
역자의 말: VRS와 Vis-Buffer는 매우 중요한 트렌딩 포인트입니다. 이미 텐센트 게임 연구센터에서 모바일 플랫폼을 지원하는 클러스터 컬링을 활용한 자신들만의 지오메트리 렌더링 최적화 기법을 발표했으며 점진적으로 실무에 적용하고 있는 형국입니다. 출근할 때 웃긴 숏폼 볼 시간에 천천히 이러한 글들을 읽어가면서 이해해 나간다면 분명히 개개인에게 도움이 될 것 같네요.
저자 : JOHN HABLE @FILMICWORDS

그는 일렉트로닉 아츠, 너티독, 에픽게임즈, 유니티에서 경력을 쌓은 렌더링 프로그래머입니다.
소개
가시성 렌더링에는 매우 흥미로운 트레이드오프가 있으며, 살펴봐야 할 기법도 많습니다. 첫 번째 포스팅에서는 가시성 렌더링에 대한 개요와 머티리얼 그래프를 사용하여 최적화하는 방법을 소개했습니다. 두 번째는 지오메트리 샘플링 속도와 셰이더 샘플링 속도를 분리하여 안티 에일리어싱을 개선하는 새로운 기법에 대해 설명했습니다. 세 번째는 지오메트리 샘플링 속도와 셰이딩 샘플링 속도를 분리하는 또 다른 방법에 대해 설명합니다: 가변 비율 셰이딩입니다.
가시성 렌더링의 모험
- Part 1: 머티리얼 그래프를 사용한 비저빌리티 버퍼 렌더링
- Part 2: 디커플링 된 가시성 멀티샘플링
- Part 3: 가시성 버퍼 렌더링이 포함된 소프트웨어 VRS
- Part 4: 가시성 TAA 및 서브샘플 히스토리를 사용한 업샘플링
하드웨어 가변 속도 셰이딩(줄여서 VRS)을 사용하면 GPU가 다양한 속도로 셰이딩 및 지오메트리 샘플링을 수행할 수 있습니다. 비교적 새로운 기능이지만 현재 AMD [1], Intel [4], NVIDIA [7] GPU에서 지원됩니다. 다음은 포워드 렌더링과 TAA가 적용된 단일 확대 예시 프레임입니다:

다음은 2x2 하드웨어 VRS를 활성화한 동일한 샷입니다. 1x 이미지와는 다른 샘플링 포인트를 사용하며, 각 2x2 셰이딩 포인트는 4개의 원본 샘플 포인트의 평균입니다.

하지만 가시성 렌더링을 사용하면 다른 접근 방식을 취할 수 있습니다. 하드웨어 VRS처럼 샘플을 변경하는 대신 일반적으로 렌더링 하는 샘플 포인트의 하위 집합을 선택할 수 있습니다.

그런 다음 해당 포인트에 대한 사용자 지정 보간을 수행하여 흐릿한 결과를 얻을 수 있습니다.

그런 다음 각 프레임마다 샘플 포인트를 무작위로 추출할 수 있습니다. 샘플은 원본 프레임과 동일한 위치에 있기 때문에 움직이는 것이 없으면 시간이 지나면서 원래의 기준 프레임으로 수렴합니다. 이 기능은 원본보다 더 흐릿한 이미지로 수렴하는 하드웨어 VRS와는 대조적입니다. 다음은 최종 수렴된 프레임입니다:

이 방식은 하드웨어 VRS보다 수렴 품질이 높을 뿐 아니라, 특히 트라이앵글 밀도가 높아질수록 성능상의 이점도 있습니다.
선행 기술
특히 하드웨어 VRS [8]를 사용하면 이미지에 대한 셰이딩 비율을 변경할 수 있는 몇 가지 옵션이 있습니다. 또한 VRS 레벨에 대한 화면 공간 마스크를 지정할 수 있으므로 최신 Gears 5 [9]에서처럼 콘텐츠에 따라 보수적이거나 공격적인 샘플링 속도를 적응적(Adaptive)으로 적용할 수 있습니다. 4 xMSAA [2]를 사용하여 2x2 픽셀 쿼드를 에뮬레이트한 Call of Duty: 모던 워페어와 같은 소프트웨어 버전도 있습니다. 또한 인텔(Intel)[3]의 마리사 뒤 보이스(Marissa du Bois)가 이 기술, 실질적인 고려 사항, UE4와의 통합에 대해 설명하는 좋은 개요 동영상을 제공합니다. 이 비디오의 후반부에서는 트립와이어의 존 깁슨(John Gibson)이 자신의 게임인 기사도 2의 퍼포먼스 수치에 대해 설명합니다. 토마스 스타초비악(Tomasz Stachowiak)은 GCN 해킹을 통해 셰이더를 점유별로 그룹화하고, 동일한 픽셀 쿼드에서 데이터가 공유될 때 VRS 알고리즘을 사용하는 인상적인 시스템을 구현하기도 했습니다 [10].
API는 매우 쉽게 활성화할 수 있으며, 대부분의 경우 다른 작업 없이도 더 나은 성능을 얻을 수 있습니다. 동일해 보이지만 더 빠르다면 당연히 그렇게 해야 합니다. 하지만 소프트웨어에서 직접 수행하여 이 기술을 개선할 수 있는 방법이 있습니다.
앞서 언급했듯이 1x 기준 이미지와 동일한 샘플 위치를 사용하여 이미지가 비-VRS 결과와 수렴하도록 할 수 있습니다. 또한, 가시성 VRS는 하드웨어 VRS의 일부 성능 비효율성을 해결할 수 있습니다. 하드웨어 VRS에는 어떤 비효율성이 있나요? 쿼드 활용에 대한 이야기가 끝났다고 생각했다면 나쁜 소식이 있습니다.
쿼드 활용도
이전 게시물에서 렌더링이 쿼드로 분할되는 방식에 대해 설명한 적이 있습니다. 일반 1x 렌더링의 경우 래스터라이저는 이 삼각형을 2x2 쿼드로 분할하고 회색 픽셀은 실행해야 하는 헬퍼 레인이 됩니다.

결국 쿼드는 3개, 2x2개가 됩니다. 왼쪽 상단, 왼쪽 하단, 오른쪽 하단에 하나씩 있습니다. 회색 픽셀은 최종 이미지에 기여하지 않으며 화면에 실제로 표시되는 픽셀의 UV에 부분 도함수를 제공하기 위해 존재합니다.

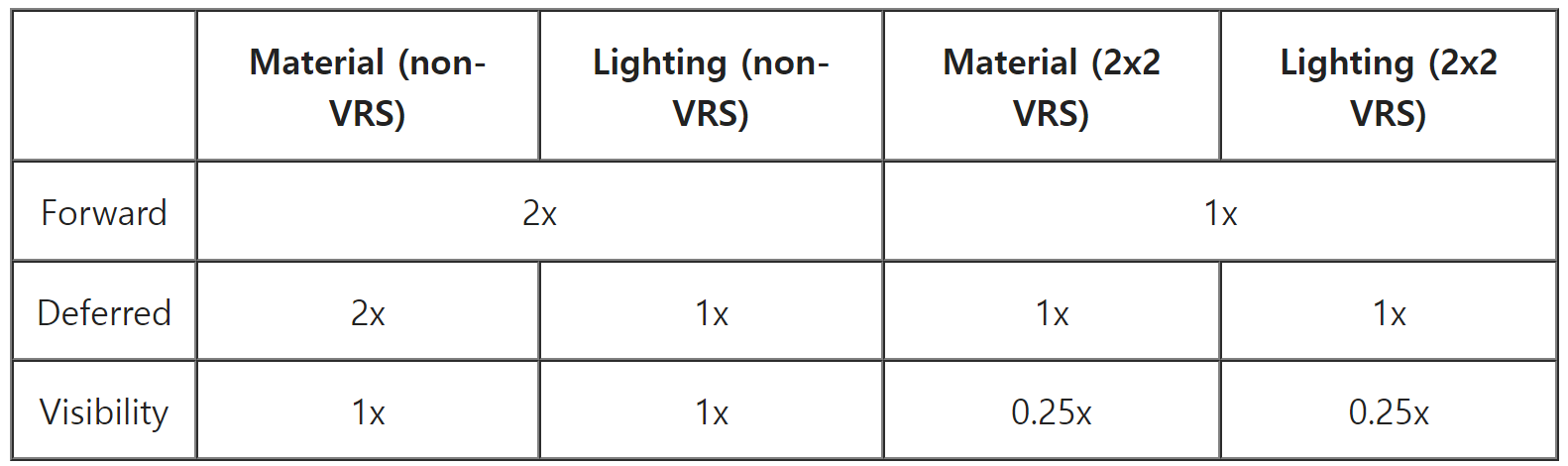
그렇다면 동일한 삼각형을 2x2 VRS로 렌더링 하면 어떻게 될까요? 래스터라이저는 아래와 같이 각 4x4 픽셀 블록을 하나의 2x2 쿼드로 간주합니다.

그러면 단일 픽셀 셰이더 쿼드가 생성되며, 오른쪽 위는 헬퍼 레인이 됩니다.

픽셀 셰이더가 실행되면 원본 이미지의 각 2x2 블록에 해당 색상을 각각 적용합니다. 아래와 같이 보라색으로 된 큰 삼각형이 있다고 가정해 보겠습니다. 일반적인 비-VRS의 경우 삼각형이 2x2 정사각형의 단일 픽셀에 닿으면 다른 점은 헬퍼 레인으로 렌더링해야 합니다. 이러한 차선은 회색으로 표시됩니다.

이 프로세스는 VRS가 활성화되면 "반올림"됩니다. 2x2 VRS를 사용하면 이 삼각형이 4x4 그리드에서 단일 픽셀에 닿으면 나머지는 헬퍼 레인으로 채워야 합니다. 다시 말해, 삼각형이 4x4 블록의 픽셀 하나 이상에 닿으면 4x4 블록을 렌더링해야 합니다.

2x2 VRS로 이 삼각형을 렌더링 할 때 래스터라이저는 이 삼각형에 닿는 모든 4x4 블록을 찾아야 합니다. 그런 다음 4x4 블록은 픽셀 셰이더로 전송되는 쿼드가 됩니다. 파란색 픽셀의 2x2 그룹은 VRS 픽셀 셰이더 쿼드에서 헬퍼 레인이 됩니다. 4x4 픽셀 블록은 처리할 2x2 쿼드 하나만 생성합니다.
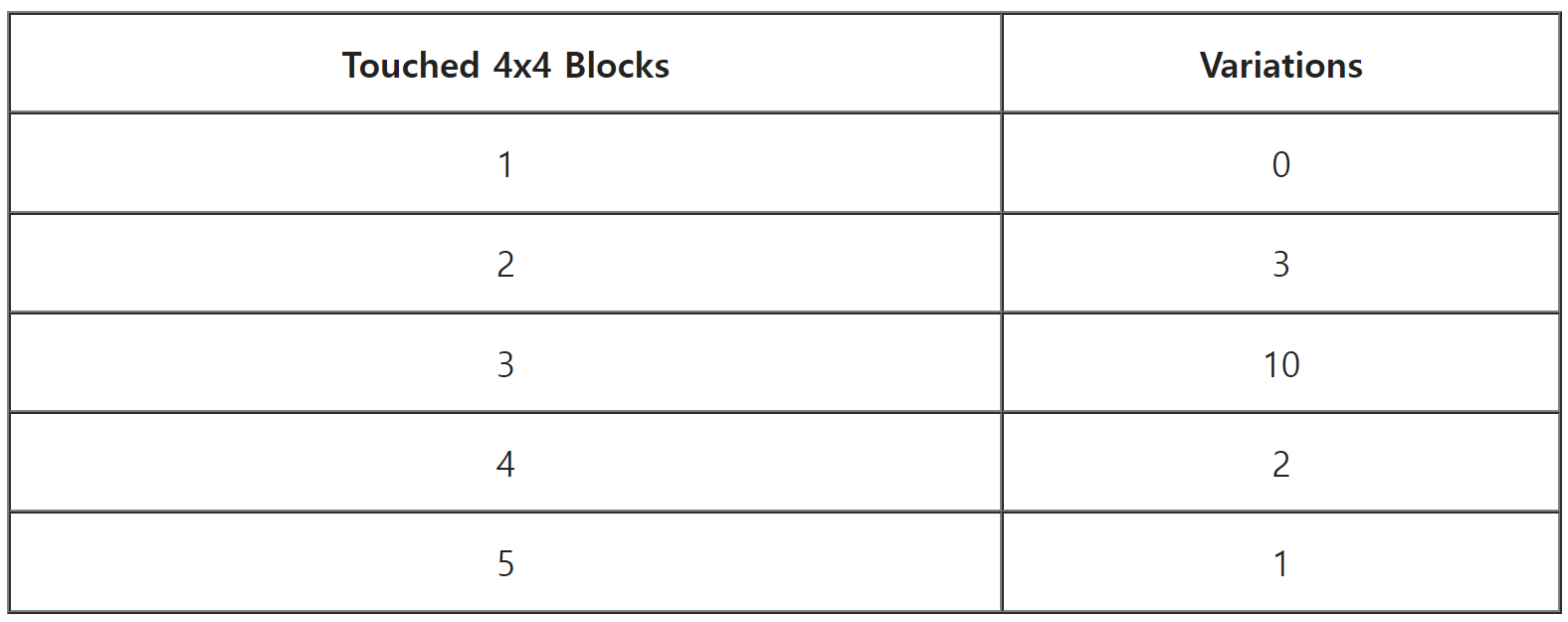
그렇다면 큰 삼각형의 경우 픽셀 셰이더를 몇 번 실행해야 할까요? 앞서 설명한 것처럼 표준 비-VRS의 경우 포워드 렌더러는 픽셀당 한 번씩 픽셀 셰이더를 호출합니다. 이는 비저빌리티 렌더러뿐만 아니라 디퍼드 렌더러의 머티리얼 및 라이팅 패스에서도 동일하게 적용됩니다. 하지만 2x2 VRS의 경우는 어떨까요?
포워드 렌더러에서는 각 픽셀 셰이더가 2x2 쿼드당 한 번씩 실행되므로 픽셀당 0.25개의 픽셀 셰이더 호출이 발생합니다. 디퍼드의 경우 머티리얼 패스는 픽셀당 0.25픽셀 셰이더 호출로 래스터화 되지만 조명 패스는 래스터화 되지 않으므로 1배로 실행됩니다. 예, Gears 5 [9]에서처럼 라이팅을 더 낮은 속도로 실행하는 방법도 있지만 자세한 내용은 여기서는 생략하겠습니다.
그렇다면 가시성은 어떨까요? 픽셀당 0.25번의 인보케이션으로 렌더링 할 수 있을까요? 물론 안 될 이유가 없죠. 픽셀의 하위 집합을 선택하고, 그 픽셀에 조명을 비추고, 그 사이의 픽셀을 보간하면 됩니다.

추가 작업이 필요하겠지만 충분히 해낼 수 있습니다. 또한 UV 파생물을 분석적으로 계산할 수 있으므로 헬퍼 레인이 필요하지 않습니다.
다음은 비-VRS 및 2x2 VRS 버전에서 포워드/디퍼드/비저빌리티에 대해 라이팅 및 머티리얼 평가가 실행되는 횟수를 보여주는 표입니다.
큰 트라이앵글의 픽셀당 대략적인 셰이더 함수 호출 수입니다:

간단합니다. 하드웨어 VRS 덕분에 포워드 및 디퍼드 머티리얼을 0.25배 속도로 실행할 수 있습니다. 비저빌리티는 우리 자체 소프트웨어 VRS 솔루션으로 0.25 배율로 실행할 수 있습니다. 그리고 디퍼드 라이팅은 전체 화면 패스에 있으므로 1배속으로 실행되지만, 기어스 5에서와 같이 최적화할 수 있습니다.
작은 트라이앵글로 넘어가 보겠습니다. 비-VRS의 경우 1픽셀 삼각형은 1개의 활성 레인과 3개의 도우미 레인이 있는 2x2 쿼드가 됩니다.

2x2 VRS 케이스의 작은 삼각형은 어떻게 될까요? 당연히 똑같은 일이 일어납니다. 픽셀 셰이더는 비-VRS의 경우와 마찬가지로 1개의 활성 레인과 3개의 헬퍼 레인이 있는 2x2 쿼드로 변환합니다.

작은 1픽셀 트라이앵글의 경우, VRS와 비-VRS의 경우는 동일합니다. 작은 트라이앵글에는 항상 1개의 활성 레인이 필요하므로 3개의 헬퍼 레인이 있는 쿼드가 필요합니다. 하지만 가시성 렌더링은 어떨까요?

가시성을 사용하면 픽셀당 0.25개의 셰이더 호출로 렌더링 할 수 있습니다. 실행할 픽셀 선택은 임의적이므로 큰 삼각형의 경우와 동일한 알고리즘을 사용할 수 있습니다. 픽셀의 하위 집합만 렌더링 하고 나머지는 보간하면 됩니다. 삼각형의 크기는 상관없습니다. 다음은 픽셀당 셰이더 호출 표입니다.
1픽셀 트라이앵글의 픽셀당 대략적인 셰이더 함수 호출 수입니다:

이것이 바로 VRS를 사용한 가시성 렌더링의 핵심 아이디어입니다. 작은 트라이앵글의 경우 포워드 및 디퍼드 머티리얼 패스는 VRS와 관계없이 쿼드 활용으로 인해 픽셀당 4픽셀 셰이더 인보케이션을 렌더링해야 합니다. 하지만 가시성 렌더링을 사용하면 두 경우 모두 픽셀당 0.25개의 셰이더 인보케이션을 유지할 수 있습니다.
마지막으로 보다 일반적인 10픽셀 트라이앵글은 어떨까요? 이것부터 다시 시작하겠습니다:

이 경우 삼각형은 4x4 픽셀 블록에 완벽하게 맞으며 정확히 하나의 쿼드를 생성합니다. 그러나 이 삼각형을 4x4 그리드에 맞추는 방법은 16가지가 있습니다.
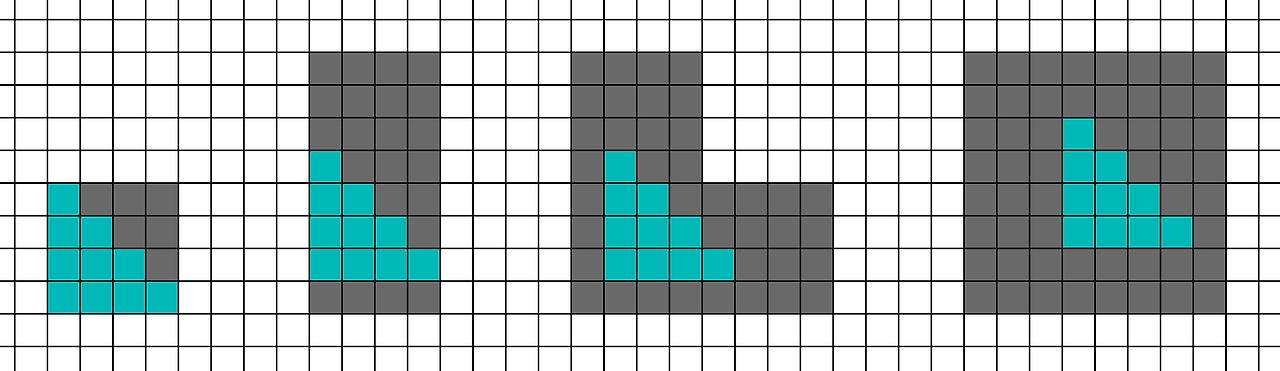
삼각형이 하나의 4x4 블록 안에 완벽하게 들어맞는 방법은 정확히 1가지이지만, 2블록을 터치하는 방법은 6가지, 3블록을 터치하는 방법은 6가지, 4블록을 터치하는 방법은 3가지가 있습니다. 즉, 이 모양의 삼각형은 평균 10.75픽셀 셰이더 레인(활성 + 헬퍼)을 생성합니다.

더 길고 얇은 모양을 살펴보겠습니다.

이것은 조금 더 나쁩니다. 4x4 블록 하나를 정확히 맞출 수 있는 방법은 없으며, 평균적으로 이 모양은 12.25 픽셀 셰이더를 생성합니다.
두 셰이프의 경우 평균적으로 각각 10.75 픽셀과 12.25 픽셀 셰이더 호출이 필요합니다. 잊지 마세요: 원본 삼각형은 10픽셀에 불과합니다. 따라서 셰이딩 속도를 지오메트리 속도의 1/4로 렌더링 하려고 해도 실제로는 픽셀 수보다 셰이더 호출 수가 더 많습니다.
이전 포스팅에서 기억하시겠지만, 비-VRS를 사용하면 픽셀당 셰이더 호출이 약 2배가 됩니다. 간단히 설명하기 위해 2x2 VRS의 10픽셀 트라이앵글에 픽셀당 1x 셰이더 호출이 필요하다고 가정해 보겠습니다. 그리고 가시성 렌더링의 경우 픽셀당 0.25배의 셰이더 호출을 쉽게 얻을 수 있습니다.
10픽셀 트라이앵글의 픽셀당 대략적인 셰이더 함수 호출 수입니다:
이 분석에 따르면 매우 큰 트라이앵글의 경우 포워드, 디퍼드, 가시성 성능이 비슷할 것으로 예상됩니다. 그러나 삼각형이 10에 가까워질수록 가시성이 더 빨라질 것으로 예상됩니다. 그리고 삼각형이 단일 픽셀로 줄어들면 쿼드 활용으로 인해 가시성이 승자가 될 것입니다. 물론 그전에 Visibility 버퍼를 사용하여 소프트웨어에서 실제로 VRS를 수행하는 방법에 대해 논의해야 합니다.
Software VRS with Visibility
하이레벨에서 픽셀을 켜짐 또는 꺼짐으로 표시하겠습니다. 켜짐으로 표시된 픽셀은 비저빌리티 머티리얼 패스에 누적되어 스파스 GBuffer를 생성합니다. 스파스 GBuffer는 라이팅 패스에 의해 라이팅 됩니다. 그런 다음 희소 조명의 포장을 풀고 구멍을 채웁니다. 그런 다음 그 이미지를 TAA에 전달하면 마법처럼 모든 것을 고칠 수 있습니다. 농담이 아니라 농담입니다.
예를 들어 선택한 픽셀은 다음과 같이 표시됩니다:

재구성된 단일 프레임은 다음과 같이 표시됩니다:

TAA 후 최종 프레임은 다음과 같이 표시됩니다:

첫 번째 질문은 희소 지점에서 이미지를 어떻게 재구성해야 할까요? 여러 가지 옵션과 양방향 업샘플링의 다양한 변형을 시도해 보았지만 가장 효과가 좋았던 접근 방식은 Ian Mallet, Cem Yuksel, Larry Seiler [5,6]의 Deferred Active Compute Shading 논문에서 나온 것이었습니다. 이들의 핵심 아이디어는 먼저 전체 GBuffer를 렌더링 하되 반복 패스를 사용하여 가변 속도로 조명을 수행하는 것이었습니다. 이들의 알고리즘은 다음과 같이 X와 Y의 4번째 샘플마다 조명을 계산하는 것으로 시작합니다:

다음 단계는 누락된 픽셀을 채우는 것입니다. 아래 그림과 같은 픽셀의 경우 4개의 이웃 픽셀에서 값을 보간하면 됩니다.

매우 흥미로운 혁신이 하나 있었습니다. 데이터가 있기 때문에 픽셀을 즉석에서 계산하거나 보간하는 방법을 선택할 수 있었습니다. 4개의 이웃 값을 모두 비교하고 충분히 비슷하면 보간을 수행합니다. 하지만 GBuffer 데이터가 다르면 더 비싼 전체 조명 계산을 수행합니다. 매우 멋진 접근 방식이며 두 논문을 모두 읽어보시길 추천합니다. 그 사이의 각 값에 대해 보간하거나 직접 계산하여 새로운 색상을 선택합니다.

두 번째 단계는 계속됩니다...

... 그리고 세 번째 단계...

... 그리고 4단계...

... 이미지가 완성될 때까지 기다립니다. 이 가시성 버퍼 구현에서는 이웃 픽셀에 조명이 켜질 때까지 픽셀 보간과 조명을 결정하기 위해 기다리는 것은 실용적이지 않습니다. 따라서 이 변형에서는 희소 조명 패스 이후의 이미지부터 시작하겠습니다.

녹색 픽셀은 조명 값을 계산한 위치입니다. 그런 다음 각 패스마다 빈칸을 채웁니다. 이 새 픽셀에는 어떤 알고리즘을 사용해야 할까요?

일반적인 접근 방식은 이미지 디베이어링에 사용된 것처럼 더 작은 절대 차이를 사용하는 것입니다. 코드로 설명하는 것이 가장 쉬울 것입니다:
float3 InterpolatePrimaryCrossColorMerged(
uint matC, uint mat0, uint mat1, uint mat2, uint mat3,
bool validC,
float3 colorC, float3 color0, float3 color1, float3 color2, float3 color3)
{
float4 color = 0.0f;
float4 temp0 = (matC == mat0) ? float4(color0, 1) : float4(0, 0, 0, 0);
float4 temp1 = (matC == mat1) ? float4(color1, 1) : float4(0, 0, 0, 0);
float4 temp2 = (matC == mat2) ? float4(color2, 1) : float4(0, 0, 0, 0);
float4 temp3 = (matC == mat3) ? float4(color3, 1) : float4(0, 0, 0, 0);
float4 avg0 = .5f*(temp0 + temp1);
float4 avg1 = .5f*(temp2 + temp3);
bool bothGood0 = temp0.w >= .75f;
bool bothGood1 = temp1.w >= .75f;
if (bothGood0 && bothGood1)
{
float diff0 = abs(dot(float3(1, 2, 1), temp0 - temp1));
float diff1 = abs(dot(float3(1, 2, 1), temp2 - temp3));
color = diff0 < diff1 ? avg0 : avg1;
}
else if (bothGood0 && !bothGood1)
color = avg0;
else if (!bothGood0 && bothGood1)
color = avg1;
else
color = avg0 + avg1;
if (color.w < .25f)
color = float4(color0 + color1 + color2 + color3, 4);
color.xyz *= rcp(color.w);
if (validC)
color.xyz = colorC;
return color.rgb;
}중심 픽셀과 4개의 이웃 픽셀의 드로우 콜 ID를 모두 전달하고 있으며, 동일한 드로우 콜 ID의 이웃 픽셀만 사용하여 보간할 것입니다. 이 픽셀을 보간하는 데 사용할 수 있는 두 쌍의 쌍이 있습니다. 두 픽셀이 계산하려는 픽셀과 동일한 드로우 콜 ID에 있는 경우 한 쌍이 "양호"한 것으로 간주됩니다. 두 쌍이 모두 양호한 경우 "더 나은" 쌍을 사용하여 보간하며, 여기서 "더 나은" 쌍은 절대 차이가 더 작은 쌍을 의미합니다. 한 쌍만 양호한 경우 해당 쌍을 사용합니다. 두 쌍 모두 좋지 않은 경우 픽셀을 합산하고 최선을 다합니다.
돌이켜보면 더 작은 절대 차이를 사용하여 보간할 쌍을 선택한 것은 최선의 선택이 아니었던 것 같습니다. 원시 이미지에는 노이즈처럼 보이는 단일 픽셀이 많이 있습니다. 이러한 픽셀은 평균보다 훨씬 밝거나 어두운 픽셀입니다. 따라서 주변 픽셀을 보간할 때 항상 다른 픽셀 쌍이 선택되기 때문에 이러한 픽셀은 사용되지 않았습니다. 따라서 픽셀의 직선 평균 또는 하이브리드 접근 방식으로 전환할 수 있습니다. 더 많은 조사가 필요합니다.
이 접근법의 장점은 주변 4픽셀만 필요하기 때문에 보간이 빠르다는 것입니다. 하지만 가장자리를 인식하므로 색상이 번지지 않습니다. 이웃 4명이 모두 다른 추첨 콜 ID를 사용하는 경우 어떻게 되나요? 최악의 경우 평균을 취하고 출혈을 받아들일 수 있습니다. 하지만 실제로는 애초에 출혈이 발생하지 않도록 막을 수 있습니다. 프레임 초기에 계산/보간할 픽셀을 선택할 때 좋은 이웃이 없는 픽셀의 우선순위를 지정하면 이러한 경우가 발생하지 않습니다.
이 알고리즘을 사용하면 각 패스를 진행할 수 있습니다. 패스 1의 각 픽셀에 대해 누락된 픽셀을 보간합니다.

그런 다음 패스 2를 계속할 수 있습니다...

... 그리고 패스 3...

... 그리고 4번을 통과합니다.

이 접근 방식의 가장 큰 장점은 유연성입니다. 렌더링 하거나 보간할 픽셀을 완벽하게 제어할 수 있습니다. 유일한 엄격한 규칙은 모든 픽셀을 패스 0(전체 픽셀의 1/16)에 렌더링해야 한다는 것입니다. 그리고 소프트 규칙으로 4개의 이웃이 모두 유효하지 않을 때 픽셀을 렌더링 하고 싶습니다. 그렇지 않으면 원하는 메트릭에 따라 픽셀을 활성화/비활성화할 수 있습니다.
Convergence
눈치챘겠지만, 하드웨어 VRS와는 다른 위치에서 샘플링하고 있습니다. 일반 1x 네이티브 렌더링에서는 각 픽셀의 중앙에 있는 모든 샘플 포인트를 음영 처리합니다.

2x2 VRS를 활성화하면 샘플 포인트가 각 2x2 블록의 중앙으로 이동합니다. 더 낮은 해상도로 렌더링 하기 때문에 최종 이미지가 더 흐릿해집니다.

하지만 이 VRS 변형에서는 표준 패턴과 동일한 샘플 지점에서 렌더링 합니다. 위치를 변경하는 하드웨어 VRS와 달리 동일한 위치에서 일부 하위 집합을 렌더링 합니다.

유연성이 있기 때문에 다음 프레임에서 다른 샘플 포인트를 선택할 수 있습니다...

... 그리고 다음...

... 그리고 그다음.

즉, 주의를 기울이면 실제로 이미지가 기준이 되는 비-VRS 이미지에 수렴하도록 만들 수 있습니다. 매 프레임마다 4x4 그리드를 지터링 하고 각 픽셀에 노이즈 오프셋을 부여하여 우선순위를 지정하면 이 작업을 수행할 수 있습니다.
TAA 누적 버퍼에 알파 채널에 신뢰도 값을 저장할 수 있습니다. 새로운 샘플을 얻으면 해당 픽셀의 신뢰도를 높입니다. 보간 된 값이 있을 때 기존 값의 신뢰도가 낮으면 보간 된 값을 중요한 값으로 취급합니다. 그러나 신뢰도가 높으면 보간 된 값을 무시할 수 있습니다. 다른 프레임에서 다른 픽셀을 지터링 하기만 하면 제대로 수렴됩니다.
여기 제가 가지고 있던 얼굴 스캔 이미지가 있습니다. 원본 스캔은 Triplegangers에서 가져온 것으로, WrapX로 표준 토폴로지로 래핑 했습니다. 모델 뺨의 모공과 스페큘러 하이라이트를 클로즈업한 것입니다. 왼쪽은 첫 번째 프레임이고 오른쪽은 수렴된 결과입니다. 첫 번째 줄은 일반 1x 프레임이고, 두 번째 줄은 2x2 VRS를 사용한 포워드입니다. 나머지 4개 줄은 다른 비율의 VRS를 사용한 가시성입니다.

보시다시피 2x2 VRS 버전은 TAA 이전과 이후 모두 더 흐릿하지만 가시성 VRS 버전은 레퍼런스와 동일한 결과로 수렴합니다. 25% 이상의 비율에서는 상당히 빠르게 수렴합니다. 수렴 속도가 매우 거칠기 때문에 실제로 10% 속도로 렌더링 하는 것은 권장하지 않지만, 그래도 필요한 곳에 도달할 수 있습니다.
여러 VRS 강연에서 소개된 흥미로운 트릭 중 하나는 모션에 관한 것입니다. 물체가 움직이면 눈이 물체를 추적하기가 더 어려워지고, 그 표면에는 모션 블러가 적용될 수밖에 없습니다. 따라서 움직임이 많은 영역에서는 샘플링 속도를 낮게, 움직임이 적은 영역에서는 샘플링 속도를 높게 설정하는 것이 좋습니다.
하지만 가시성 VRS를 사용하면 이러한 상충 관계를 바꿀 수 있습니다. 움직임이 많은 영역에서는 여전히 낮은 샘플링 속도를 유지할 수 있습니다. 하지만 어차피 몇 프레임 안에 수렴할 것이므로 움직임이 적은 영역에서도 샘플링 속도를 낮출 수 있습니다. 모든 곳에서 낮은 셰이딩 레이트를 사용할 수 있습니다!
가시성 VRS는 근본적으로 트레이드오프를 바꿉니다. 표준 하드웨어 VRS를 사용하면 GPU 성능과 이미지 품질을 맞바꾸게 됩니다. 반면 Visibility VRS는 GPU 성능과 컨버전스 시간을 교환하여 셰이딩 비율에 관계없이 컨버전스 된 이미지 품질을 일정하게 유지합니다.
저에게 Visibility VRS의 흥미로운 점은 렌더링 시간을 특별히 개선한다는 것이 아닙니다. 오히려 가시성의 장점은 이러한 모든 개선 사항이 서로 완벽하게 조화를 이룬다는 점입니다. 트라이앵글 수가 많을 때 가시성은 디퍼드/포워드에 비해 상당한 개선이 이루어집니다:
- 쿼드 사용률로 인해 1배의 가시성은 순수한 디퍼드/포워드보다 빠릅니다.
- 래스터라이저는 더 큰 픽셀 블록으로 반올림해야 하므로 VRS를 사용한 가시성은 래스터화 된 VRS보다 더 나은 배율을 제공합니다.
- VRS를 사용한 가시성은 비-VRS 이미지에 수렴하기 때문에 더 공격적인 가변 셰이딩 비율을 허용합니다.
이러한 각 혜택은 그 자체로도 훌륭하지만, 진정한 강점은 아래 수치에서 설명하는 것처럼 함께 활용되는 방식에 있습니다.
Choosing Pixels
마지막으로 논의할 세부 사항은 픽셀 선택입니다. 가장 최근의 작업에서는 이미지를 분석하고 [7,9] 해당 영역에 얼마나 많은 디테일이 있는지 감지한 다음 적절한 VRS 셰이딩 비율을 설정하는 것이 추세입니다. 하지만 저희는 더 유연하게 대처할 수 있습니다.
비슷한 테스트를 수행하여 품질의 컷오프 값을 결정할 수 있지만 성능 비용이 변동될 수 있습니다. 하늘을 볼 때는 GPU 사이클이 유휴 상태가 되지만, 세부 영역을 볼 때는 프레임 시간제한을 초과할 가능성이 있습니다.
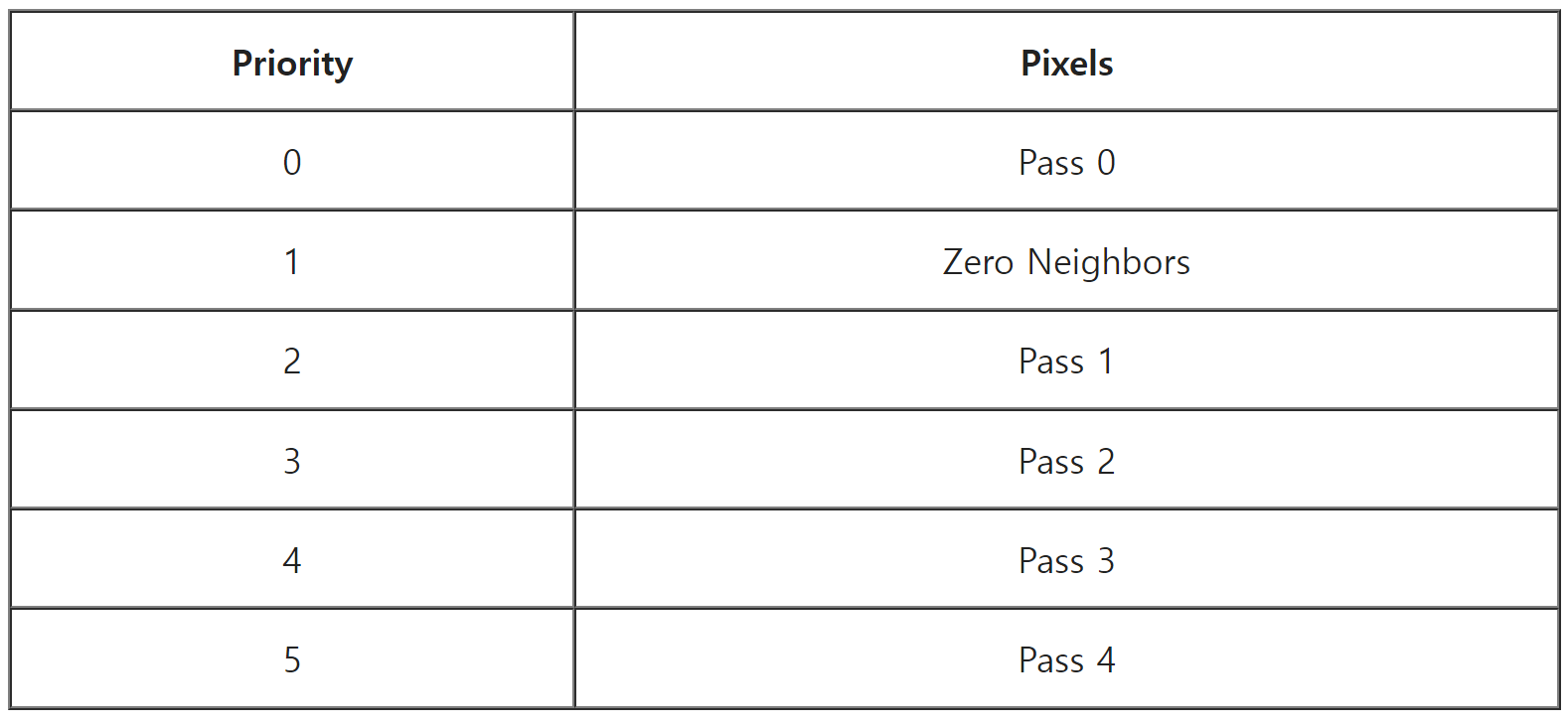
대신 각 픽셀에 대해 4비트 값으로 우선순위를 선택합니다. 그런 다음 모든 픽셀을 히스토그램으로 묶고 최종 이미지에서 음영 처리할 픽셀 수에 대한 명시적인 임계값을 설정할 수 있습니다. 그런 다음 컷오프 값을 찾을 수 있으며, 컷오프는 0에서 16 사이의 실수 값이 됩니다. 각 픽셀은 임계값에 대해 우선순위와 디더 값을 테스트합니다. 3.62 값은 우선순위 0, 1, 2의 모든 픽셀과 우선순위 3의 픽셀 중 약 62%를 포함합니다.
보간 알고리즘은 각 패스가 후속 픽셀에 영향을 미치는 패스로 실행되므로 당연히 이전 패스의 픽셀이 더 높은 우선순위를 가져야 합니다. 또한 4개의 이웃 픽셀과 동일한 드로우 콜을 공유하지 않는 픽셀도 있으므로 이 픽셀도 높은 우선순위가 필요합니다. 따라서 기본 우선순위는 다음과 같습니다:
그 외에도 몇 가지 주의해야 할 사항이 있습니다. 일반적으로 얇은 오브젝트는 내부에 유효한 픽셀이 충분하지 않을 때 상당히 좋지 않게 보입니다. 따라서 가까운 4개의 이웃이 각 방향에서 동일한 드로우 콜인지 빠르게 검색한 다음 우선순위를 바이어스 하여 가장자리의 우선순위가 높아지도록 할 수 있습니다. 다음은 예시 이미지입니다.

다음은 씬 오브젝트 우선순위 바이어스가 꺼진 상태에서 선택한 픽셀입니다:

그리고 씬 오브젝트 우선순위 바이어스가 켜져 있는 선택된 픽셀:

다음은 우선순위 바이어스에 의해 추가된 픽셀만 표시한 이미지의 차이점입니다.

그러나 총 픽셀 수는 일정하기 때문에 어딘가에 픽셀을 추가하면 다른 곳에서 픽셀을 제거해야 합니다. 다음은 가장자리에 우선순위를 부여하여 제거된 픽셀을 보여주는 차이의 반대입니다.

이 접근 방식의 장점은 원하는 메트릭 조합을 간단히 선택할 수 있고 매 프레임마다 항상 일정한 픽셀 수를 렌더링 할 수 있다는 것입니다.
Results
그렇다면 숫자는 어떤 모습일까요? 숫자의 경우 이전 배치에서 단순화하겠습니다. 프리패스, 머티리얼 패스, 라이팅 패스의 길이를 추적할 것입니다. 하지만 다른 모든 것은 기타에 있습니다. 항상 그렇듯이 머티리얼과 라이팅 패스는 포워드에서 병합됩니다.

결과는 놀랍지 않습니다. 매우 큰 삼각형의 수가 적으면 VRS가 완벽하게 작동합니다. 저는 VRS를 사용한 통과 시간과 사용하지 않은 통과 시간의 비율을 비교하는 것을 좋아합니다. 이를 통해 각 패스에 대해 VRS를 켜서 실제로 얼마나 절약할 수 있는지 알 수 있습니다.

하드웨어 VRS의 결과는 꽤 훌륭합니다. 포워드 패스에서는 픽셀의 25%가 25%의 시간이 소요될 것으로 예상했지만 실제로는 27.6%가 소요되었습니다. 디퍼드 머티리얼 패스는 37.7%의 시간이 소요됩니다. 절대적인 수치로 보면 디퍼드 머티리얼 패스가 포워드 패스보다 실제로 더 적게 걸리므로(0.442ms 대 0.402ms), 프리미티브 설정 비용과 같은 다른 병목 현상에 부딪히는 것이 타당합니다. 대역폭 비용도 그럴듯한 병목 현상입니다. 그럼에도 불구하고 여전히 좋은 개선 사항입니다. 디퍼드 라이팅 패스는 거의 변하지 않았습니다.
흥미롭게도 가시성 평가의 경우 세 가지 방법 중 가장 낮은 점수를 받았습니다. 재료 평가 패스는 원래 시간의 54.6%가 소요되어 다른 두 가지 방법보다 열등합니다. 조명 패스는 원본 시간의 32.3%가 소요되어 더 나은 성능을 보입니다. 제 생각에는 가시성 VRS 알고리즘의 메모리 액세스 패턴이 더 희박해지면서 효율성이 떨어진다고 생각합니다.
다음은 각 삼각형이 약 5~10픽셀인 중간 밀도 삼각형의 경우의 수치입니다.

트라이앵글 수가 증가함에 따라 래스터화 패스(포워드 및 디퍼드 머티리얼) 비용이 크게 증가하지만 가시성은 상대적으로 안정적으로 유지됩니다. 더 흥미로운 점은 상대적인 VRS 절감 효과입니다.
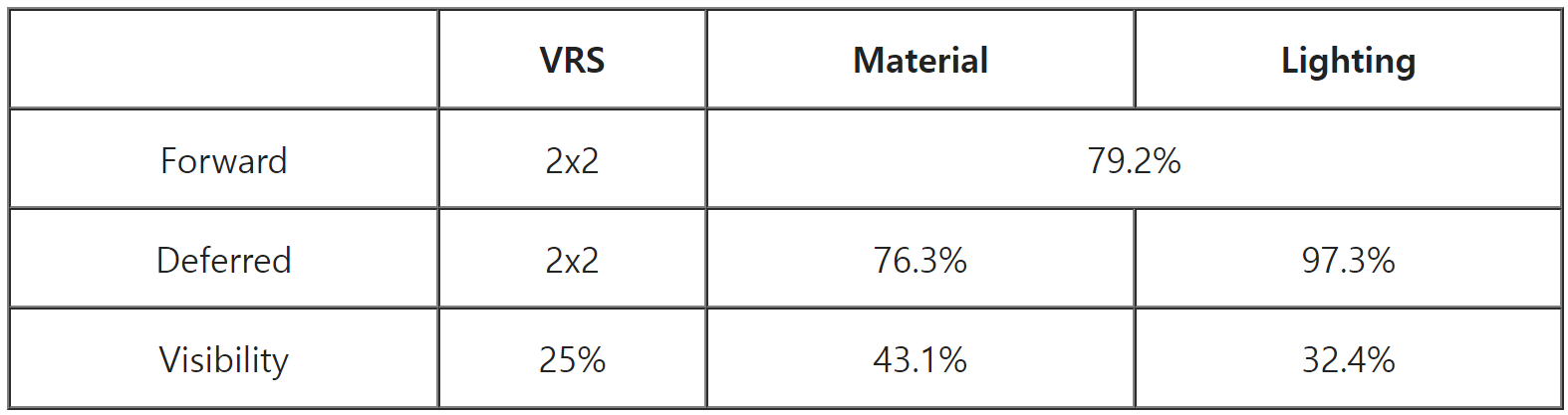
포워드 및 디퍼드 머티리얼 패스는 각각 비-VRS 타이밍의 79.2%와 76.3%가 소요됩니다. 트라이앵글이 작아질수록 하드웨어 VRS의 절감 효과는 크게 감소합니다. 하지만 가시성 패스는 원래 시간의 43.1%로 실행되고 있습니다. 이상적으로는 25%로 실행되는 것이 좋겠지만 43.1%도 꽤 괜찮은 수치입니다.
마지막으로 고밀도 삼각형의 경우의 수치는 다음과 같습니다.

다시 한번 VRS 패스와 일반 패스의 상대적 비용을 비교해 보겠습니다.

디퍼드 머티리얼의 경우 9.2%가 될 거라고는 전혀 예상하지 못했기 때문에 조금 의외입니다. 해당 패스가 예상치 못한 무언가와 겹치는지 확인하기 위해 PIX 캡처를 살펴봤지만 눈에 띄는 것은 없었습니다. 속도 저하가 실제로 있는 것처럼 보이지만, 이 경우 VRS를 끄면 간단히 제거할 수 있으므로 제거하기는 어렵지 않습니다. 삼각형이 작아지면 하드웨어 VRS 이득이 사라집니다.
이를 다른 방식으로 생각해 봅시다. 다음은 저밀도 및 중간 밀도에서 디퍼드와 가시성에 대한 머티리얼 패스의 비용만 비교한 것입니다.

비저빌리티 렌더링에서 계단식 효율성 향상을 얻고 있습니다. 디퍼드 머티리얼 패스는 저밀도 트라이앵글을 1배로 사용하는 비저빌리티 머티리얼 패스보다 약간 더 낫기 때문에 약간 느리게 실행됩니다(디퍼드 속도의 95.3%). 하지만 밀도가 중간으로 올라가면 Visibility Material 셰이더는 Deferred 패스보다 약 1.8배 빠르게 실행됩니다. 그리고 밀도가 25%로 높아지면 비저빌리티의 작업 감소 효과가 배가되어 비저빌리티 머티리얼 VRS 패스는 이제 디퍼드 패스보다 약 3.2배 더 빨라집니다.
1픽셀 트라이앵글을 목표로 하면 수치는 더욱 극단적으로 증가합니다. 다음은 고밀도 트라이앵글의 경우와 동일한 비교입니다. 디퍼드 VRS 패스가 실제로 더 높았기 때문에 비-VRS 번호로 바꿨습니다.

벤치마크를 수행할 때 흔히 하는 질문은 다음과 같습니다: 이 워크로드가 얼마나 더 빠른가? VRS를 사용하면 가시성이 더 빨라지지만 그게 중요한 것은 아닙니다. 오히려 어떤 종류의 워크로드를 실행할 수 있을까 하는 질문이 더 중요합니다.
더 큰 이점은 가시성 VRS가 머티리얼 및 라이팅 패스의 스케일링을 근본적으로 변경한다는 점입니다. 중간 밀도의 경우 머티리얼 패스가 3.2배 빨라집니다. 즉, 이론적으로 머티리얼 그래프에 약 3.2배 더 많은 노드를 사용할 수 있습니다. 고밀도 케이스와 비교하면 머티리얼 케이스는 약 6.5배 더 빠릅니다. 또 다른 측면에서 라이팅 패스는 약 3.1배 빠릅니다. 프레임 시간을 줄일 수 있다는 장점이 아닙니다. 오히려 같은 예산으로 머티리얼과 조명의 복잡도를 크게 높일 수 있다는 이점이 있습니다.
물론 실제 이득은 더 적을 것입니다. 추가 패스에 대한 고정 비용을 지불해야 하므로 이득이 사라집니다. 그리고 속도 향상은 모든 유형의 셰이딩에 동일하게 적용되지 않습니다. 예를 들어 스토캐스틱 레이 트레이싱을 통해 노이즈가 제거된 그림자를 누적하는 경우 가변 속도로 셰이딩 하여 수렴 속도를 높일 필요는 없습니다.
실제로 머티리얼 복잡도가 6.5배/3.2배 증가하거나 조명 복잡도가 3.1배 증가하지는 않습니다. 하지만 두 범주 모두에서 1.2배의 이득을 얻는 것만으로도 큰 성과입니다. 이 합성 테스트 사례의 수치보다 실제 이득이 더 작을지라도 결과는 설득력이 있습니다.
Decoupled Visibility Multisampling
이전 게시물의 DVM에서도 작동하나요? 간단히 말해서 그렇습니다. 가시성 VRS는 GBuffer의 기본 구조를 변경하지 않습니다. 따라서 단일 프레임 케이스는 "그냥 작동"합니다. 여전히 더 많은 작업이 필요한 한 가지 영역은 TAA입니다. DVM 누적 공식을 조정했는데 효과가 있지만 일반 1x TAA 케이스만큼 작은 물체의 움직임이 깔끔하지는 않습니다. TAA를 제대로 조정하려면 몇 달 동안 콘텐츠의 모든 구석진 케이스에 집착하여 모든 세부 사항을 최적화하기 위해 패스와 숫자를 만지작거려야 합니다. 안타깝게도 테스트할 실제 콘텐츠가 없고 장난감 엔진의 파라미터를 미세 조정하는 데 몇 달을 소비하는 것은 말이 되지 않습니다. DVM을 사용한 TAA는 정지 상태에서는 수렴하고 움직일 때는 주관적으로 괜찮아 보입니다. 그러나 이 정도로는 충분하지 않으며 최적화는 다음 날을 기다려야 합니다.

Sparse GBuffers
한 가지 주의할 점은 GBuffer가 희박하다는 것입니다. 하지만 대부분의 화면 공간 패스는 GBuffer에서 가까운 값을 샘플링해야 합니다. 그렇다면 어떤 옵션이 있을까요?
- Extract Full-Res: 가장 간단한 옵션은 조명에서와 마찬가지로 GBuffer에서 동일한 패스를 실행하는 것입니다. 즉, 전체 해상도로 확장하는 것입니다. 대역폭 비용이 많이 들지만 가장 쉬운 해결책입니다.
- Extract Half-Res: 대안으로 전체 해상도 GBuffer를 건너뛰고 절반 해상도로만 갈 수도 있습니다. 이웃이 필요한 모든 패스가 하프 해상도 버전을 가져와도 괜찮을까요? 반 해상도 노멀을 강제로 사용해야 한다면 SSAO가 정말 그렇게 많이 저하될까요?
- Embrace Sparsity: 그렇다면 실제로 전체 해상도 GBuffer가 필요할까요? 전체 GBuffer를 저장하는 대신 근처 샘플 목록 몇 개만 저장하는 것으로 충분하지 않을까요? 예를 들어, 서브서피스 스캐터링에서는 일반적으로 근처 지점을 무작위로 샘플링하고 싶습니다. 실제로 특정 지점은 중요하지 않습니다. 그보다는 편향 없이 일정한 거리의 합리적인 지점에서 무작위로 샘플링하고 싶을 뿐입니다. 따라서 각 픽셀에서 선택할 수 있는 4개의 픽셀 목록이 제공된다면, 그 4개의 픽셀 중 하나를 무작위로 선택할 수 있습니다. 편견 없이 수학을 조정하여 이를 수행할 수 있어야 합니다. 하지만 이를 위해서는 모든 GBuffer 패스에 대한 철저한 검토가 필요하며 대부분의 엔진에는 이러한 패스가 많이 있습니다.
대부분의 화면 공간 패스는 풀 해상도 GBuffer를 지불하지 않고도 할 수 있을 것 같습니다. 월드 노멀은 풀 해상도로 추출하되 나머지는 모두 희박하게 남겨두는 등 하이브리드 접근 방식이 가장 좋을까요? 그 질문에 대한 답은 없지만 해결해야 할 흥미로운 문제인 것 같습니다.
Sample Choosing
또한 VRS에 대한 다양한 프레젠테이션에서 음영률을 줄이기 위한 다양한 지표에 대해 논의했다는 점도 주목할 필요가 있습니다. 이 구현에서 픽셀 우선순위를 결정하는 유일한 입력은 통과 지수, 에지까지의 거리, 픽셀에 이웃이 없는 경우입니다. 하지만 다른 옵션도 많이 있습니다. 특별한 순서는 없습니다:
- 디테일이 부족한 픽셀은 당연히 샘플을 더 적게 사용할 수 있습니다. 고전적인 감지 방법은 소벨 필터입니다.
- 움직이는 물체는 흐릿한 경향이 있으므로 움직임 벡터가 큰 픽셀의 샘플을 줄일 수 있습니다.
- 투명도가 높은 영역은 샘플 수를 줄일 수 있습니다.
- 씬 GUI 아래의 픽셀은 확실히 전체 속도로 렌더링 할 필요가 없습니다.
- DOF에서 초점이 맞지 않는 영역도 더 낮은 속도로 샘플링할 수 있습니다.
- 스카이박스 픽셀에서 음영 비율을 비활성화할 수 있습니다.
- VR의 포비티드(Forveated) 렌더링은 음영률을 크게 떨어뜨릴 수 있습니다.
다른 콘텐츠도 있을 것입니다. 이 중 어느 것을 사용하는 것이 합리적일까요? 솔직히 모두 이러한 기술을 사용하면 큰 성공을 거둘 수 있다고 생각합니다. 하지만 그러기 위해서는 이 구현에 비현실적인 더 다양한 콘텐츠에 대한 테스트가 필요합니다.
References
[1] AMD RDNA 2 및 DirectX 12 얼티밋이 탑재된 차세대 게임. AMD.
Next-Generation Gaming with AMD RDNA 2 and DirectX 12 Ultimate
Earlier this year we told you that in partnership with Microsoft we will provide full support for DirectX 12 Ultimate in the AMD RDNA 2 gaming architecture. Now with AMD Radeon RX 6000 Series graphics cards powered by AMD RDNA 2, our support for Microsoft
community.amd.com
[2] 콜 오브 듀티의 가변 비율 셰이딩: 모던 워페어. 마이클 드로봇.
Software-based Variable Rate Shading in Call of Duty: Modern Warfare
This lecture covers a novel rendering pipeline used in Call of Duty: Modern Warfare (2020). It enables a highly customizable software-based variable rate shading; a method to render parts of the render target at a resolution matching image frequency. As op
research.activision.com
[3] 이론에서 실무에 이르기까지 Microsoft DirectX 12를 사용하는 가변 비율 셰이딩 티어 1. 마리사 뒤 보이스와 존 깁슨.
https://www.youtube.com/watch?v=d-qEvmVcg8I
[4] Get Started with Variable Rate Shading on Intel Processor Graphics. Intel.
https://software.intel.com/content/www/us/en/develop/articles/getting-started-with-variable-rate-shading-on-intel-processor-graphics.html
Get Started with Variable Rate Shading on Intel® Processor Graphics
VRS hardware capability is now available on Intel Graphics technology. Take advantage of the VRS API that is part of Microsoft DirectX 12 on Windows.
www.intel.com
[5] 지연된 적응형 컴퓨팅 셰이딩. 이안 말렛과 켐 육셀. (https://geometrian.com/data/research/dacs/HPG2018_DeferredAdaptiveComputeShading.pdf)
[6] 하드웨어 스캐터 타일을 사용한 효율적인 적응형 지연 셰이딩. 이안 말렛, 켐 육셀, 래리 사일러. (https://dl.acm.org/doi/abs/10.1145/3406184)
[7] VRWorks - Variable Rate Shading (VRS). NVIDIA. (https://developer.nvidia.com/vrworks/graphics/variablerateshading)
[8] Variable Rate Shading: A scalpel in a world of sledgehammers. Jacques van Rhyn. (https://devblogs.microsoft.com/directx/variable-rate-shading-a-scalpel-in-a-world-of-sledgehammers/)
[9] Moving Gears to Tier 2 Variable Rate Shading, Jacques van Rhyn. (https://devblogs.microsoft.com/directx/gears-vrs-tier2/)
[10] A Deferred Material Rendering System. Tomasz Stachowiak. (https://onedrive.live.com/view.aspx?resid=EBE7DEDA70D06DA0!115&app=PowerPoint&authkey=!AP-pDh4IMUug6vs)
http://filmicworlds.com/blog/software-vrs-with-visibility-buffer-rendering/
Software VRS with Visibility Buffer Rendering
Introduction
filmicworlds.com