
역자의 말. 대학을 막 졸업(CS)한 루키분들과 테크아트 쪽 관련 업무를 추진 하다보면 셰이더 컴파일 관련 해서 미처 생각하지 않던 부분들이 있다는 것을 깨닫고 몇 가지 내용에 대해서 이야기 해 주다가.... 간략하게 도입하는데 있어 편히 읽어 볼 만한 기사를 발견 했어요. 2010년 부터 2016년 까지만 해도 컴파일러를 통해 IPC 를 확인 해 가면서 작업 해 왔던 저로서는 지금의 환경 그러니까... 예로 들어...POW 를 아무렇게나 쓰면 안되는 시대있다가.. 큰 무리 없는 시대(하드웨어 급속 발전과 캄파일러 개선) 가 되긴 했는데...그래도 몰라도 되는게 몰라도 되는게 아니지만 정말 무관심하게 최적화 하고 학부 졸업 하는 4년 동안 대학에서 이런거 절대 접하지 않는구나 라는 생각을 하게 되었어요. 아무튼... 한번 읽어볼만 한 기사 입니다.
이 기사와 엮어 보기.
https://techartnomad.tistory.com/219
[최적화]IPC with GPU.
작성자의 회고 : 2015년 PC 기반의 OPENWORLD MMORPG 개발을 담당하다가 2016년 다시 모바일 MMORPG 까지 담당하게 되었을 때로 기억 되는데요... 셰이더 최적화 메서드 중에서 가장 기초가 되는 부분을 살
techartnomad.tistory.com
저자: Luna
도입
최근 셰이더 최적화에 대한 몇 가지 조언이 공유되는 것을 보았는데, 의도는 좋았지만 정확하지 않았습니다.이 글에서는 셰이더 최적화와 관련된 몇 가지 잘못된 상식을 바로잡고자 합니다.특히 언리얼 엔진 내 머티리얼 에디터와 관련된 몇 가지 잘못된 상식을 바로잡고자 합니다.
*이 정보는 기술적으로 나이아가라에 일부 적용되지만, 나이아가라가 컴퓨팅 셰이더를 생성하기 때문입니다.
이 문서 정보
저는 전문가가 아니며 수년에 걸쳐 수집한 정보로, 의도적으로 단순화했습니다.의미론적 용어 사용 등 일부 정보가 누락되어 있고 복잡한 주제입니다.모든 분들이 친근한 태도로 토론에 참여해 주실 것을 공개적으로 초대합니다.
Material Editor
먼저 머티리얼 에디터가 실제로 무엇인지 이해해야 합니다.머티리얼 에디터는 간단히 말해 노드 그래프와 일부 메타데이터(블렌드 모드 등)가노드 그래프와 일부 메타데이터(블렌드 모드 등)를 사용하여 여러 셰이더를 생성하는 도구로, 모두 깔끔한 작은 에셋인 머티리얼에 저장됩니다.
그래프의 각 원자(녹색) 노드는 컴파일러에 어떤 코드를 생성할지 지시합니다.
역자 주: 노드 기반 에디터에서 기본 노드를 통상 atomic node 라고 하는데요. 번역하면 원자? 인데 사실 기본 노드 정도라고 이해 하면 맞습니다.
(이 경우 HLSL)를 생성하도록 컴파일러에 지시하며, 마지막에는 다음과 같이 됩니다.(사용 플래그와 도메인 유형에 따라 다르지만 보통은를 사용하면 하나의 머티리얼에 여러 개의 버텍스 셰이더와 픽셀 셰이더가 있습니다.
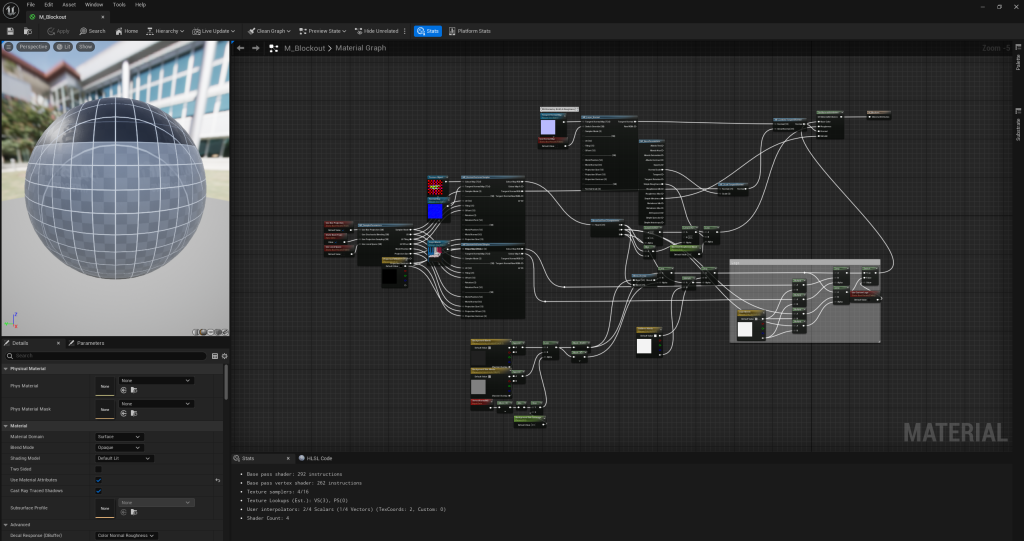
생성된 셰이더 코드
생성된 중간 HLSL 코드는 창 > 셰이더 코드 > HLSL 코드에서 볼 수 있습니다.여기에서 생성된 플랫폼별 코드도 볼 수 있습니다.- 이 코드는 HLSL일 수도 있고 GLSL로 변환될 수도 있습니다(예: Android).

템플릿화된 코드가 많이 보일 것입니다(MaterialTemplate.usf) - 컴파일러가 마지막에 필요 없는 것을 제거하므로 놀라지 마세요.
Material Instances
머티리얼 인스턴스는 전통적인 머티리얼 개념(즉, 주어진 셰이더 세트의 파라미터를 포함하는 패키지)과 클래스 상속을 결합한 개념입니다.Unity의 정의처럼 특정 셰이더 세트에 대한 모든 파라미터를 포함하는 패키지)와 클래스 상속을 결합한 개념입니다.흥미로운 개념이며 기본적으로 이 모든 것이 의미하는 바는 다음과 같습니다.서로 상속할 수 있는 머티리얼 인스턴스의 부모-자식 하이리치를 가질 수 있다는 뜻입니다.
하지만 머티리얼 인스턴스가 사용하는 셰이더를머티리얼 인스턴스가 사용하는 셰이더는 머티리얼 프로퍼티 오버라이드(즉.블렌드 모드, 양면 오버라이드 등), 머티리얼 레이어 및 스태틱 파라미터를 재정의할 수 있습니다.
랜드스케이프 머티리얼은 완전히 다른 토끼굴이므로 여기서는 다루지 않겠습니다.
셰이더 최적화
인스트럭션 카운트
인스트럭션 카운트는 기본적으로 두 가지를 알려줍니다.
셰이더의 메모리(및 디스크) 크기 - 인스트럭션이 많을수록 더 많은 메모리셰이더가 소비하는 메모리
잠재적으로 셰이더가 얼마나 느린지 매우 높은 수준에서 볼 수 있습니다..(계속 읽어보세요)
언리얼은 머티리얼이 생성하는 인스트럭션 수에 대한 몇 가지 통계를 제공합니다.머티리얼이 생성하는 인스트럭션 수에 대한 통계 정보를 제공하는데, 이 정보는 머티리얼이 생성하는 것을 처음 살펴볼 때 유용합니다.

문제는 앞서 제기한 것에서 비롯됩니다.이것은 생성된 중간 HLSL 코드를 기반으로 한 추정치입니다!따라서 이는 종종 부정확하며 매우 높은 수준의 뷰만 제공합니다.이 문제를 해결하기 위해 머티리얼 에디터의 플랫폼 통계 툴을 사용하면 다음과 같이 할 수 있습니다.해당 플랫폼에 대해 생성된 셰이더의 실제 인스트럭션 수(및 기타 통계)를 확인할 수 있습니다.이는 해당 플랫폼에 연결된 컴파일러를 사용하기 때문에 작동합니다.
이 보기는 매우 유용합니다.다른 사용 플래그에 대해 생성된 셰이더에 대해 조금 더 알 수 있습니다.예를 들어 스켈레탈 메시의 버텍스 셰이더는 스태틱 메시보다 훨씬 무거워질 것입니다!

Static Parameters
이에 대해 이야기하기 전에 정적 파라미터에 대해 이야기해 보겠습니다!엔진 코드 내부에서는 정적 파라미터를 가리키지만, 본질적으로 우리가 말하는 것은 다음과 같습니다.
베이스 프로퍼티 오버라이드(블렌드 모드, 셰이딩 모델, 양면 등).)
머티리얼 레이어
스태틱 스위치 및 스태틱 채널 마스크 매개변수(일반 채널 매개변수가 아닌 점만 있는제품)
랜드스케이프 레이어 - 각 랜드스케이프 프록시는 어떤 레이어를 칠하고 어떤 순서로 칠하는지에 따라 새로운 순열을 생성합니다.순서(제가 알기로는 프록시 간에 공유되지 않는 것으로 알고 있습니다,최근 버전에서 변경되지 않은 한)
이들은 머티리얼 인스턴스 내부에서 변경할 수 있는로, 머티리얼 인스턴스 내에서 변경할 수 있으며 순열을 더럽혀서 이 머티리얼에 대한 새 셰이더를 생성하게 됩니다.
이렇게 하면 컴파일 타임에 도입된 프로퍼티/리소스를 수용하기 위해 셰이더의 전체 복사본이 생성됩니다.프로퍼티/리소스를 수용하기 위해 셰이더의 전체 복사본을 생성하므로 더 많은 인스트럭션이 더 많은 셰이더 메모리를 사용하게 됩니다.
이전 버전에서는 정적 파라미터 오버라이드를 사용하는 것만으로도가 더럽혀지는 문제가 있었지만, 최신 버전에서는 이 문제가 해결된 것으로 보입니다.
Flags 사용
사용 플래그는 이 문제를 더욱 심화시킵니다(머티리얼의 모든 체크박스(를 설정하여 머티리얼을 렌더링할 수 있는 프리미티브 유형을 결정합니다.)이는 각 정적 파라미터가 각 사용 플래그에 대해 새로운 셰이더를 생성하기 때문입니다(일부 셰이더는 다행히도 공유되지만).
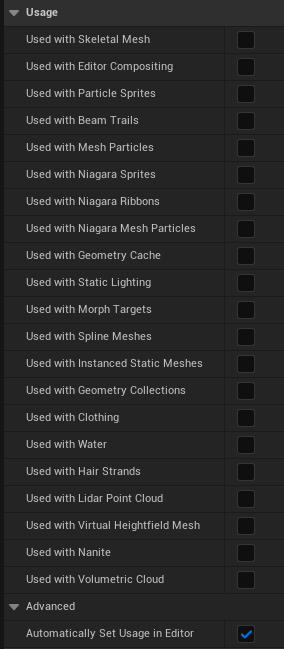
이 문제를 피하는 방법은 매우 간단합니다. 에디터에서 자동 사용 설정 비활성화를 비활성화하면, 에디터에서 머티리얼의 플래그를 자동으로 체크하는 기능을 비활성화합니다.머티리얼의 플래그를 자동으로 체크하는 기능을 비활성화합니다,머티리얼이 어디에 사용되는지 명시적으로 정의하는 것은 작성자에게 맡깁니다.
GPU Cycles
머티리얼의 성능에 인스트럭션의 수가 영향을 미친다는 것은 상식적인 사실일 것입니다.실행해야 하는 인스트럭션이 많을수록 셰이더의 실행 속도가 느려지겠죠? 사실 그렇지 않습니다.
모든 인스트럭션이 1을 생성하는 것은 아닙니다:생성하는 어셈블리에서 1:1이 아니며, 모든 인스트럭션이이 동일한 속도(GPU의 사이클 수)로 실행되는 것은 아닙니다.
안타깝게도 언리얼은 이를 보여주지 않으며, 컴파일러에 따라 다소 달라질 수 있습니다.하지만 약간의 실험과 HLSL에 대한 지식, 수학 지식, 그리고 무슨 일이 일어나고 있는지에 대한인스트럭션의 일반적인 출력과 그 주기를 파악할 수 있습니다.
인스트럭션의 어셈블리 및 GPU 주기를 확인하려면 shader-playground.timjones.io를 적극 추천합니다.저는 작업에 Radeon GPU 분석기를 사용합니다.

Examples
Radeon 컴파일러를 기반으로 제가 찾은 몇 가지 일반적인 지침은 다음과 같습니다.
| Instruction | Assembly | Cycles | Notes |
| * (operator) | mul | 4 | |
| + (operator) | add | 4 | |
| – (operator) | – | – | Seems to be free to flip a value to negative |
| / (operator) | mul, rcp | 20 | Compiled to multiply by reciprocal (16 cycles) |
| pow | exp | 16 | If constants are used this will vary into a string of muls |
| sqrt | sqrt | 16 | |
| sin | sin | 16 | |
| cos | cos | 16 | |
| tan | sin, mul, rcp, cos | 52 | Compiled to use identity of tan = sin/cos, where the divide is a mul rcp like a regular divide, making this one of the most expensive instructions! |
역자 주
저자의 정리 중에 IPC 내용을 좀 보강 해 보자면... ↡↡
버택스 스테이지

프라그먼트 또는 픽셀 스테이지

Distance Squared
이를 알면 캔에서 두 점 사이의 거리를 구하는 것이 다음과 같다는 것을 알 수 있습니다.거리가 델타 벡터의 길이에 불과하기 때문에 상당히 비용이 많이 드는 연산이라는 것을 알 수 있습니다!
AB == B – A, so distance(A, B) == length(AB)!
벡터의 길이를 구하는 것은 sqrt(x^2 + y^2+ z^2)(사용 중인 차원에 따라 스케일 조정, 여기서는 float3을 가정합니다)로 결정됩니다.
Fun Fact
피타고라스 정리에 익숙한 분들은 매우 낯익은 것을 보게 될 것입니다.여기서 이것은 사실 c = sqrt(a^2 +b^2)와 정확히 같기 때문입니다. 여기서 a와 b는 두 직교 모서리의 길이입니다,삼각형의 점 또는 벡터로 시각화할 수도 있습니다.
이 지식으로 거리/길이를 구하는 데만 약 28 사이클이 소요된다는 것을 알 수 있습니다!
| length(A) | sqrt(x^2 + y^2 + z^2) | sqrt, mul, mac, mac | 28 cycles |
이 문제를 제기하는 이유는 가능한 경우 거리 제곱을 사용하여 이를 최적화할 수 있기 때문입니다.즉, 거리 값을 비교할 때는 거리 제곱을 사용하면 됩니다!(일반 거리인 경우 비교 값을 제곱하면 됩니다.값)
만약 우리가 (부호 있는) 거리 필드를 만들거나를 루프에서 수행하는 경우 거리 제곱를 사용한 다음 결과를 제곱하면 되므로 한 번만 제곱하면 됩니다!
거리 제곱은 어떻게 구하나요?답변:도트 제품
C++ 코드에서도 옵션 최적화를 위해 많이 사용되는 것을 볼 수 있습니다.코드에서도 연산 최적화를 위해 많이 사용되므로 GPU에만 국한된 것이 아닙니다!
상수 최적화
간단히 말해, 컴파일러는 컴파일 시 상수와 관련된 연산을 평가합니다.상수와 관련된 연산(가능한 경우)을 컴파일 타임에 평가하여 매우 유용한 최적화를 제공합니다..
다음은 몇 가지 예시 표현식과 컴파일러에 의해 단순화되는 표현식입니다.
| Expression | Compiled To |
| (x + 0) * 1 | x |
| sin(0) | 0 (radians) |
일반적으로 저는 컴파일러를 이길려고 하지 말고표현식을 직접 재평가하는 것을 권장합니다 (저는 이렇게 하곤 했습니다).e.나누기를 곱하기 RCP로 바꾸기 - 컴파일러가 결정하고 열심히 일하도록 맡겨야 하기 때문입니다!
또한 코드/노드 그래프를 가독성 있고 이해하기 쉽게 유지합니다.
Custom Node
커스텀 노드 내부에서는 작동하지 않는다는 메모를 본 적이 있는데, 어셈블리가 생성될 때 최적화가 이루어지므로 언리얼의 통계 탭에 반드시 반영되지 않기 때문에 이는 사실이 아닙니다.
Example – Pow
이 글을 쓰게 된 계기가 된 예는 pow 명령어의 사용입니다.
상수 지수를 사용할 때 컴파일러는 이를 곱하기 명령어 문자열로 최적화합니다.명령어 문자열로 최적화합니다(그렇지 않으면 생성되는 exp 명령어보다 적은 주기).
즉, 상수 지수와 함께 pow 노드를 사용할 수 있고에 따라 비용이 결정됩니다(exp 명령어의 경우 최대 16사이클).
예를 들어 이 두 표현식은 2의 지수가 상수이므로 동일합니다.

| Expression | Compiled to | Cycles | Notes |
| pow(x, 2) | mul | 4 | |
| pow(x, 5) | mul, mul, mul | 12 | |
| pow(x, 16) | exp | 16 | Seems to hit the limit where exp is used |
| pow(x, 0.5) | sqrt | 16 | Reciprocal values (1/x) as exponents will produce the root |
Optimized broken by Varyings
컴파일 시점에 표현식을 평가할 수 없는 경우(약간의 수학 지식이 필요할 수 있음) 이 방법은 작동하지 않습니다.따라서 변수(파라미터, 텍스처 샘플, 리소스 등)를 평가할 수 없으므로 최적화할 수 없습니다.즉로 사용되는 변수는 최적화되지 않지만, 기본 인수인를 기본 인자로 사용하면 x^3을 x*x*x로 평가할 수 있기 때문에 최적화될 것입니다.
이를 활용하기
수학과 컴파일러에 대한 이해가 있다면 워크플로에서 이 최적화를 활용할 수 있습니다.특히 머티리얼 함수를 많이 사용하는 워크플로(제가 추천하는 워크플로)를 사용하는 경우 더욱 그렇습니다.
예를 들어 일반적인 UV 조작 함수를 작성할 수 있습니다.에는 기본적으로 최적화될 몇 가지 입력 값이 있습니다.기능을 추가하고 싶으신가요? 매개변수를 입력하기만 하면 됩니다! 스위치를 돌릴 필요가 없습니다!
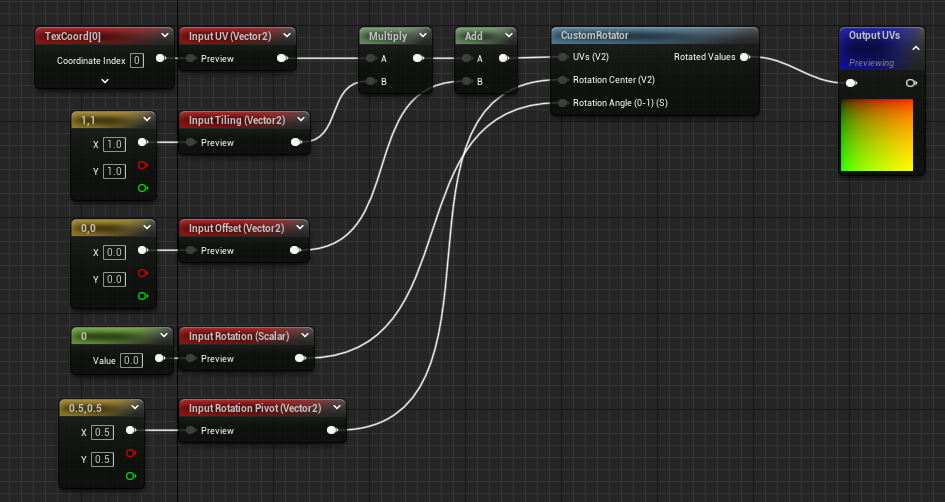
모든 곳에 적용할 수 있습니다!이러한 입력값이 변하지 않고 수학 연산이 상쇄된다는 것을 알고 있는 값을 사용한다면값을 사용하기만 하면 수학 연산이 상쇄될 수 있습니다!생성된 코드를 확인하시기만 하면 됩니다.
텍스처 샘플링 - 프리 페치(버텍스 보간기) 최적화(구형 하드웨어)
중요 참고 사항작성자
구형 하드웨어에서는 GPU가 수행하며 최적화하는 텍스처 샘플링(ES2.0) 픽셀(조각) 셰이더가 시작되기 전에 텍스처를 미리 가져오는데, 이를 프리페치라고 합니다.
*일반적으로 최신 하드웨어에서는 성능 저하가 거의 없는 것으로 알려져 있습니다.
텍스처 가져오기가 종속 텍스처 가져오기가 되면 이 최적화가 깨지는데, 여기서 텍스처의 샘플링이의 샘플링이 샘플을 시작하기 전에 실행해야 하는 일부 연산에 의존하므로 GPU가 사전 가져오기를 수행할 수 없습니다.
이는 다양한 상황에서 발생할 수 있습니다.
텍스처를 샘플링하는 데 사용된 UV를 어떤 형태로든 수정하는 경우(스와이즐도 종속 텍스처 읽기를 유발합니다)
텍스처 분기하기샘플 분기하기
다른 텍스처 샘플의 결과에 의존하는 텍스처 샘플링하기다른 텍스처 샘플의 결과
여기에 Apple의 자체 문서에서 설명되어 있습니다.
다른 텍스처 페치에 의존하기
종속 텍스처 페치는 종종 다른 상황과 혼동되는 경우가 있습니다(여전히 매우 종속적인 텍스처 페치입니다) 다른 텍스처 샘플의 결과를 사용하여 텍스처를 샘플링하는 경우(즉, 노이즈 텍스처를 사용하여 다른 텍스처의 UV를 왜곡하는 경우입니다.즉, 노이즈 텍스처를 사용하여 다른 텍스처의 UV를 왜곡하는 것입니다.)
하지만 이것은 여전히 종속 텍스처 페치이지만 유일한 정의는 아닙니다.
이 특정 상황에서도 최신 하드웨어에서 성능 저하가 발생할 수 있다고 들었습니다.퍼포먼스 페널티가 발생할 수 있다고 들었지만, 현재로서는 이에 대한 구체적인 정보가 없습니다.
버텍스 보간기 및 커스텀 UV
가장 일반적인 상황에서 종속적인 텍스처 페치를 피하기 위해UV를 수정하는 경우, 버텍스 셰이더에서 UV를 미리 계산하고버텍스 셰이더에서 UV를 미리 계산하고 새 UV를 픽셀 셰이더로 전달할 수 있습니다.내부적으로는 TEXCOORD 레지스터를 활용하지만, 하드웨어마다 사용 가능한 수에 대한 제한이 다릅니다.언리얼에서는 이를 사용자 보간기라고 합니다.
이를 위해 커스텀 UV라는 기능을 활용하거나, 더 최근의버텍스 보간기(몇 년 전 커스텀 UV 관리의 번거로움을 자동화하기 위해 도입된 기능)를 사용하면 됩니다.일반적으로 버텍스 보간기는 커스텀 UV를 수동으로 관리하는 대신플로트를 함께 묶어주므로 커스텀 UV를 수동으로 관리할 필요가 없습니다.

이 작업을 수행할 때마다 사용자 보간기 통계에 추가됩니다(보기에 혼란스러울 수 있지만).
또한 TexCoord1과 같은 커스텀 UV 채널을 사용하면 새로운보간기가 추가되며, 플랫폼에 따라 보간기 개수가 제한되어 있습니다(보통 16개)!
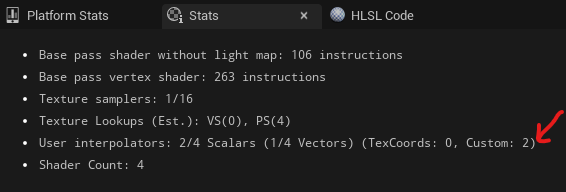
짐작하셨겠지만, 이렇게 하면 PoM, 왜곡, 시차 매핑 등과 같은 일부 픽셀당 조작 기술이 제한됩니다.이로 인해 (다른 하드웨어에서 확장하는) 비용이 엄청나게 높아질 수 있습니다.
Conclusion
셰이더를 최적화할 때, 특히 언리얼 엔진 내 머티리얼 에디터를 사용할 때는 고려해야 할 사항이 많습니다.
항상 하드웨어마다 다른 최적화가 필요하기 때문에 말할 필요는 없지만 항상 다음을 확인해야 합니다.
명령어 개수는 일반적으로 실행되는 실제 연산보다 덜 중요하지만 (에서 볼 수 있습니다), 여전히 좋은 하이 레벨 뷰입니다.셰이더 메모리 사용량
GPU 사이클은 진정한(r)성능의 척도이며, 표현식 재평가를 위한 수학 지식과 컴파일러에 대한 지식이 매우 중요합니다.예: divide는 mul rcp가 됩니다(20사이클, mul의 경우 4사이클). https://shader-playground.timjones.io/
거리 제곱은 CPU와 GPU에서 연산을 최적화하는 부두교의 마술입니다.및 GPU 작업을 최적화하는 부두술입니다
픽셀 셰이더에서 텍스처 샘플에 대한 UV를 조작하면GPU를 지연시킬 수 있지만, 버텍스 보간기/커스텀 UV를 영리하게 사용하면 해결할 수 있습니다
분기는 GPU 를 멈출 수 있습니다 (자세히 다루지는 않았지만)
사용 플래그를컴파일할 수 없으므로 사용되는 셰이더를 제한하기 위해 제한해야 합니다.
정적 파라미터(스위치, 머티리얼 레이어, 베이스 프로퍼티 오버라이드, 랜드스케이프레이어)는 모두 퍼뮤테이션 부풀림을 유발하여 인스트럭션 수를 증가시킬 수 있습니다.따라서 셰이더 메모리
상수는 컴파일 타임에 최적화되는 것과 변수(텍스처, 파라미터 등)에 최적화되는 것이 다릅니다.)에 최적화되어 있으므로 일반적으로 무언가를 파라미터로 노출해야 할 특별한 이유가 없는 한 상수를 사용하는 것이 좋습니다.머티리얼 함수는 조작 방법을 이해하면 워크플로 측면에서 훨씬 더 강력해집니다.
여기까지입니다!앞으로 더 많은 글을 쓸 수도 있습니다.(및 텍스처 샘플링에 대한 제한 사항), ddx/ddy/fwidth 등을 사용하는 방법 등에 대해 더 많은 글을 쓸 수 있습니다.
셰이더 점유율과 같이 아직 풀어야 할 퍼즐이 훨씬 더 많지만, 이 글을 통해 많은 혼란이 사라지길 바랍니다.혼란을 없애고 그래픽 프로그래머가 아닌 일반인에게는 한 곳에서 쉽게 접할 수 없는 많은 틈새 정보를 알려줄 수 있기를 바랍니다.
원문
Optimizing Shaders in Unreal Engine – Luna's Technical Art Blog
Optimizing Shaders in Unreal Engine
PreludeAbout this ArticleMaterial EditorGenerated Shader CodeMaterial InstancesOptimizing ShadersInstruction CountsStatic ParametersUsage FlagsGPU CyclesExamplesDistance SquaredConstant Optimizatio…
calvinatorrtech.art.blog
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [공유]Physically Based Cel Shading by VTA (1) | 2024.07.16 |
|---|---|
| [번역] Stencil 교차하는 방법과 주의점 (1) | 2024.07.13 |
| [번역] UE5 커스텀 메시패스 추가하기 (0) | 2024.07.09 |
| [번역] TGDC2022 | 언리얼 5를 우아하게 플레이하는 방법은?쉐이더부터! (0) | 2024.07.08 |
| [소식] 미호요 젠레스 존 제로 캐릭터 모델 공개. MMD (0) | 2024.07.05 |