
역자 주:
해당 토픽은 꽤 오래 전에 가볍게 읽어봤던 것으로 기억됩니다. 특히 해당 토픽에서 언급 한 https://blog.selfshadow.com/publications/s2013-shading-course/karis/s2013_pbs_epic_notes_v2.pdf 자료는 2015년 중국 게임사인 넷이즈에서 업무를 시작 할 때에도 많은 도움이 되었습니다. 다시 언리얼 엔진을 사용하는 프로젝트 컨설팅을 해야함에 따라서 다양한 방향의 최적화 방법들의 옛 히스토리들을 재탐색 하고 있습니다. 그 차에 근사 방식의 최적화 구현에 대한 또 다른 실험적 인사이트 글이라고 생각되어 리마인드 차원에서 간략히 한글화 했습니다.
원문.
Implementation Notes: Runtime Environment Map Filtering for Image Based Lighting
In this post I will cover implementing and optimizing runtime environment map filtering for image based lighting (IBL). Before we get started, this approach is covered in depth in Real Shading in U…
placeholderart.wordpress.com
이 게시물에서는 이미지 기반 조명(IBL)을 위한 런타임 환경 맵 필터링의 구현과 최적화에 대해 다룰 것입니다. 시작하기 전에, 이 방법에 대해서는 언리얼 엔진 4에서의 실제 쉐이딩과 피지컬리 베이스 렌더링으로의 Frostbite 로의 전환에서 자세히 다루고 있으니, 여기에서 제공하는 것보다 더 많은 배경 지식과 정보가 필요하다면 꼭 확인해보세요. 런타임 환경 맵 필터링은 오프라인 필터링된 맵(큐브맵젠과 같은 것 사용)보다 몇 가지 이점이 있습니다. 하나는 동적인 날씨와 낮과 밤의 변경과 같은 더 다이나믹한 요소를 사용할 수 있다는 것입니다. 올해 GDC에서 Steve McAuley가 파크라이 4의 월드 렌더링에서 언급한 것처럼, 환경 맵 재조명 및 필터링 전 동적인 스카이박스를 합성할 수 있습니다. 또한 런타임 필터링을 통해 현재 카메라 노출 정보를 사용하여 적절한 범위로 미리 노출할 수 있으므로 더 작은 텍스처(r10g11b10 대 r16b16g16a16)를 사용할 수 있습니다.
https://www.gdcvault.com/play/1022235/Rendering-the-World-of-Far
Rendering the World of Far Cry 4
Rendering Kyrat, the beautiful world of Far Cry 4, inspired the development of many new graphical features to use the power of the new generation of hardware. First, the foundations were laid down by lighting and material improvements. An...
www.gdcvault.com

Overview
이미지 기반 조명은 (이 경우 환경 맵) 이미지의 내용물을 빛의 원천으로 사용하는 것을 의미합니다. 무차별 대입법 구현에서는 모든 픽셀이 빛의 원천으로 간주되어 양방향 반사 분포 함수(BRDF)를 사용하여 평가됩니다. 이를 나타내는 전체 적분은 다음과 같습니다:
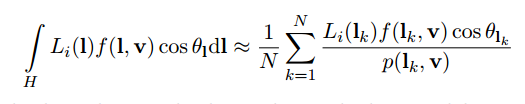
우리가 구현할 필터링의 변형은 카리스가 취한 분할합 접근 방식입니다. 이 접근 방식은 조명 기여도와 나머지 BRDF를 개별적으로 통합하여 위의 적분을 근사화합니다. 이렇게 하면 큐브맵과 tex2D 조회(lookup)를 사용하여 적분을 근사화할 수 있습니다.

초기 구현
언리얼 4의 리얼 셰이딩에 제공된 구현은 문서화가 잘 되어 있고 완성도가 높으므로 이를 레퍼런스 구현으로 참조하겠습니다.
언급된 논문의 저자들은 샘플 수를 줄이기 위해 Important samping을 활용하여 샘플을 BRDF의 중요한 부분에 재분배했습니다. Important samping은 매우 흥미로운 주제이므로 자세히 알아보려면 Important samping에 대한 참고 사항을 확인하세요. BRDF 통합의 경우 매 프레임마다 통합되지 않으므로 이 구현에서 멈출 수 있습니다. 또한 프로스트바이츠 개발자가 이 텍스처에 디즈니 디퓨즈 BRDF 용어를 추가하기 위해 수행한 확장을 무시하기로 선택했지만 여기에도 적용될 수 있습니다. 환경 맵 필터링은 저희가 최적화 작업에 집중하고 싶은 부분입니다.
Notes on importance sampling
Notes on importance sampling
blog.tobias-franke.eu
첫 번째 단계는 필터링할 새 큐브맵을 렌더링하는 것입니다. 비교를 위해 이 글에서는 언리얼 프레젠테이션의 큐브맵을 사용했습니다. 하지만 이 단계에서는 Far Cry 개발진처럼 환경 맵을 재조명하는 등의 멋진 작업을 할 수 있습니다. 참고로 지오메트리 셰이더를 사용하여 큐브의 모든 면을 한 번에 렌더링하는 경우도 있지만, 이 예제에서는 카메라를 적절한 면에 맞게 설정하고 한 번에 하나씩 렌더링했습니다.
Foreach Face in Cube Faces
Setup camera
Render envmap다음으로 Karis의 분할 합계 참조 구현을 구현합니다. 처음에는 샘플 수를 코스 노트에 제공된 대로 유지하지만 최적화할 때 이 부분에 중점을 둘 것입니다.
float fTotalWeight = 0.0f;
const uint iNumSamples = 1024;
for (uint i = 0; i < iNumSamples; i++)
{
float2 vXi = Hammersley(i, iNumSamples);
float3 vHalf = ImportanceSampleGGX(vXi, fRoughness, vNormal);
float3 vLight = 2.0f * dot(vView, vHalf) * vHalf - vView;
float fNdotL = saturate(dot(vNormal, vLight));
if (fNdotL > 0.0f)
{
vPrefilteredColor += EnvironmentCubemapTexture.SampleLevel(LinearSamplerWrap, vLight, 0.0f).rgb * fNdotL;
fTotalWeight += fNdotL;
}
}
return vPrefilteredColor / fTotalWeight;대략의 코드는 이렇습니다.
Foreach Face in Cube Faces
Setup camera
Bind Envmap
For i = 0; i < MipLevels; ++i
Set roughness for shader
Execute filtering제가 잘못한 것이 없는지 확인하기 위해 다이어그램 중 하나 이상을 재현하여 비교하는 것을 좋아합니다.

시야각이 약간 어긋나고 노출 차이가 있으며 다른 톤 매핑 연산자를 사용했기 때문에 중간 광택 구의 테두리를 따라 약간 어두워졌지만 그 외에는 좋은 출발점에 있습니다.
최적화할 영역
저는 최적화에 관해서는 다른 사람들만큼 미치지는 않았지만, 이런 코드를 볼 때 스스로에게 몇 가지 질문을 던집니다.
- 전역적으로 수행되는 작업의 양을 줄이려면 어떻게 해야 할까?
- 샘플 수를 줄이려면 어떻게 해야 할까?
- 샘플당 작업량을 줄이려면 어떻게 해야 할까?
- 어떻게 하면 가정을 유리하게 활용할 수 있을까요?
- 모든 샘플을 최대한 활용하려면 어떻게 해야 할까요?
- 어떤 부분을 확장할 수 있을까요?
다행히도 Frostbite 팀원들이 이미 위의 몇 가지 사항을 검토하여 그들이 제공하는 구현에서 도움을 받을 수 있습니다.
전역적으로 수행되는 업무량 감소
이 방법은 간단하며 기본적으로 프로스트바이츠 pbr에 해당하는 각주만 추가하면 됩니다. 첫 번째 밉(mip)은 본질적으로 미러 리플렉션이므로 해당 밉 레벨 처리를 모두 건너뛰고 생성된 환경 맵을 복사하기만 하면 됩니다. 생성된 텍스처를 그대로 유지하면서 최종 텍스처에 복사하는 것이 다음 단계에서 더 중요해집니다. 이제 코드는 다음과 같습니다:
Foreach Face in Cube Faces
Setup camera
Bind Envmap
Copy face into mip 0
For i = 1; i < MipLevels; ++i
Set roughness for shader
Execute filtering
샘플 수 줄이기
따라서 1024개의 샘플은 확실히 셰이더의 픽셀당 처리하고자 하는 것보다 많은 양입니다. 16~32개가 더 합리적인 샘플 수라고 생각합니다. 셰이더의 샘플 수를 줄이면 어떻게 되는지 살펴봅시다:

러프니스가 증가함에 따라 32개의 샘플만으로는 충분하지 않다는 것은 분명합니다. 이때 필터링된 Important sampling 이 유용합니다. 저는 중요도 샘플링에 대한 전문가는 아니지만 프로스트바이트 과정 노트에서 FIS 구현을 따라하기는 꽤 쉬웠습니다. 기본 개념은 중요도 샘플링으로 인해 BRD의 분포로 인해 특정 방향에서 더 적은 수의 샘플이 수집된다는 것입니다. 언더샘플링을 방지하기 위해 소스 환경 맵의 밉 체인이 샘플링됩니다. 밉은 샘플이 나타내는 솔리드 각도(OmegaS)와 최고 해상도의 단일 텍셀이 커버하는 솔리드 각도(OmegaP) 사이의 비율에 따라 결정됩니다. 예제에서 이를 구현하면 환경 맵 생성에서 밉을 생성하는 두 번째 단계가 추가되고, 각 샘플에 대해 OmegaS와 OmegaP를 계산한 다음 마지막으로 필요한 밉을 계산해야 합니다.
Foreach Face in Cube Faces
Setup camera
Render envmap
GenerateMips envmapfloat fTotalWeight = 0.0f;
const uint iNumSamples = 32;
for (uint i = 0; i < iNumSamples; i++)
{
float2 vXi = Hammersley(i, iNumSamples);
float3 vHalf = ImportanceSampleGGX(vXi, fRoughness, vNormal);
float3 vLight = 2.0f * dot(vView, vHalf) * vHalf - vView;
float fNdotL = saturate(dot(vNormal, vLight));
if (fNdotL > 0.0f)
{
// Vectors to evaluate pdf
float fNdotH = saturate(dot(vNormal, vHalf));
float fVdotH = saturate(dot(vView, vHalf));
// Probability Distribution Function
float fPdf = D_GGX(fNdotH) * fNdotH / (4.0f * fVdotH);
// Solid angle represented by this sample
float fOmegaS = 1.0 / (iNumSamples * fPdf);
// Solid angle covered by 1 pixel with 6 faces that are EnvMapSize X EnvMapSize
float fOmegaP = 4.0 * fPI / (6.0 * EnvMapSize * EnvMapSize);
// Original paper suggest biasing the mip to improve the results
float fMipBias = 1.0f;
float fMipLevel = max(0.5 * log2(fOmegaS / fOmegaP) + fMipBias, 0.0f);
vPrefilteredColor += EnvironmentCubemapTexture.SampleLevel(LinearSamplerWrap, vLight, fMipLevel).rgb * fNdotL;
fTotalWeight += fNdotL;
}
}
return vPrefilteredColor / fTotalWeight;이렇게 하면 거칠기가 높은 구체에 훨씬 더 나은 결과를 얻을 수 있지만 여전히 약간 두툼합니다.

가능한 사전 계산을 많이...
이전 변경 사항에는 내부 루프에 많은 수학을 추가하는 불행한 부작용이 있었습니다. 이제 이 부분에 주의를 집중하고 미리 계산할 수 있는 것이 있는지 살펴보겠습니다.
먼저, 출력의 모든 단일 픽셀에 대해 해머슬리 수열을 계산할 필요가 없으며 모든 픽셀에 대해 동일하다는 것을 쉽게 알 수 있습니다. 이 지식을 바탕으로 시퀀스 무작위 값이 어떻게 사용되는지 살펴보겠습니다:
float3 vHalf = ImportanceSampleGGX(vXi, fRoughness, vNormal);
...
float3 ImportanceSampleGGX(float2 vXi, float fRoughness, float3 vNoral)
{
// Compute the local half vector
float fA = fRoughness * fRoughness;
float fPhi = 2.0f * fPI * vXi.x;
float fCosTheta = sqrt((1.0f - vXi.y) / (1.0f + (fA*fA - 1.0f) * vXi.y));
float fSinTheta = sqrt(1.0f - fCosTheta * fCosTheta);
float3 vHalf;
vHalf.x = fSinTheta * cos(fPhi);
vHalf.y = fSinTheta * sin(fPhi);
vHalf.z = fCosTheta;
// Compute a tangent frame and rotate the half vector to world space
float3 vUp = abs(vNormal.z) < 0.999f ? float3(0.0f, 0.0f, 1.0f) : float3(1.0f, 0.0f, 0.0f);
float3 vTangentX = normalize(cross(vUp, vNormal));
float3 vTangentY = cross(vNormal, vTangentX);
// Tangent to world space
return vTangentX * vHalf.x + vTangentY * vHalf.y + vNormal * vHalf.z;
}이 함수는 색상으로 표시된 두 부분으로 나눌 수 있습니다. 첫 번째 부분은 샘플링 함수와 러프니스를 기반으로 로컬 공간 하프 벡터를 계산합니다. 두 번째 부분은 노멀에 대한 탄젠트 프레임을 생성하고 하프 벡터를 해당 프레임으로 회전시킵니다. 첫 번째 부분은 무작위 값(해머슬리 시퀀스에서 나온)과 러프니스의 함수이므로 로컬 공간 샘플 방향을 미리 계산할 수 있습니다. 또한 모든 샘플에 대해 탄젠트 프레임을 다시 계산하는 데 많은 사이클을 낭비하고 있다는 것도 이제 분명해졌습니다. 따라서 이를 업데이트 루프 외부로 플로팅하여 매트릭스에 넣고 들어오는 로컬 스페이스 샘플 방향을 월드 스페이스로 회전시킬 수 있습니다(실제로 셰이더 컴파일러도 이를 알아채고 루프 외부에서 수학식을 최적화했습니다).
// Compute a matrix to rotate the samples
float3 vTangentY = abs(vNormal.z) < 0.999f ? float3(0.0f, 0.0f, 1.0f) : float3(1.0f, 0.0f, 0.0f);
float3 vTangentX = normalize(cross(vTangentY, vNormal));
vTangentY = cross(vNormal, vTangentX);
float3x3 mTangentToWorld = float3x3(
vTangentX,
vTangentY,
vNormal );
for (int i = 0; i < NumSamples; i++)
{
float3 vHalf = mul(vSampleDirections[i], mTangentToWorld);
float3 vLight = 2.0f * dot(vView, vHalf) * vHalf - vView;
....셰이더의 다음 코드 비트는 샘플의 대표적인 빛 방향을 결정하기 위해 절반 벡터 주위에 뷰 벡터를 반영합니다.
분할합 기법의 등방성 가정에 따라 뷰 == 노멀, 그리고 로컬 공간에서 노멀 == 0,0,1이라고 말할 수 있습니다.
따라서 여기서 할 수 있는 일은 로컬 공간에서 벡터를 반사하고 반 벡터를 월드 스페이스로 회전하는 대신 라이트 벡터를 월드 스페이스로 회전하는 것입니다.
하지만 코드 후반부에서는 샘플의 밉 레벨을 계산하기 위해 하프 벡터와 노멀 벡터의 도트 곱이 있다고 가정한다는 문제가 있습니다.
다시 한 번 등방성 가정을 활용하면 로컬 공간에서 두 벡터 사이의 내적이 다른 공간에서 두 벡터의 내적과 같다는 것을 알 수 있습니다.
따라서 ndoth = vdoth = dot((0,0,1),half) 또는 ndoth = vdoth = half.z 이므로 이제 샘플별로도 미리 계산할 수 있습니다. 코드를 다시 살펴보면 밉 선택 연산이 전역 변수와 샘플당 값 두 개를 기반으로 하므로 이 역시 미리 계산할 수 있습니다(추세가 보이시나요?). 이 모든 계산을 CPU로 옮기고 셰이더에 업로드하기만 하면 이렇게 됩니다:
float fTotalWeight = 0.0f;
const uint iNumSamples = 32;
for (uint i = 0; i < iNumSamples; i++)
{
float3 vLight = mul(vSampleDirections[i], mTangentToWorld);
float fNdotL = saturate(dot(vNormal, vLight));
if (fNdotL > 0.0f)
{
vPrefilteredColor += EnvironmentCubemapTexture.SampleLevel(LinearSamplerWrap, vLight, fSampleMipLevels[i]).rgb * fNdotL;
fTotalWeight += fNdotL;
}
}FIS를 추가하기 전보다 샘플당 수식이 줄어든 상태로 돌아갔지만 여전히 더 잘할 수 있습니다. 여전히 광 벡터와 조건부가 있는 도트 곱이 있습니다. 다시 한 번 로컬 공간에서 빛 벡터를 미리 계산한 것을 활용하여 ndotl = dot((0,0,1), light) = light.z라고 말합니다. 또한 샘플을 업로드하기 전에 샘플의 가중치가 0이 될지 확인할 수 있으므로 검사에 실패할 샘플을 완전히 건너뛸 수 있습니다. 이 시점에서 내부 루프는 로컬 광원 벡터를 월드 스페이스로 회전하고 누적 샘플을 만듭니다.
for (uint i = 0; i < iNumSamples; i++)
{
float3 vLight = mul(vSampleDirections[i], mTangentToWorld);
vPrefilteredColor += EnvironmentCubemapTexture.SampleLevel(LinearSamplerWrap, vLight, fSampleMipLevels[i]).rgb * fSampleWeights[i];
}
return vPrefilteredColor * fInvTotalWeight;
다음은 제시된 다양한 접근 방식과 최적화 단계에 대한 몇 가지 타이밍이며, PC, 특히 노트북에서 수치를 얻는 것은 매우 정확하지 않으므로 신중하게 고려해야 합니다.
| Device | Time(ms) | Size | Approach |
| Iris 6100 | 54.0 | 256×256 | 1024 Samples Reference (UE4) |
| Iris 6100 | 2.6 | 256×256 | 32 Samples FIS Original (Frostbite) |
| Iris 6100 | 1.5 | 256×256 | 32 Samples FIS Optimized |
| Iris 6100 | 1.2 | 256×256 | Varying Sample Count |
| Iris 6100 | 0.5 | 128×128 | Varying Sample Count |
| GTX 980 | 9.4 | 256×256 | 1024 Samples Reference (UE4) |
| GTX 980 | 0.48 | 256×256 | 32 Samples FIS Original (Frostbite) |
| GTX 980 | 0.36 | 256×256 | 32 Samples FIS Optimized |
| GTX 980 | 0.36 | 256×256 | Varying Sample Count |
| GTX 980 | 0.16 | 128×128 | Varying Sample Count |
특정 수의 Sample Weight 가 0보다 큰지 확인합니다.
거칠기 값이 높으면 Hammersley sequence가 생성한 샘플의 거의 절반이 NdotL 검사에 실패하는 광 벡터를 생성합니다. 저는 간단한 선형 검색을 통해 올바른 수의 유효한 샘플을 생성하는 데 필요한 시퀀스 번호의 수를 찾는 것만으로도 상당한 개선이 이루어졌음을 알 수 있었습니다.
Hammersley 시퀀스는 소수점 주위의 10진수 2진 표현을 반영하는 Van Der Corpus 시퀀스를 기반으로 한다.
참조: https://gyutts.tistory.com/190

밉 레벨당 샘플 수 변경하기
이는 첫 번째 밉이 거울 반사를 나타내야 하므로 샘플이 하나만 필요하다는 Frostbite 의 그것의 어느 정도 확장된 것입니다. 이를 전체 밉 체인으로 확장하면 낮은 러프니스 값(큰 큐브 면을 처리할 때)에서는 샘플 수를 줄이고 높은 러프니스 값(면이 더 작을 때)에서는 샘플 수를 늘릴 수 있습니다. 이론적으로 이렇게 하면 필요한 샘플 수가 줄어들고 전반적인 노이즈가 감소합니다.

이렇게 하면 품질이 크게 향상되고 환경 맵에서 가져오는 총 샘플 수가 약 40만 개에서 약 20만 개로 줄었지만 성능이 크게 향상되는 것을 느끼지 못했으며, 오히려 그 반대의 경우도 있었습니다. 이는 밉 체인으로 내려갈수록 픽셀 수가 적어 많은 작업이 필요하고 샘플 수를 늘리면 필터링된 중요도 샘플링의 효과가 감소하기 때문일 수 있습니다. 이 접근 방식은 여전히 조사할 가치가 있으며 각 face를 개별적으로 렌더링한다는 사실에 구속될 수 있습니다.
기본 벡터 조회
이것은 Frostbite 프레젠테이션에서 직접 가져온 것입니다. 기본적으로, 환경 맵과 BRDF 텍스처에서 값을 검색할 때 거칠기에 따라 반사 벡터를 수정합니다. 이렇게하면 최초의 구현과는 매우 다르게 보입니다. 그러나 언리얼 강의 노트를 다시 살펴보면 전체 참조 구현과 더 유사해 보입니다:

float3 vReflection = 2.0f * vNormal * dot(vViewDirection, vNormal) - vViewDirection;
float fA = fRoughness * fRoughness;
vReflection = lerp(vNormal, vReflection, (1.0f - fA) * (sqrt(1.0f - fA) + fA));
아이디어
아직 구체화되지는 않았지만 잠재적으로 실현될 수 있는 기능입니다.
다양한 필터링 분포
지금까지는 중요도 샘플링에 GGX 분포를 사용했지만, 앞으로는 각각의 NdotL 항에 따라 샘플에 가중치를 부여합니다. 이로 인해 개선 섹션의 해결 방법을 통해 두 번째 가중치 계층에서 실패할 샘플을 무시할 수 있게 되었습니다. 나중에 분포를 수정하고 다시 정규화할 필요가 없도록 N점 L 가중치를 고려한 새로운 확률 분포를 만들 수 있을 것 같습니다. 그 분포의 분석적 버전을 찾아보려고 잠시 장난을 쳤지만 수학에 능숙하지 않아서 시간이 부족했습니다. 그 후에야 분석적 확률 분포 함수가 없어도 이 작업을 수행할 수 있으며, 대신 고정된 거칠기 값과 일련의 슈에도 랜덤 변수에 대해 수치적으로 적분할 수 있다는 것을 깨달았습니다. 조만간 이에 대해 조사해볼 계획입니다.
다양한 준 무작위 샘플링 세트
몇 가지 조사를 해본 결과, 해머슬리 세트는 샘플 수가 적을 때 가장 효과적이지 않다는 것이 분명해졌습니다. 동일한 수의 샘플에 대해 더 낮은 노이즈를 생성할 수 있는 다른 시퀀스가 있는데, 최근 픽사가 발표한 잠재적인 시퀀스는 다음과 같습니다: 상관 다중 지터 샘플링입니다. 이 방법을 사용해 본 결과 결과는 크게 다르지 않았지만, 한 가지 눈에 띄는 점은 시드 값을 전달하여 32개의 샘플 시퀀스를 생성할 수 있다는 점인데, 이는 환경 맵의 점진적 필터링을 수행하려는 경우 유용할 수 있습니다.
프로그레시브 필터링
프레임의 총 가중치를 알고 있으므로 해당 데이터를 다음 프레임으로 전달하고 결과를 결합하는 것은 쉽습니다. 해머슬리 시퀀스로 이 작업을 수행하려면 매트릭스에 로테이션을 추가하여 라이트를 로컬 공간에서 월드 공간으로 회전시킨 다음 평소와 같이 필터링하고 총 가중치와 결과에 이전 프레임의 총 가중치를 더하면 됩니다. 환경 맵을 무효화할 때가 되면 총 가중치를 지우기 시작하면 됩니다. 이렇게 하면 이전 세대 플랫폼에 필요한 마지막 성능을 조정하는 데 도움이 될 수 있습니다. 또한 특정 총 가중치에 도달하는 시점을 추적하여 콘텐츠가 변경된 것을 확인할 때까지(예: 하루 중 시간이 특정 임계값을 초과하여 진행되는 경우) 모든 처리를 중지할 수 있습니다.
결론
이 글이 누군가에게 도움이 되었기를 바랍니다. 이 프로세스를 최적화하기 위해 다른 방법을 시도했거나 제가 제안한 방법 중 어떤 것이라도 시도해 본 적이 있다면 여러분의 의견을 듣고 싶습니다.
Resources
Light probe used in this article from http://gl.ict.usc.edu/Data/HighResProbes/
Correlated Multi-Jittered Sampling: http://graphics.pixar.com/library/MultiJitteredSampling/paper.pdf
Hammersley Points on the Hemisphere: http://holger.dammertz.org/stuff/notes_HammersleyOnHemisphere.html
Real Shading in Unreal Engine 4: http://blog.selfshadow.com/publications/s2013-shading-course/karis/s2013_pbs_epic_notes_v2.pdf
Moving Frostbite To PBR: http://www.frostbite.com/2014/11/moving-frostbite-to-pbr/
Notes on Important Sampling: http://blog.tobias-franke.eu/2014/03/30/notes_on_importance_sampling.html
GPU Based Importance Sampling: http://http.developer.nvidia.com/GPUGems3/gpugems3_ch20.html
Rendering the world of Far Cry 4: http://www.gdcvault.com/play/1022235/Rendering-the-World-of-Far
Physically Based Shading at Disney: https://disney-animation.s3.amazonaws.com/library/s2012_pbs_disney_brdf_notes_v2.pdf
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [번역]Brief Analysis of UE5 Rendering Pipeline (0) | 2023.09.19 |
|---|---|
| [번역]물리적 기반 렌더링 알고리즘 (0) | 2023.09.17 |
| [번역]GDC 2023 - Two-Level Radiance Caching for Fast and Scalable Real-Time Global Illumination in Games (0) | 2023.09.14 |
| 채용. 프락시스 스튜디오. 파이프라인 SW 엔지니어 및 프론트엔드. (0) | 2023.09.13 |
| TECHARTFLOWIO 파트너 컨설턴트 이호성의 언리얼 엔진 라이팅 FAST CAMPUS the RED. (0) | 2023.09.13 |