
랜덤 분할 조명(Stochastic Tile-Based Lighting) 발표를 시청해 주셔서 감사합니다.
Hello everyone, and welcome to the presentation about Stochastic Tile-Based lighting.
저는 HypeHype에서 수석 그래픽 엔지니어로 일하고 있는 Jarkko Lempiäinen 입니다.
I'm Jarkko Lempiäinen and I work as a Principal Graphics Engineer at HypeHype.
지난 25년 동안 Ubisoft, Unity, Treyarch 등에서 AAA급 렌더링 기술 개발에 주로 집중해 왔습니다. 약 1년 전 HypeHype에 합류했고, 지금은 99달러짜리 보급형 스마트폰부터 하이엔드 PC까지 모든 기기에서 동작하는 UGC(User-Generated Content) 플랫폼을 만들고 있습니다.
Over the past 25 years, I have focused mainly on developing AAA rendering technology at companies like Ubisoft, Unity and Treyarch. I joined HypeHype about a year ago, where we are building a User-Generated Content platform that runs on everything from $99 budget phones to high-end PCs.
현재 HypeHype에는 사용자가 만든 게임이 약 50만 개 정도 있으며, 누구나 이 게임들을 플레이하거나 자신의 취향에 맞게 리믹스할 수 있습니다. HypeHype의 목표는 기술적 배경이 없는 일반 사용자까지 포함해, 누구나 게임을 쉽고 재미있게 만들 수 있게 하는 것입니다. 이는 우리가 설계하는 기술에 큰 제약 조건으로 작용합니다. 기술은 최소한의 기술 이해만으로도 동작해야 하고, 다양한 모든 기기에서 좋은 화질과 높은 성능을 유지해야 합니다. 우리는 모바일 기기에서도 실행될 수 있는 직관적인 제작 도구를 만들고 있으며, 진입 장벽을 더 낮추기 위해 워크플로에 AI도 통합하고 있습니다.
Currently, HypeHype has about half a million games created by our users, which anyone can play or remix for their liking. HypeHype's goal is to make game creation easy and fun for everyone, including casual users with no technical background. This has big implications on the technology we develop, because it just has to work with minimal technical skills while having good quality and high performance across all the devices. We are building intuitive creation tools that run even on mobile devices and are integrating AI into the workflow to make the barrier to entry even lower.


제가 HypeHype에 합류했을 당시 엔진은 그림자가 있는 태양광 한 종류만 지원했습니다. 게임의 시각적 품질을 끌어올리기 위해, 저는 로컬 조명 솔루션을 구현하기 시작했습니다. 이번 발표에서는 우리가 예산형 모바일 폰에서도 돌아가도록 개발한 랜덤 조명 알고리즘을 소개하겠습니다. 왜 이런 알고리즘이 필요했는지에 대한 동기, 구현 세부, 그리고 우리가 얻은 결과까지 순서대로 설명드리겠습니다.
When I joined HypeHype, the engine supported only shadowed sunlight, and to boost the visual quality of the games, I started to implement a local lighting solution. In this talk, I'll take you through the stochastic lighting algorithm that we developed to run even on budget mobile phones. I'll cover the motivation behind it, implementation details, and the results we've achieved.
모바일 플랫폼의 도전 과제
모바일 폰에서 로컬 조명을 지원하려면, 조명 알고리즘 설계에 큰 영향을 미치는 몇 가지 특수한 제약 조건을 고려해야 합니다.
To support local lighting on mobile phones, we need to deal with some unique constraints that significantly influence the lighting algorithm design.
하드웨어 제약

가장 중요한 제약 중 하나는 메모리 대역폭입니다. 특히 저가형 모바일 기기에서는 이 대역폭이 매우 제한적입니다. 오늘날 99달러짜리 보급형 스마트폰은 약 15 GB/s 정도의 피크 대역폭과 250 GFLOP/s 수준의 ALU 연산 성능을 가지는데, 이는 20년 전에 출시된 Xbox 360, PS3와 비슷한 수준입니다. 심지어 고급형 스마트폰도 피크 대역폭이 약 85 GB/s 정도에 불과합니다. 비교를 위해, Xbox Series X와 PS5 Pro는 500 GB/s가 넘는 대역폭과 각각 12, 17 TFLOP/s의 ALU 성능을 제공합니다.
One of the most critical limitations is the memory bandwidth, which is very constrained on mobile, especially in the low-end. $99 budget phones today have around 15 GB/s of peak bandwidth and around 250 GFLOP/s of ALU power, which is about the same as Xbox360 and PS3 released 20 years ago. Even high-end phones peak only at around 85 GB/s. For comparison, Xbox Series X and PS5 Pro have over 500 GB/s of bandwidth, and respectively 12 and 17 TFLOP/s of ALU power.
PC와 콘솔과 달리 모바일 기기는 패시브 쿨링을 사용하기 때문에, 대역폭을 많이 쓰는 연산은 곧바로 발열과 스로틀링으로 이어집니다. GPU와 DRAM 사이에서 단지 1바이트의 데이터를 옮기는 데 들어가는 전력 소모가 단순한 ALU 연산 대비 약 100배에 달할 정도입니다.
Unlike PCs and consoles, mobile devices are passively cooled, so bandwidth-heavy operations quickly translate to heat and throttling. To put things in perspective, moving just a byte of data between GPU and DRAM consumes hundred times more power than a simple ALU operation.
타일 기반 렌더링 아키텍처
모바일 GPU는 대역폭 절감을 위해 주로 타일 기반 렌더링(Tile-Based Rendering)에 의존합니다. 이 아키텍처에서는 프레임을 여러 개의 타일로 나누고, 각 타일을 작은 고속 온칩 메모리에 렌더링합니다. 한 타일에 대한 모든 삼각형이 래스터화되면, 해당 타일의 렌더 타깃 데이터는 무손실 프레임버퍼 압축 등을 사용해 메인 메모리로 기록됩니다.
Mobile GPUs rely largely on Tile-Based Rendering to conserve bandwidth. In this architecture, the frame is split to tiles and rendered tile by tile into small but fast on-chip memory. Once all triangles for a tile are rasterized, the tile render target data is written out to main memory, often using lossless framebuffer compression to further reduce the memory transfer costs.
이 구조를 최대한 활용하려면, 렌더링 알고리즘은 컴퓨트 셰이더가 아니라 픽셀 셰이더 기반으로 작성되어야 하며, DRAM 왕복을 줄이기 위해 렌더 패스의 수도 최소화해야 합니다.
To take advantage of this, rendering algorithms must be written with pixel shaders instead of compute shaders and the number of render passes should be minimized to reduce DRAM round-trips.
ALU 사용을 최적화하기 위해 알고리즘은 처음부터 fp16 사용을 염두에 두고 작성하는 것이 좋습니다. 모바일 기기는 이미 fp16 듀얼 레이트 파이프라인을 널리 채택하고 있기 때문입니다. 이 밖에도 분기 다이버전스 최소화, VGPR 사용 최적화와 같은 일반적인 GPU 최적화 기법 역시 중요합니다.
To optimize the ALU usage, algorithms should be written from ground up to work with fp16, since mobile devices have widely adopted double-rate fp16 pipelines. Besides this there are the common GPU optimizations, like minimizing branch divergence and optimizing VGPR usage.
사용자 측 제약

사용자 관점에서 보면, 우리 플랫폼은 캐주얼 크리에이터를 위한 것이기 때문에 조명 측면에서 추가적인 도전과제가 있습니다.
From the user side, our platform is designed for casual creators, which poses some extra challenges for lighting.
우리 크리에이터들이 성능 트레이드오프를 이해하거나, 하드웨어마다 조명 파라미터를 따로 조정해주길 기대할 수는 없습니다. 조명 컨트롤은 직관적이고 견고해야 하며, 크리에이터들이 장면에 조명을 "쉽고 재미있게" 더할 수 있어야 합니다.
We can't expect our creators to understand performance trade-offs or tweak lighting parameters for different hardware. Lighting controls must also be intuitive and robust to make lighting the scenes simple and fun for our creators.
또 게임이 하이엔드 PC나 스마트폰에서 만들어져서 보급형 안드로이드 기기에서 플레이되더라도, 일관된 결과를 제공해야 합니다. 성능과 일관성이 무너지면 게임 플레이 자체를 깨뜨릴 수 있는 문제가 생길 수 있습니다.
And we must deliver consistent results, whether the game is created on high-end PC or phone and played on a budget Android device. The performance and consistency must hold up, or it could lead to gameplay-breaking issues.

또한 우리는 조명이 랜덤하게 생성되고 이동하는 상황에도 대비해야 합니다. 예를 들어, 여기서 보이는 분홍색 구체 하나하나가 적이 죽을 때마다 만들어지는 조명입니다. 이런 예측 불가능한 조명 뭉침 때문에 큰 프레임 드롭이나 눈에 거슬리는 시각 아티팩트가 발생해서는 안 됩니다.
We must also prepare that lights may be randomly spawned and moved. For example, every pink orb here is a light created whenever an enemy dies. We can't afford large framerate drops or visually disturbing artifacts because of unpredictable light clumping.
또 어떤 크리에이터는 그냥 한 방에 그림자까지 있는 조명을 50개쯤 넣을 수도 있습니다. 왜 안 되겠어요? 크리에이터들은 에셋 라이브러리의 프리팹을 갖다 붙여 씬을 구성하는데, 이 프리팹 안에 조명이 들어 있을 수 있고, 이렇게 해서 게임 월드가 금방 수많은 조명으로 채워집니다.
Or, our creators might just decide to add 50 shadowed lights to a room, because why not? The creators kitbash scenes from our asset library prefabs that can include lights and quickly populate game worlds with a large number of lights.
기존 솔루션 탐색
분할 지연 조명 (Tiled Deferred Lighting)

기존 솔루션을 검토하기 위해, 많은 현대 렌더러에서 사용하는 분할 지연 조명(Tiled Deferred Lighting)을 먼저 고려했습니다. 이 방식의 장점은 로컬 메모리 접근과 파동(wave) 단위로 연속적인 조명 평가가 가능하다는 점으로, GPU 성능에 유리합니다.
To explore existing solutions, we considered Tiled Deferred lighting used by many modern renderers. The benefit of this solution is local memory access and wave coherent lighting evaluation, which is good for high GPU performance.
하지만 이 방식은 타일당 조명 수에 대해 선형적으로만 스케일링되며, 아티스트가 성능을 위해 조명의 영향 범위를 꼼꼼히 제한해 준다는 가정을 깔고 있습니다.
However, it scales only linearly with the number of lights per tile and assumes that artists light scenes carefully limiting their region of influence to keep the performance in check.
비교적 단순한 씬에서도, 특히 그림자 실루엣 주변에서는 타일당 조명 수가 금방 많아질 수 있습니다. 여기에 동적인 조명까지 추가되면, 조명 비용은 매우 예측 불가능해지고, 특히 성능이 낮은 기기에서는 심각한 성능 문제로 이어질 수 있습니다. 일부 엔진은 타일당 조명 수에 상한을 두는데, 이 상한을 넘으면 타일 단위의 깜빡임 아티팩트가 발생합니다.
Even in quite simple scenes the light count per tile can become high, especially at object silhouettes as highlighted here. When dynamic lights are added to the mix, the lighting cost can be very unpredictable causing performance issues especially on weaker devices. Some engines limit the number of lights per tile but exceeding this limit results in flickering tile artifacts.
타일 단위의 조명 컬링 또한 비용이 만만치 않습니다. 특히 타일 시야체 프러스텀을 정확히 사용해 정밀하게 계산하면 그 비용은 더욱 커집니다.
The light culling for the tiles is also quite costly, especially when done precisely with exact tile frustum checks.
ReSTIR

우리는 Bitterli 등이 제안한 ReSTIR도 랜덤 조명 솔루션으로 검토했습니다. 랜덤 조명의 강점은 씬의 조명 복잡도와 관계없이 비용을 고정할 수 있다는 점입니다. 그 대가로 일정 수준의 노이즈가 추가됩니다. 이렇게 하면 한 픽셀에 아주 많은 조명이 영향을 주더라도 조명 예산을 터뜨리지 않을 수 있습니다. 제가 밴쿠버에서 찍은 이 야경 사진처럼 말이죠. ReSTIR은 픽셀 단위로 조명 샘플링을 수행하고, 균일한 장면 조명 샘플링 외에도 이전 프레임의 주변 픽셀 이웃으로부터 조명을 다시 샘플링합니다.
We had also a look at ReSTIR by Bitterli et al. for a stochastic lighting solution. The benefit of stochastic lighting is the fixed cost regardless of the scene lighting complexity, at the expense of some added noise. You can have many lights influencing a single pixel without blowing the lighting budget, like in this night shot I just took here in Vancouver. ReSTIR performs light sampling per pixel and in addition to uniform scene light sampling it resamples lights from the previous frame local pixel neighborhood.
균일 샘플링은 장면의 조명 리스트를 랜덤하게 접근하기 때문에 캐시 친화적이지 못하고, 메모리 대역폭 사용량을 크게 늘립니다. 균일 샘플 결과는 매우 노이즈가 크기 때문에, ReSTIR은 히스토리 버퍼로부터 또 한 번의 시공간 재샘플링을 수행합니다. 이것 역시 캐시 친화적이지 않고 대역폭을 많이 소모하는 연산입니다. 이렇게 픽셀마다 대역폭 집약적인 샘플링을 수행하면, 모바일에서는 알고리즘 비용이 상당히 커집니다.
The uniform sampling accesses the scene lights randomly which is quite cache unfriendly and increases the memory bandwidth usage. Because the result from the uniform sampling is very noisy, ReSTIR performs another spatiotemporal resampling step from the history buffer, which is another cache unfriendly and bandwidth-heavy operation. Doing such bandwidth intensive sampling per pixel, makes this algorithm quite expensive on mobile.
또 픽셀 단위 샘플링 때문에 픽셀마다 조명 데이터와 타입이 랜덤하게 달라질 수 있습니다. 그 결과 조명 평가 중에 비연속적인 조명 데이터 로드와 분기 다이버전스가 발생해 성능을 저하시킵니다. 우리가 알기로는, 우리의 요구 사항을 만족하면서도 저가형 모바일을 염두에 두고 설계된 기존 조명 솔루션은 없었습니다. 이것이 바로, 모바일의 제약 안에서 동작하도록 특별히 맞춰진 랜덤 타일 기반 조명 알고리즘을 개발하게 된 이유입니다.
Also, because of the per pixel sampling, light data and types can vary randomly per pixel. This causes incoherent light data loads and diverging code execution paths during lighting evaluation, which hurts performance. We weren't aware of any existing lighting solution that matched our needs and were designed low-end mobile in mind. This led us to develop our Stochastic Tile-Based lighting algorithm tailored specifically to work within the mobile limits.
랜덤 타일 기반 조명 알고리즘

핵심 설계 철학
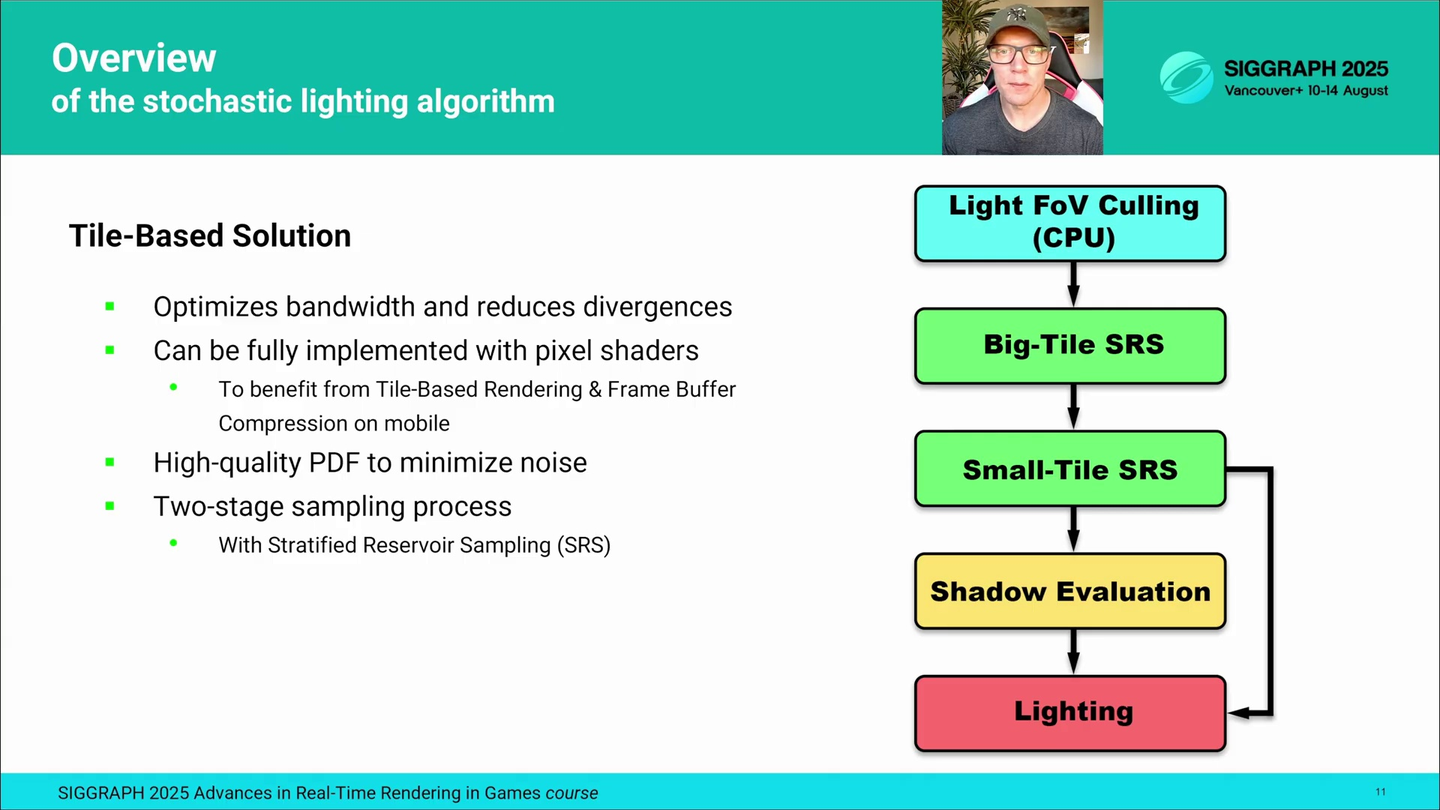
랜덤 타일 기반 조명 알고리즘은 픽셀 단위가 아니라 타일 단위로 조명 샘플링을 수행합니다. 즉, 각 타일마다 해당 타일의 모든 픽셀이 공유하는 조명 샘플 집합을 하나 저장합니다. 이를 통해 메모리 사용량과 대역폭, 그리고 조명 평가 중 파동 다이버전스를 크게 줄일 수 있습니다. 전통적인 Tiled Deferred 조명과 마찬가지로, GPU 파동 안의 스레드가 동일한 실행 경로를 따르고 연속적인 데이터 로드의 이점을 얻을 수 있습니다.
The Stochastic Tile-Based lighting algorithm performs light sampling per tile, rather than per pixel. This means that for each tile we store a single set of light samples shared across all its pixels, significantly reducing memory usage, bandwidth, and wave divergence during lighting evaluation. Much like traditional Tiled Deferred lighting, this allows threads in a GPU wave to take the same execution path and benefit from coherent data loads.
또한 알고리즘의 모든 패스가 모바일의 타일 기반 렌더링 아키텍처와 프레임버퍼 압축의 이점을 얻도록, 픽셀 셰이더만으로 효율적으로 구현될 수 있게 설계했습니다. 물론 하드웨어 아키텍처에 따라 컴퓨트 셰이더로 구현하면 추가적인 성능 향상을 기대할 수도 있습니다.
We also designed the algorithm so that all the passes can be implemented efficiently with pixel shaders to benefit from tile-based rendering architecture and frame buffer compression on mobile. That said, compute shader implementations can further improve performance, depending on the hardware architecture.
노이즈와 디노이즈 비용을 최소화하기 위해, 각 조명 샘플링이 타일에 대한 각 조명의 영향을 잘 근사하는 고품질 중요도 함수에 의해 가이드되도록 했습니다. 예를 들어, 어떤 타일이 특정 조명에 대해 완전히 그림자 속에 있다면, 이상적으로는 그 조명은 조명 평가 대상에 포함되지 않아야 합니다.
To minimize noise and denoising cost, we wanted the light sampling to be guided by a high-quality importance function that closely approximates influence of each light to a tile. For instance, if a tile is fully in shadow from a light, that light should ideally not be picked for lighting evaluation.
하지만 씬의 모든 타일과 조명에 대해 정확한 PDF를 계산하는 것은 비용이 너무 크기 때문에, 우리는 계층적 저장소 샘플링(Stratified Reservoir Sampling, SRS)을 이용한 2단계 샘플링 과정을 설계했습니다.
However, computing a precise PDF for every tile and light in the scene would be far too expensive, so we developed a two-stage sampling process using Stratified Reservoir Sampling.
알고리즘 파이프라인 개요

알고리즘은 먼저 CPU 측에서 카메라 시야 내에 있는 씬 조명을 컬링하는 것부터 시작합니다. 이렇게 걸러진 조명 리스트가 GPU로 넘어가 첫 번째 단계인 "대(大) 타일 샘플링(Big-Tile Sampling)"에 사용되며, 여기서 화면은 더 큰 타일들로 나뉩니다. 각 대타일에 대해, 우리는 SRS를 사용해 간단하고 저비용인 PDF에 따라 조명 하위 집합을 선택하는데, 이 PDF는 해당 타일 영역에 대한 조명의 중요도를 대략적으로 근사합니다.
The algorithm start on CPU side with camera field-of-view culling of the scene lights. The list of culled lights is passed to GPU for the first "Big-Tile Sampling" stage, where the screen is divided into larger tiles. For each big-tile, we use Stratified Reservoir Sampling to select a subset of lights based on a simple low-cost PDF that roughly approximates light's importance for the tile region.
그 다음 "소(小) 타일 재샘플링(Small-Tile Resampling)" 단계에서, 각 대타일의 저장소에서 다시 한 번 SRS를 수행해 소타일에 사용할 소수의 조명을 뽑습니다. 이때는 더 정교한 PDF를 사용하며, 여기에는 보다 정확한 조명 가시성 정보와 BRDF 항이 포함됩니다.
Then, in the "Small-Tile Resampling" stage, we resample few lights for small-tiles by performing another round of SRS from corresponding big-tile reservoirs. This time we use a higher-quality PDF that includes more accurate light visibility and BRDF terms.
조명 샘플링 이후에는 지연된 그림자 패스가 이어지며, 이 단계에서 소타일 조명 샘플과 그 타일의 모든 픽셀에 대해 그림자 항을 평가합니다. 성능 최적화를 위해 그림자 평가는 조명 셰이더와 분리되어 있습니다.
The light sampling is followed by deferred shadow pass, where we evaluate shadow terms for small-tile light samples and for all the tile pixels. The shadow evaluation is decoupled from the lighting shader to optimize performance.
마지막으로 조명 패스에서는 각 픽셀에 대해 조명 샘플과 그림자 항을 읽어와 BRDF를 평가하고, 적절한 조명 가중치를 적용해 최종 조명 결과를 만듭니다.
Finally, during the lighting pass, we read light samples and shadow terms for each pixel, evaluate the BRDF, and apply proper light weighting for the final lighting result.
큰 타일 샘플링

조명 샘플링은 먼저 각 대타일마다 씬 조명 하위 집합을 뽑는 것부터 시작합니다. 이렇게 하면 이후 소타일 재샘플링 단계에서 고려해야 하는 조명 후보 수를 줄일 수 있습니다. 각 대타일은 그림처럼 128×128 픽셀 크기의 영역을 커버합니다.
The light sampling starts by sampling a subset of scene lights per big-tile to reduce the number of light candidates considered during the subsequent small-tile resampling stage. Each big-tile covers a 128x128px region of the image as shown with the checkerboard pattern.
각 대타일마다 씬 전체에서 무작위로 16개의 서로 다른 조명을 선택하여 해당 타일의 저장소에 기록합니다. 여기서 사용하는 샘플링 알고리즘이 바로 SRS입니다.
For every big-tile, we stochastically select 16 distinct lights from the scene and write them into that tile's reservoir. For the sampling, we use Stratified Reservoir Sampling.
SRS는 "비복원 샘플링(without replacement)" 알고리즘으로, 대타일 저장소 안에서 중복 조명이 생기지 않도록 보장하고, 저장소 공간을 효율적으로 사용하게 해 줍니다. 이는 각 대타일에 대해 다양하면서도 대표성이 높은 조명 집합을 유지하는 데 중요합니다. 또한 SRS는 각 저장소 슬롯이 독립적으로 샘플링되기 때문에 픽셀 셰이더로도 효율적으로 구현할 수 있습니다.
SRS is "without replacement" sampling algorithm that ensures we don't have light duplicates in big-tile reservoirs and that we use the reservoir space efficiently, which is important to maintain a diverse and representative set of lights for each big-tile. SRS can be also implemented efficiently with pixel shaders because each reservoir slot is independently sampled.

데이터 저장 형식

각 최종 조명 샘플은 그림과 같이 32비트 포맷으로 저장됩니다. 픽셀 셰이더 구현에서는 대타일 저장소의 각 슬롯에 대해 대타일 샘플링 셰이더를 실행하고, 32비트 조명 샘플을 렌더 타깃에 기록합니다.
Each resulting light sample is stored in a 32bit format as shown in the image. For pixel shader implementation, the big-tile sampling shader is evaluated for each big-tile reservoir slot that exports the 32bit light sample to the render target.
조명 인덱스는 카메라 FoV 컬링을 통과한 조명들이 들어 있는 버퍼를 가리키며, 조명 가중치는 PDF의 역수입니다. 저장소 샘플은 캐시 일관성을 높이기 위해 렌더 타깃에서 4×4 픽셀 영역 단위로 저장됩니다. 예를 들어 1080p 프레임버퍼라면, 이 저장소를 위해 60×36 픽셀 정도의 아주 작은 렌더 타깃만 있으면 충분합니다.
The light index refers to the buffer containing the camera FoV-culled lights. The light weight is the inverse of the PDF. The reservoir samples are stored in 4x4px regions in the render target for improved cache coherence. For example 1080p frame buffer requires tiny 60x36px render target for the storage.
PDF 계산
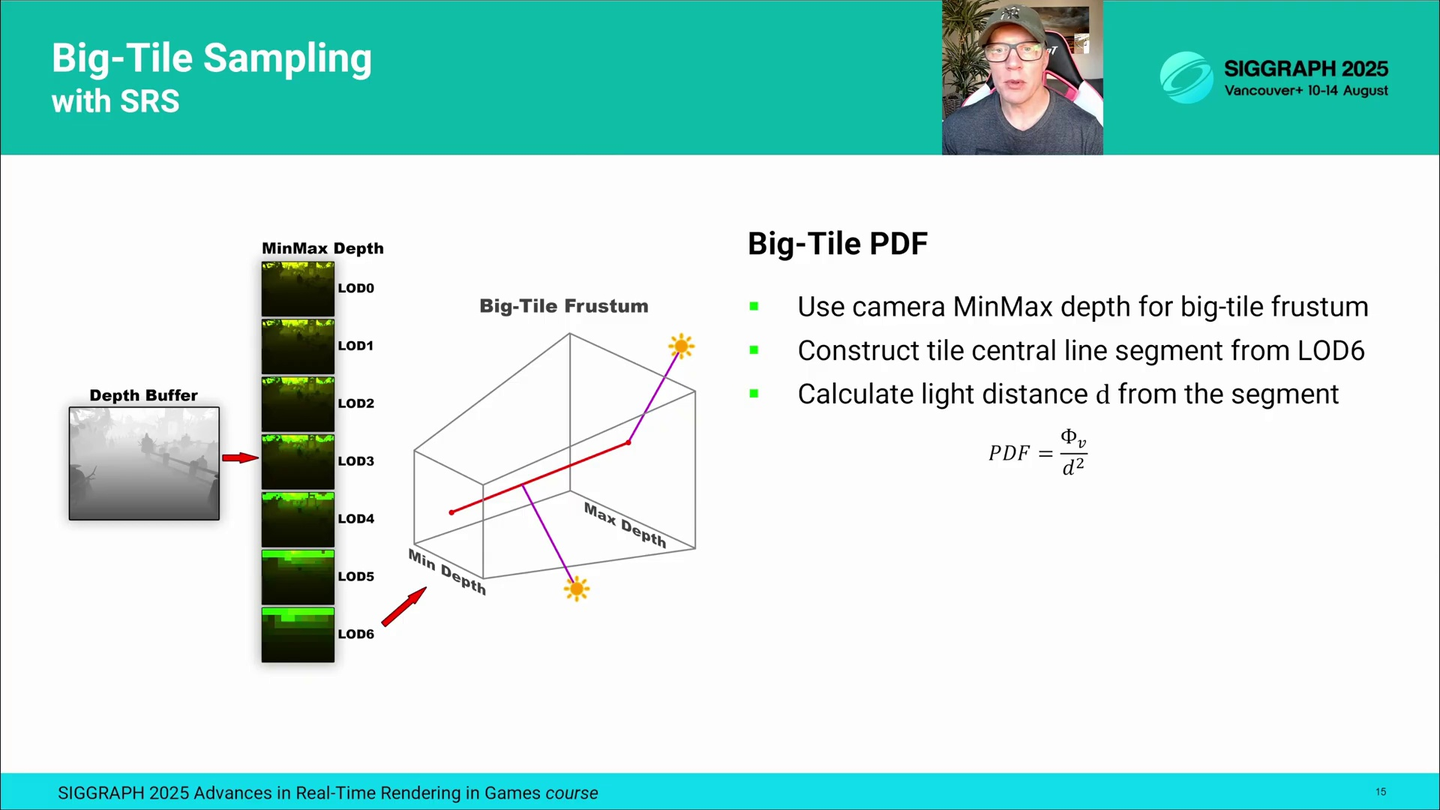
대타일 샘플링에 사용할 PDF를 계산하기 위해, 먼저 G-Buffer 패스 이후 생성된 계층적 MinMax 깊이 버퍼에서 해당 타일의 깊이 범위를 읽어옵니다. 128픽셀 크기의 대타일에는 대타일과 동일한 픽셀 풋프린트를 가진 LOD6 MinMax 깊이 버퍼를 사용합니다. 그 다음, 그림에 표시된 것처럼 깊이 범위 사이에 타일 중심 선분(빨간색)을 구성합니다.
To compute the PDF for the big-tile sampling, we start by fetching the depth bounds of the tile from hierarchical MinMax depth buffer, that was generated after the G-Buffer pass. For 128px big-tiles we use LOD6 of the MinMax depth buffer which has the same pixel footprint as the big-tile. Next, we construct the tile central line segment between the tile depth bounds, shown red in the image.
SRS 동안 우리는 모든 조명 타입에 대해 동일한 PDF를 사용합니다. 이를 위해, 선분 위의 가장 가까운 지점에서 전방위(omni) 광원에 대한 스칼라 조도(scalar illuminance)를 평가합니다. 이렇게 하면 각 조명이 해당 타일에 미치는 영향을 대략적으로 추정할 수 있고, PDF가 어디서나 양수이기 때문에 샘플링 편향을 일으키지 않습니다. 이 PDF는 계산이 빠르지만, 타일 내 픽셀이 깊이 범위 전체에 고르게 분포해 있다고 가정한다는 한계가 있으며, 실제로는 그렇지 않을 수 있습니다. 더 정밀한 PDF를 사용하면 저장소 품질을 향상시킬 수 있지만, 현재로서는 이 단순한 PDF만으로도 충분한 결과를 얻고 있습니다.
During SRS we use the same PDF for all the light types. For this we evaluate omni-light scalar illuminance at the nearest point on the line segment. This provides a rough estimate of each light's influence on the tile, and because the PDF is positive everywhere, it doesn't introduce sampling bias. The PDF is fast to evaluate but assumes that the tile pixels are roughly evenly distributed between the tile depth bounds, which may not be true. With more accurate PDF the reservoir quality could be improved, but this simple PDF has been sufficient for us for now.
SRS 구현

SRS를 수행하기 위해, 씬의 조명을 16개의 독립적인 스트림으로 나누고, 각 대타일 저장소 슬롯마다 하나의 스트림을 할당합니다. 그런 다음 각 스트림에 대해 1-샘플 A-Chao 가중 저장소 샘플링을 수행합니다. 이렇게 하면 각 슬롯이 서로 다른 조명 집합에서 샘플링하기 때문에, 저장소 안에 중복 조명이 생기지 않도록 보장할 수 있습니다.
To perform SRS, we divide the lights into 16 separate streams, one for each big-tile reservoir slot and run 1-sample A-Chao Weighted Reservoir Sampling for each stream. This ensures we don't get light duplicates in the reservoir because each slot samples a unique set of lights.
우리는 씬 조명 인덱스가 저장소 슬롯 인덱스와 일치하도록 맞추는 것부터 스트림 순회를 시작합니다. 이렇게 초기 정렬을 해두면, 첫 번째 배치의 조명이 특정 슬롯에 배치되도록 할 수 있어, 소수의 조명만 있는 씬에서 성능과 노이즈 측면에서 유리합니다.
We start the stream iteration with the scene light index matching the reservoir slot index. This initial ordering is done to ensure that first lights are placed in specific slots to optimize performance and to reduce noise in scenes with only few lights.
그 다음 SRS의 다음 반복에서는 다음 16개의 조명 그룹으로 건너뛰고, 이번 반복에 사용할 랜덤 오프셋을 생성한 뒤, 스트림 인덱스에 모듈로 16 오프셋을 더해 스트림을 랜덤하게 섞습니다. 이렇게 스트림을 섞는 이유는, 중요도가 높은 조명들이 여러 대타일과 여러 프레임에서 같은 저장소 슬롯만 두고 경쟁하는 상황을 피하기 위해서입니다.
Then in the next SRS iteration we jump forward to the next group of 16 lights, generate a random offset for the iteration, and offset stream indices with modulo 16 to randomize the streams. This randomization is done to avoid heavy-weight lights competing of the same reservoir slot across big-tiles and frames.
이 과정을 모든 조명을 순회할 때까지 반복합니다. 픽셀 셰이더 구현에서도 각 슬롯의 랜덤 오프셋 시퀀스가 동일하게 나오도록, 대타일 인덱스를 시드로 사용하는 의사난수 생성기를 초기화합니다.
We keep repeating this process until we have iterated through all the lights. To ensure the same random offset sequence for each slot with a pixel shader implementation, we initialize Pseudo Random Number Generator with the seed of the big-tile index.
이 샘플링 패스가 끝나면, 각 대타일 저장소는 타일의 픽셀 풋프린트에 대한 대략적인 영향도에 따라 선택된, 중복 없는 16개의 조명 후보를 가지게 됩니다.
At the end of this sampling pass, each big-tile reservoir has 16 unique and unbiased light candidates picked based on their approximate influence on the big-tile footprint.
여기에는 A-Chao WRS 기반 SRS를 사용한 대타일 슬롯 샘플링 코드 조각이 나와 있습니다. 설명한 랜덤 오프셋 시퀀스를 사용해, 해당 대타일 저장소 슬롯이 참조하는 씬 조명들을 순회합니다. 각 반복에서 조명 PDF를 평가하고, 그 PDF를 이용해 확률적으로 조명을 선택합니다. 반복이 끝나면 선택된 조명과 그 가중치를 저장소에 기록합니다.
Here's a code snippet for the big-tile slot sampling using SRS based on A-Chao WRS. We iterate through scene lights for a big-tile reservoir slot using the described random offset sequence. For each iteration we evaluate the PDF for each light and use the PDF to probabilistically pick the light. Once completed we store the light and its weight to the reservoir.

이 그림은 균일 샘플링과 비교했을 때, 대타일 SRS가 어떻게 노이즈를 줄이는지를 보여줍니다. 왼쪽 이미지는 씬 조명에서 균일하게 샘플링한 16개의 조명을 그대로 사용해 소타일 샘플을 뽑은 경우이고, 오른쪽 이미지는 16개 샘플을 가진 대타일 저장소에서 다시 재샘플링한 경우입니다. 오른쪽이 눈에 띄게 노이즈가 적습니다.
Here's a comparison how the big-tile SRS reduces noise versus uniform sampling. On the left we have an image where we pick small-tile samples from 16 uniformly sampled scene lights. On the right we have an image with lights resampled from the big-tile reservoirs of 16 samples, which has significantly less noise.
소타일 재샘플링


초기 대타일 조명 샘플링 이후에는, 각 대타일 저장소에서 소타일당 1-4개의 조명을 다시 뽑습니다. 이 샘플들이 최종 조명 평가에 사용됩니다. 재샘플링에는 다시 한 번 SRS를 사용해, 소타일 저장소 안에서도 중복 조명이 없도록 합니다. 이 재샘플링 단계는 고정 크기의 대타일 저장소에서만 작업하기 때문에, 씬의 조명 복잡도와 무관하게 비용이 일정합니다.
After the initial big-tile light sampling, we resample 1-4 lights for small-tiles from the big-tile reservoirs. These samples will be used for the final lighting evaluation. For the resampling we'll have another round of Stratified Reservoir Sampling to ensure no light duplicates in small-tile reservoirs. This resampling step is independent of the scene's lighting complexity because the resampling is done from the fixed-size big-tile reservoirs.
각 소타일은 256 픽셀을 커버하며, 재샘플링에 사용할 대타일 저장소는 소타일 중심점이 위치한 곳을 기준으로 선택합니다.
Each small-tile covers 256 pixels, and for resampling we pick a big-tile reservoir based on the location of the small-tile center point.
타일링 아티팩트 제거

하지만 소타일 픽셀을 16×16 픽셀의 규칙적인 격자 형태로만 배치하면, 샘플 상관관계 때문에 그림과 같은 눈에 띄는 타일링 아티팩트가 생깁니다.
However, if we lay out the small-tile pixels in a regular 16x16px grid, it leads to visible tiling artifacts due to sampling correlation as shown in the image.
이런 타일링 아티팩트를 줄이기 위해, 우리는 더 큰 32×32 픽셀 풋프린트 안에서 인접한 4개의 타일이 서로 소타일 픽셀을 교차 배치(interleave) 하도록 했습니다.
To break these tiling artifacts, we interleave the small-tile pixels with 4 neighbor tiles over a larger 32x32px footprint.

구체적으로, 4개의 타일에 대해 총 64개의 2×2 픽셀 쿼드를 분배합니다. 그림에서 빨간색, 초록색, 파란색, 노란색으로 표시된 것이 바로 이 네 타일을 위한 64개 사전 계산 쿼드 샘플 분포입니다. 샘플 분포는 타일 중앙 쪽에 샘플을 조금 더 밀도 있게 배치하되, 같은 타일의 샘플이 서로 바로 인접하지 않도록 하는 가우시안-포아송 분포를 사용합니다. 이렇게 만든 샘플 패턴은 전체 렌더 이미지에 반복 적용됩니다.
Specifically, we distribute 64 2x2px quads for each four tiles. Here we have the 64 precomputed quad sample distributions for the four tiles shown in red, green, blue and yellow. For the sample distribution we use Gaussian-Poisson distribution to concentrate a bit more samples to the tile centers while avoiding placing samples from the same tile right next to each other. These sampling patterns are then repeated over the entire rendered image.

이러한 교차 샘플링 패턴 덕분에 소타일 수준의 타일링 아티팩트는 많이 줄어듭니다. 다만, 소타일 중심점을 기준으로 대타일 저장소를 선택하는 방식 때문에, 여전히 대타일 크기의 큰 네모 모양 조명 아티팩트는 남아 있습니다.
This interleaved sampling pattern reduces the small-tile tiling artifacts. However, we can still see square big-tile lighting artifacts, because the big-tile reservoirs are point sampled at the small-tile centers.
이를 해결하기 위해, 우리는 대타일을 단순히 한 점에서 샘플링하는 대신, 인접한 대타일들 사이를 랜덤하게 쌍선형 필터링(stochastic bilinear filtering) 하도록 만들었습니다. 구체적으로는, 재샘플링에 사용할 대타일을 고를 때 소타일 중심점을 무작위로 약간씩 이동시키는 방식입니다. 그 결과 대타일 경계 사이가 부드럽게 연결되면서 타일링 아티팩트가 사라집니다. 여전히 교차 배치된 소타일들이 약간 보이긴 하지만, 이제 이미지는 시공간 디노이징에 훨씬 더 적합한 형태가 됩니다.
To fix this, instead of point sampling the big-tiles, we use stochastic bilinear filtering between neighboring big-tiles. We implement this by randomly offsetting small-tile centers when selecting the big-tile for resampling. The result is a smoother transition between big-tiles and eliminates the tiling artifact. We can still see some interleaved small-tiles, but this image is now much better suited for spatiotemporal denoising.
정교한 PDF

소타일 재샘플링 단계에서는, 각 조명이 해당 타일에 미치는 중요도를 더 잘 추정할 수 있는 정교한 PDF를 사용합니다. 우리는 64개의 샘플 중에서 무작위로 4개의 소타일 쿼드 샘플 점을 골라 랜덤 PDF 평가(stochastic PDF evaluation) 를 수행합니다. 그런 다음, 각 점에서 조명의 그림자 조도와 BRDF를 사용해 반사 휘도를 평균합니다.
For the small-tile resampling we use a more refined PDF that better estimates light's importance to the tile. We use stochastic PDF evaluation by picking 4 random small-tile quad sample points out of the 64. Then average reflected luminance at the points using light's shadowed illuminance and a BRDF.
PDF는 표준 시감도 함수(standard luminous efficiency)로 가중된 조도와 BRDF 함수의 곱으로 계산합니다. 이것은 재질과 조명이 단색(monochromatic)이라고 가정하는 셈입니다. 더 바람직한 방법은 RGB 조도와 BRDF 곱을 구한 뒤에 가중치를 적용해, 예를 들어 빨간 조명이 파란 표면을 비추는 경우 PDF가 더 낮게 나오도록 하는 것입니다. 하지만 우리는 성능을 위해 이를 생략했고, 그 대가로 어느 정도의 추가 노이즈를 허용했습니다.
We calculate the product of the standard luminous-efficiency weighted light illuminance and BRDF functions for the PDF, which means that materials and lights are assumed to be monochromatic. It would be better to perform the weighting after the RGB illuminance and BRDF product so that for example a red light illuminating a blue surface would result in lower PDF, but we compromise currently for performance at the expense of some added noise.

이 그림은 그림자 항이 노이즈에 어떤 영향을 미치는지 보여줍니다. 어떤 타일이 특정 조명에 대해 완전히 그림자 속에 있거나, 타일 내 모든 표면 법선이 조명으로부터 등을 돌리고 있다면, 우리는 그 조명을 조명 평가 대상으로 선택하지 않습니다. 이로 인해 노이즈가 줄어듭니다.
Here's an example image showing how the shadow term influences noise. If a tile is completely shadowed or all its surface normals point away from the light we don't pick the light for the lighting evaluation, which reduces noise.
처음에는 PDF 계산에 Lambert BRDF를 사용했지만, 거울반사 노이즈를 줄이기 위해 이를 스펙룰러 BRDF로 교체했습니다. 최종 Lambert + GGX BRDF의 노이즈를 줄이기 위한 PDF 근사로는 Lambert + Blinn-Phong 조합이 충분히 좋으면서도 더 저렴하다는 것을 확인했습니다. 현재 우리는 하나의 조명 BRDF만 지원하지만, 여러 BRDF에 대해 서로 다른 PDF 근사를 구현하면 노이즈를 더 잘 최적화할 수 있을 것입니다.
Initially we used Lambert BRDF for the PDF but replaced it with a specular BRDF to reduce specular noise. We found that Lambert + Blinn-Phong is good enough but cheaper approximation for the PDF to reduce noise of the final Lambert + GGX BRDF. Also worth noting that we support currently only one lit BRDF, and it might be good to implement different PDF approximations for multiple BRDFs to optimize noise.
ALU 사용량과 VGPR 압박을 줄이기 위해, 우리는 먼저 타일 샘플 점에서 시감도 가중 재질 파라미터를 평균한 뒤, 이 평균값을 각 점의 반사 휘도 계산에 재사용합니다.
To reduce the ALU usage and VGPR pressure, we also first average luminous-efficiency weighted material parameters at the tile sample points and then use the same parameters in reflected luminance calculation of the points.
무편향성(unbiasedness) 고려

이상적으로는, 타일의 반사 휘도가 0이 아닌 곳에서는 PDF도 0이 아니도록 해서 재샘플링이 무편향성을 유지해야 합니다. 하지만 실제 구현에서는 이 조건을 완전히 만족하지 못합니다. 예를 들어, 타일 내 일부 픽셀은 빛을 받더라도, 운이 나쁘게도 선택된 4개의 PDF 샘플 점이 모두 그림자 영역 안에 들어갈 수 있습니다. 이렇게 되면 빨간 화살표로 표시된 영역처럼 조명 경계에 편향된 노이즈가 생깁니다. 아래의 TAA 이미지를 보면, 이 편향된 노이즈가 해당 영역을 약간 어둡게 만드는 형태로 나타납니다.
Ideally, our resampling stays unbiased by ensuring the PDF is non‑zero everywhere the tile's reflected luminance is non‑zero. In practice we don't fully meet that requirement: For example, it's possible that all the four PDF sample points fall in shadow even though some tile pixels are lit. This adds a biased lighting edge noise as shown in the areas highlighted with the red arrows. In the TAA image at the bottom this biased noise shows as slight darkening in the area.
편향은 단순한 조명 환경에서 특히 두드러지며, 이를 완화하기 위해 우리는 그림자 코사인 항에 아주 작은 오프셋을 더한 뒤 PDF에 곱해 주었습니다. 디노이저를 통과하면 이 편향은 대부분 사라지고 눈에 띄지 않게 됩니다.
The bias is most obvious in simply lit areas and to mitigate the issue, we add a small offset to the shadowed cosine term, before it's multiplied into the PDF. After denoising the bias is mostly gone and unnoticeable.
재샘플링 구현

소타일 재샘플링에도 대타일 패스와 같은 SRS 전략을 적용합니다. 소타일 저장소에 N개의 조명 샘플을 저장한다고 할 때, 16개의 대타일 후보 샘플을 N개의 독립 스트림으로 나눕니다. 스트림 분할 덕분에, 재샘플링 비용은 N과 무관하게 일정하게 유지됩니다. 패스의 총 비용에는 대타일 저장소 크기와 소타일 PDF 평가 비용만 영향을 미칩니다.
For the small-tile resampling we apply the same SRS-strategy as in the big-tile pass. For the small-tile reservoir of N light samples, we split the 16 big-tile sample candidates into N independent streams. The resampling cost is independent of N, because of the stream splitting. Only the big-tile reservoir size and the small-tile PDF cost influences the total cost of the pass.
대타일 SRS와 마찬가지로, 먼저 대타일 저장소에서 앞의 N개 샘플을 스트림의 초기값으로 선택합니다. 이 예에서는 N=4입니다. 다음 반복에서는 랜덤 오프셋을 사용해 다음 4개의 조명 샘플 배치를 스트림 간에 섞어 줍니다. 이렇게 하면 중요도가 높은 조명들이 주변 소타일들의 동일한 저장소 슬롯만 두고 경쟁할 확률이 줄어듭니다. 이 과정을 대타일 저장소의 16개 샘플을 모두 처리할 때까지 반복합니다. 재샘플링 단계가 끝나면, 최종 조명 평가에 사용할 4개의 서로 다른 고품질 조명 샘플을 얻게 됩니다.
Like with the big-tile SRS, we start by picking the first N samples from the big-tile reservoir for the streams. In this example we use N=4. For the next iteration we shuffle the next batch of 4 light samples across the streams with a random offset, to reduce the likelihood of high-importance lights competing of the same reservoir slots for nearby small-tiles. We then repeat this process until all the 16 big-tile samples have been processed. At the end of the resampling stage, we have 4 unique high-quality light samples that will be used for the lighting evaluation.

소타일 저장소는 픽셀 셰이더에서 1-4 채널 렌더 타깃으로 내보내며, 대타일 저장소와 같은 32비트 포맷을 사용합니다. 저장소 안에 4개보다 많은 샘플을 둘 수도 있지만, 성능과 하나의 렌더 타깃에 담기도록 하기 위해 최대 4개로 제한했습니다. 1080p 기준으로는 120×68 픽셀 크기의 렌더 타깃이 필요하며, 저장소 크기에 따라 약 32KB에서 128KB 정도의 메모리를 사용합니다.
The small-tile reservoir is exported from the pixel shader to a 1-4 channel render target, using the same 32bit format as for the big-tile reservoirs. It's possible to have more than 4 samples in the reservoir, but we max at 4 for performance and to fit the reservoir into one render target. For 1080p this requires 120x68px render target, or from 32KB to 128KB of memory depending on the reservoir size.
여기에는 SRS를 이용해 소타일 슬롯을 재샘플링하는 코드 조각이 나와 있습니다. 설명한 대로, 해당 슬롯에 대해 대타일 저장소 샘플을 순회합니다. 각 반복에서 조명 PDF를 계산하고, 대타일 샘플링이 유발한 편향을 제거하기 위한 재샘플링 PDF를 구합니다. 이 재샘플링 PDF를 이용해 조명을 확률적으로 선택한 뒤, 반복이 끝나면 선택된 조명과 그 가중치를 저장소에 기록합니다.
Here's a code snippet for the small-tile slot resampling with SRS. We iterate through the big-tile reservoir samples for the slot as described. For each iteration we evaluate the light PDF and calculate resampling PDF that unbiases the big-tile sampling bias. This resampling PDF is then used to probabilistically pick the light. Once completed we store the light and its weight to the reservoir.
그림자 평가

지연 그림자 패스

소타일 재샘플링 이후에는 선택된 조명 샘플에 대한 그림자 항을 평가합니다. 이 단계는 최종 조명 평가와 분리된 별도의 픽셀 셰이더 패스에서 수행됩니다. 이렇게 분리하면, 성능을 위해 그림자 평가를 더 낮은 해상도로 수행할 수 있습니다. 구체적으로, 우리는 픽셀마다가 아니라 2×2 픽셀 소타일 쿼드마다 한 번씩만 그림자를 평가합니다.
After the small-tile resampling, we evaluate the shadow terms for the light samples. We perform this in a separate pixel shader pass, decoupled from the final lighting evaluation. This enables us to evaluate shadows at a lower resolution for better performance. Specifically, we evaluate shadows once per 2x2px small-tile quad instead of per pixel.
이렇게 하면 그림자 평가 횟수가 1/4로 줄어들어 성능이 좋아질 뿐 아니라, 조명 셰이더 자체도 단순해집니다. 조명 타입별 그림자 샘플링 코드를 셰이더 밖으로 분리했기 때문에, 파동 다이버전스와 데이터 접근량, VGPR 압박이 모두 줄어듭니다.
This not only improves shadow evaluation performance by cutting the evaluations to one quarter, but also simplifies the lighting shader. The wave divergence, data access and VGPR pressure is reduced because the light type specific shadow sampling is kept out of the shader.
알고리즘이 완전히 픽셀 셰이더로 구현되어 있기 때문에, 그림자 항은 소타일의 64개 쿼드 샘플에 대응하는 8×8 픽셀 블록으로 저장됩니다. 이는 GPU가 일반적으로 픽셀 셰이딩을 파동 단위로 묶는 방식과 잘 맞아떨어져, 파동 다이버전스를 줄이는 데 도움이 됩니다. 그림자 평가 코드는 스포트라이트와 전방위 조명에 대해서는 대부분 공통이며, 태양광은 캐스케이드 그림자 맵을 사용하는 별도의 경로를 사용합니다.
Since the algorithm is implemented entirely in pixel shaders, shadow terms are stored in 8×8 pixel blocks, corresponding to the 64 quad samples of a small-tile. This organization reduces wave divergences because of how GPUs generally pack pixel shading to waves. The shadow evaluation code is largely unified for spot and omni lights, but sunlight uses cascaded shadow maps with a separate path.
메모리 사용량과 대역폭을 줄이기 위해, 우리는 8비트짜리 그림자 항만 사용하고, 여기에 1비트짜리 시간 축 랜덤 노이즈를 더해 TAA에서 밴딩이 생기지 않도록 했습니다. 1080p 기준으로 약 0.5MB에서 2MB 정도의 메모리가 필요합니다.
To reduce memory usage and bandwidth, we use only 8bit shadow terms and add 1bit of temporal noise to eliminate banding with TAA. For 1080p this uses from 0.5MB to 2MB of memory.
또한 지연 그림자 패스를 사용하면, 최종 조명 셰이더의 성능에 영향을 주지 않고도, 그림자 평가를 그림자 맵 외에 레이 트레이싱 같은 다른 방식으로 구현할 수 있습니다.
The deferred shadow pass also enables the shadow evaluation to be implemented using different techniques, such as shadow maps or ray-tracing, without influencing the final lighting shader performance.
그림자 맵 구현

우리의 타깃 플랫폼 특성상, 현재 그림자 평가는 그림자 맵 기반으로 구현되어 있으며, 16bpp 포맷의 지속적인(dynamic-managed) 그림자 맵 아틀라스에 저장됩니다. 이 아틀라스에는 스포트라이트와 전방위 조명의 그림자 맵이 모두 들어 있으며, 정사각형이고 크기는 2의 거듭제곱입니다. 스포트라이트는 표준 투영 그림자 맵을 사용하고, 전방위 조명은 옥타헤드럴(octahedral) 매핑된 그림자 맵을 사용합니다. 또한 조명이 카메라에서 얼마나 떨어져 있는지에 따라 그림자 맵 해상도를 조절해, 제한된 아틀라스 용량 안에서 그림자 품질을 균형 있게 유지합니다.
Because of our target platforms, currently we use shadow maps for shadow evaluation, stored in a persistent, dynamically managed 16bpp atlas. The atlas contains both spot and omni shadow maps, which are square and power-of-two in size. For spotlights, we use standard projected shadow maps, while for omni lights we use octahedral-mapped shadow maps. We also resize the shadow maps based on lights distance from the camera, to balance the shadow quality with the limited atlas storage.
조명의 그림자 맵을 업데이트할 때는, 먼저 그 조명의 범위 안에 있는 지오메트리를 임시 깊이 버퍼에 렌더링한 뒤, 그 데이터를 아틀라스로 복사합니다. 스포트라이트의 경우, 조명 시점에서 일반 깊이 버퍼를 렌더링하고, 복사할 때 깊이를 선형화하고 바이어스를 적용합니다. 전방위 조명의 경우, 깊이 버퍼에 큐브맵을 렌더링한 뒤, 복사 과정에서 깊이 선형화와 바이어스에 더해 큐브맵 면들을 옥타헤드럴 공간으로 매핑합니다. 두 경우 모두 PCF 필터링을 위해 복사 시 2픽셀짜리 보더를 추가합니다.
When updating a shadow map for a light, we first render geometry within the light's range to a temp depth buffer, and then copy the data into the atlas. For spotlights, we render a regular depth buffer from the light's point of view. Then upon the copy we linearize and bias the depth values. For omni lights, we render a cubemap to the depth buffer and during the copy, we map the cube faces to octahedral space in addition to depth linearization and biasing. We also add 2px border upon both copies to support PCF filtering.
우리는 정적(static) 그림자 맵과 동적(dynamic) 그림자 맵을 모두 지원합니다. 정적 맵은 조명의 변환이나 그림자 해상도가 바뀔 때에만 업데이트되며, 정적 지오메트리만 포함하고, 장식용 조명에 주로 사용합니다. 동적 맵은 정적 + 동적 지오메트리를 모두 포함하며 계속해서 업데이트되기 때문에 더 비용이 큽니다. 많은 그림자 맵이 동시에 업데이트되어 성능 스파이크가 일어나는 것을 막기 위해, 우선순위 큐를 사용한 로드 밸런싱 시스템으로 그림자 맵 렌더링을 여러 프레임에 걸쳐 분배합니다.
We support both static and dynamic shadow maps. Static maps are updated only when light's transform or shadow resolution changes. Static maps include only static geometry and are meant for decorative lighting. Dynamic maps are more expensive because they are constantly updated, and include both static and dynamic geometry. To avoid performance spikes when many shadow maps require updates, we load balance the updates with a priority queue system to spread the shadow map rendering across multiple frames.
그림자 필터링

그림자 필터링에는 4탭 "하드웨어" PCF에 랜덤 PCF를 더해, 보다 부드럽고 자연스러운 그림자를 구현합니다. 그림자 항 하나를 평가하는 데 그림자 맵에서 필요한 gather 연산은 1회뿐입니다. 이 단계에서 선택된 IES 조명 프로파일과 스포트라이트의 각도 감쇠도 그림자 항에 곱해 줘, 조명별 모양 감쇠를 구현합니다. 또한 소타일 PDF 평가 시에도 IES 프로파일을 반영해 노이즈를 줄입니다.
For shadow filtering, we use 4-tap "hardware" PCF with stochastic PCF to produce softer, more natural-looking shadows. This requires only 1 gather operation from the shadow map per shadow term evaluation. At this stage, we apply also selected IES light profile and angular spot falloff to the shadow term, allowing light-specific shape falloff. We apply IES profiles also during small-tile PDF evaluation to reduce noise.
향후에는 PCSS를 사용한 접촉 경화 그림자(contact hardening shadows), 화면 공간 레이마칭 디테일 그림자, 레이트레이싱 그림자 등을 도입해 그림자 품질을 더 끌어올릴 계획이며, 이런 기능은 고급형 기기에서 옵션으로 켤 수 있을 것입니다.
We plan to improve shadow quality further with PCSS for contact hardening shadows, screen-space ray-marched detail shadows, and ray-traced shadows, which can be enabled on higher-end devices.
저해상도 그림자의 트레이드오프

2×2 픽셀 쿼드가 하나의 그림자 항을 공유하는 방식은 대부분의 경우 잘 동작하지만, 쿼드 안의 픽셀마다 그림자 값이 상당히 달라져야 하는 물체 실루엣에서는 아티팩트를 유발할 수 있습니다. 다만 랜덤 타일 샘플링과 TAA 덕분에 이 문제는 대부분 완화됩니다. 경계에서 약간의 조명 편향이 생길 수는 있지만, 아티팩트는 비교적 미미한 수준입니다. 필요하다면 추가 비용을 들여 전 해상도 그림자 평가로 되돌아가 품질을 높일 수도 있습니다.
Sharing one shadow term per 2x2px quad works well in most cases, but it can introduce artifacts at object silhouettes where quad pixels should have quite different shadow term values. However, randomized tile sampling and TAA mostly mitigates this issue. While it can still introduce subtle lighting bias at the edges, the artifacts are quite minor. If necessary, we can also fall back to full-resolution shadow evaluation to improve the quality at an additional cost.
조명 평가

조명 평가 단계에서는 먼저 해당 픽셀에 맞는 소타일 조명 샘플과 그림자 항을 가져옵니다. 이 단계도 픽셀 셰이더로 실행하고 싶기 때문에, 스크린 픽셀이 어느 소타일과 어느 샘플 인덱스에 대응하는지 역으로 찾을 방법이 필요합니다. 이를 위해 16×16 픽셀 크기의 역 LUT를 사용해, 스크린 공간 쿼드 좌표를 교차 배치된 타일 및 샘플 인덱스로 매핑합니다. 이 정보를 이용해 각 픽셀에 대해 조명 샘플과 그림자 항을 읽어올 수 있습니다.
In the lighting evaluation stage, we first fetch small-tile light samples and shadow terms for the pixel. Since we want this stage to also run in a pixel shader, we need a way to map screen pixels back to small-tile and sample indices. To achieve this, we use a 16x16px inverse LUT, that links screen-space quad coordinates to the interleaved tile and sample indices. With this information, we can then fetch both the light samples and shadow terms for each pixel.
컴퓨트 셰이더로 구현한다면, 이런 역 매핑이 필요 없습니다. 그 대신 해당 타일의 픽셀들에 대해 직접 조명 샘플을 평가하고, 산출된 조명 값을 스캐터 쓰기로 조명 버퍼에 기록하면 됩니다.
With compute shaders the inverse mapping isn't necessary, and we could directly evaluate the light samples for the tile pixels and write the lighting result to the lighting buffer with scattered writes.
마지막으로 각 조명 샘플에 대해 Lambert + GGX BRDF 기여도를 계산하고, 샘플 가중치와 그림자 항을 모두 곱해 누적한 뒤, 결과를 조명 버퍼에 기록합니다. 우리가 타일마다 1-4개의 고정된 조명 샘플만 저장하기 때문에, 이 패스의 비용 또한 씬의 조명 복잡도와 무관하게 일정하게 유지됩니다. 그림자 평가를 분리해 두었기 때문에, 조명 타입 간 구현 차이도 줄어들어 픽셀 셰이더에서의 분기 다이버전스가 감소합니다. 컴퓨트 셰이더를 사용할 경우에는, 파동에 묶인 타일 픽셀에 대해 보다 연속적인 조명 평가를 수행할 수 있어 다이버전스를 한 번 더 줄일 수 있습니다.
Finally, we accumulate the Lambert + GGX BRDF contribution for each light sample, weighted by both the sample weight and its shadow term, and write the result to the lighting buffer. Because we store a fixed 1 to 4 light samples per tile, this pass has also a fixed cost independent of the scene lighting complexity. The lighting evaluation is also quite unified across all our light types because of the decoupled shadow evaluation, which reduces the divergence with the pixel shader implementation. With compute shaders we could have coherent lighting evaluation of tile pixels packed to waves, further reducing the divergence.
디노이징
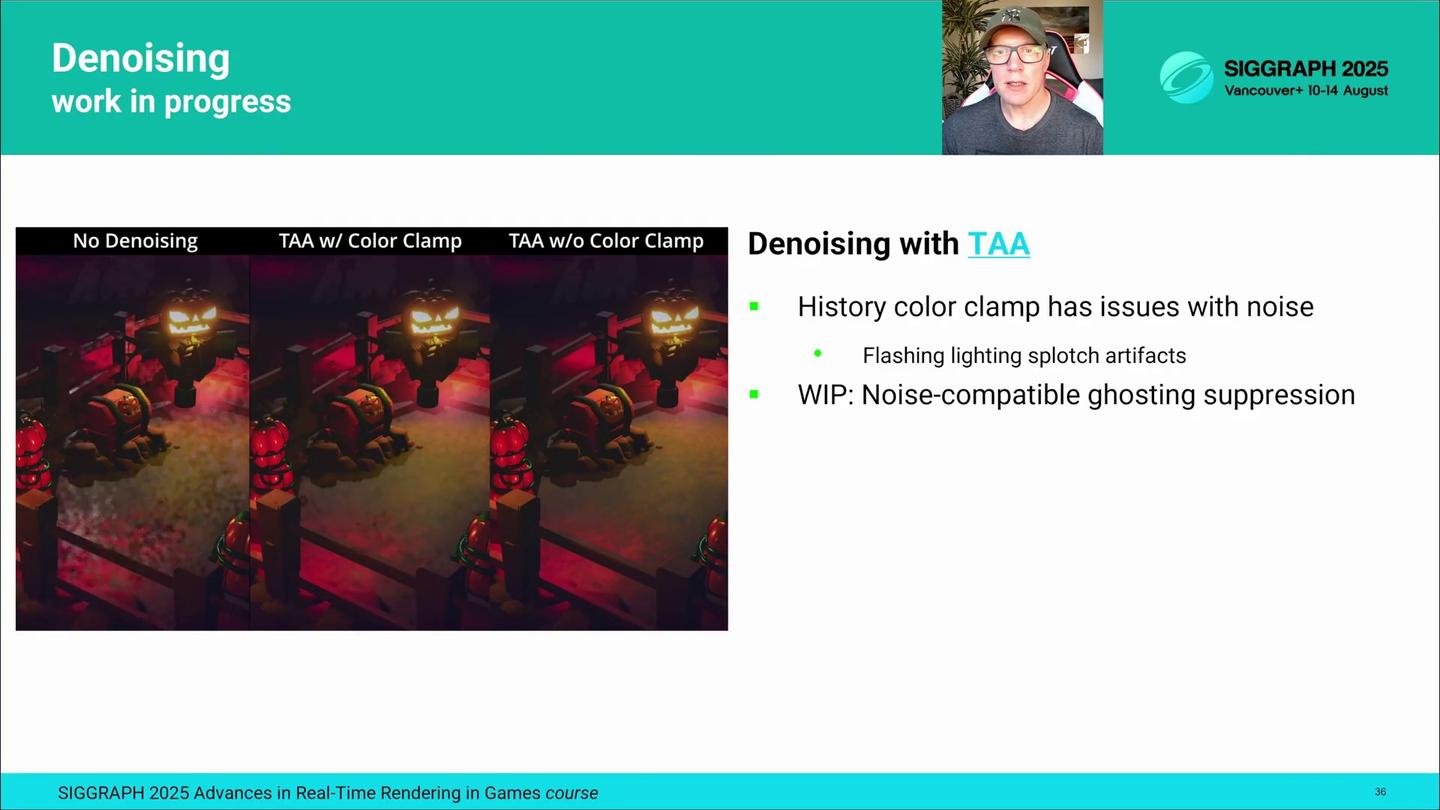
디노이징 비용을 낮게 유지하기 위해, 우리는 별도의 디노이저 패스를 추가해 대역폭을 더 쓰는 대신, 기존의 TAA를 개선해 곧바로 디노이저 역할을 하도록 만드는 것을 목표로 하고 있습니다. 하지만 표준 TAA에서는 고스팅을 줄이기 위해 3×3 픽셀 이웃의 히스토리 색을 클램핑하는 과정이 있는데, 우리처럼 입력이 노이즈가 심한 경우에는 이것이 큰 문제가 됩니다. 주변 픽셀 이웃이 어떤 프레임에서는 핵심 조명을 전혀 렌더링하지 않을 수 있기 때문에, 색 범위가 너무 좁게 제한되어 가운데 보이는 것처럼 번쩍이는 조명 얼룩이 생깁니다.
To keep the denoising cost low, we are planning to improve temporal anti-aliasing to work as our denoiser and avoid the need for a separate denoising pass, which would consume more bandwidth. However, the main challenge with the standard TAA is the 3x3px neighborhood history color clamping designed to reduce ghosting. In our case, this causes flashing lighting splotches shown in the middle, because the pixel neigborhoods may not render key lights for a frame, limiting the color range.
따라서 우리는 색 클램핑을 노이즈 있는 입력과 더 잘 맞도록 바꾸거나, 다른 형태의 고스팅 억제 기법을 찾거나, 혹은 TAA에 더 적합한 입력 데이터를 제공하는 방식이 필요합니다. 현실적인 해법은 이 접근법들을 적절히 조합하는 것일 것입니다. 이 부분은 아직도 활발히 연구 개발 중입니다.
So, we need to either make the color clamping more compatible with the noisy input, find alternative ghosting suppression techniques, or provide input data that better suits TAA, or with a combination of these approaches. This is still an active area of R&D for us.
시각적 결과
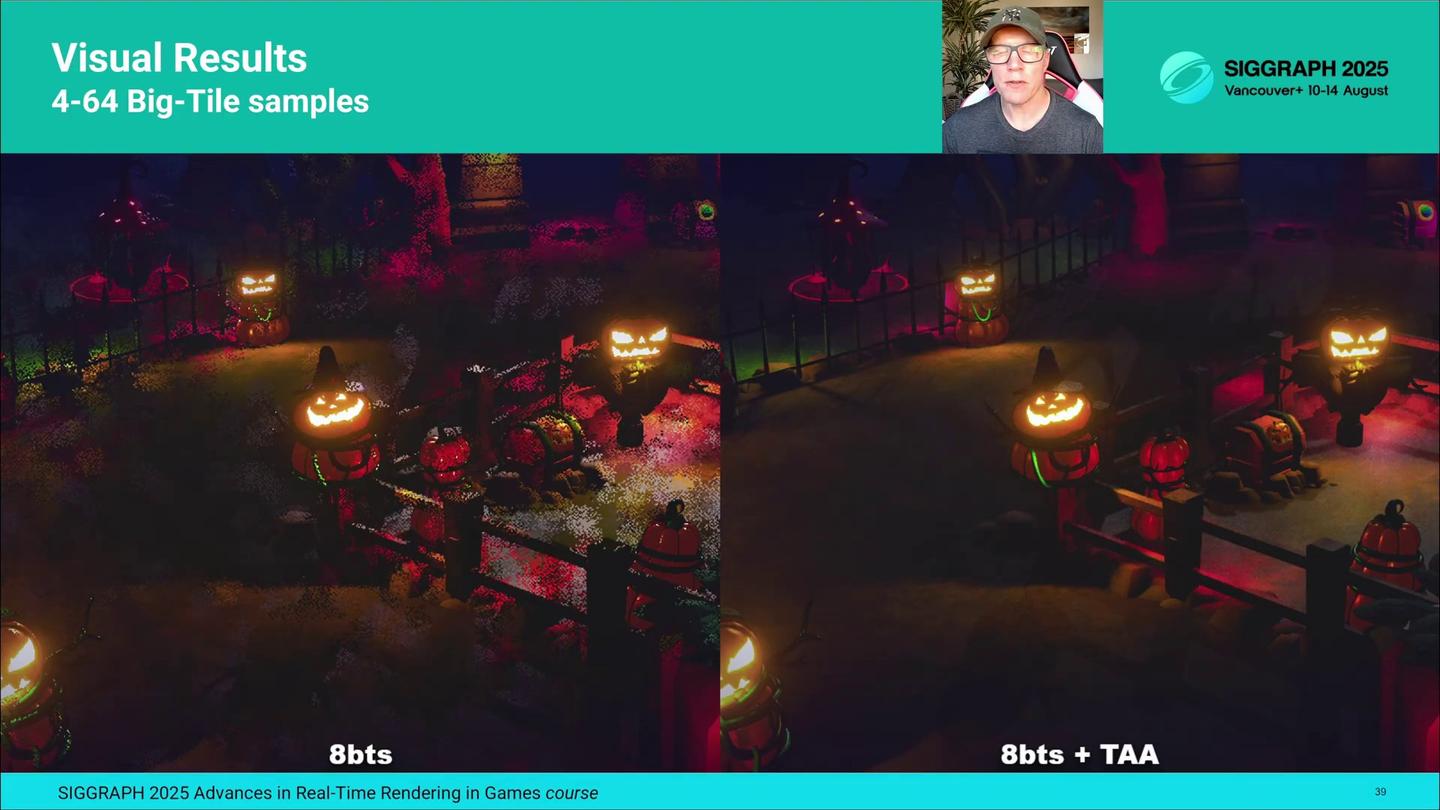
먼저 픽셀당 1샘플과 4샘플인 경우의 조명 결과를 비교해 보겠습니다. 왼쪽의 노이즈 이미지를 보면, 예상대로 1spp 결과가 4spp보다 훨씬 노이즈가 많습니다. 오른쪽의 TAA 이미지를 보면, 4spp 결과가 디테일한 지오메트리에서 더 선명한 거울반사 같은 세밀한 조명 디테일을 재현해 주는 것도 볼 수 있습니다. 다만 전반적으로 두 경우 모두 비슷하고 충분히 수용 가능한 결과로 수렴합니다.
For visual results, here is a comparison between 1 and 4 samples-per-pixel lighting. In the noisy image on the left, the 1spp image has more noise, as expected. In the TAA image on the right, we can also see that the 4spp result is able to reproduce some of the finer lighting details, like sharp specular reflections in detailed geometry. Both converge to quite similar and acceptable results though without major differences.
다음은 대타일 저장소 크기가 조명 결과에 어떤 영향을 미치는지 보여주는 비교입니다. 대타일 샘플 수를 줄이면, 특히 먼 거리에서 씬이 더 어두워지는 경향을 보입니다. 이는 파이어플라이를 줄이기 위해 조명 가중치에 상한을 두면서 생긴 조명 편향 때문입니다. 그 외에는 대타일 저장소 크기를 늘리면 노이즈가 줄어들고, 소타일 재샘플링이 더 풍부한 후보 집합에서 관련성이 높은 조명을 선택할 수 있게 되어 조명 디테일이 개선됩니다.
Here's a visual comparison how big-tile reservoir size influences the lighting results. Decreasing the number of big-tile samples darkens the scene, especially in the distance. The darkening is lighting bias caused by capping the light weights to reduce fireflies. Otherwise, increasing the big-tile reservoir reduces noise and improves lighting details because the small-tile resampling can pull more relevant light samples from a richer set.
성능 분석

성능 분석에는 다음과 같은 하드웨어 구성을 사용했습니다. 가장 약한 안드로이드 타깃 폰 중 하나, 고급형 안드로이드 폰, 그리고 더 강력한 하이엔드 노트북을 아우르도록 선택했습니다. Adreno 610은 오늘날 99달러대 보급형 스마트폰에서 볼 수 있으며, ALU 성능과 메모리 대역폭이 대략 Xbox 360, PS3와 비슷하지만 전력 소모는 3W 수준입니다. Adreno 830은 약 1000달러대 스마트폰에서 볼 수 있고, 대략 10년 전 콘솔 및 데스크톱 GPU에 해당하는 성능을 5W 안팎에서 제공합니다. 또한 약한 기기에서는 렌더링 해상도를 더 낮게 설정했습니다.
For the performance profiling, we are using the following hardware setup. It covers one of our weakest Android target phones, a high-end Android phone and a more powerful high-end laptop. Adreno 610 is found in phones and matches around 10 year old consoles and desktop GPUs, but runs at 5W. We also use lower rendering resolutions on weaker devices.

먼저, 기존의 태양광만 사용하는 조명과 랜덤 타일 기반 조명을 시각적으로 동일한 조건에서 비교해 보았습니다. 태양광 전용 조명은 어떤 종류의 조명 분류도 없이, 픽셀마다 그림자가 있는 태양광을 한 번 평가하는 아주 단순한 방식입니다. 시각적으로 둘은 거의 동일해 보입니다. 가장 큰 차이는 STB 조명은 태양광 그림자를 픽셀 단위가 아니라 2×2 픽셀 쿼드 단위로 평가하기 때문에, 그림자가 약간 더 부드럽게 느껴진다는 점입니다.
First, we'll have an apples-to-apples visual test, comparing our old sun-only lighting with the Stochastic Tile-Based lighting. Sun-only lighting simply evaluates shadowed sunlight for every pixel without any kind of light classification. Visually, the sun-only lighting and our STB lighting look almost identical. The main difference is that STB lighting evaluates sun shadows for 2x2px quads instead of pixels, so they appear slightly softer.
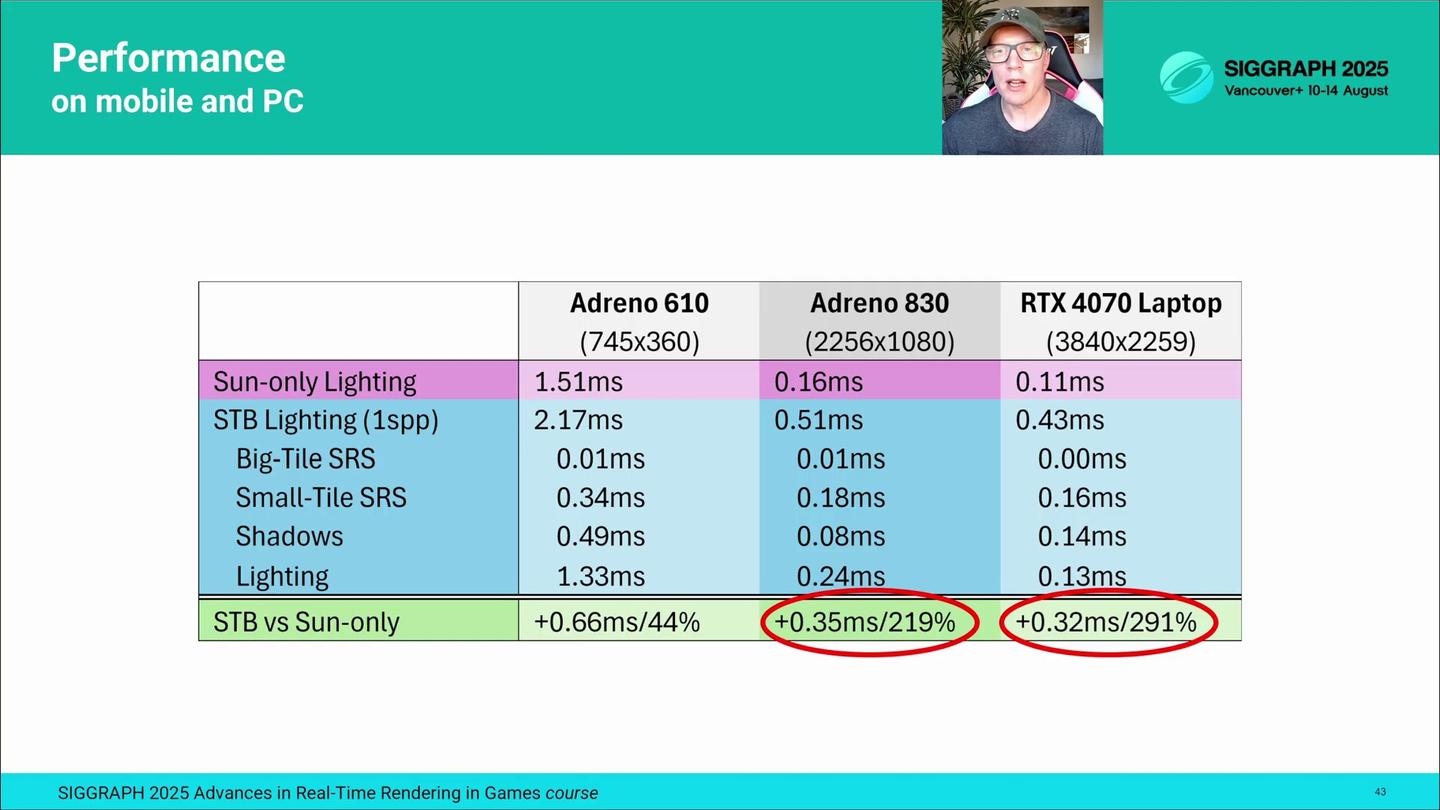
우리의 조명 패스는 실제로는 스펙룰러/디퓨즈 IBL, SSAO 업샘플링 등도 함께 평가하지만, 여기서 제시하는 숫자는 직접 조명 비용만 포함하고 있습니다. 1spp 랜덤 조명을 사용할 때, Adreno 610에서의 추가 비용은 0.66ms 정도이며, 이제 임의의 로컬 조명까지 처리한다는 점을 감안하면 꽤 적당한 수준입니다. Adreno 830과 RTX 4070에서는 약 0.35ms 정도 증가하지만, 상대적인 비용 증가는 더 큰 편입니다. 이런 플랫폼들은 컴퓨트 셰이더 구현과 패스 병합을 통해 그 격차를 줄일 여지가 있습니다.
Our lighting passes evaluate also specular and diffuse IBL, SSAO upscaling, and so forth, but these numbers include only the direct lighting cost. With 1spp stochastic lighting, the cost on the Adreno 610 increases only by 0.66ms, which is quite modest given it now also handles arbitrary local lights. On Adreno 830 and RTX 4070 the cost increase is around 0.35ms, but the relative cost increase is higher. These platforms could potentially benefit from the compute shader implementations and merging passes to bridge the gap.
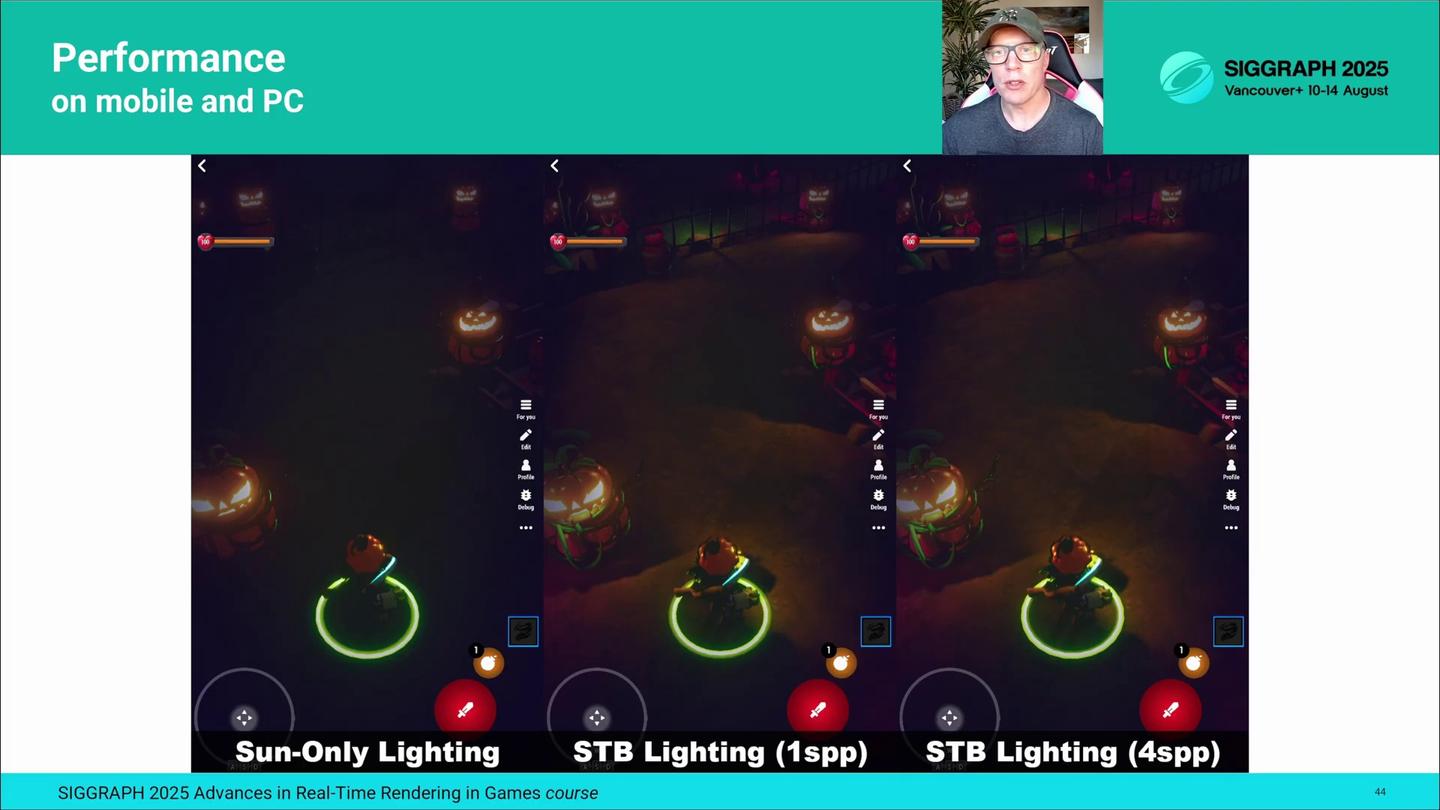
또한 카메라 시야 안에 50개의 로컬 조명이 있을 때, 픽셀당 샘플 수에 따라 STB 조명 성능이 어떻게 스케일링되는지, 그리고 이것이 태양광 전용 조명 성능과 어떻게 비교되는지도 살펴보았습니다. 왼쪽의 태양광 전용 조명은 아주 희미한 달빛만 렌더링하기 때문에, 시각적으로는 당연히 차이가 있습니다.
We also profiled how the STB lighting performance scales with samples-per-pixel with 50 local lights in camera FoV, and how it compares to the sun-only lighting performance. The sun-only lighting on the left differs visually of course because it renders only the faint directional moonlight.

이 장면에서는 태양광 전용 조명이 약간 더 비싸지만, 1spp STB 조명은 보급형 폰에서 약 1.5ms, 고급형 폰과 노트북에서는 약 0.5ms 정도의 추가 비용을 더합니다.
In this scene the sun-only lighting is a bit more costly, but 1spp adds an extra 1.5ms on budget phone and around 0.5ms on the high-end phone and the laptop.
눈여겨볼 점은, 이 장면에서는 소타일 SRS 패스 비용이 이전 장면에 비해 보급형 폰에서 3배 가까이 증가했다는 것입니다. 이는 전체 대타일 저장소를 대상으로 재샘플링을 수행해야 하기 때문입니다. 비용을 줄이는 가장 간단한 방법은 대타일 저장소 크기를 줄이는 것이지만, 그만큼 노이즈가 늘어나는 대가를 치러야 합니다. 4spp 조명은 보급형 폰에서는 꽤 비싸지만, 고급형 폰과 노트북에서는 특히 해당 해상도 조건에서 어느 정도 수용 가능한 수준입니다.
Notably the Small-Tile SRS pass is now 3x as expensive as in the previous scene on the budget phone because it needs to resample from the full big-tile reservoirs. An easy way to reduce the cost would be to reduce big-tile reservoir size, at the cost of some added noise. 4spp lighting gets quite expensive on the budget phone but is more reasonable on the high-end phone and the laptop, especially at those resolutions.
대타일 SRS 패스 비용은 여전히 아주 작지만, 조명 수가 훨씬 많아져 문제가 된다면 균일 샘플링으로 바꿔 비용을 완전히 고정시킬 수도 있습니다. 별도의 500개 조명 씬에서 테스트해 본 결과, 대타일 샘플링 비용은 모든 플랫폼에서 여전히 0.02ms 수준에 불과했습니다.
The cost of big-tile SRS pass is still tiny, but could be improved to fixed cost with uniform sampling if it becomes an issue with larger light counts. I tested the performance in a separate scene with 500 lights and the Big-Tile sampling cost was still only 0.02ms on all the platforms.
정리 및 향후 과제

우리는 조명 샘플링을 픽셀 단위에서 타일 단위로 옮겨, 대역폭과 다이버전스를 크게 줄이면서도 복잡한 완전 동적 조명을 보급형 모바일 폰까지 포함한 다양한 기기에서 현실적인 선택지로 만들어 주는 새로운 랜덤 조명 알고리즘을 제안했습니다. 개발은 아직 진행 중이지만, 품질과 성능 면에서 모두 고무적인 결과를 얻고 있으며 앞으로도 계속 개선해 나갈 계획입니다. 향후 작업 계획 중 몇 가지는 다음과 같습니다.
We presented a new stochastic lighting algorithm that moved light sampling from per-pixel to per-tile, drastically cutting bandwidth and divergence, and making fully dynamic complex lighting a viable option even on budget mobile phones. The development is still work in progress, but the results are encouraging for both quality and performance that we plan to keep improving in the future. Some of our future work includes:
컴퓨트 셰이더 구현
현재 픽셀 셰이더 기반 패스에 대해 컴퓨트 셰이더 버전을 구현하고, 다양한 기기에서 성능을 분석할 계획입니다. 모바일에서도 효과를 볼 수 있는 ALU 및 대역폭 최적화 여지가 많습니다. 컴퓨트 셰이더를 사용하면 소타일 재샘플링, 그림자, 조명 등 마지막 세 패스를 하나로 합쳐 PC·콘솔에서는 물론 일부 모바일 기기에서도 의미 있는 성능 향상을 기대할 수 있습니다.
Implementing compute shader variants of the current pixel shader passes and profiling on different devices. There are good ALU and bandwidth optimization opportunities that might translate to mobile devices as well. With compute shaders we could also merge the last three passes; small-tile resampling, shadows and lighting, to a single pass which should give significant performance boost on PC & consoles and possibly also on some mobile devices.
TAA 개선
우리는 TAA를 계속 개선해 디노이저로서의 역할을 강화하고, 조명 알고리즘이 만들어내는 노이즈 수준을 낮출 계획입니다. 조명 비용은 고정된 상태이지만, 특정 영역을 비추는 조명 수가 늘어날수록 노이즈 수준은 상승합니다. 현재 가장 큰 과제는, 조명 알고리즘이 만들어내는 노이즈가 많은 출력을 TAA가 잘 처리하도록 만드는 것입니다. 별도의 시공간 디노이저 패스를 구현하지 않고, 수정된 TAA만으로 결과를 충분히 디노이징하는 것이 아직까지의 목표입니다. ReSTIR처럼 이전 프레임의 소타일 저장소를 재샘플링하는 방식도 노이즈를 줄이는 데 도움이 될 수 있지만, 이를 위해서는 추가적인 연구 개발이 필요합니다.
We'll also continue the work on TAA to improve denoising and lower the level of noise generated by the lighting algorithm. While the lighting cost remains fixed, the level of noise increases as more lights are illuminating a region. Our biggest challenge currently is to make TAA to work well with noisy output produced by the lighting algorithm. We are still hopeful that we can denoise the result with a modified TAA instead of having to implement a separate spatiotemporal denoising pass. It might be also possible to reduce noise with pervious frame small-tile reservoir resampling similarly to ReSTIR, but this requires more R&D.
PDF 최적화
현재 대타일 PDF는 타일 깊이 범위 사이의 중심 선분을 사용해 각 조명이 타일에 미치는 영향을 추정합니다. 깊이 범위가 매우 넓고, 타일 내 픽셀이 주로 근·원평면 근처에 몰려 있는 경우, 깊이 범위 중간 지점에 있는 조명이 지나치게 자주 선택되어 노이즈가 늘어나는 문제가 생깁니다. 특정 깊이에 존재하는 픽셀 수에 비례하도록 PDF를 가중하면, 더 높은 품질의 대타일 저장소 샘플을 얻을 수 있을 것입니다. 또 다른 잠재적인 개선은, 스포트라이트 콘이 대타일 프러스텀과 교차하지 않는다면 PDF를 0으로 두는 것입니다. 현재 대타일 샘플링 비용은 매우 작기 때문에, 보다 다양한 상황을 잘 다룰 수 있도록 대타일 샘플 품질 향상에 약간의 연산을 더 투자할 여지가 있습니다.
The current big-tile PDF estimates lights influence on the tile using the central line segment between the tile depth bounds. If the depth range is large and the tile pixels are mostly near the near and far planes, lights in the middle of the range are picked too frequently increasing noise. It would be better to weigh the PDF proportionally to number of pixels at certain depth for higher quality big-tile reservoir samples. Another potential improvement is to set PDF to 0 if spotlight cone doesn't intersect the big-tile frustum. The current big-tile sampling is very efficient so we could spend some more cycles to improve the big-tile sample quality to better handle a wider range of scenarios.
소타일 PDF 역시 성능과 품질 양면에서 개선 여지가 있습니다. 현재 우리의 랜덤 PDF 평가는 4개의 샘플 점마다 그림자 조도와 BRDF를 평가해야 하므로 다소 비싸고, 조명 경계에서 약간의 편향을 유발하기도 합니다. 타일 경계와 계층적 그림자 맵을 사용해 한 번의 보수적 그림자 평가로 줄이고, G-Buffer의 저해상도 버전을 생성해 한 번의 보수적 BRDF 평가만 하는 방식으로 비용을 줄이면서 편향도 줄일 수 있을 것으로 기대합니다. PDF 평가에 톤 매핑을 전혀 사용하지 않고 있는데, 톤 매핑을 적절히 도입하는 것도 노이즈를 낮이는 데 도움이 될 것입니다.
The small-tile PDF can also be improved for both performance and quality. Our stochastic PDF evaluation requires currently 4 shadowed illuminance and BRDF evaluations which is rather expensive and results in some bias at lighting boundaries. We might be able to reduce this to one conservative shadow evaluation using tile bounds and hierarchical shadow map, and to have single conservative BRDF evaluation by generating a low-res version of the G-buffer. We don't either use any tone-mapping in the PDF evaluation, which should also help to bring down the noise.
파라미터 튜닝
기존 알고리즘의 파라미터를 조정해 품질과 성능을 동시에 개선할 수 있는, 이른바 "낮게 달린 과일"도 여전히 많이 남아 있습니다. 예를 들어 대타일 저장소 크기, 대타일 픽셀 크기, 샘플 패턴 등은 모두 개선 여지가 있는 요소들입니다.
There are also potential low-hanging fruits to improve the quality and performance by tuning the existing algorithm parameters. For example, big-tile reservoir size, big-tile pixel size, sampling patterns, and so forth can be likely improved.
반투명 지원
현재 조명 알고리즘은 G-Buffer에 렌더링된 완전 불투명 표면만 지원합니다. 래스터 기반 반투명 표면까지 지원하려면, 광선이 래스터화 중에도 효율적으로 샘플링할 수 있는 볼륨까지 조명 샘플링과 저장소 개념을 확장해야 합니다. 또한 이 알고리즘은, 예를 들어 볼륨 레이마칭 과정에서 소타일 재샘플링을 수행하는 방식으로 볼류메트릭 조명까지 확장할 수도 있습니다.
The lighting algorithm supports currently only fully opaque surfaces rendered in the G-Buffer. To add support for rasterized semi-transparent surfaces the light sampling and reservoirs should be extended to volumes that can be efficiently sampled during the rasterization. The algorithm can be also extended to support volumetric lighting for example by performing small-tile resampling upon volumetric ray marching.
감사의 말

발표를 마치겠습니다. 끝까지 들어주셔서 감사합니다! 발표를 검토하고 준비를 도와준 Natalya Tatarchuk, Sébastien Lagarde, Sebastian Aaltonen, Janne Gröndahl에게 감사를 전하며, 이번 출장에 후원해 준 HypeHype에도 감사드립니다. 마지막으로, 항상 인내심과 지지로 힘이 되어 준 아내 Laura에게 고마움을 전하고 싶습니다.
So, that wraps up my presentation and thank you for listening! I would like to thank Natalya Tatarchuk, Sébastien Lagarde, Sebastian Aaltonen and Janne Gröndahl for reviewing and helping to prepare the presentation, and HypeHype for sponsoring the trip. And finally, my wife Laura for her patience and support.
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [발표 번역] MEGALIGHTS: STOCHASTIC DIRECT LIGHTING IN UNREAL ENGINE 5 (0) | 2025.12.30 |
|---|---|
| 게임 Coder 전용 모델 강화 학습 WIP (2) | 2025.12.30 |
| [번역] UnityShader 간단한 털 렌더링: 짧은 털 편 (1) | 2025.12.05 |
| [번역] Cartoon Rendering Colouring Part 1: Forward and Deferred Mixing Shading Techniques (0) | 2025.11.28 |
| [번역] 클립맵 기반 정적 섀도우맵 (0) | 2025.11.26 |