
역자의 말.
여전히 언리얼 엔진의 이슈를 탐색 하고 렌더링 일부를 수정 하고 관리하고 있지만 RDG 에는 더 많은 이해가 필요 합니다.
그래서 읽고 탐구 해 볼만한 기사를 찾아 공유해 보고자 해요. 분석 기사를 읽고 복기 하면서 렌더 그래프에 대한 분명한 이해력을 향상 시켜봅시다.
RDG 엮인 글.
[주석번역] RDG 101 A Crash Course
역자 주. 요 몇일동안은 아트팀을 직접 지원하는 셰이더 함수작업을 했습니다. 엔진 소스를 수정해야 할 필요가 없는 수요 부터 우선순위를 올려서 작업중이죠. 최대한 엔진 소스를 고치지 않는
techartnomad.tistory.com
[번역]Why Talking About Render Graphs
역자 주. 최근 RDG 를 좀 더 심층적으로 복기하고 있습니다. 뭔가 언리얼엔진 렌더링 부분에서 좀 더 고도화 된 커스터마이징 처리를 하기위해서는 더욱 분명하게 RDG의 재생성, 활용, 사용자화 하
techartnomad.tistory.com
저자
Lnusie1

머리말
RDG(렌더 종속성 그래프)의 설계는 GDC 2017에서 프로스트바이트 엔진 팀이 제안한 프레임그래프에서 처음 시작되었으며, 이후 유니티와 언리얼 모두 유사한 솔루션을 구현했습니다.
최신 게임 엔진에서 렌더링 기능이 점점 더 확장됨에 따라 기존의 렌더링 파이프라인 즉시 렌더링 방식은 기능 간의 긴밀한 결합, 기능 개발자가 리소스의 수명 주기를 수동으로 관리해야 하고 기능 확장이 어려운 등 많은 문제를 야기할 수 있습니다. 이러한 문제를 해결하기 위해 RDG가 탄생했습니다.

배틀필드 4에서 이렇게 많은 기능을 지원하려면 보다 고급 아키텍처 설계가 필요합니다.
RDG의 주요 설계 아이디어는 "지연 실행"으로, 각 기능의 개발자는 패스의 구현과 입출력에만 집중하면 되고, 패스에 사용되는 실제 리소스와 패스 간의 종속성은 RDG가 처리하도록 맡겨두었습니다. 또한 RDG는 하위 수준에서 렌더링 파이프라인을 최적화하기 위해 수동 배리어 및 MemoryAlias와 같은 최신 API 기능의 적용을 용이하게 하기 위해 도입되었습니다.
미리 읽기:
프로스트바이트 엔진 그룹에서 공유
https://www.slideshare.net/slideshow/framegraph-extensible-rendering-architecture-in-frostbite/72795495
FrameGraph: Extensible Rendering Architecture in Frostbite
FrameGraph: Extensible Rendering Architecture in Frostbite - Download as a PDF or view online for free
www.slideshare.net
UE 공식 RDG 문서:Render Dependency Graph
RDG 리소스
FRDGResource
RDG의 리소스는 텍스처와 버퍼의 캡슐화 레이어인 FRDGTexture와 FRDGBuffer로 나뉘며, RDG의 리소스 사용에 대한 정보도 기록합니다.
둘 다 리소스에 대한 실제 RHI 포인터를 보유하는 기본 클래스 FRDGResource에서 상속합니다.
class FRDGResource
{
...
FRHIResource* ResourceRHI = nullptr;
...
}
FRDGTexture와 FRDGBuffer는 리소스의 빈 셸에 불과한 FRDGBuilder::CreateTexture와 FRDGBuilder::CreateBuffer에 의해 생성되며, 실제 리소스는 RDG가 실행될 때 할당됩니다. 불필요한 패스와 패스에 사용된 리소스가 컴파일 시 잘려나가고 최종적으로 정말 필요한 리소스만 생성된다는 점이 RDG의 '지연 실행'의 장점 중 하나입니다.
FRDGTextureRef CreateTexture(const FRDGTextureDesc& Desc, const TCHAR* Name, ERDGTextureFlags Flags = ERDGTextureFlags::None);
FRDGBufferRef CreateBuffer(const FRDGBufferDesc& Desc, const TCHAR* Name, ERDGBufferFlags Flags = ERDGBufferFlags::None);
Extrarnal Resource
외부 텍스처와 버퍼는 RDG 외부의 외부 수단인 RegisterExternalTexture와 RegisterExternalBuffer를 통해 등록하며, 수명 주기는 RDG에서 관리하지 않습니다.
FRDGTextureRef RegisterExternalTexture(const TRefCountPtr<IPooledRenderTarget>& ExternalPooledTexture,ERDGTextureFlags Flags = ERDGTextureFlags::None);
FRDGBufferRef RegisterExternalBuffer(const TRefCountPtr<FRDGPooledBuffer>& ExternalPooledBuffer, ERDGBufferFlags Flags = ERDGBufferFlags::None);
예를 들어 UE4.2x 버전에서는 RDG가 아직 엔진에 완전히 적용되지 않았기 때문에 SceneColor, SceneDepth 같은 씬 텍스처는 수명 주기 동안 별도로 유지되며, 이를 사용하기 전에 RegisterExternalTexture 를 호출하여 마킹해야 합니다.
외부로 표시된 리소스는 RDG에서 관리하지 않는 수명 주기를 가지므로 출력이 외부인 패스의 경우 해당 리소스도 잘리지 않습니다.
Extract Resource
QueueTextureExtraction과 QueueBufferExtraction을 사용하면 텍스처와 버퍼를 RDG 외부로 익스포트할 수 있습니다. 예를 들어 일부 알고리즘에서 이전 프레임의 패스 결과를 사용해야 하는 경우, 이를 익스포트하여 재사용할 수 있습니다.
void FRDGBuilder::QueueTextureExtraction(FRDGTextureRef Texture, TRefCountPtr<IPooledRenderTarget>* OutTexturePtr, ERDGResourceExtractionFlags Flags)
{
*OutTexturePtr = nullptr;
Texture->bExtracted = true;
...
ExtractedTextures.Emplace(Texture, OutTexturePtr);
}
void FRDGBuilder::QueueBufferExtraction(FRDGBufferRef Buffer, TRefCountPtr<FRDGPooledBuffer>* OutBufferPtr)
{
*OutBufferPtr = nullptr;
Buffer->bExtracted = true;
Buffer->bForceNonTransient = true;
ExtractedBuffers.Emplace(Buffer, OutBufferPtr);
}
RDG 기본 프로세스
RDG의 기본 실행 흐름은 다음과 같습니다.

패스 추가
패스는 패스의 이름, 필수 파라미터, 패스 유형, 패스가 실제로 실행하는 콜백을 전달하여 FRDGBuilder::AddPass를 통해 RDG에 추가됩니다.
template <typename ParameterStructType, typename ExecuteLambdaType>
FRDGPassRef AddPass(FRDGEventName&& Name, const ParameterStructType* ParameterStruct, ERDGPassFlags Flags, ExecuteLambdaType&& ExecuteLambda);예를 들어 SceneColorRendering의 패스 추가 기능입니다.
GraphBuilder.AddPass(
RDG_EVENT_NAME("SceneColorRendering"),PassParameters,ERDGPassFlags::Raster,
[this, PassParameters, ViewContext, &SceneTextures](FRHICommandList& RHICmdList)
{
FViewInfo& View = *ViewContext.ViewInfo;
...
RenderMobileBasePass(RHICmdList, View);
RenderMobileDebugView(RHICmdList, View);
PostRenderBasePass(RHICmdList, View);
});
AddPass의 매개 변수인 ParameterStruct와 Flags에 대해 설명합니다.
파라미터스트럭트는 BEGIN_SHADER_PARAMETER_STRUCT와 같은 매크로를 사용하여 정의된 데이터 구조로, SHADER_PARAMETER_RDG_XX를 통해 정의된 데이터는 RDG가 사용하는 리소스를 나타내며, 원칙적으로 원래 SHADER_PARAMETER_XXX 선언과 크게 다르지 않습니다. 셰이더 파라미터의 선언은 래핑된 데이터가 FRDGResource라는 점을 제외하면 원칙적으로 크게 다르지 않습니다.
BEGIN_SHADER_PARAMETER_STRUCT(FMobileRenderPassParameters, RENDERER_API)
SHADER_PARAMETER_STRUCT_INCLUDE(FViewShaderParameters, View)
SHADER_PARAMETER_RDG_UNIFORM_BUFFER(FSceneUniformParameters, Scene)
SHADER_PARAMETER_RDG_UNIFORM_BUFFER(FMobileBasePassUniformParameters, MobileBasePass)
SHADER_PARAMETER_STRUCT_REF(FMobileReflectionCaptureShaderData, ReflectionCapture)
SHADER_PARAMETER_RDG_BUFFER_SRV(Buffer<float4>, LocalHeightFogInstances)
RDG_BUFFER_ACCESS_ARRAY(DrawIndirectArgsBuffers)
RDG_BUFFER_ACCESS_ARRAY(InstanceIdOffsetBuffers)
RENDER_TARGET_BINDING_SLOTS()
END_SHADER_PARAMETER_STRUCT()
플래그는 패스 유형과 컴파일 및 실행 시간 설정을 설명하는 데 사용됩니다.
enum class ERDGPassFlags : uint16
{
None = 0,
Raster = 1 << 0,//光栅化的Pass、也就是一般的渲染Pass
Compute = 1 << 1,//CS的Pass
AsyncCompute = 1 << 2,//运行在异步管线的CS,只在特定设备上支持,不支持的话会fallback为Compute
Copy = 1 << 3,//用于拷贝数据的Pass
NeverCull = 1 << 4,//不剔除
SkipRenderPass = 1 << 5,//在执行Raster Pass时,不调用BeginRenderPass(仅可以和Raster一起使用)
NeverMerge = 1 << 6, //不与其他Pass合并
NeverParallel = 1 << 7,//不并行执行
ParallelTranslate = 1 << 8,
Readback = Copy | NeverCull //数据回读到CPU
};
template <typename ParameterStructType, typename ExecuteLambdaType>
FRDGPassRef FRDGBuilder::AddPassInternal(
FRDGEventName&& Name,
const FShaderParametersMetadata* ParametersMetadata,
const ParameterStructType* ParameterStruct,
ERDGPassFlags Flags,
ExecuteLambdaType&& ExecuteLambda)
{
using LambdaPassType = TRDGLambdaPass<ParameterStructType, ExecuteLambdaType>;
FRDGPass* Pass = Allocator.AllocNoDestruct<LambdaPassType>(
MoveTemp(Name),
ParametersMetadata,
ParameterStruct,
OverridePassFlags(Name.GetTCHAR(), Flags),
MoveTemp(ExecuteLambda));
Passes.Insert(Pass);
SetupParameterPass(Pass);
return Pass;
}Pass는 SetupParameterPass에서 초기화됩니다. 그런 다음 SetupPassResources를 호출하여 Pass에서 사용하는 FRDGResource를 초기화합니다:
주요 로직은 패스에 사용된 텍스처와 버퍼를 반복처리하고, 텍스처를 사용한 첫 번째와 마지막 패스를 표시하는 것이며, 패스의 TextureStates 는 텍스처의 사용 상태와 레퍼런스 수를 현재 Pass.FRDGPass::FTextureState 의 State 는 하나 이상의 FRDGSubresourceState 를 보유합니다.
EnumerateTextureAccess(PassParameters, PassFlags, [&](FRDGViewRef TextureView, FRDGTextureRef Texture, ERHIAccess Access, ERDGTextureAccessFlags AccessFlags, FRDGTextureSubresourceRange Range)
{
TryAddView(TextureView);
const FRDGViewHandle NoUAVBarrierHandle = GetHandleIfNoUAVBarrier(TextureView);
const EResourceTransitionFlags TransitionFlags = GetTextureViewTransitionFlags(TextureView, Texture);
FRDGPass::FTextureState* PassState;
if (Texture->LastPass != PassHandle)
{
Texture->LastPass = PassHandle;
Texture->PassStateIndex = static_cast<uint16>(Pass->TextureStates.Num());
PassState = &Pass->TextureStates.Emplace_GetRef(Texture);
}
else
{
PassState = &Pass->TextureStates[Texture->PassStateIndex];
}
PassState->ReferenceCount++;
EnumerateSubresourceRange(PassState->State, Texture->Layout, Range, [&](FRDGSubresourceState& State)
{
State.Access = MakeValidAccess(State.Access, Access);
State.Flags |= TransitionFlags;
State.NoUAVBarrierFilter.AddHandle(NoUAVBarrierHandle);
State.SetPass(PassPipeline, PassHandle);
});
if (IsWritableAccess(Access))
{
bRenderPassOnlyWrites &= EnumHasAnyFlags(AccessFlags, ERDGTextureAccessFlags::RenderTarget);
if (!bParallelSetupEnabled)
{
Texture->bProduced = true;
}
}
});Texture->bProduced = true;
}
}
});
FRDGSubresourceState의 주요 멤버는 아래에 나열되어 있으며, 이 정보는 나중에 컴파일하는 데 필요한 기반을 제공합니다.
struct FRDGSubresourceState
{
/*
对资源的访问操作,比如"在CPU读取"、"在GraphicShader中读取"、
"在ComputerShader中读取"、"在GraphicShader中写入"
通过这个字段,后续能分析出当前的资源的在Pass中输入输出状态
*/
ERHIAccess Access = ERHIAccess::Unknown;
/*
Resource Transition 标签,为后续Barrier的添加提供额外的要求
*/
EResourceTransitionFlags Flags = EResourceTransitionFlags::None;
/*
RHI管线, ERHIPipeline::Graphics或ERHIPipeline::AsyncCompute.
现代的GPU可能支持并行执行两个管线以提升并行效率。
并不是说Compute只能在AsyncCompute管线中执行,在Graphics执行也是可以的。
*/
ERHIPipeline Pipeline = ERHIPipeline::Graphics;
FRDGPassHandle FirstPass;//引用这个资源的第一个Pass (合并Pass时会用到)
FRDGPassHandle LastPass;//引用这个资源的最后一个Pass
}
버퍼의 설정은 텍스처와 비슷하기 때문에 여기서는 다루지 않겠습니다~.
Prologue Pass와Epilogue Pass
실행과 컴파일을 쉽게 하기 위해 RDG는 패스 목록에 두 개의 빈 패스를 보조 노드로 추가하고, 프롤로그 패스는 FRDGBuilder 구성 시 추가하며, 에플로그 패스는 FRDGBuilder::Execute 메서드의 맨 처음에 추가합니다.
패스 편집
FRDGBuilder::Compile() 항목 컴파일 FRDGBuilder::Execute()에서 실행되는 패스의 공식 실행 전에 수집된 패스에 대한 컴파일 작업을 수행해야 하며, 그 목적은 최종 결과에 기여하지 않는 패스를 잘라 불필요한 소비를 줄이고, 조건을 충족하는 패스를 병합하여 다음과 같이 하는 것입니다. 패스의 시작과 끝에서 소비를 줄이기 위해서입니다.
패스 트리밍
가지 치기의 목적은 최종 결과물(또는 추출의 리소스)에 기여하지 않는 패스를 제거하고 불필요한 소비를 줄이는 것입니다. 첫 번째 단계는 "생산자/소비자" 종속성을 구축하는 것입니다. 예를 들어 아래 그림에서 RDG에 순차적으로 추가되는 세 개의 패스, 즉 패스 A, B, C가 있는데, 이 중 TextureC는 최종 렌더링이므로 TextureC를 출력하는 패스C는 크롭할 수 없고, 패스C가 의존하는 입력 TextureA는 패스A가 출력하므로 패스A도 크롭할 수 없습니다. 그리고 PassB에 의해 출력되는 TextureB는 PassC에 종속되지 않으므로 PassB를 잘라낼 수 있고 TextureB를 할당 해제할 수 있습니다.
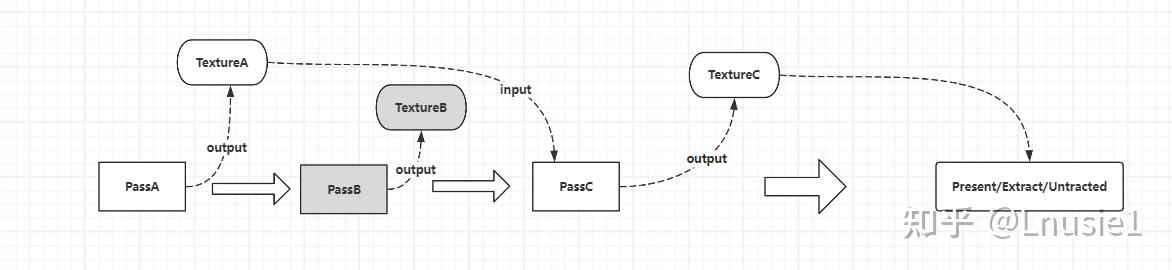
구현 측면에서 FRDG 리소스에는 해당 리소스를 출력하는 패스를 가리키는 LastProducer 목록이 있습니다.
패스에는 종속 패스(다른 패스에서 생성된 리소스를 사용하는 패스)를 가리키는 LastProducer 목록도 있습니다.
프롤로그 패스와 에필로그 패스를 제외한 패스를 반복하고 SetupPassDependencies를 호출하여 리소스와 패스, 패스와 패스 간의 종속성을 구축합니다.
에필로그, 출력 엑스트라 패스도 루트 노드로 설정합니다. 먼저 모든 노드(프롤로그 제외)를 bculled = true로 설정합니다.
마지막으로 모든 루트 노드를 반복하고 모든 루트 종속 노드를 bculled = false로 설정하고 설정되지 않은 나머지 노드는 컬링(역방향 작업)할 수 있는 노드로 설정합니다.
키코드
void FRDGBuilder::Compile()
{
if (bCullPasses)
{
CullPassStack.Reserve(CompilePassCount);
}
if (bCullPasses || AsyncComputePassCount > 0)
{
SCOPED_NAMED_EVENT(PassDependencies, FColor::Emerald);
if (!bParallelSetupEnabled)
{
for (FRDGPassHandle PassHandle = ProloguePassHandle + 1; PassHandle < EpiloguePassHandle; ++PassHandle)
{
SetupPassDependencies(Passes[PassHandle]);
}
}
const auto AddLastProducersToCullStack = [&](const FRDGProducerStatesByPipeline& LastProducers)
{
for (const FRDGProducerState& LastProducer : LastProducers)
{
if (LastProducer.Pass)
{
CullPassStack.Emplace(LastProducer.Pass->Handle);
}
}
};
for (const FExtractedTexture& ExtractedTexture : ExtractedTextures)
{
FRDGTextureRef Texture = ExtractedTexture.Texture;
for (auto& LastProducer : Texture->LastProducers)
{
AddLastProducersToCullStack(LastProducer);
}
}
for (const FExtractedBuffer& ExtractedBuffer : ExtractedBuffers)
{
FRDGBufferRef Buffer = ExtractedBuffer.Buffer;
AddLastProducersToCullStack(Buffer->LastProducer);
}
for (const auto& Pair : ExternalTextures)
{
FRDGTexture* Texture = Pair.Value;
for (auto& LastProducer : Texture->LastProducers)
{
AddLastProducersToCullStack(LastProducer);
}
}
for (const auto& Pair : ExternalBuffers)
{
FRDGBuffer* Buffer = Pair.Value;
AddLastProducersToCullStack(Buffer->LastProducer);
}
}
else if (!bParallelSetupEnabled)
{
...
}
if (bCullPasses)
{
CullPassStack.Emplace(EpiloguePassHandle);
//标记EpiloguePass以便从最后的pass开始遍历
EpiloguePass->bCulled = 1;
//第一个Pass永不剔除
ProloguePass->bCulled = 0;
//从EpiloguePass的根节点开始遍历,把所有依赖的pass的bCulled置为0,没有置为0的,说明跟根节点没联系,可以Cull
while (CullPassStack.Num())
{
FRDGPass* Pass = Passes[CullPassStack.Pop()];
if (Pass->bCulled)
{
Pass->bCulled = 0;
CullPassStack.Append(Pass->Producers);
}
}
//遍历要剔除的pass,减去其对资源的引用计数
for (FRDGPassHandle PassHandle = ProloguePassHandle + 1; PassHandle < EpiloguePassHandle; ++PassHandle)
{
FRDGPass* Pass = Passes[PassHandle];
if (!Pass->bCulled)
{
continue;
}
// Subtract reference counts from culled passes that were added during pass setup.
for (auto& PassState : Pass->TextureStates)
{
PassState.Texture->ReferenceCount -= PassState.ReferenceCount;
}
for (auto& PassState : Pass->BufferStates)
{
PassState.Buffer->ReferenceCount -= PassState.ReferenceCount;
}
}
}
}
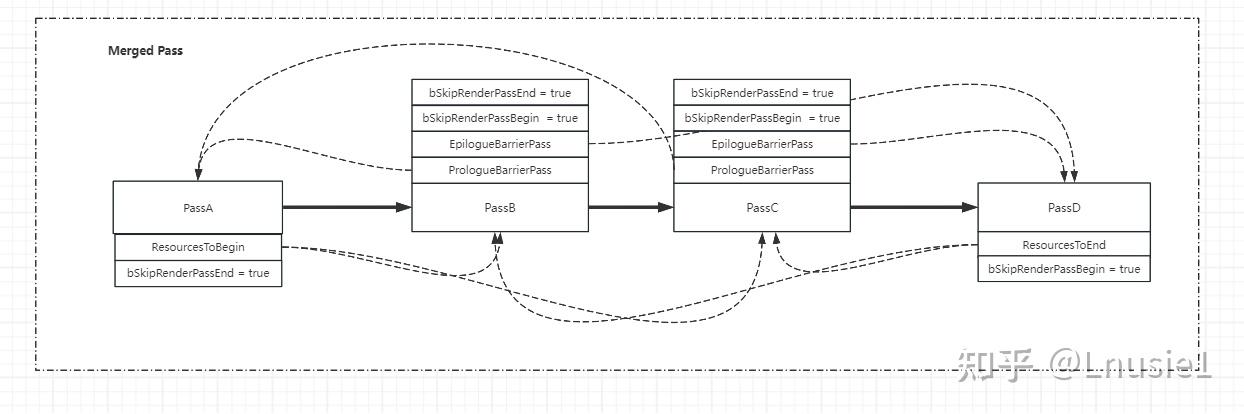
패스 통합
병합해야 하는 이유:
a. RT 전환 등과 같은 패스 시작 및 종료의 오버헤드를 줄입니다.

합병 조건:
1. 인접 패스를 순차적으로 추가합니다
2. 래스터의 패스만 추가합니다
3. 패스가 SkipRenderPass 또는 NerverMerge로 표시되지 않습니다
4. RenderTarget이 동일하고 RT에서의 연산이 동일합니다(LoadAction, subpassHint는 동일합니다.).
5. GPUMask가 동일해야 합니다(여러 GPU가 있는 경우).
합병의 논리:
먼저 패스를 순서대로 반복하고 위의 조건을 충족하는 두 패스가 합쳐지면 병합할 수 있습니다.
void FRDGBuilder::Compile()
{
...
if (IsRenderPassMergeEnabled() && RasterPassCount > 0)
{
TArray<FRDGPassHandle, TInlineAllocator<32, FRDGArrayAllocator>> PassesToMerge;
FRDGPass* PrevPass = nullptr;
const FRenderTargetBindingSlots* PrevRenderTargets = nullptr;
const auto CommitMerge = [&]
{
if (PassesToMerge.Num())
{
const auto SetEpilogueBarrierPass = [&](FRDGPass* Pass, FRDGPassHandle EpilogueBarrierPassHandle)
{
Pass->EpilogueBarrierPass = EpilogueBarrierPassHandle;
Pass->ResourcesToEnd.Reset();
Passes[EpilogueBarrierPassHandle]->ResourcesToEnd.Add(Pass);
};
const auto SetPrologueBarrierPass = [&](FRDGPass* Pass, FRDGPassHandle PrologueBarrierPassHandle)
{
Pass->PrologueBarrierPass = PrologueBarrierPassHandle;
Pass->ResourcesToBegin.Reset();
Passes[PrologueBarrierPassHandle]->ResourcesToBegin.Add(Pass);
};
const FRDGPassHandle FirstPassHandle = PassesToMerge[0];
const FRDGPassHandle LastPassHandle = PassesToMerge.Last();
Passes[FirstPassHandle]->ResourcesToBegin.Reserve(PassesToMerge.Num());
Passes[LastPassHandle]->ResourcesToEnd.Reserve(PassesToMerge.Num());
{
FRDGPass* Pass = Passes[FirstPassHandle];
Pass->bSkipRenderPassEnd = 1;
SetEpilogueBarrierPass(Pass, LastPassHandle);
}
for (int32 PassIndex = 1, PassCount = PassesToMerge.Num() - 1; PassIndex < PassCount; ++PassIndex)
{
const FRDGPassHandle PassHandle = PassesToMerge[PassIndex];
FRDGPass* Pass = Passes[PassHandle];
Pass->bSkipRenderPassBegin = 1;
Pass->bSkipRenderPassEnd = 1;
SetPrologueBarrierPass(Pass, FirstPassHandle);
SetEpilogueBarrierPass(Pass, LastPassHandle);
}
{
FRDGPass* Pass = Passes[LastPassHandle];
Pass->bSkipRenderPassBegin = 1;
SetPrologueBarrierPass(Pass, FirstPassHandle);
}
}
PassesToMerge.Reset();
PrevPass = nullptr;
PrevRenderTargets = nullptr;
};
for (FRDGPassHandle PassHandle = ProloguePassHandle + 1; PassHandle < EpiloguePassHandle; ++PassHandle)
{
FRDGPass* NextPass = Passes[PassHandle];
if (NextPass->bCulled || NextPass->bEmptyParameters)//标记为cull和不带参数的pass不处理
{
continue;
}
if (EnumHasAnyFlags(NextPass->Flags, ERDGPassFlags::Raster))//必须是渲染的pass才能合并
{
// A pass where the user controls the render pass or it is forced to skip pass merging can't merge with other passes
if (EnumHasAnyFlags(NextPass->Flags, ERDGPassFlags::SkipRenderPass | ERDGPassFlags::NeverMerge))
{
CommitMerge();
continue;
}
if (!NextPass->bRenderPassOnlyWrites)//bRenderPassOnlyWrites表示只对RenderTarget有写入,比如还有buffer的写入那就不行(合并只针对相同RT的pass)
{
CommitMerge();
continue;
}
const FRenderTargetBindingSlots& RenderTargets = NextPass->GetParameters().GetRenderTargets();
if (PrevPass)
{
check(PrevRenderTargets);
if (PrevRenderTargets->CanMergeBefore(RenderTargets)
#if WITH_MGPU
&& PrevPass->GPUMask == NextPass->GPUMask//GPU需要相同(如果有多颗的话)
#endif
)
{
if (!PassesToMerge.Num())
{
PassesToMerge.Add(PrevPass->GetHandle());
}
PassesToMerge.Add(PassHandle);
}
else
{
CommitMerge();
}
}
PrevPass = NextPass;
PrevRenderTargets = &RenderTargets;
}
else if (!EnumHasAnyFlags(NextPass->Flags, ERDGPassFlags::AsyncCompute))
{
// A non-raster pass on the graphics pipe will invalidate the render target merge.
CommitMerge();
}
}
CommitMerge();
}
...
}
병합과 관련된 FRDGPass의 몇 가지 필드:
class FRDGPass
{
...
uint32 bSkipRenderPassBegin : 1; //是否跳过BeginRenderPass
uint32 bSkipRenderPassEnd : 1;//是否跳过EndRenderPass
FRDGPassHandle PrologueBarrierPass; //指向合并后Pass的第一个Pass,默认指向自身
FRDGPassHandle EpilogueBarrierPass;//指向合并后Pass的最后一个Pass,默认指向自身
TArray<FRDGPass*, TInlineAllocator<1, FRDGArrayAllocator>> ResourcesToBegin; //合并后的第一个Pass需要开始生命周期的资源的Pass
TArray<FRDGPass*, TInlineAllocator<1, FRDGArrayAllocator>> ResourcesToEnd;//合并后的最后一个Pass需要开始生命周期的资源的Pass
}
예를 들어 인접한 PassA, B, C, D가 여러 개 있는데 이를 병합하여 얻는다고 가정해 보겠습니다:
Fork/Joint 균형
그래픽과 병렬로 동작하지만 리소스 종속성이 있을 수 있는 AsyncComputePass의 경우.
이 단계는 나중에 CollectBarrier를 준비하기 위해 "생산자/소비자" 관계, 즉 분기점과 수렴점에 따라 AsyncCompute와 Graphic의 포크/조인을 찾는 단계입니다.

코드는 다음과 같습니다:
void FRDGBuilder::Compile()
{
//cull...
//merge...
if (AsyncComputePassCount > 0)
{
FRDGPassHandle CurrentGraphicsForkPassHandle;
FRDGPass* AsyncComputePassBeforeFork = nullptr;
for (FRDGPassHandle PassHandle = ProloguePassHandle + 1; PassHandle < EpiloguePassHandle; ++PassHandle)
{
FRDGPass* AsyncComputePass = Passes[PassHandle];
if (!AsyncComputePass->IsAsyncCompute() || AsyncComputePass->bCulled)
{
continue;
}
FRDGPassHandle GraphicsForkPassHandle = FRDGPassHandle::Max(AsyncComputePass->CrossPipelineProducer, FRDGPassHandle::Max(CurrentGraphicsForkPassHandle, ProloguePassHandle));
FRDGPass* GraphicsForkPass = Passes[GraphicsForkPassHandle];
AsyncComputePass->GraphicsForkPass = GraphicsForkPassHandle;
Passes[GraphicsForkPass->PrologueBarrierPass]->ResourcesToBegin.Add(AsyncComputePass);
if (CurrentGraphicsForkPassHandle != GraphicsForkPassHandle)
{
CurrentGraphicsForkPassHandle = GraphicsForkPassHandle;
FRDGBarrierBatchBegin& EpilogueBarriersToBeginForAsyncCompute = GraphicsForkPass->GetEpilogueBarriersToBeginForAsyncCompute(Allocator, TransitionCreateQueue);
GraphicsForkPass->bGraphicsFork = 1;
EpilogueBarriersToBeginForAsyncCompute.SetUseCrossPipelineFence();
AsyncComputePass->bAsyncComputeBegin = 1;
AsyncComputePass->GetPrologueBarriersToEnd(Allocator).AddDependency(&EpilogueBarriersToBeginForAsyncCompute);
// Since we are fencing the graphics pipe to some new async compute work, make sure to flush any prior work.
if (AsyncComputePassBeforeFork)
{
AsyncComputePassBeforeFork->bDispatchAfterExecute = 1;
}
}
AsyncComputePassBeforeFork = AsyncComputePass;
}
FRDGPassHandle CurrentGraphicsJoinPassHandle;
for (FRDGPassHandle PassHandle = EpiloguePassHandle - 1; PassHandle > ProloguePassHandle; --PassHandle)
{
FRDGPass* AsyncComputePass = Passes[PassHandle];
if (!AsyncComputePass->IsAsyncCompute() || AsyncComputePass->bCulled)
{
continue;
}
FRDGPassHandle CrossPipelineConsumer;
// Cross pipeline consumers are sorted. Find the earliest consumer that isn't culled.
for (FRDGPassHandle ConsumerHandle : AsyncComputePass->CrossPipelineConsumers)
{
FRDGPass* Consumer = Passes[ConsumerHandle];
if (!Consumer->bCulled)
{
CrossPipelineConsumer = ConsumerHandle;
break;
}
}
FRDGPassHandle GraphicsJoinPassHandle = FRDGPassHandle::Min(CrossPipelineConsumer, FRDGPassHandle::Min(CurrentGraphicsJoinPassHandle, EpiloguePassHandle));
FRDGPass* GraphicsJoinPass = Passes[GraphicsJoinPassHandle];
AsyncComputePass->GraphicsJoinPass = GraphicsJoinPassHandle;
Passes[GraphicsJoinPass->EpilogueBarrierPass]->ResourcesToEnd.Add(AsyncComputePass);
if (CurrentGraphicsJoinPassHandle != GraphicsJoinPassHandle)
{
CurrentGraphicsJoinPassHandle = GraphicsJoinPassHandle;
FRDGBarrierBatchBegin& EpilogueBarriersToBeginForGraphics = AsyncComputePass->GetEpilogueBarriersToBeginForGraphics(Allocator, TransitionCreateQueue);
AsyncComputePass->bAsyncComputeEnd = 1;
AsyncComputePass->bDispatchAfterExecute = 1;
EpilogueBarriersToBeginForGraphics.SetUseCrossPipelineFence();
GraphicsJoinPass->bGraphicsJoin = 1;
GraphicsJoinPass->GetPrologueBarriersToEnd(Allocator).AddDependency(&EpilogueBarriersToBeginForGraphics);
}
}
}
}
포크 추가:
그래픽스포크패스의 PrologueBarrierPass 의 ResourcesToStart 가 ComputePass 에 추가되었습니다
그래픽스포크패스에 할당된 EpilogueBarriersToBeginForAsyncCompute, 유형이 FRDGBarrierBatchBegin인
AsyncComputePass 에 할당된 PrologueBarriersToEnd, 유형이 FRDGBarrierBatchEnd인 유형인 반면, 위의 FRDGBarrierBatchBegin 을 종속성으로 취합니다.

Fork의 처리.
Join
GraphicsJoinPass 의 EpilogueBarrierPass 의 ResourcesToBegin 에 추가됨
AsyncComputePass 에 할당된 EpilogueBarriersToBeginForGraphics, 유형이 FRDGBarrierBatchBegin인
GraphicsJoinPass 에 할당된 PrologueBarriersToEnd, 유형이 FRDGBarrierBatchEnd입니다.
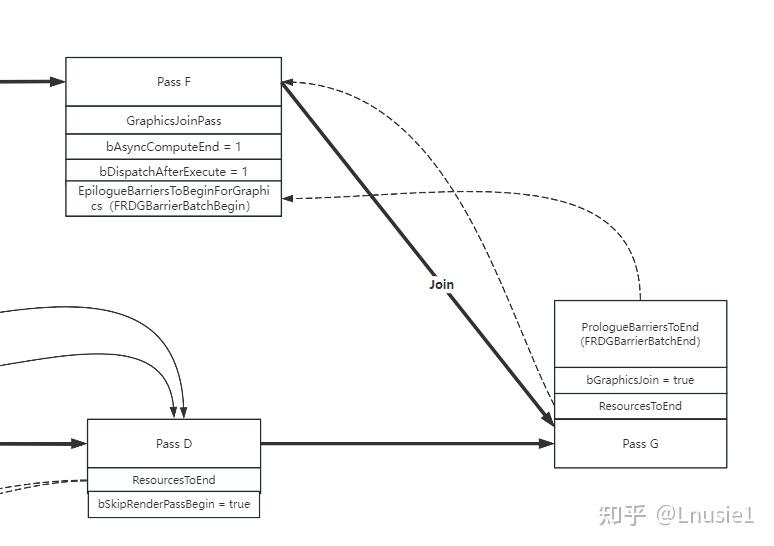
조인 처리
보시다시피 이 단계의 주요 목적은 포크와 조인의 양쪽에 FRDGBarrierBatchBegin과 FRDGBarrierBatchEnd 세트를 할당하는 것인데, 이 두 클래스의 역할은 무엇일까요? 다음은 RDG에서 보다 중심적인 위치인 Barrier에 대한 내용입니다!
배리어 수집 및 삽입
메모리 배리어 소개
GPU에서는 데이터 읽기 속도를 높이기 위해 코어와 메인 RAM 사이에 L1 및 L2 캐시가 추가됩니다. 이는 캐시 일관성 문제를 처리하는 것을 의미합니다. 예를 들어 PassA와 PassB가 동일한 리소스에 대해 읽기-후-쓰기를 하는 경우, PassA가 데이터를 쓸 때 데이터가 L1에 그냥 존재할 수 있는데, 나중에 Pass가 올바른 데이터를 읽기 위해서는 PassA가 실행이 끝나면 Flush를 해야 하는데, 이는 데이터를 L2로 플러시하는 작업을 기술적으로 표현하는 용어입니다. 메모리 사용 가능(Availbale)을 위한 기술 용어입니다. PassB가 데이터를 읽을 때 L1의 데이터를 바로 읽는 것은 잘못될 수 있으므로 PassB가 실행을 완료하기 전에 L1을 무효화한 다음 L2에서 L1으로 데이터를 플러시하는 작업을 해야 하는데, 이를 기술 용어로는 Visible이라고 합니다. 이 작업을 수행하는 도구는 Barrier입니다.

GPU의 논리적 아키텍처
또한, GPU는 데이터에 대한 다양한 액세스 작업을 최적화하기 위해 보다 최적화된 메모리 레이아웃을 제공할 수 있습니다(예: 매핑을 위한 읽기, 쓰기, 제시가 서로 다른 메모리 레이아웃에 해당할 수 있음). "읽기 후 쓰기"의 경우, 데이터를 읽기 전에 GPU가 먼저 데이터를 읽기에 더 적합한 레이아웃으로 변환할 수 있습니다. 따라서 메모리 배리어에는 메모리 레이아웃 변환 기능도 있습니다.
전환 및 베리어
RDG에서 서로 다른 패스 간의 균일한 리소스에 대한 읽기/쓰기 종속성을 처리하기 위해 UE는 트랜지션 개념을 도입했습니다. 트랜지션은 패스 간 리소스의 단일 변환을 나타냅니다.

다시 하부 레이어로 돌아가서 트랜지션은 어떻게 구현될까요? Vulkan을 예로 들어 GPU 파티클을 구현한다고 가정하면, ComputePass A에서 계산된 파티클의 버텍스 데이터를 Buffer에 쓰고, Compute Pass A의 실행이 완료된 후 배리어를 삽입해야 합니다(srcAccessMask = VK_ACCESS_SHADER_WRITE_BIT , dstAccessMask = 0)를 삽입하여 패스 A에서 버퍼에 쓰기가 끝났음을 표시하고 메모리를 사용할 수 있게 합니다. 래스터 패스 B가 실행되기 전에 배리어(srcAccessMask = 0,dstAccessMask = VK_ACCESS_VERTEX_ATTRIBUTE_READ_BIT)를 삽입하여 패스 B의 버퍼에 읽기 시작을 표시하고 메모리를 표시할 수 있도록 해야 합니다.
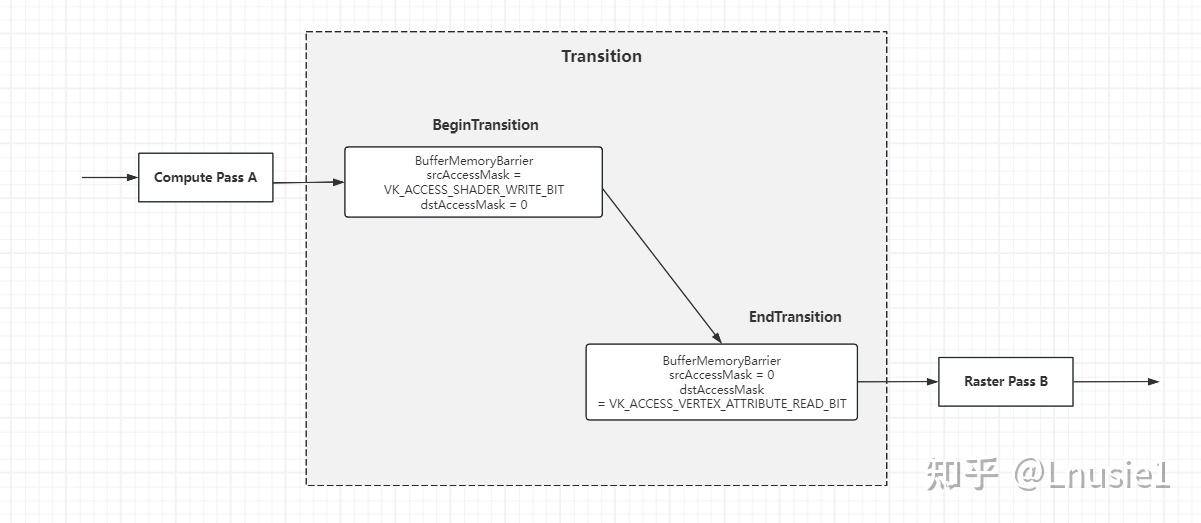
Transition的本值就是一组Barrier
요약하자면, 트랜지션은 리소스의 상태를 전환하는 프로세스를 나타냅니다. 구현 측면에서는 다음과 같이 나타냅니다.
a.BeginTransition: 제너레이터 패스 뒤에 배리어를 삽입하여 이전 메모리 액세스 상태의 끝을 표시합니다.
위에서 언급했듯이 FRDGBarrierBatchBegin과 FRDGBarrierBatchEnd는 쌍으로 존재하는 BeginTransition과 EndTransition을 구현하는 데 사용됩니다.
주요 데이터 멤버는 다음과 같습니다:
class FRDGBarrierBatchBegin
{
...
const FRHITransition* Transition = nullptr;
TArray<FRHITransitionInfo, FRDGArrayAllocator> Transitions;//FRHITransitionInfo,创建FRHITransition的数据,CollectPassBarrier阶段会生成
void CreateTransition();//用收集到的FRHITransitionInfo创建FRHITransition的数据
void Submit(FRHIComputeCommandList& RHICmdList, ERHIPipeline Pipeline);//提交Transition到RHI,执行BeginTransitions
}
class FRDGBarrierBatchEnd
{
...
TArray<FRDGBarrierBatchBegin*, TInlineAllocator<4, FRDGArrayAllocator>> Dependencies;//依赖的FRDGBarrierBatchBegin
void Submit(FRHIComputeCommandList& RHICmdList, ERHIPipeline Pipeline);//提交Transition到RHI,执行EndTransitions
}
UE에서 트랜지션을 시작과 끝의 두 부분으로 디자인한 이유는 무엇인가요?
시작과 끝으로 분리하면 배리어 삽입 타이밍이 더 정확해집니다. 위의 예시에서 다시 말하지만, 패스 A와 패스 B는 서로 관련이 없는 다른 여러 패스로 분리될 수 있으므로 패스B가 실행되기 전에 EndTransition만 실행하면 됩니다. (다시 말하지만, 실행 지연이라는 개념입니다).

트랜지션과 배리어에 대해 소개한 후 RDG가 트랜지션을 수집하는 방법, 즉 FRDGBarrierBatchBegin과 FRDGBarrierBatchEnd가 트랜지션 정보를 추가하는 방법을 살펴 보겠습니다.
CompilePassBarriers
코드의 경우, Compile 이후에 실행되는 FRDGBuilder::CompilePassBarriers 메서드입니다. 이 단계는 패스에서 리소스를 사용할 때 리소스의 상태를 결정하고 병합할 수 있는 경우 패스 간에 리소스 상태를 병합하는 단계입니다. 구체적으로 이 코드는 리소스의 MergeState와 패스의 PassState를 생성합니다.
void FRDGBuilder::CompilePassBarriers()
{
const FRDGPassHandle ProloguePassHandle = GetProloguePassHandle();
const FRDGPassHandle EpiloguePassHandle = GetEpiloguePassHandle();
for (FRDGPassHandle PassHandle = ProloguePassHandle + 1; PassHandle < EpiloguePassHandle; ++PassHandle)
{
FRDGPass* Pass = Passes[PassHandle];
if (Pass->bCulled || Pass->bEmptyParameters)
{
continue;
}
const ERHIPipeline PassPipeline = Pass->Pipeline;
const auto MergeSubresourceStates = [&](ERDGViewableResourceType ResourceType, FRDGSubresourceState*& PassMergeState, FRDGSubresourceState*& ResourceMergeState, const FRDGSubresourceState& PassState)
{
if (!ResourceMergeState || !FRDGSubresourceState::IsMergeAllowed(ResourceType, *ResourceMergeState, PassState))
{
ResourceMergeState = AllocSubresource(PassState);
}
else
{
ResourceMergeState->Access |= PassState.Access;
FRDGPassHandle& FirstPassHandle = ResourceMergeState->FirstPass[PassPipeline];
if (FirstPassHandle.IsNull())
{
FirstPassHandle = PassHandle;
}
ResourceMergeState->LastPass[PassPipeline] = PassHandle;
}
PassMergeState = ResourceMergeState;
};
for (auto& PassState : Pass->TextureStates)
{
FRDGTextureRef Texture = PassState.Texture;
if (Texture->FirstBarrier == FRDGTexture::EFirstBarrier::ImmediateRequested)
{
check(Texture->bExternal);
Texture->FirstBarrier = FRDGTexture::EFirstBarrier::ImmediateConfirmed;
Texture->FirstPass = PassHandle;
for (FRDGSubresourceState& SubresourceState : *Texture->State)
{
SubresourceState.SetPass(ERHIPipeline::Graphics, PassHandle);
}
}
for (int32 Index = 0; Index < PassState.State.Num(); ++Index)
{
if (PassState.State[Index].Access == ERHIAccess::Unknown)
{
continue;
}
MergeSubresourceStates(ERDGViewableResourceType::Texture, PassState.MergeState[Index], Texture->MergeState[Index], PassState.State[Index]);
}
}
for (auto& PassState : Pass->BufferStates)
{
FRDGBufferRef Buffer = PassState.Buffer;
if (Buffer->FirstBarrier == FRDGBuffer::EFirstBarrier::ImmediateRequested)
{
check(Buffer->bExternal);
Buffer->FirstBarrier = FRDGBuffer::EFirstBarrier::ImmediateConfirmed;
Buffer->FirstPass = PassHandle;
Buffer->State->SetPass(ERHIPipeline::Graphics, PassHandle);
}
MergeSubresourceStates(ERDGViewableResourceType::Buffer, PassState.MergeState, Buffer->MergeState, PassState.State);
}
}
}
예를 들어 동일한 텍스처를 사용하는 패스A, 패스B, 패스C가 있고, 텍스처에 대한 패스A와 패스B의 액세스가 Read인 경우, 패스A와 패스B 상태 사이의 텍스처A를 병합할 수 있고, 패스C의 텍스처 액세스가 Write인 경우, 별도의 State라고 이해하면 더 이해하기 쉽습니다. 아래 그림과 같이 텍스처에 대한 패스C의 액세스는 쓰기이므로 별도의 스테이트가 됩니다:

위 코드에는 텍스처 처리를 위한 특별한 로직이 있습니다.
if (Texture->FirstBarrier == FRDGTexture::EFirstBarrier::ImmediateRequested)
{
check(Texture->bExternal);
Texture->FirstBarrier = FRDGTexture::EFirstBarrier::ImmediateConfirmed;
Texture->FirstPass = PassHandle;
for (FRDGSubresourceState& SubresourceState : *Texture->State)
{
SubresourceState.SetPass(ERHIPipeline::Graphics, PassHandle);
}
}
이리Texture- & gt; FirstBarrier == FRDGTexture::EFirstBarrier::ImmediateRequested는 무슨 뜻인가요?
FRDGTexture 구조에서 FirstBarrier 는 기본적으로 EFirstBarrier::Split 이며, 텍스처에 ForceImmediateFirstBarrier 가 표시되고 ETextureCreateFlags 가 Presentable 인 경우 ImmediateRequested 로 설정됩니다. 분할과 즉시 요청의 차이점은 무엇인가요? 해당 트랜지션의 타이밍이 다릅니다. Split은 위에서 언급한 트랜지션을 시작과 끝의 두 부분으로 분할하는 것에 해당하며, EndTransition은 필요할 때만 실행됩니다. 즉시 요청된 경우, End는 Begin 직후에 실행됩니다. CollectPassBarriers는 나중에 ImmediateRequested를 처리합니다.

분할 및 즉시 요청 비교
CollectPassBarriers
수집 패스 장벽 작업은 패스 사이의 리소스 상태에 따라 적절한 트랜지션 정보를 생성하는 것입니다.
遍历Pass,调用CollectPassBarriers
for (FRDGPassHandle PassHandle = ProloguePassHandle + 1; PassHandle < EpiloguePassHandle; ++PassHandle)
{
FRDGPass* Pass = Passes[PassHandle];
if (!Pass->bCulled && !Pass->bEmptyParameters)
{
CollectPassBarriers(Pass);
}
}
수집 패스 배리어에서 텍스처와 버퍼를 사용하는 패스 내 상태를 반복하고, 추가 트랜지션
void FRDGBuilder::CollectPassBarriers(FRDGPass* Pass)
{
IF_RDG_ENABLE_DEBUG(ConditionalDebugBreak(RDG_BREAKPOINT_PASS_COMPILE, BuilderName.GetTCHAR(), Pass->GetName()));
for (auto& PassState : Pass->TextureStates)
{
FRDGTextureRef Texture = PassState.Texture;
AddTransition(Pass->Handle, Texture, PassState.MergeState);
}
for (auto& PassState : Pass->BufferStates)
{
FRDGBufferRef Buffer = PassState.Buffer;
AddTransition(Pass->Handle, Buffer, *PassState.MergeState);
}
}
추가 트랜지션의 코드는 꽤 길지만, 여기서는 텍스처, 버퍼의 처리만 붙여넣습니다.
void FRDGBuilder::AddTransition(FRDGPassHandle PassHandle, FRDGTextureRef Texture, FRDGTextureSubresourceStateIndirect& StateAfter)
{
const FRDGTextureSubresourceLayout Layout = Texture->Layout;
FRDGTextureSubresourceState& StateBefore = Texture->GetState();//资源当前的状态
const uint32 SubresourceCount = StateBefore.Num();
//对DS的特殊处理...
for (uint32 SubresourceIndex = 0; SubresourceIndex < SubresourceCount; ++SubresourceIndex)
{
if (const FRDGSubresourceState* SubresourceStateAfter = StateAfter[SubresourceIndex])
{
check(SubresourceStateAfter->Access != ERHIAccess::Unknown);
FRDGSubresourceState& SubresourceStateBefore = StateBefore[SubresourceIndex];
if (FRDGSubresourceState::IsTransitionRequired(SubresourceStateBefore, *SubresourceStateAfter))//资源状态有变化,需要插入Transition
{
const FRDGTextureSubresource Subresource = Layout.GetSubresource(SubresourceIndex);
FRHITransitionInfo Info;
Info.Texture = Texture->GetRHIUnchecked();
Info.Type = FRHITransitionInfo::EType::Texture;
Info.Flags = SubresourceStateAfter->Flags;
Info.AccessBefore = SubresourceStateBefore.Access;
Info.AccessAfter = SubresourceStateAfter->Access;
Info.MipIndex = Subresource.MipIndex;
Info.ArraySlice = Subresource.ArraySlice;
Info.PlaneSlice = Subresource.PlaneSlice;
if (Info.AccessBefore == ERHIAccess::Discard)
{
Info.Flags |= EResourceTransitionFlags::Discard;
}
AddTransition(Texture, SubresourceStateBefore, *SubresourceStateAfter, Info);//将Transition插入到合适的位置
}
SubresourceStateBefore = *SubresourceStateAfter; //更新资源的当前状态,供下次遍历使用
}
}
}
위의 추가 트랜지션은 트랜지션 정보를 생성하고 해당 FRDGBuilder::추가 트랜지션 버전을 호출합니다. 구체적인 코드는 너무 길어서 게시하기 어렵고 MergePass의 존재로 인해 이 부분의 이해 논리가 직관적이지 않으므로 그림으로 직접 설명하겠습니다.
전환은 다음과 같은 방식으로 추가됩니다:
1 대 1 또는 1 대 N 케이스 . 다음 다이어그램을 참조하세요.
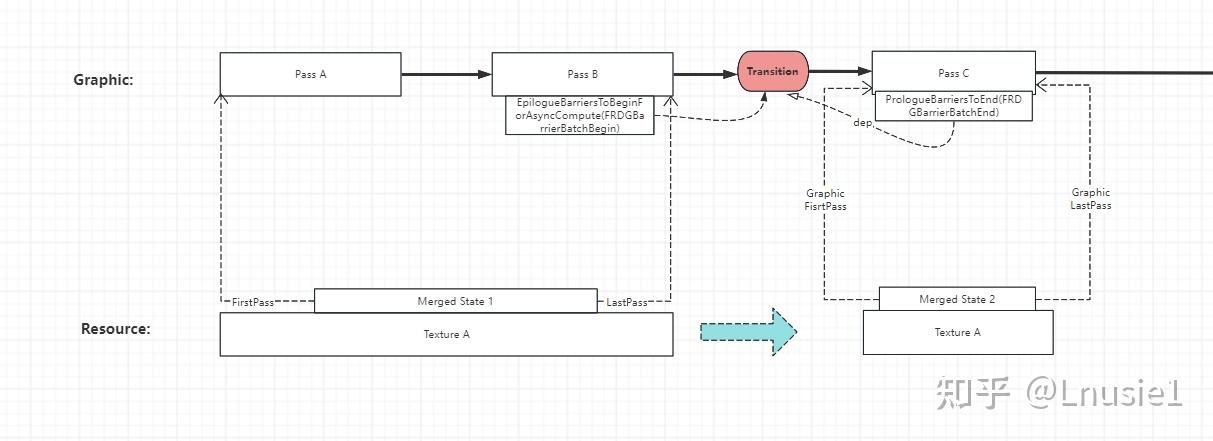
1대1
1 ~ N
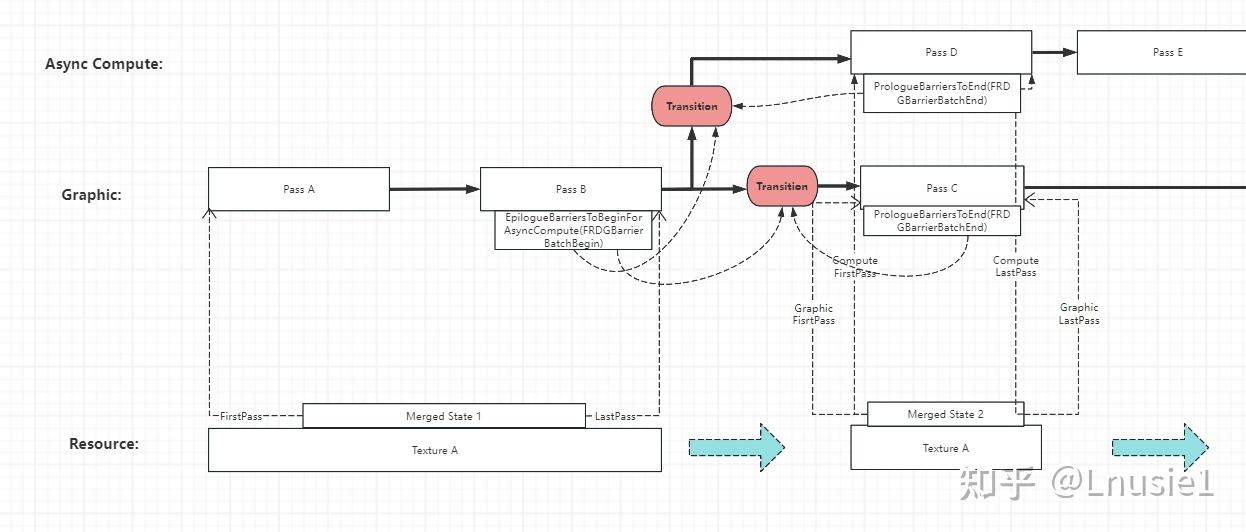
N 대 1 또는 N 대 N의 경우 다음 그림을 참조할 수 있습니다.

N对1的情况
콜렉트패스배리어는 트랜지션이 추가될 위치를 식별하는 트랜지션인포만 생성하며, 실제 트랜지션은 패스 실행 전후에 추가됩니다.
패스 구현
void FRDGBuilder::ExecutePass(FRDGPass* Pass, FRHIComputeCommandList& RHICmdListPass)
{
//...
ExecutePassPrologue(RHICmdListPass, Pass);//执行Pass的“序言”逻辑
Pass->Execute(RHICmdListPass);//真正执行Pass的Callback
ExecutePassEpilogue(RHICmdListPass, Pass);//执行Pass的“尾声”逻辑
//...
}
ExecutePassPrologue 와 ExecutePassEpliogue
FRDGBuilder::ExecutePassPrologue: Sumit의 주요 로직은 이전에 수집한 TransitionInfo와 비교하여 BeginTransition 또는 EndTransition을 실행하고 BeginRenderPass도 실행합니다.
void FRDGBuilder::ExecutePassPrologue(FRHIComputeCommandList& RHICmdListPass, FRDGPass* Pass)
{
//...
const ERDGPassFlags PassFlags = Pass->Flags;
const ERHIPipeline PassPipeline = Pass->Pipeline;
if (Pass->PrologueBarriersToBegin)
{
IF_RDG_ENABLE_DEBUG(BarrierValidation.ValidateBarrierBatchBegin(Pass, *Pass->PrologueBarriersToBegin));
Pass->PrologueBarriersToBegin->Submit(RHICmdListPass, PassPipeline);
}
IF_RDG_ENABLE_DEBUG(BarrierValidation.ValidateBarrierBatchEnd(Pass, Pass->PrologueBarriersToEnd));
Pass->PrologueBarriersToEnd.Submit(RHICmdListPass, PassPipeline);
if (EnumHasAnyFlags(PassFlags, ERDGPassFlags::Raster))
{
if (!EnumHasAnyFlags(PassFlags, ERDGPassFlags::SkipRenderPass) && !Pass->SkipRenderPassBegin())
{
static_cast<FRHICommandList&>(RHICmdListPass).BeginRenderPass(Pass->GetParameters().GetRenderPassInfo(), Pass->GetName());
}
}
//...
}
FRDGBuilder::ExecutePassEpilogue의 주요 로직은 수집된 TransitionInfo에 대해서도 제출한다는 점에서 ExecutePassPrologue와 유사합니다.
하나의 다이어그램에 ExecutePass를 요약 했습니다.
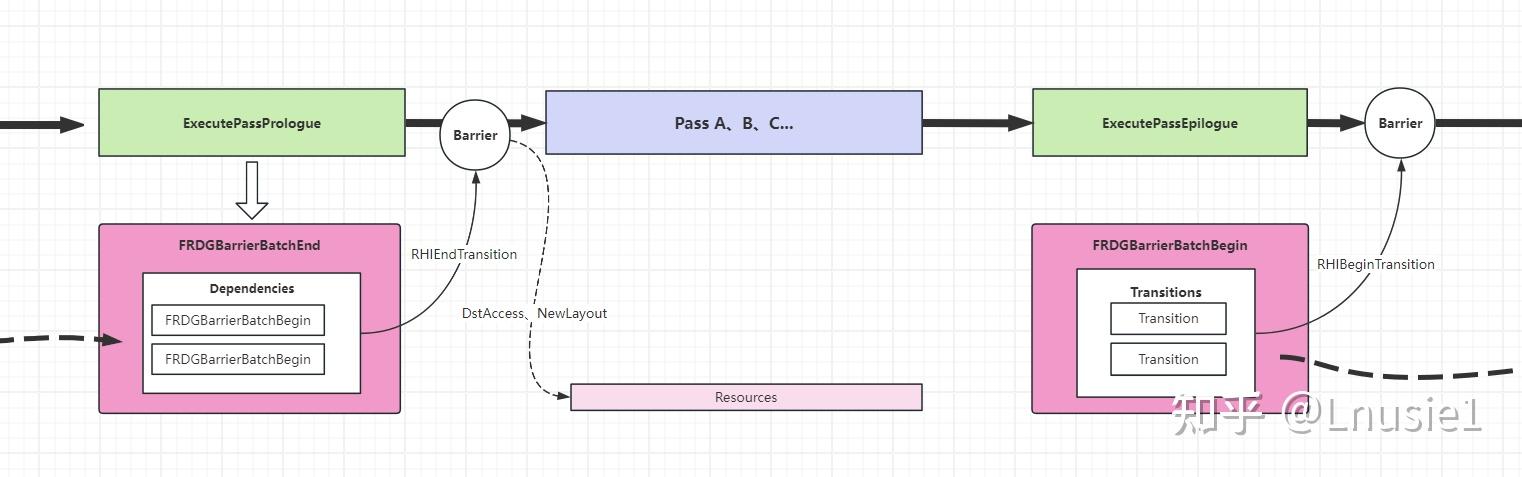
ExecutePass 스키마
마치며...
RDG에는 관련된 내용이 너무 많아서 이 글에서는 지금까지 RDG를 컴파일하고 실행하는 방법과 배리어 컬렉션을 자세히 분석하는 데만 초점을 맞췄습니다. RDG 설계의 또 다른 주요 용도인 메모리 앨리어스(Frost 엔진이 대량의 메모리를 최적화하는 데 도움이 됨)는 아직 언급하지 않았고, RDG의 멀티스레드 설계에 대해서도 언급하지 않았습니다. 이따가 새로운 글을 시작해서 파헤쳐 보도록 하겠습니다~ 읽어주셔서 감사합니다, 건강하시고 곧 뵙겠습니다.
원문
https://zhuanlan.zhihu.com/p/702354878
zhuanlan.zhihu.com
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [번역] UDF 및 얼굴 SDF 섀도 맵의 GPU 생성 (0) | 2024.06.25 |
|---|---|
| [번역] 【UE5.4】Slate Post-buffer를 사용해보자. (0) | 2024.06.25 |
| [번역]언리얼 엔진 초실감 인간을 해부하는 렌더링 기술 Part 2 - 눈동자 렌더링 (1) | 2024.06.10 |
| [번역] 《명조》언리얼 엔진 4를 기반으로 한 멀티 플랫폼 이펙트 및 퍼포먼스 최적화 사례. (0) | 2024.06.04 |
| [번역]캐릭터 카툰 렌더링(디퍼드 라이팅) 참고 사항 (10) | 2024.06.03 |