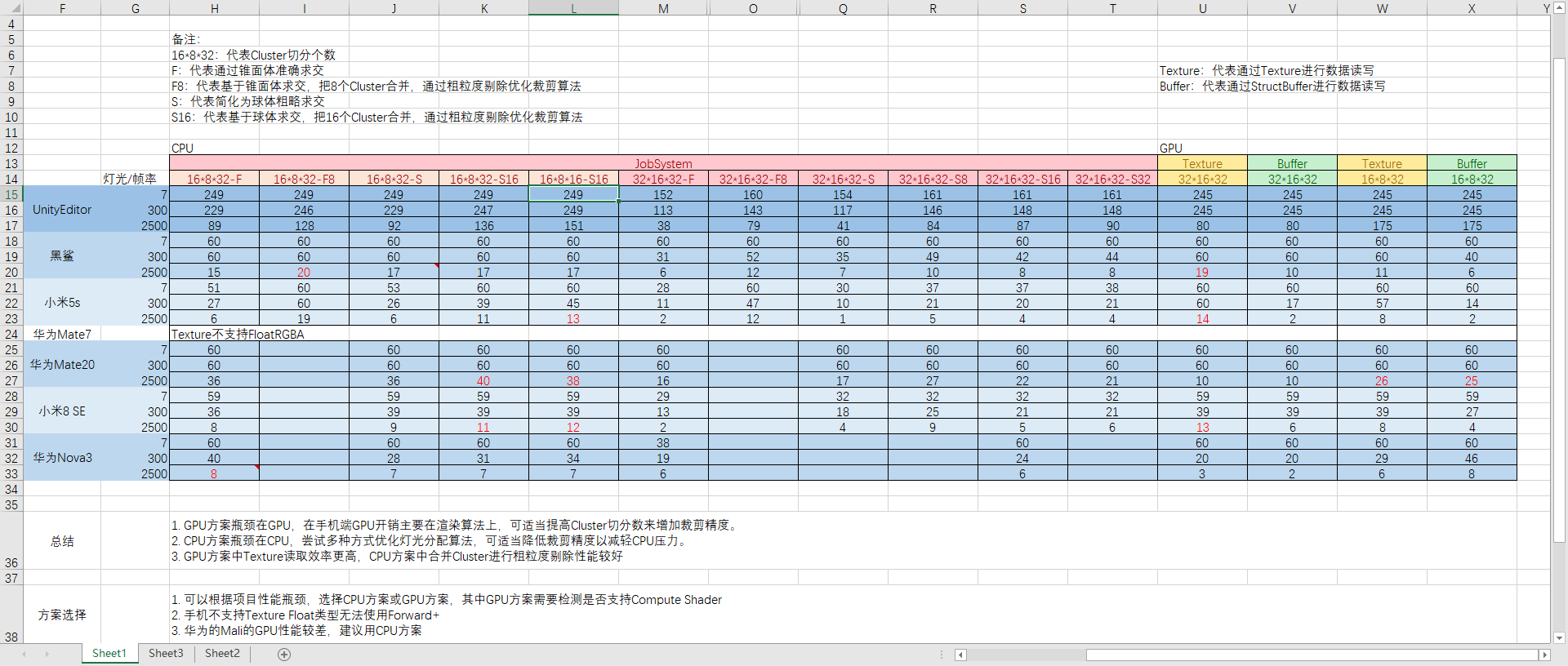
- 조명 분배 방식을 선택할 때 프로젝트의 성능 병목 현상에 따라 CPU 방식 또는 GPU 방식을 선택할 수 있습니다 (Huawei Mali의 GPU 성능이 저하되고 CPU 방식이 권장 됨).
- 라이트 데이터 읽기에서 텍스처를 사용하십시오.
- 조명 계산에서 조명 모델을 단순화하십시오.
휴대폰 테스트 엑셀 테이블.
디버그 패널
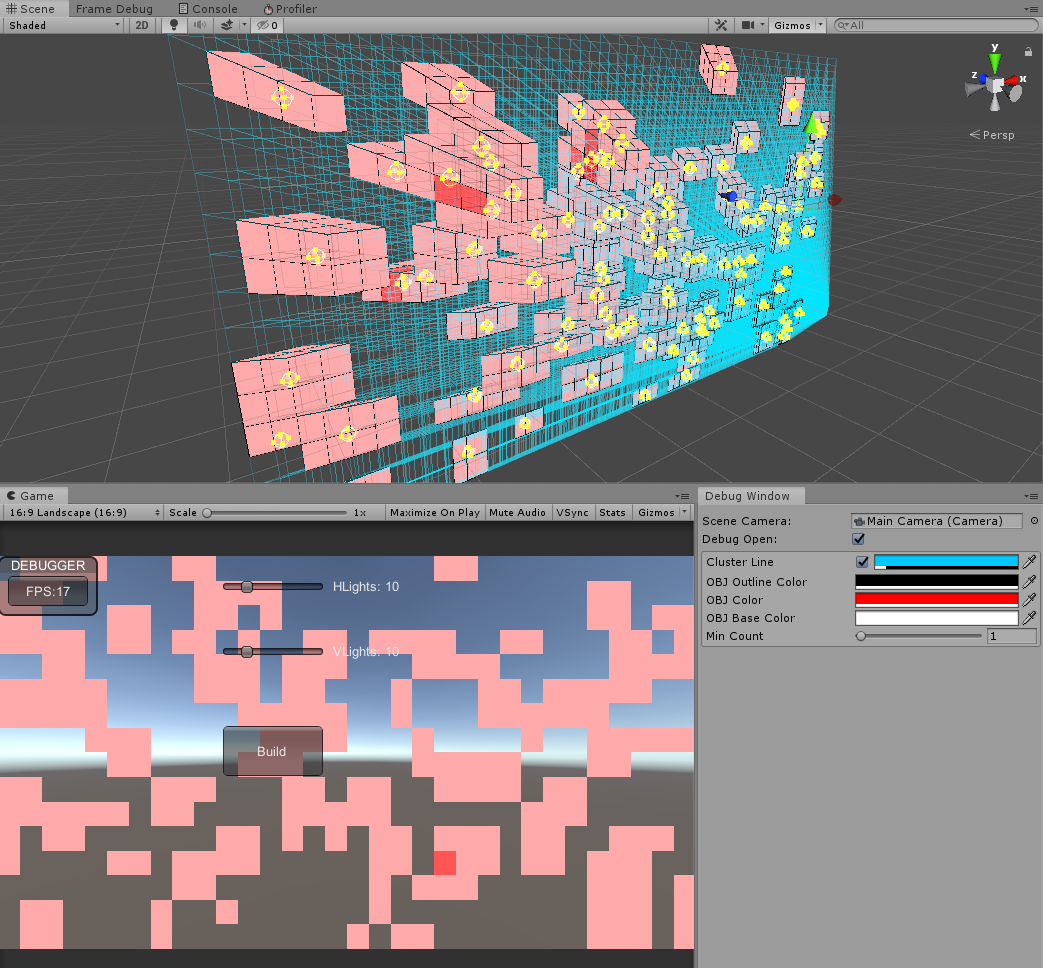
- 클러스터 자르기 결과를 시각화하고 클러스터의 조명 수에 색상을 지정합니다.
- 클러스터에 해당하는 그리드를 클릭하여 조명 정보를 표시하십시오.
추가
- 빛이 일정하면 다시 계산되지 않습니다.
- 3 층 구조는 라이트 목록을 저장하여 메모리 사용량을 줄이고 1 개의 샘플을 추가하며 성능을 테스트하는 데 사용됩니다.
'UNITY3D' 카테고리의 다른 글
| Custom Shadow Attenuation Tweak Example (0) | 2024.09.25 |
|---|---|
| Unity6 Adaptive Light Probe Debugmode. (0) | 2024.09.24 |
| RCAS ( Robust Contrast-Adaptive Sharpening ) (0) | 2024.09.20 |
| Unity Rendering Graph System. (2) | 2024.09.18 |
| [UNITY6] For GPU Driven Rendering. BRG | GRD (0) | 2024.08.27 |