
저자: 傻头傻脑亚古兽
서문
소개
Nanite는 UE5의 가상화 지오메트리 시스템(Virtualized Geometry System)으로, 주요 용도는 고폴리곤 모델의 고효율 렌더링입니다. Nanite는 모델에 대해 LOD 구조를 자동으로 생성하는데, 전통적인 LOD와 달리 Nanite의 LOD는 더 이상 모델 단위가 아니라 모델 내부의 국소 영역 단위까지 세분화되어 있어, 아티스트가 더 이상 LOD 제작이나 처리 때문에 고민할 필요가 없습니다. 게다가 GPU Driven의 고효율 컬링과 단일 드로우 콜(Draw Call)이라는 이점도 함께 누릴 수 있습니다.

기술 요점
Nanite 기술은 여러 기술을 결합하여 고효율 렌더링을 실현했습니다:
- Cluster Rendering: Cluster 단위로 삼각형을 조직하여 더욱 효율적인 컬링이 가능합니다.
- Auto LOD: Graph Partitioning 기술로 모델을 분할·단순화하여 LOD를 구축하고, 데이터를 BVH 구조로 조직하여 런타임에 LOD를 효율적으로 병렬 선택할 수 있습니다. 이 방식으로 구축된 LOD의 전환은 매우 매끄럽습니다.
- GPU Driven Pipeline: GPU가 주도하는 드로잉으로 CPU의 성능 부담을 줄입니다.
- Occlusion Culling: 더 세밀한 입자 단위의 오클루전 컬링으로 보이지 않는 삼각형을 제거합니다.
- Hardware/Software Rasterization: 작은 삼각형은 하드웨어 래스터라이저에 매우 비우호적이므로, 이러한 삼각형들은 Compute Shader로 소프트웨어 래스터라이즈를 수행하여 효율을 높입니다.
- Visibility Buffer: VisibilityBuffer를 활용해 Overdraw를 줄여 GPU 효율을 한층 더 끌어올립니다.
- Streaming: 현재 보이는 부분과 관련된 데이터만 로드하여 지오메트리가 메모리에 주는 압박을 줄입니다.
본문의 구현 효과
Nanite 시스템은 규모가 매우 방대하고 처리해야 할 엔지니어링 디테일이 아주 많기 때문에, 본문에서는 일부 내용을 단순화하거나 건너뛰고 핵심 부분만 구현하며, UE5 버전과는 다소 차이가 있을 수 있습니다.
아래 그림은 본문에서 구현한 효과입니다. 각 색상 블록은 하나의 삼각형이며, LOD 전환과 카메라 컬링이 모두 매우 부드럽게 이루어지는 것을 볼 수 있습니다(GIF 문제로 약간 끊겨 보입니다).


구현
1. Clusterize
첫 번째 단계는 오프라인 단계에서 처리하며, 복잡한 초고정밀 메시 모델을 효율적이고 합리적으로 더 작고 관리하기 쉬운 클러스터(Cluster)로 분할합니다. 각 Cluster는 최대 128개의 삼각형으로 구성됩니다. 이 분할은 단순한 절단이 아니라, 클러스터 사이를 잇는 간선의 수(컷 크기)를 최소화하면서 동시에 각 클러스터의 크기를 대체로 균등하게 유지하는 것을 목표로 합니다.


UE가 사용하는 파티션 라이브러리는 METIS입니다.
https://github.com/KarypisLab/METIS
구현 코드는 UE5 소스 코드의 다음 부분을 참고할 수 있습니다:
UnrealEngine-release\\Engine\\Source\\Developer\\NaniteBuilder\\Private\\NaniteBuilder.cpp
본문에서는 meshoptimizer를 사용하여 메시의 Cluster 분할과 Partition 기능을 구현합니다. 이 라이브러리에는 그 밖에도 Overdraw 최적화, Shadow Depth Index 등의 기능이 있습니다.
https://github.com/zeux/meshoptimizer
C++ DLL 익스포트 프로젝트를 새로 만들어, Unity에서 사용할 수 있도록 주요 함수 몇 개를 래핑합니다. 사실 코드량이 많지 않아 C#으로 옮겨 바로 사용해도 무방합니다.
각 함수는 다음과 같습니다:
meshopt_buildMeshlets (Cluster 구축)
meshopt_partitionClusters (Cluster를 Partition으로 분할)
meshopt_buildMeshletsBound (Cluster 개수 계산)
meshopt_computeSphereBounds (BoundsSphere 병합)



unsafe static List<Cluster> clusterize(Vector3[] vertices, int[] indices)
{
const int max_vertices = 192; // TODO: depends on kClusterSize, also may want to dial down for mesh shaders
const int max_triangles = kClusterSize; //128
const int min_triangles = (kClusterSize / 3) & ~3;
const float split_factor = 2.0f;
const float fill_weight = 0.75f;
int max_meshlets = BuildMeshletsBound(indices.Length, max_vertices, max_triangles); //meshopt_buildMeshletsBound
var meshlets = new Meshlet[max_meshlets * 2];
var meshlet_vertices = new int[max_meshlets * max_vertices];
var meshlet_triangles = new byte[max_meshlets * max_triangles * 3];
var meshlet_count = BuildMeshletFlex(meshlets, meshlet_vertices, meshlet_triangles, indices, indices.Length, vertices, vertices.Length, sizeof(float) * 3, max_vertices, min_triangles, max_triangles, 0.0f,
split_factor); //meshopt_buildMeshlets
List<Cluster> clusters = new List<Cluster>(meshlet_count);
for (int i = 0; i < meshlet_count; i++)
{
ref Meshlet meshlet = ref meshlets[i];
fixed (int* ptr = &meshlet_vertices[meshlet.vertex_offset])
{
fixed (byte* ptr2 = &meshlet_triangles[meshlet.triangle_offset])
{
OptimizeMeshlet(ptr, ptr2, (int)meshlet.triangle_count, (int)meshlet.vertex_count);
}
}
Cluster cluster = new Cluster();
cluster.indices = new int[meshlet.triangle_count * 3];
for (int j = 0; j < meshlet.triangle_count * 3; ++j)
cluster.indices[j] =
meshlet_vertices[meshlet.vertex_offset + meshlet_triangles[meshlet.triangle_offset + j]];
cluster.parent.error = float.MaxValue;
clusters.Add(cluster);
}
return clusters;
}
그런 다음 meshopt_buildMeshlets 함수를 통해 각 Cluster의 인덱스(indices)를 바로 얻을 수 있습니다.
2. Build DAG
이 Cluster들이 준비되면 "LOD"를 구축할 수 있습니다. 다음 작업을 반복하기만 하면 됩니다: 그룹화 → 병합 → 폴리곤 감소 → Clusterize. 아래 그림과 같습니다.
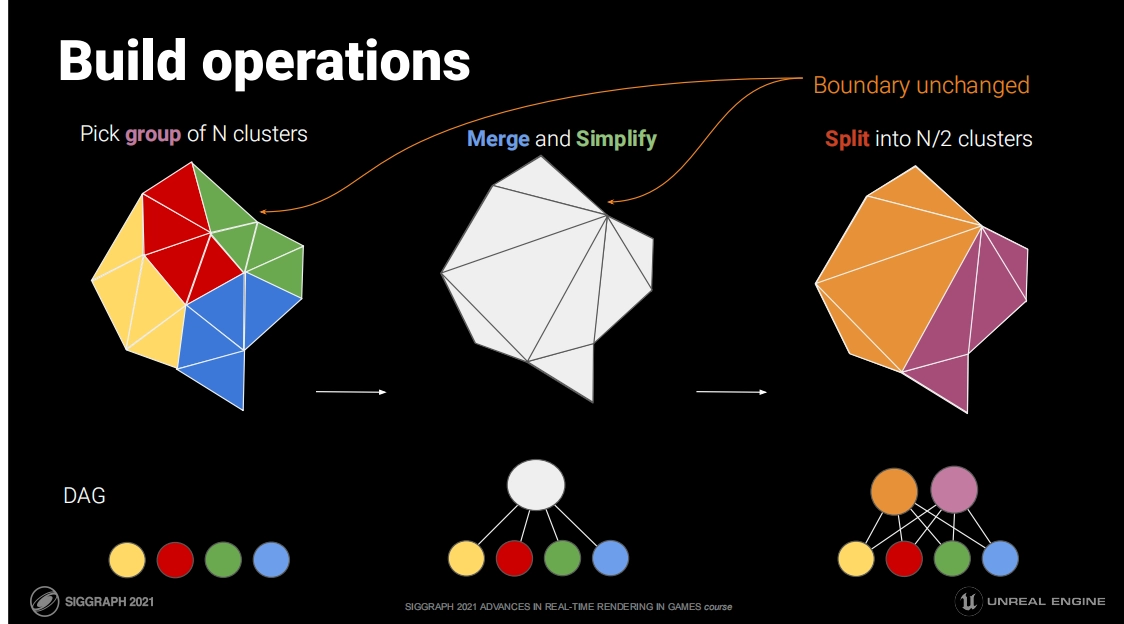
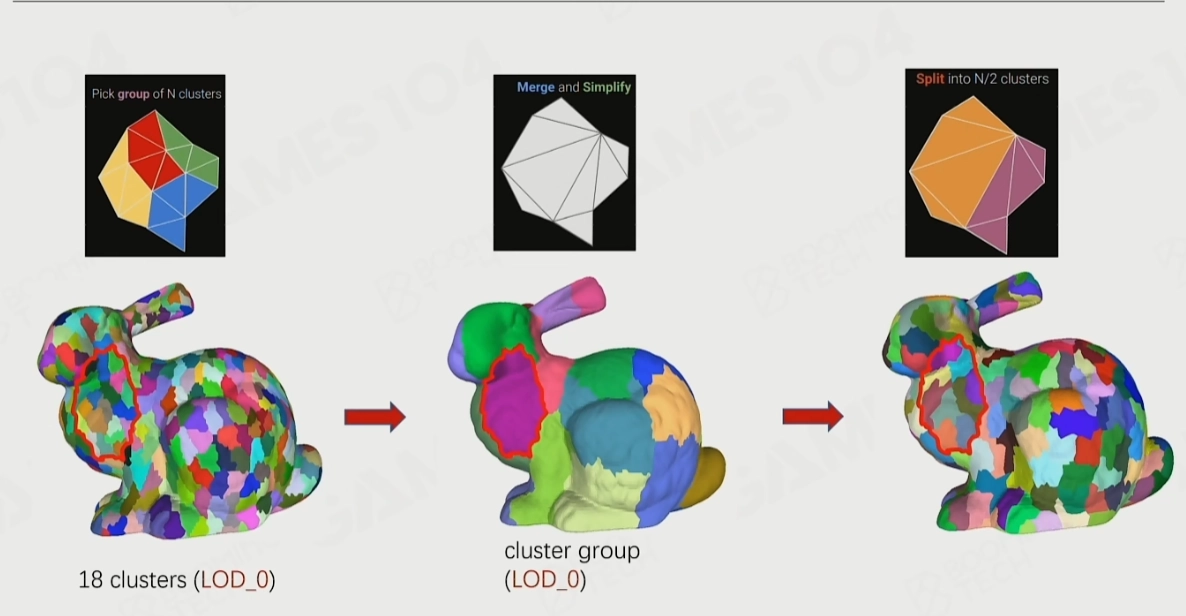

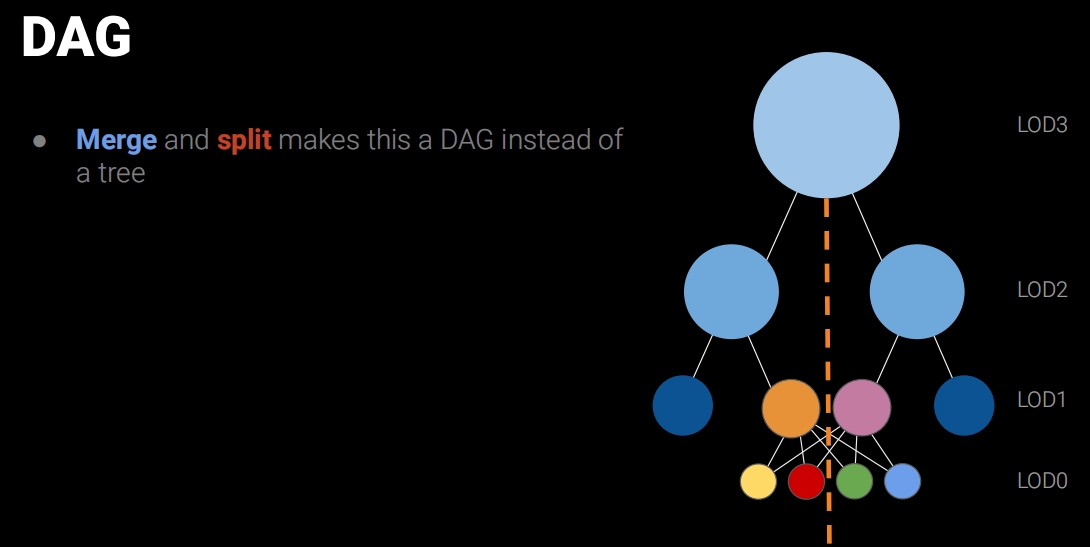
이 과정은 마치 Mipmap처럼 한 층씩 위로 병합하고 단순화해 나가는 느낌이며, 런타임 LOD 선택에 사용할 오차 값(error)과 바운드(bounds)를 함께 기록합니다. 이렇게 병합된 노드들을 Cluster Group이라고 부릅니다. 최종적으로 DAG(유향 비순환 그래프, Directed Acyclic Graph) 구조를 얻게 됩니다.
public struct ClusterGorup
{
public List<int> Children;
public Vector3 Bounds;
public float radius;
public Vector3 LODBounds;
public float MinLODError;
public float MaxParentLODError;
public int MipLevel;
}
public class NaniteSubMesh
{
public List<ClusterGorup> clusterGroupList;
public List<Cluster> clusterList;
public int maxMipLevel;
}
static NaniteSubMesh Nanite(Vector3[] vertices, Vector3[] normals, int[] indices)
{
NaniteSubMesh res = new NaniteSubMesh();
List<ClusterGorup> clusterGroupList = new List<ClusterGorup>();
var clusters = clusterize(vertices, indices);
res.clusterList = clusters;
res.clusterGroupList = clusterGroupList;
res.maxMipLevel = 0;
for (int i = 0; i < clusters.Count; ++i)
{
var c = clusters[i];
c.self = Bounds(vertices, clusters[i].indices, 0f);
c.mip = 0;
clusters[i] = c;
}
List<int> pending = new List<int>(clusters.Count);
int[] remap = new int[vertices.Length];
for (int i = 0; i < remap.Length; ++i)
remap[i] = i;
for (int i = 0; i < clusters.Count; ++i)
pending.Add(i);
int curMip = 1;
byte[] locks = new byte[vertices.Length];
while (pending.Count > 1)
{
List<List<int>> groups = partition(clusters, pending, remap, vertices);
if (kUseLocks)
lockBoundary(locks, groups, clusters, remap);
pending.Clear();
List<int> retry = new List<int>();
int triangles = 0;
int stuck_triangles = 0;
for (int i = 0; i < groups.Count; ++i)
{
var curGroupClusters = groups[i];
if (curGroupClusters.Count == 0)
{
continue; // metis shortcut
}
List<int> merged = new List<int>(vertices.Length);
for (int j = 0; j < curGroupClusters.Count; ++j)
{
merged.AddRange(clusters[curGroupClusters[j]].indices);
}
LODBounds groupb = boundsMerge(clusters, curGroupClusters);
ClusterGorup clusterGorup = new ClusterGorup();
clusterGorup.Bounds = groupb.center;
clusterGorup.MaxParentLODError = groupb.error;
clusterGorup.radius = groupb.radius;
clusterGorup.Children = new List<int>(merged.Count);
clusterGorup.MipLevel = curMip - 1;
for (int j = 0; j < curGroupClusters.Count; ++j)
{
clusterGorup.Children.Add(curGroupClusters[j]);
}
clusterGroupList.Add(clusterGorup);
// aim to reduce group size in half
int target_size = (merged.Count / 3) / 2 * 3;
float error = 0f;
var simplified = simplify(vertices, normals, merged.ToArray(), kUseLocks ? locks : null, target_size,
ref error);
if (simplified.Count > merged.Count * kSimplifyThreshold)
{
stuck_triangles += merged.Count / 3;
for (int j = 0; j < curGroupClusters.Count; ++j)
{
retry.Add(curGroupClusters[j]);
}
continue; // simplification is stuck; abandon the merge
}
// enforce bounds and error monotonicity
// note: it is incorrect to use the precise bounds of the merged or simplified mesh, because this may violate monotonicity
var split = clusterize(vertices, simplified.ToArray());
groupb.error += error; // this may overestimate the error, but we are starting from the simplified mesh so this is a little more correct
// update parent bounds and error for all clusters in the group
// note that all clusters in the group need to switch simultaneously so they have the same bounds
for (int j = 0; j < curGroupClusters.Count; ++j)
{
int clusterIndex = curGroupClusters[j];
var t = clusters[clusterIndex];
t.parent = groupb;
clusters[clusterIndex] = t;
}
for (int j = 0; j < split.Count; ++j)
{
var sj = split[j];
sj.self = groupb;
sj.mip = curMip;
split[j] = sj;
clusters.Add(sj); // std::move
pending.Add(clusters.Count - 1);
triangles += sj.indices.Length / 3;
}
}
curMip++;
}
if (pending.Count == 1)
{
var c = clusters[pending[0]];
ClusterGorup clusterGorup = new ClusterGorup();
clusterGorup.Bounds = c.self.center;
clusterGorup.MaxParentLODError = c.self.error;
clusterGorup.radius = c.self.radius;
clusterGorup.Children = new List<int>(1);
clusterGorup.MipLevel = curMip - 1;
clusterGorup.Children.Add(pending[0]);
clusterGroupList.Add(clusterGorup);
}
res.maxMipLevel = curMip - 1;
return res;
}
static void lockBoundary(byte[] locks, List<List<int>> groups, List<Cluster> clusters, int[] remap)
{
// for each remapped vertex, keep track of index of the group it's in (or -2 if it's in multiple groups)
int[] groupmap = new int[locks.Length];
for (int i = 0; i < groupmap.Length; ++i)
groupmap[i] = -1;
for (int i = 0; i < groups.Count; ++i)
{
var c = groups[i];
for (int j = 0; j < c.Count; ++j)
{
var indices = clusters[c[j]].indices;
for (int k = 0; k < indices.Length; ++k)
{
var v = indices[k];
var r = remap[v];
if (groupmap[r] == -1 || groupmap[r] == i)
groupmap[r] = i;
else
groupmap[r] = -2;
}
}
}
// note: we need to consistently lock all vertices with the same position to avoid holes
for (int i = 0; i < locks.Length; ++i)
{
var r = remap[i];
locks[i] = (byte)((groupmap[r] == -2) ? 1 : 0);
}
}
이렇게 해서 각 Mip 레벨에 해당하는 일련의 Cluster들을 얻게 됩니다.

3. 가속 구조
삼각형을 Cluster로 분할하더라도 그 수가 여전히 너무 많아, Compute Shader로 병렬 연산을 하더라도 효율이 높지 않습니다. 그래서 Nanite는 BVH를 ClusterGroup의 가속 구조로 사용하고, Persistent Threads와 결합하여 탐색과 필터링을 수행합니다.
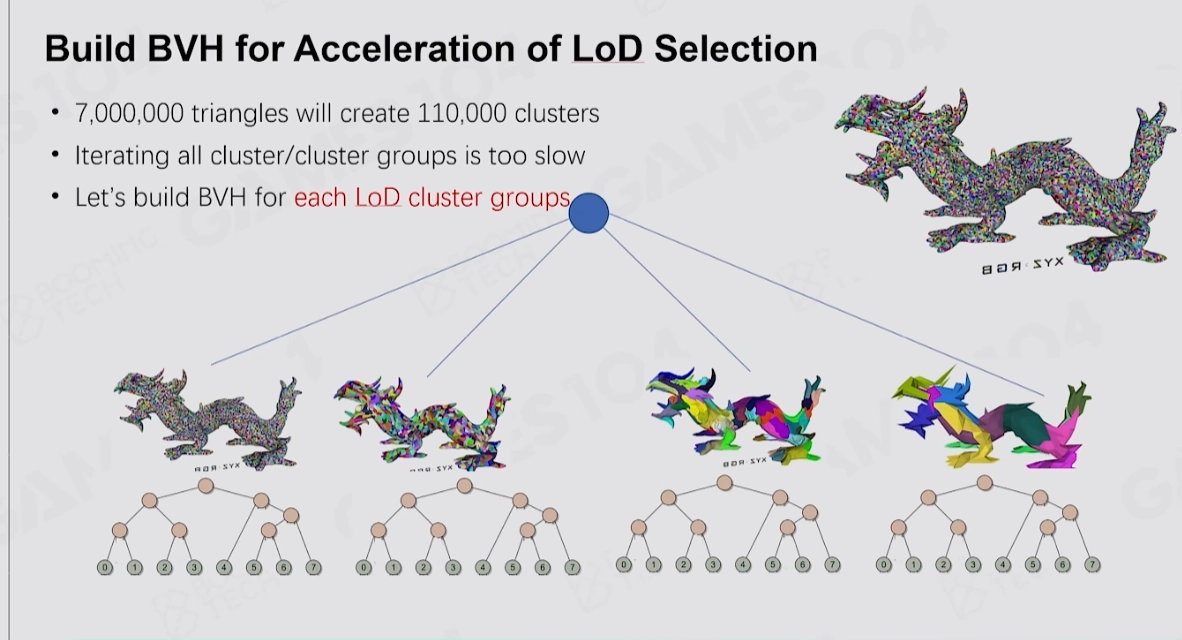
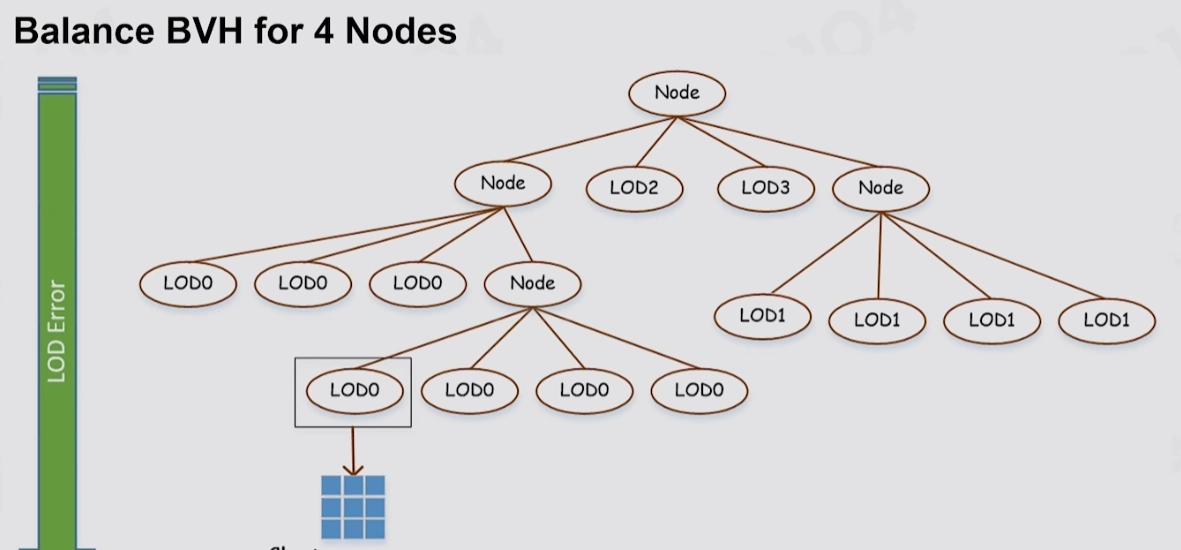
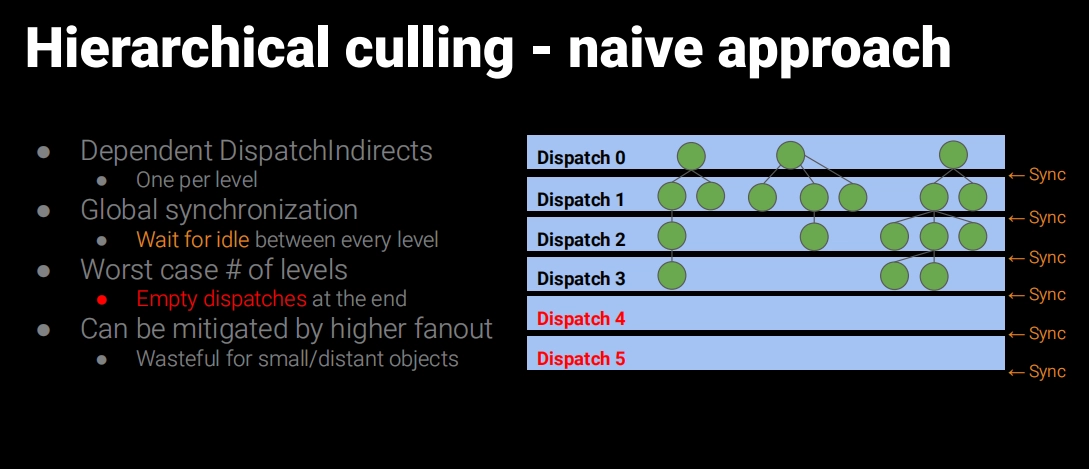

Persistent Threads로 BVH를 순회하는 부분은, 관심 있다면 UE5 소스 코드의 Shaders\\Private\\Nanite\\NaniteClusterCulling.usf를 참고하세요.
UE5에는 Persistent Threads를 사용하지 않는 흐름도 있으며, 일반적으로 기본값은 사용하지 않는 쪽이라고 봐야 합니다.

UE5 소스 코드 부분
개인적으로 Persistent Threads 방식으로 GPU에서 이런 BVH 구조를 순회하는 것은 다소 우격다짐에 무겁다고 느껴져서 조금 단순화했습니다. 여러 Cluster를 하나의 컬링 단위(Part)로 합쳐, 먼저 Part 단위로 병렬 컬링을 수행한 뒤 Part 내부의 Cluster들에 대해 다시 병렬 컬링을 하는 2단 구조로 가속함으로써 Persistent Threads의 간단한 대체 방안으로 삼았습니다.
그리고 여러 Part를 Page로 조직하여 블록 단위 로딩에 사용합니다. 머티리얼 처리 디테일도 다른데, UE5의 머티리얼은 각 Cluster가 MaterialRange를 기록하지만, 여기서는 간단하게 각 SubMesh마다 독립적인 Cluster들을 구축하도록 구현했습니다.
코드는 다음과 같습니다:
[Serializable]
public struct NaniteCluster
{
public int indiceIndex;
public int indiceCount;
public float selfErrer;
public float parentErrer;
public Vector4 selfSphere;
public Vector4 parentSphere;
public int subMeshID;
public int vertexOffset;
};
[Serializable]
public struct NaniteClusterGorup
{
public int ClusterStart;
public int ClusterCount;
public Vector3 Bounds;
public float radius;
public Vector3 LODBounds;
public float MinLODError;
public float MaxParentLODError;
public int MipLevel;
}
[Serializable]
public struct NaniteMeshPart
{
public int ClusterStart;
public int ClusterCount;
public Vector4 selfSphere;
public float MaxParentLODError;
}
public class NaniteSubMesh
{
public List<ClusterGorup> clusterGroupList;
public List<Cluster> clusterList;
public int maxMipLevel;
}
public class BuildPart
{
public List<int> clusterList;
public int mip;
public int subMesh;
}
public static void BuildNaniteMesh(Mesh mesh)
{
var vertices = mesh.vertices;
var normals = mesh.normals;
var uvs = mesh.uv;
int subMeshCount = mesh.subMeshCount;
int totalClusterCount = 0;
int totalIndexCount = 0;
List<NaniteSubMesh> subMeshList = new List<NaniteSubMesh>();
for (int i = 0; i < subMeshCount; i++)
{
var triangles = mesh.GetTriangles(i);
var subMesh = Nanite(vertices, normals, triangles);
subMeshList.Add(subMesh);
totalClusterCount += subMesh.clusterList.Count;
}
List<BuildPart> buildPartsList = new List<BuildPart>(totalClusterCount);
int MAX_PART_PERPAGE = 128;
int MAX_CLUSTER_PERPART = 8;
for (int subMeshIndex = 0; subMeshIndex < subMeshList.Count; subMeshIndex++)
{
var subMesh = subMeshList[subMeshIndex];
List<Cluster> clusters = subMesh.clusterList;
var groupsList = subMesh.clusterGroupList;
BuildPart buildPart = null;
for (int i = 0; i < groupsList.Count; i++)
{
var gIndex = i; // sortGroups[i].OldIndex;
var g = groupsList[gIndex];
var childs = g.Children;
for (int c = 0; c < childs.Count; c++)
{
int cIndex = childs[c];
int cMip = clusters[cIndex].mip;
totalIndexCount += clusters[cIndex].indices.Length;
// new Part
if (buildPart == null || buildPart.clusterList.Count >= MAX_CLUSTER_PERPART ||
buildPart.mip != cMip)
{
buildPart = new BuildPart();
buildPart.clusterList = new List<int>(MAX_CLUSTER_PERPART);
buildPart.mip = cMip;
buildPart.subMesh = subMeshIndex;
buildPartsList.Add(buildPart);
}
buildPart.clusterList.Add(cIndex);
}
}
}
int buildPartCount = buildPartsList.Count;
NaniteMeshPage[] pageArray = new NaniteMeshPage[(buildPartCount + (MAX_PART_PERPAGE - 1)) / MAX_PART_PERPAGE]; //ceil
List<int> tempIndiceList = new List<int>(totalIndexCount);
List<int> mipLists = new List<int>(totalClusterCount);
int partIndex = 0;
for (int i = 0; i < pageArray.Length; i++)
{
// create new page
var p = ScriptableObject.CreateInstance<NaniteMeshPage>();
pageArray[i] = p;
tempIndiceList.Clear();
int partCount = (i == (pageArray.Length - 1)) ? (buildPartCount % MAX_PART_PERPAGE) : MAX_PART_PERPAGE;
p.parts = new NaniteScene.NaniteMeshPart[partCount];
List<NaniteScene.NaniteCluster> pageClusters = new List<NaniteScene.NaniteCluster>(partCount * MAX_CLUSTER_PERPART);
for (int j = 0; j < partCount; j++)
{
var buildPart = buildPartsList[partIndex];
var buildPartCluster = buildPart.clusterList;
// create part
var part = new NaniteScene.NaniteMeshPart();
part.ClusterStart = pageClusters.Count; // local index
part.ClusterCount = buildPartCluster.Count;
int subMeshID = buildPart.subMesh;
float maxParentErr = 0f;
var clusters = subMeshList[subMeshID].clusterList;
for (int c = 0; c < buildPartCluster.Count; c++)
{
var cluster = clusters[buildPartCluster[c]];
mipLists.Add(cluster.mip);
// create Cluster
NaniteScene.NaniteCluster naniteCluster = new NaniteScene.NaniteCluster();
naniteCluster.indiceIndex = tempIndiceList.Count;
naniteCluster.indiceCount = cluster.indices.Length;
naniteCluster.parentErrer = cluster.parent.error;
naniteCluster.parentSphere = new Vector4(cluster.parent.center.x, cluster.parent.center.y, cluster.parent.center.z, cluster.parent.radius);
naniteCluster.selfErrer = cluster.self.error;
naniteCluster.selfSphere = new Vector4(cluster.self.center.x, cluster.self.center.y, cluster.self.center.z, cluster.self.radius);
naniteCluster.subMeshID = subMeshID;
tempIndiceList.AddRange(cluster.indices);
maxParentErr = Mathf.Max(naniteCluster.parentErrer, maxParentErr);
pageClusters.Add(naniteCluster);
}
LODBounds partBounds = boundsMerge(clusters, buildPartCluster, true);
part.selfSphere = new Vector4(partBounds.center.x, partBounds.center.y, partBounds.center.z, partBounds.radius);
part.MaxParentLODError = maxParentErr;
p.parts[j] = part;
partIndex++;
}
p.clusterArray = pageClusters.ToArray();
p.indiceArray = tempIndiceList.ToArray();
p.clusterMip = mipLists.ToArray();
}
string fileName = AssetDatabase.GetAssetPath(mesh);
string extension = Path.GetExtension(fileName);
fileName = fileName.Replace(extension, "");
// Build page
int totalVerts = 0;
for (int i = 0; i < pageArray.Length; i++)
{
var page = pageArray[i];
var clusterArray = page.clusterArray;
var indiceArray = page.indiceArray;
Dictionary<int, int> indicesMap = new Dictionary<int, int>();
List<Vector3> tempVerts = new List<Vector3>(vertices.Length);
List<Vector3> tempNormals = new List<Vector3>(vertices.Length);
List<Vector2> tempUVs = new List<Vector2>(vertices.Length);
List<int> newIndices = new List<int>(totalIndexCount);
for (int c = 0; c < clusterArray.Length; c++)
{
ref var cluster = ref clusterArray[c];
var indexStart = cluster.indiceIndex;
var indexEnd = indexStart + cluster.indiceCount;
for (int index = indexStart; index < indexEnd; index++)
{
int vertIndex = indiceArray[index];
int newIndex;
if (!indicesMap.TryGetValue(vertIndex, out newIndex))
{
newIndex = newIndices.Count;
indicesMap.Add(vertIndex, newIndex);
tempVerts.Add(vertices[vertIndex]);
tempNormals.Add(normals[vertIndex]);
if (uvs.Length == 0)
{
tempUVs.Add(Vector2.zero);
}
else
{
tempUVs.Add(uvs[vertIndex]);
}
newIndices.Add(newIndex);
}
indiceArray[index] = newIndex;
}
}
page.vertexStride = 5; // pos3 + uv2
page.vertexData = new float[tempVerts.Count * page.vertexStride];
page.vertexCount = tempVerts.Count;
for (int v = 0; v < tempVerts.Count; v++)
{
int vertexIndex = v * page.vertexStride;
page.vertexData[vertexIndex + 0] = tempVerts[v].x;
page.vertexData[vertexIndex + 1] = tempVerts[v].y;
page.vertexData[vertexIndex + 2] = tempVerts[v].z;
page.vertexData[vertexIndex + 3] = tempUVs[v].x;
page.vertexData[vertexIndex + 4] = tempUVs[v].y;
}
totalVerts += tempVerts.Count;
string newPath = fileName + "_p" + i + ".asset";
AssetDatabase.CreateAsset(page, newPath);
}
AssetDatabase.Refresh();
Debug.Log("mesh Vertx:" + vertices.Length + " mesh Nanite:" + totalVerts + " cluster:" + totalClusterCount + "part:" + buildPartCount + " page:" + pageArray.Length);
NaniteMesh naniteMesh = ScriptableObject.CreateInstance<NaniteMesh>();
{
naniteMesh.subMeshCount = subMeshCount;
naniteMesh.pageArray = new NaniteMeshPage[pageArray.Length];
for (int i = 0; i < pageArray.Length; i++)
{
string newPath = fileName + "_p" + i + ".asset";
naniteMesh.pageArray[i] = AssetDatabase.LoadAssetAtPath<NaniteMeshPage>(newPath);
}
}
var meshBound = mesh.bounds;
naniteMesh.boundingSphere = meshBound.center;
naniteMesh.boundingSphere.w = meshBound.extents.magnitude;
string meshExt = "_mesh.asset";
AssetDatabase.CreateAsset(naniteMesh, fileName + meshExt);
AssetDatabase.Refresh();
}
여기까지로 오프라인 부분은 기본적으로 마무리되며, Nanite 리소스를 얻을 수 있습니다. 물론 UE5 원본에서는 BVH, 인코딩(Encode), 압축, Page 분할, 버텍스 속성 최적화 등 훨씬 많은 작업을 수행하지만, 개인적으로 이런 것들은 모두 엔지니어링 디테일에 속한다고 생각합니다.

4. 런타임 리소스
이제 런타임 부분입니다. 이 Nanite Mesh를 로드해야 하는데, 편의를 위해 여기서는 리소스를 스크립트에 직접 참조시키고 로딩 부분은 생략하겠습니다.

리소스, Object, 머티리얼 정보를 통합하여 GPU의 버퍼로 전달합니다. 여기서의 처리 방식은 그다지 정식적인 방법은 아니고 편의적인 처리입니다. 물론 Compute Shader를 사용해 Page 데이터를 GPU 버퍼로 업데이트할 수도 있습니다.
public static List<NaniteRenderer> renderers = new List<NaniteRenderer>();
private static SceneObject[] gpuObjects = new SceneObject[2048];
// cluster -> part -> page
public struct SceneObject
{
public int naniteMeshID;
public Matrix4x4 localToWorldMatrix;
public int materialIDOffset;
}
public struct NaniteRes
{
public Vector4 boundingSphere;
public int partIndex;
public int partCount;
}
unsafe static void UpdateRenderList()
{
if (renderers.Count == 0)
return;
// object update
if (renderers.Count > gpuObjects.Length)
{
gpuObjects = new SceneObject[Mathf.NextPowerOfTwo(renderers.Count)];
}
objectCount = 0;
maxPartCount = 0;
naniteMeshes.Clear();
materialList.Clear();
List<int> materialIndices = new List<int>();
for (int i = 0; i < renderers.Count; i++)
{
var renderer = renderers[i];
var nMesh = renderer.naniteMesh;
foreach (var p in nMesh.pageArray)
{
maxPartCount += p.parts.Length;
maxClusterCount += p.clusterArray.Length;
}
SceneObject obj = new SceneObject();
obj.localToWorldMatrix = renderer.transform.localToWorldMatrix;
// mesh index
int index = naniteMeshes.IndexOf(nMesh);
if (index < 0)
{
index = naniteMeshes.Count;
naniteMeshes.Add(nMesh);
}
obj.naniteMeshID = index;
// mat indexs
obj.materialIDOffset = materialIndices.Count;
for (int m = 0; m < renderer.materials.Length; m++)
{
var mat = renderer.materials[m];
int matIndex = materialList.IndexOf(mat);
if (matIndex < 0)
{
matIndex = materialList.Count;
materialList.Add(mat);
}
materialIndices.Add(matIndex);
}
gpuObjects[i] = obj;
renderer.transformChanged = false;
objectCount++;
}
if (candidateClusterBuffer != null)
candidateClusterBuffer.Dispose();
candidateClusterBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Structured, maxClusterCount * 2, sizeof(int));
if (visibleClusterBuffer != null)
visibleClusterBuffer.Dispose();
visibleClusterBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Structured, maxClusterCount * 2, sizeof(int));
if (objectsBuffer != null)
objectsBuffer.Dispose();
objectsBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Structured, objectCount, sizeof(SceneObject));
objectsBuffer.SetData(gpuObjects, 0, 0, objectCount);
if (visObjectsBuffer != null)
visObjectsBuffer.Dispose();
visObjectsBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Structured, objectCount, sizeof(int));
int vertCount = 0;
List<NaniteCluster> tempClusters = new List<NaniteCluster>(2048);
List<NaniteMeshPart> tempParts = new List<NaniteMeshPart>(2048);
List<NaniteRes> naniteRes = new List<NaniteRes>(2048);
List<int> tempIndices = new List<int>(2048 * 100);
List<float> vertexDataList = new List<float>();
// load page
for (int nID = 0; nID < naniteMeshes.Count; nID++)
{
NaniteRes res = new NaniteRes();
var nMesh = naniteMeshes[nID];
// GPU에 채워 넣기
var pages = nMesh.pageArray;
res.partIndex = tempParts.Count;
res.partCount = 0;
res.boundingSphere = nMesh.boundingSphere;
for (int p = 0; p < pages.Length; p++)
{
var page = pages[p];
var parts = page.parts;
int vertOffset = vertCount;
int indicesOffset = tempIndices.Count;
int clusterOffset = tempClusters.Count;
// add all cluster
var clusters = page.clusterArray;
for (int c = 0; c < clusters.Length; c++)
{
var cluster = clusters[c];
cluster.indiceIndex += indicesOffset;
cluster.vertexOffset = vertOffset;
tempClusters.Add(cluster);
}
// add all part
for (int partIndex = 0; partIndex < parts.Length; partIndex++)
{
var part = parts[partIndex];
part.ClusterStart += clusterOffset;
tempParts.Add(part);
res.partCount++;
}
// add page data
tempIndices.AddRange(page.indiceArray);
vertexDataList.AddRange(page.vertexData);
vertCount += page.vertexCount;
}
naniteRes.Add(res);
}
// TODO GPU Update Buffer
if (naniteResBuffer != null)
naniteResBuffer.Dispose();
naniteResBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Structured, naniteRes.Count, sizeof(NaniteRes));
naniteResBuffer.SetData(naniteRes);
if (partsBuffer != null)
partsBuffer.Dispose();
partsBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Structured, tempParts.Count, sizeof(NaniteMeshPart));
partsBuffer.SetData(tempParts);
if (clusterBuffer != null)
clusterBuffer.Dispose();
clusterBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Structured, tempClusters.Count, sizeof(NaniteCluster));
clusterBuffer.SetData(tempClusters);
if (indiceseBuffer != null)
indiceseBuffer.Dispose();
indiceseBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Raw, tempIndices.Count, sizeof(int));
indiceseBuffer.SetData(tempIndices);
if (materialIndexBuffer != null)
materialIndexBuffer.Dispose();
materialIndexBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Structured, materialIndices.Count, sizeof(int));
materialIndexBuffer.SetData(materialIndices);
if (vertexDataBuffer != null)
vertexDataBuffer.Dispose();
vertexDataBuffer = new GraphicsBuffer(GraphicsBuffer.Target.Raw, vertexDataList.Count, sizeof(float));
vertexDataBuffer.SetData(vertexDataList);
}
// input object ID =>
public unsafe static void UpdateNaniteScene()
{
if (renderListDirty)
{
UpdateRenderList();
// UpdateRenderListGPU();
renderListDirty = false;
}
for (int i = 0; i < renderers.Count; i++)
{
var renderer = renderers[i];
if (renderer.transformChanged)
{
gpuObjects[i].localToWorldMatrix = renderer.transform.localToWorldMatrix;
renderer.transformChanged = false;
transformDirty = true;
}
}
if (objectsBuffer != null && transformDirty)
objectsBuffer.SetData(gpuObjects, 0, 0, objectCount);
}
5. 컬링
이 시점에는 오프라인 단계에서 이미 Cluster들이 배열로 평탄화(Flatten)되어 있으며, 이 Cluster들은 병렬로 컬링할 수 있습니다. 교묘한 점은 부모(상위 레벨)의 오차와 자기 자신의 오차를 함께 기록해 두었다는 것입니다. 덕분에 오차 계수를 전달하면 상위·하위 레벨과 무관하게 각 Cluster가 독립적으로 자신이 컬링될지를 판단할 수 있습니다.
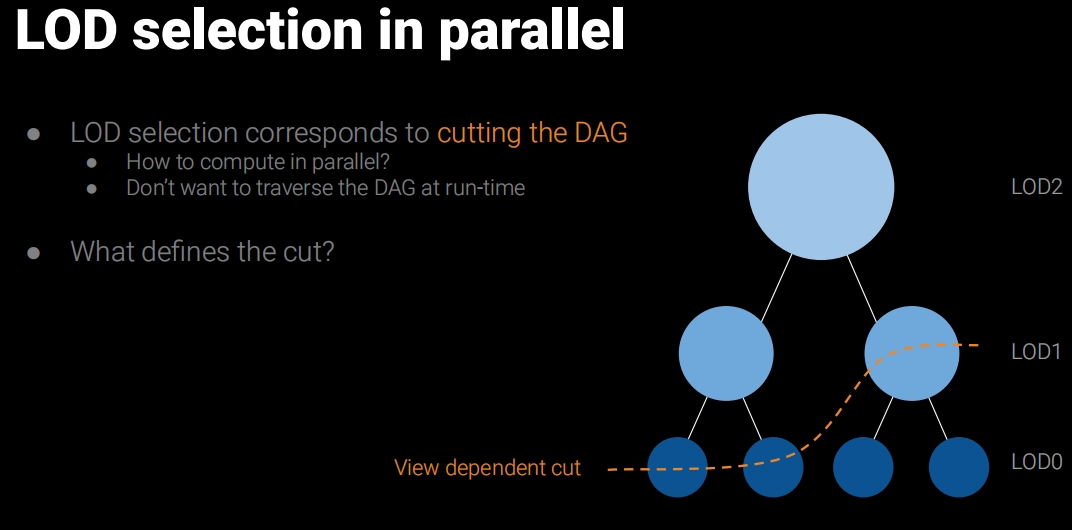
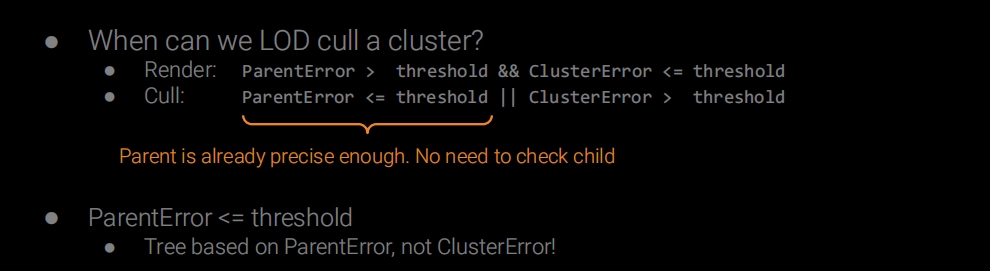

먼저 CPU에서 컬링 Compute Shader의 Dispatch를 시작합니다. 데이터를 조직하는 시점에 이미 모든 Object의 최대 Parts/Cluster 수를 알고 있으므로, 그 수를 그대로 사용해 Dispatch했습니다.
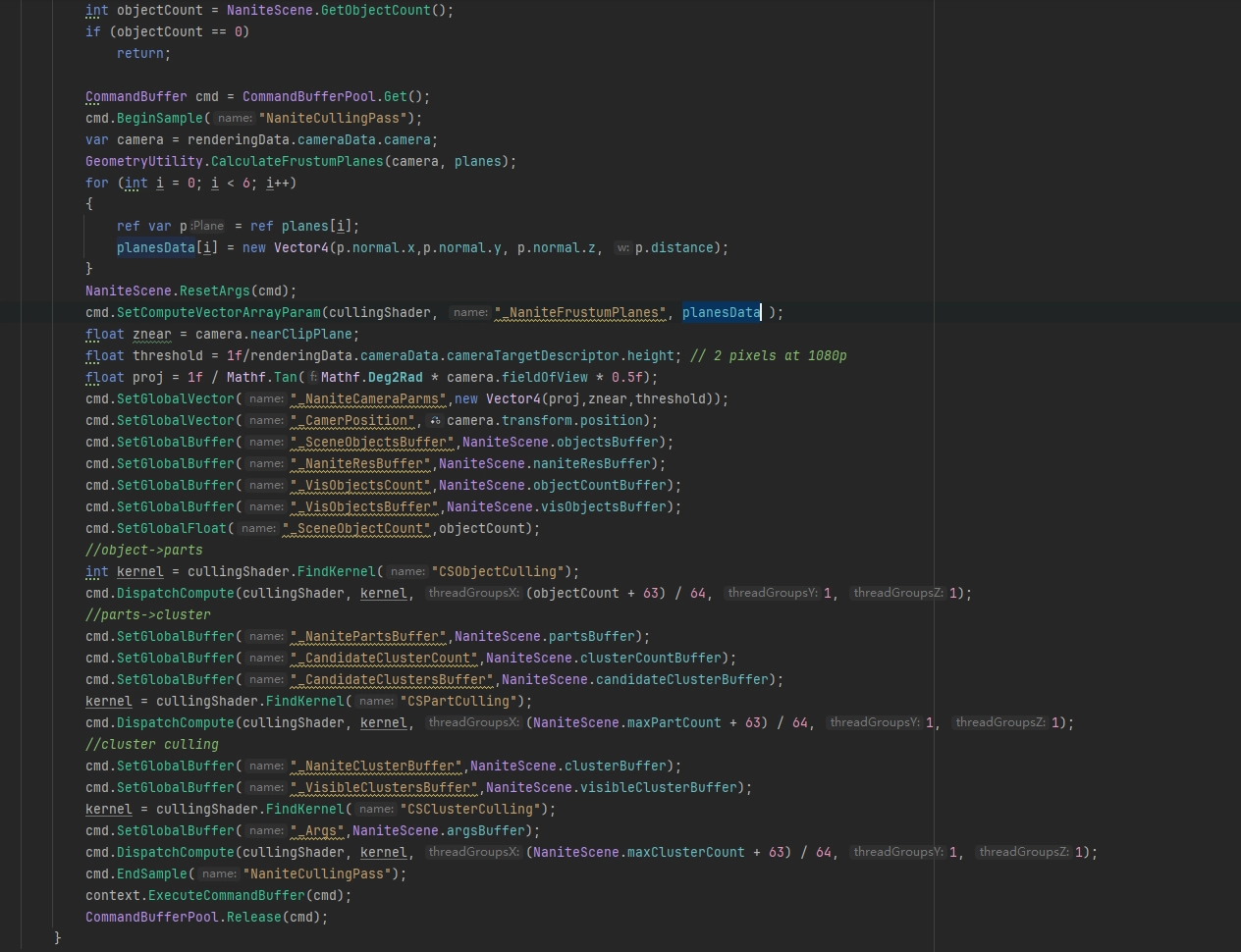
Objects 컬링:
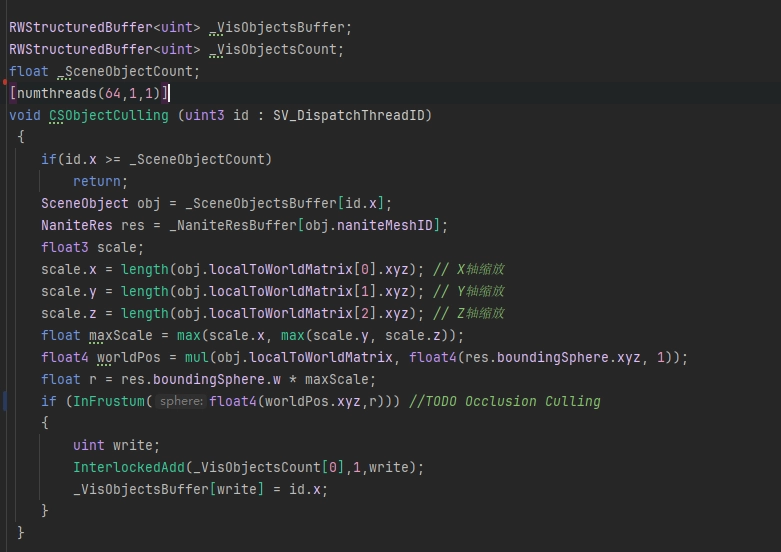
Object를 기반으로 NaniteMesh의 Parts를 찾아 컬링(Culling)을 수행합니다.
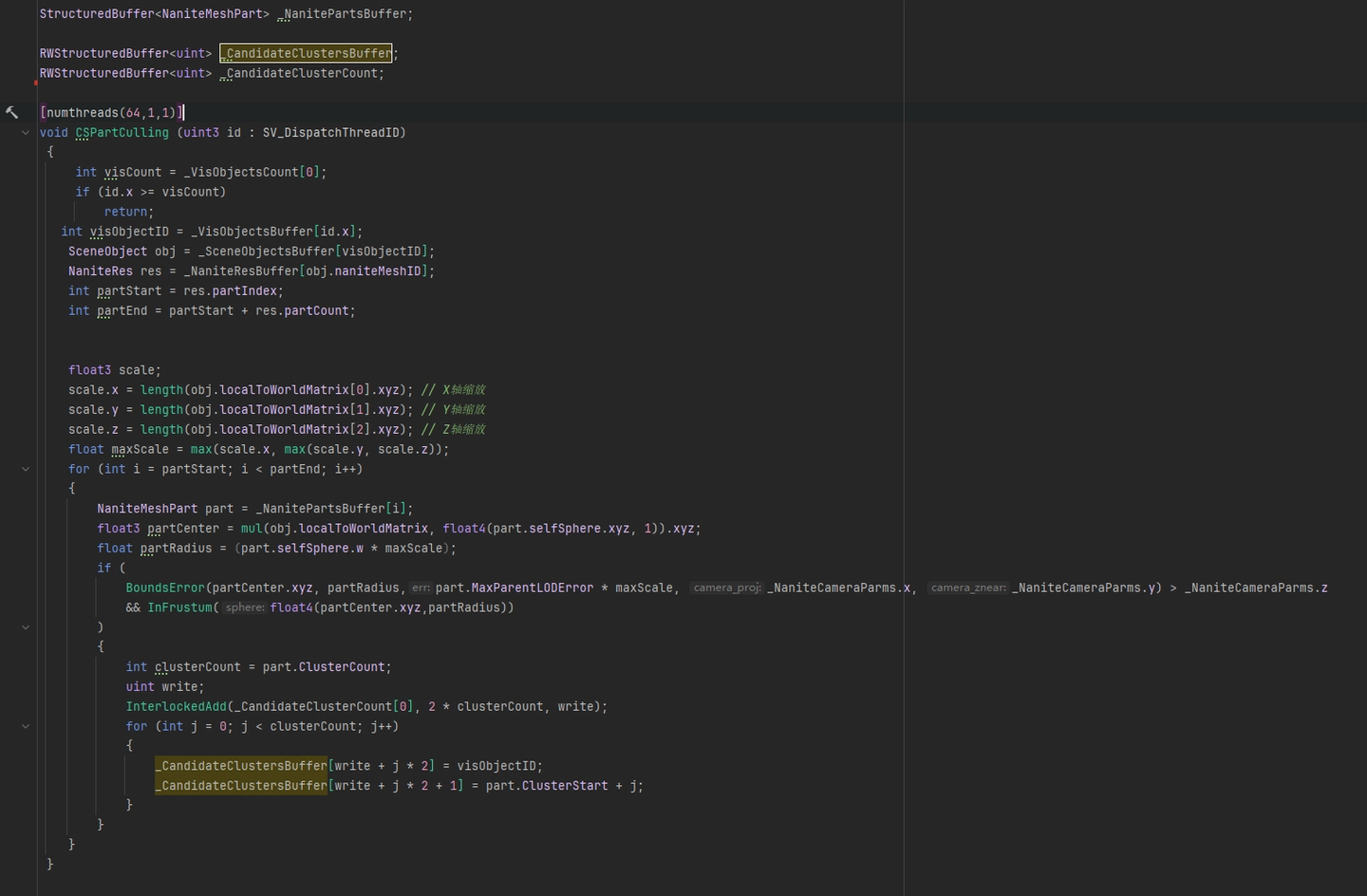
Clusters 컬링


6. 소프트웨어 래스터라이저
요령을 좀 피워서, 생략합니다..
7. VisibilityBuffer
VBuffer는 주로 Overdraw를 줄이는 데 사용되며, 셰이더는 InstanceID, ClusterID, 머티리얼 ID를 직접 출력합니다. 그런 다음 이 VBuffer를 이용해 버텍스 데이터를 계산하여 셰이딩합니다.


이는 GPU Driven이 주는 이점 덕분으로, DrawProceduralIndirect 한 번이면 모든 물체를 그릴 수 있습니다.

한 번의 DrawProceduralIndirect로 여러 물체를 그리기
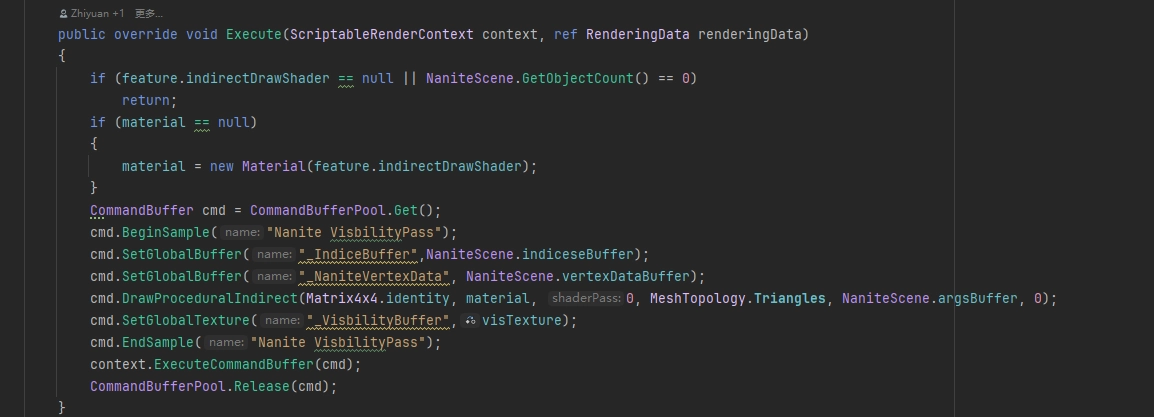
VBuffer에 어떤 속성을 몇 비트로 저장할지는 모두 엔지니어링 디테일이므로 여기서는 깊이 따지지 않겠습니다.
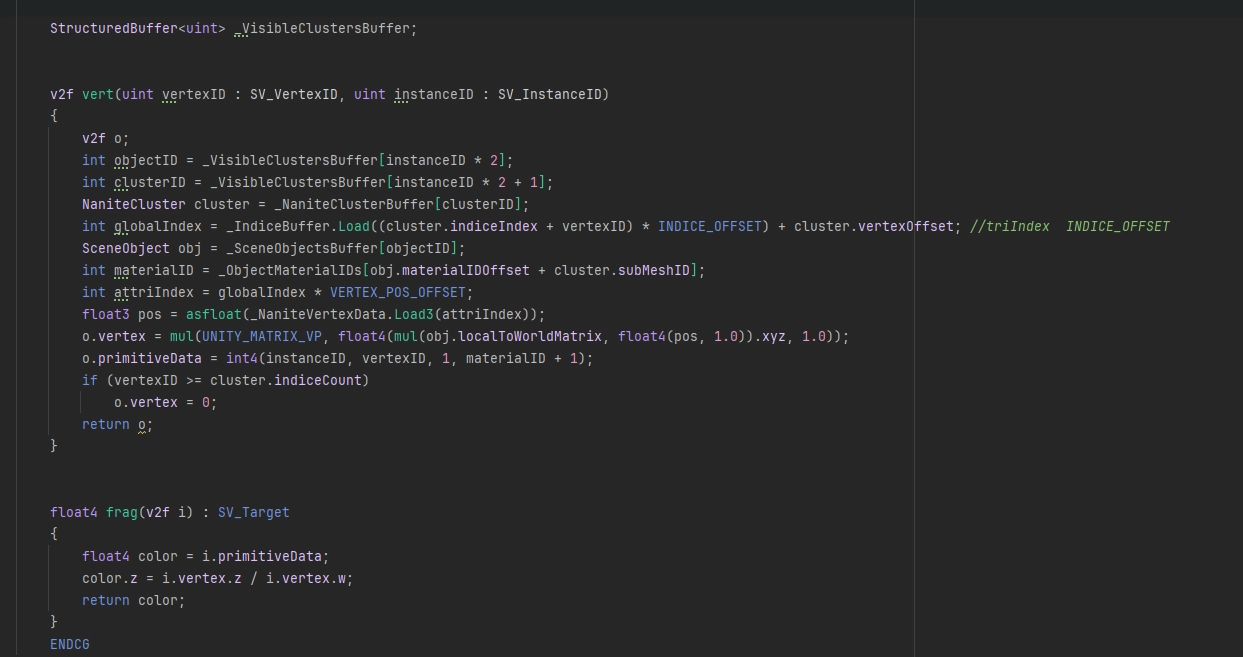
8. 셰이딩
VBuffer가 준비되면 머티리얼별로 그려야 합니다. 원본은 머티리얼 ID를 타일(Tile) 단위로 나누고 IndirectDraw를 조합해 Quad를 그리는 발상입니다.

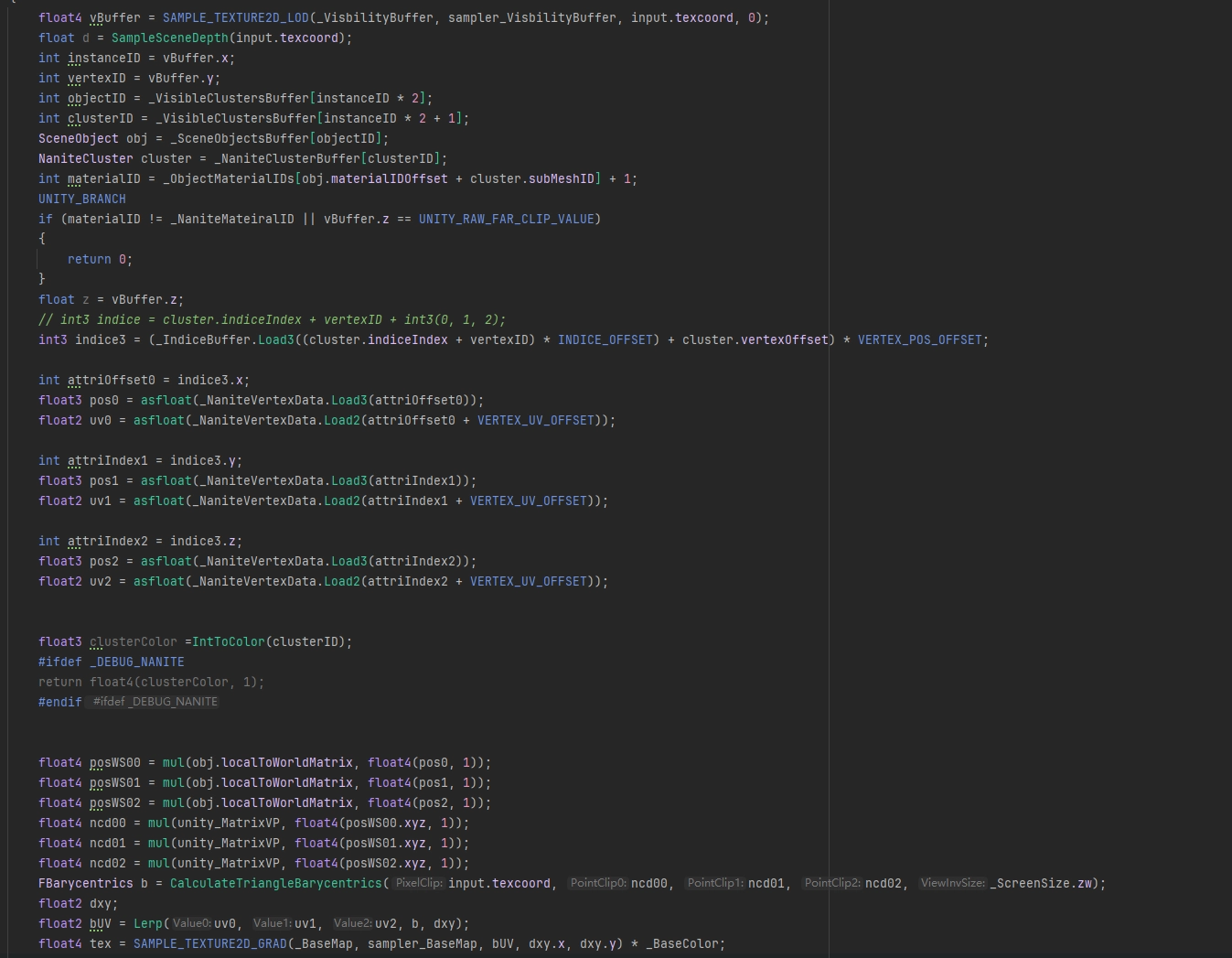

한 가지 주의할 점은, VBuffer에서 삼각형 무게중심 보간으로 구한 UV는 ddx/ddy가 올바르지 않기 때문에 그대로 텍스처 샘플링에 사용할 수 없다는 것입니다. 따라서 다시 계산해야 하며, 계산 코드는 아래에 있습니다. 그리고 SampleGrad(samplerName, coord2, dpdx, dpdy)를 사용해 샘플링합니다.
uint MurmurMix(uint Hash)
{
Hash ^= Hash >> 16;
Hash *= 0x85ebca6b;
Hash ^= Hash >> 13;
Hash *= 0xc2b2ae35;
Hash ^= Hash >> 16;
return Hash;
}
float3 IntToColor(uint Index)
{
uint Hash = MurmurMix(Index);
float3 Color = float3
(
(Hash >> 0) & 255,
(Hash >> 8) & 255,
(Hash >> 16) & 255
);
return Color * (1.0f / 255.0f);
}
struct FBarycentrics
{
float3 Value;
float3 Value_dx;
float3 Value_dy;
};
float2 Lerp(float2 Value0, float2 Value1, float2 Value2, FBarycentrics Barycentrics, out float2 dxy)
{
float2 Value = Value0 * Barycentrics.Value.x + Value1 * Barycentrics.Value.y + Value2 * Barycentrics.Value.z;
dxy.x = Value0 * Barycentrics.Value_dx.x + Value1 * Barycentrics.Value_dx.y + Value2 * Barycentrics.Value_dx.z;
dxy.y = Value0 * Barycentrics.Value_dy.x + Value1 * Barycentrics.Value_dy.y + Value2 * Barycentrics.Value_dy.z;
return Value;
}
/** Calculates perspective correct barycentric coordinates and partial derivatives using screen derivatives. */
FBarycentrics CalculateTriangleBarycentrics(float2 PixelClip, float4 PointClip0, float4 PointClip1,
float4 PointClip2, float2 ViewInvSize)
{
FBarycentrics Barycentrics;
PixelClip.y = 1 - PixelClip.y;
PixelClip.xy = PixelClip.xy * 2 - 1;
const float3 RcpW = rcp(float3(PointClip0.w, PointClip1.w, PointClip2.w));
const float3 Pos0 = PointClip0.xyz * RcpW.x;
const float3 Pos1 = PointClip1.xyz * RcpW.y;
const float3 Pos2 = PointClip2.xyz * RcpW.z;
const float3 Pos120X = float3(Pos1.x, Pos2.x, Pos0.x);
const float3 Pos120Y = float3(Pos1.y, Pos2.y, Pos0.y);
const float3 Pos201X = float3(Pos2.x, Pos0.x, Pos1.x);
const float3 Pos201Y = float3(Pos2.y, Pos0.y, Pos1.y);
const float3 C_dx = Pos201Y - Pos120Y;
const float3 C_dy = Pos120X - Pos201X;
const float3 C = C_dx * (PixelClip.x - Pos120X) + C_dy * (PixelClip.y - Pos120Y);
// Evaluate the 3 edge functions
const float3 G = C * RcpW;
const float H = dot(C, RcpW);
const float RcpH = rcp(H);
// UVW = C * RcpW / dot(C, RcpW)
Barycentrics.Value = G * RcpH;
// Texture coordinate derivatives:
// UVW = G / H where G = C * RcpW and H = dot(C, RcpW)
// UVW' = (G' * H - G * H') / H^2
// float2 TexCoordDX = UVW_dx.y * TexCoord10 + UVW_dx.z * TexCoord20;
// float2 TexCoordDY = UVW_dy.y * TexCoord10 + UVW_dy.z * TexCoord20;
const float3 G_dx = C_dx * RcpW;
const float3 G_dy = C_dy * RcpW;
const float H_dx = dot(C_dx, RcpW);
const float H_dy = dot(C_dy, RcpW);
Barycentrics.Value_dx = (G_dx * H - G * H_dx) * (RcpH * RcpH) * (2.0f * ViewInvSize.x);
Barycentrics.Value_dy = (G_dy * H - G * H_dy) * (RcpH * RcpH) * (-2.0f * ViewInvSize.y);
return Barycentrics;
}
여기까지 하면 사실상 기본적인 구현은 완료된 것입니다. IntToColor 함수를 이용하면 ClusterID나 IndexID를 기준으로 삼각형 또는 Cluster를 시각화할 수 있습니다.

정리
Nanite 기술은 정말이지 너무나 강력하다고 말하지 않을 수 없습니다. 다만 그만큼 처리해야 할 엔지니어링 디테일도 매우 많으며, 본문은 그중 극히 일부만을 구현했습니다. 전체적으로는 이미지의 Mipmap을 처리하는 과정과 닮아 있습니다.
참고
Nanite — A Deep Dive (SIGGRAPH 2021, Brian Karis)
Nanite GPU Driven Rendering (GDC Vault)
UE5 Nanite 소스 코드 진입점:
Engine\\Source\\Runtime\\Renderer\\Private\\Nanite\\NaniteCullRaster.cpp (렌더링 파이프라인 진입점)
Engine\\Shaders\\Private\\Nanite\\ (GPU 셰이더 진입점)
Engine\\Source\\Developer\\NaniteBuilder\\Private\\ (오프라인 Nanite 리소스 생성 진입점)
원문
(73 封私信 / 51 条消息) Unity实现Nanite - 知乎
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [번역] Unity에서 가상 텍스처 구현 (0) | 2026.06.10 |
|---|---|
| SDF Tool 1차 릴리스 했습니다. (0) | 2026.06.08 |
| [번역][기술 분석] 대규모 오픈 월드 게임 제작 프로세스 및 기술 탐구 - 대규모 환경 제작 기술 개요 (0) | 2026.06.07 |
| GODOT HDDAGI 가 뭔가요? 읽어보기. (0) | 2026.06.06 |
| NVIDIA DDGI for Unreal Engine 5.7 (0) | 2026.06.04 |