
역자의 말: 언리얼엔진 코드를 수정하면 정말 많은 컴파일 시간을 기다려야 하죠. 기다리는 막간을 채우기 위해 肖鲁伟 군이 잘 정리 해 놓은 "GPU-Driven Rendering in Assassin's Creed Mirage" 총 3편을 한번에 묶어서 한국어 버전으로 올려 봅니다. 읽기 어려운 내용은 내용을 더 첨부 했습니다. 그나저나...내일 운전면허시험 보러 가야 하는데... 공부 해야 하는데...
저자: 肖鲁伟
1.1 소개
1.1.1 Anvil 엔진
Anvil 게임 엔진은 《어쌔신 크리드》 시리즈 개발로 업계에 널리 알려져 있으며, 그 기술 아키텍처는 《레인보우 식스: 시즈》, 《고스트 리콘: 브레이크포인트》, 《포 아너》 등 대형 프랜차이즈 게임 개발도 뒷받침하고 있다. 이 엔진은 체계적인 오픈 월드 구축을 목표로 설계되었으며, 핵심 기술은 원거리 렌더링(Long-range Rendering), 대규모 인스턴싱(Massive Instancing), 체계적 게임플레이 디자인(Systemic Gameplay)에 있다. (Figure 1.1)

어쌔신 크리드: 미라지의 대규모 씬 렌더링
1.1.2 선행 연구
2014년 《어쌔신 크리드: 유니티》와 2015년 《레인보우 식스: 시즈》에서 이 엔진은 GPU 드리븐 렌더링 파이프라인(GPU-driven Rendering Pipeline) 을 업계 최초로 상용화하는 데 성공했다 [Haar and Aaltonen 15]. 이 기술 혁신은 이후 Anvil 엔진의 핵심 아키텍처 기반이 되어 지속적으로 개선·발전해 왔다.
- GPU-Driven Rendering Pipeline이란?→ ExecuteIndirect — Microsoft Docs
- CPU가 드로우 콜을 개별적으로 발행하는 전통 방식과 달리, 컬링·LOD 선택·드로우 파라미터 생성까지 GPU가 직접 수행하는 파이프라인 아키텍처다. CPU 오버헤드를 크게 줄이고 GPU 병렬 처리를 극대화한다. 핵심 API는 DirectX 12의 ExecuteIndirect / Vulkan의 vkCmdDrawIndirect 로, GPU가 생성한 버퍼를 드로우 인자로 직접 사용한다.

이 버전에서는 게임 내 모든 지오메트리 메시에 클러스터 기반 처리(Cluster-based Processing, Figure 1.2) 를 적용하고, 머티리얼 기준의 동적 배칭(Dynamic Batching) 을 구현한 뒤, GPU 측에서 3단계 컬링을 수행한다:
인스턴스 레벨 → 클러스터 레벨 → 트라이앵글 레벨
컬링 후에는 간접 드로우 콜 MultiDrawIndexedInstancedIndirect 를 통해 렌더링 명령을 발행한다. 메시 클러스터화 기술(Clustered Mesh) 은 게임 엔진 분야에서 비교적 최신 기술에 해당하지만, 그 이론적 기반은 컴퓨터 그래픽스 초기 연구까지 거슬러 올라간다. 관련 알고리즘 원형은 Kumar 등의 1996년 연구 【Kumar et al. 96】 및 Cignoni 팀의 2005년 논문 【Cignoni et al. 05】 에서 확인할 수 있다.
- Clustered Mesh (Meshlet, 메시 클러스터)란?→ Introduction to Turing Mesh Shaders — NVIDIA Developer | Polygon mesh — Wikipedia
- 하나의 메시를 소수의 버텍스(이 엔진에서는 64개)로 구성된 클러스터(Meshlet) 단위로 분할하는 기법이다. 각 클러스터가 독립된 바운딩 볼륨을 가지므로, 인스턴스 단위가 아닌 클러스터 단위 GPU 컬링이 가능해진다. 화면 밖에 있는 인스턴스의 일부 클러스터만 선택적으로 제거하는 세밀한 컬링이 핵심 장점이다. DirectX 12 Ultimate의 메시 셰이더(Mesh Shader)는 이 개념을 API 차원에서 공식 지원한다.
또한 [Haar and Aaltonen, 15] 는 [Silvennoinen 12] 알고리즘을 기반으로 카메라 깊이 재투영 기법(Camera Depth Reprojection) 을 도입하여, 유효한 그림자를 생성할 수 없는 그림자 캐스터(Non-visible Shadow Casters)를 컬링함으로써 캐스케이드 섀도우 맵(Cascaded Shadow Maps) 의 렌더링 효율을 크게 향상시켰다. (Figure 1.3)
- Cascaded Shadow Maps (CSM, 캐스케이드 섀도우 맵)란?→ Cascaded Shadow Maps — Microsoft Docs | Shadow mapping — Wikipedia
- 카메라 뷰 프러스텀을 거리에 따라 여러 구간(cascade)으로 분할하고, 구간마다 별도의 섀도우 맵을 렌더링하는 기법이다. 가까운 구간에는 고해상도, 먼 구간에는 저해상도를 할당하여 그림자 품질과 성능의 균형을 맞춘다. 오픈 월드 게임의 태양광 그림자 표현에 사실상 표준으로 사용된다.
- Camera Depth Reprojection (카메라 깊이 재투영)이란?→ Temporal Anti-Aliasing / Reprojection — Wikipedia
- 이전 프레임의 깊이 버퍼를 현재 카메라 위치로 재투영(reprojection) 하여, 화면 어느 픽셀에도 그림자를 드리울 수 없는 그림자 캐스터를 미리 제거하는 보수적 컬링 기법이다. 섀도우 맵 렌더링 비용을 크게 절감할 수 있다.

노란색 화살표: 태양 방향
빨간색 선: 섀도우 맵 캐스케이드 범위
빨간색 오브젝트: 지면에 유효한 그림자를 생성할 수 없는 캐스터
파란색 오브젝트: 가능한 모든 그림자 수신 오브젝트를 가리는 캐스터
[Haar And Aaltonen 15] 는 고정 각도 집합을 사용하여 각 트라이앵글 클러스터의 가시성 마스크를 정적으로 사전 계산했다. [Wihlidal 17] 은 이를 기반으로, 완전히 컴퓨트 셰이더로 재구현하여 트라이앵글 컬링을 최적화했다. 마지막으로 [Karis 21] 은 [Cignoni et al. 05] 의 사상을 계승하여, 트라이앵글 클러스터 LOD 구조와 트라이앵글 크기 분류를 도입한 버추얼 지오메트리(Virtual Geometry) 파이프라인을 제안하고, 메시 셰이더(Mesh Shader) 와 소프트 래스터화(Soft Rasterization) 로 소형 트라이앵글을 처리했다.
- Virtual Geometry (버추얼 지오메트리 / UE5 Nanite)란?→ Nanite Virtualized Geometry — Unreal Engine Docs
- UE5 Nanite 기술을 의미하며, 메시를 계층적 클러스터 LOD로 구성하여 화면 픽셀 당 트라이앵글 하나 수준까지 LOD를 자동 선택한다. 매우 작은 트라이앵글은 하드웨어 래스터화 대신 소프트웨어 래스터라이저(Soft Rasterization) 로 처리하여 파이프라인 오버헤드를 최소화한다.
- Mesh Shader (메시 셰이더)란?→ Mesh Shader — Microsoft DirectX Specs
- DirectX 12 Ultimate 및 Vulkan(VK_EXT_mesh_shader)에서 도입된 셰이더 스테이지로, 기존의 Vertex → Geometry Shader 파이프라인을 Task Shader + Mesh Shader 로 대체한다. GPU에서 클러스터 단위로 지오메트리를 직접 생성·컬링할 수 있어, CPU 개입 없는 완전한 GPU 드리븐 지오메트리 파이프라인을 구현할 수 있다.
1.1.3 설계 철학
GPU 드리븐 렌더링 파이프라인의 첫 번째 버전은 BatchRenderer 라는 이름으로, DirectX 11 계열 API 를 대상으로 설계되었다 (Figure 1.4). BatchRenderer의 주요 목표는 MultiDrawIndexedInstancedIndirect 를 활용하여 DirectX 11에서 비용이 큰 개별 드로우 콜 오버헤드를 줄이는 것이었다. 그러나 다음과 같은 단점도 존재했다:
- 비동기 연산 미지원: 컬링이 렌더링 이전에 완료되어야 했다.
- 바인드리스(Bindless) 미지원: 머티리얼 단위 배칭만 지원했다.
- 배칭이 불필요하거나 지원되지 않는 그래픽 오브젝트에는 무용지물이거나 지나치게 복잡했다.
- 수천 번 인스턴싱되는 고도로 배칭된 그래픽 오브젝트에는 효율이 너무 낮았다.
- Bindless Rendering (바인드리스 렌더링)이란?→ Bindless Texture — Khronos OpenGL Wiki | VK_EXT_descriptor_indexing — Vulkan Spec
- 전통적인 방식에서는 셰이더가 사용하는 텍스처·버퍼를 렌더링 전에 특정 슬롯에 명시적으로 바인딩(DX11의 SetShaderResource 등)해야 한다. 바인드리스에서는 모든 리소스를 대형 Descriptor Heap에 올려두고, 셰이더가 런타임에 인덱스로 직접 접근한다. 머티리얼 단위 상태 변경 없이 셰이더 단위 대량 배칭이 가능해진다.

《어쌔신 크리드: 발할라》와 《어쌔신 크리드: 미라지》에서 우리는 이 시스템을 DirectX 12 계열 API 기반으로 재설계했다. 새 시스템의 이름은 GPU 인스턴스 렌더러(GPU Instance Renderer, GPUIR) 다. GPUIR를 통해 BatchRenderer의 단점들을 다음과 같이 해결했다:
- CPU 시간 감소: 로드 타임에 배칭을 수행하고, 더 많은 작업을 GPU로 이전하며, 바인드리스 리소스를 사용해 셰이더 단위의 더 효율적인 배칭을 구현했다.
- GPU 시간 감소: 매 프레임·매 패스별 인스턴스 컬링을 비동기로 실행하고, 렌더링 시에 메시 클러스터 컬링과 트라이앵글 컬링을 수행했다.
- 불투명 정적 또는 스킨드 메시 인스턴스 및 LOD 전환에만 적용: 메시 LOD 선택 및 텍스처 스트리밍과 긴밀하게 결합되어 있다.
GPU 인스턴스 렌더러 는 GPU 드리븐 컬링 파이프라인의 핵심 철학을 기반으로 하되, 로드/생성 시점의 사전 배칭(Pre-batching) 을 특히 강조하는 고처리량 렌더러다. 바인드리스 머티리얼 과 전역 지오메트리 버퍼 를 통해 CPU가 머티리얼 단위나 지오메트리 단위가 아닌 셰이더 단위로 배칭할 수 있게 해준다. BatchRenderer와 달리 GPU 상에서 상태 유지형 LOD 전환 을 처리하며, 인스턴스 그룹(LeafNodes) 목록만을 입력으로 받아 GPU에서 이를 패스별 개별 드로우 콜(예: ZPrepass, GBufferPass)로 확장한다. (Figure 1.5)

데이터베이스(1.2절)를 통해 GPU에서 씬 전체를 기술함으로써, GPU 인스턴스 렌더러는 더 많은 작업을 GPU로 이전한다.
1.2 데이터베이스
GPUIR는 CPU와 GPU 간 씬 전체 정보를 공유하는 효율적인 방법으로 데이터베이스(Database — 본 맥락에서만 사용하는 독립 개념) 에 크게 의존한다. 이는 새로운 GPU 드리븐 파이프라인의 핵심 요소 중 하나로, 더 많은 CPU 작업을 GPU로 이전할 수 있게 해준다.
1.2.1 설계 철학
데이터베이스는 MySQL을 GPU에 이식한 것이 아니다. 본질적으로는 CPU와 GPU 사이에서 공유할 수 있는 새로운 데이터 구조 컨테이너일 뿐이다.
우리는 복잡한 시스템을 포함하는 여러 게임을 출시했다. 예를 들어, GPU 드리븐 파이프라인은 GPU에서 복잡한 데이터 구조를 조작할 수 있어야 하고, 체적 조명 베이킹(GI)은 희소 볼륨(sparse volume)에 대한 영속적 트리 구조(persistent trees)를 필요로 한다. GPU에서 이러한 복잡한 데이터 구조를 할당하고 유지 관리하는 것은 대량의 보일러플레이트 코드(boilerplate code)와 업데이트 코드 등을 수반하기 때문에 매우 번거롭다.
Boilerplate code 란 반복적으로 재사용할 수 있는 코드 단위를 의미한다.
데이터베이스를 통해 우리는 재사용 가능한 CPU/GPU 데이터 컨테이너 인터페이스를 구축하고자 했다. 이 인터페이스는 다양한 할당, 저장, 복제 동작을 모듈식으로 조합할 수 있으며, C++ 객체지향 프로그래밍(OOP)의 편의성을 일부 재현하여 디버깅을 용이하게 한다.
1.2.3 데이터 레이아웃
셰이더 입력 그룹 컴파일러(Shader Input Groups Compiler, SIG) [Rodrigues 17] 는 루트 레이아웃과 셰이더 입력을 기반으로 하는 내부 컴파일러다. C++와 HLSL을 위한 바인딩 코드를 생성한다. 우리는 데이터베이스에 필요한 모든 C++/HLSL 코드 — 접근자(accessor) 및 최적화된 데이터 레이아웃을 포함 — 를 SIG를 통해 생성하기로 결정했다. (Listing 1.1)
// Listing 1.1.
// 데이터베이스 테이블 선언 예시,
// SIG 컴파일러 입력 형식.
databasetable MyObject
{
float4x4 transform;
uint type;
uint flags;
Row<MyObject> parent;
}
데이터 접근의 자연스러운 데이터 병렬성을 강조하기 위해, 우리는 데이터베이스 유추를 사용해 데이터 접근 방식을 기술하기로 했다. (Figure 1.6) 테이블(Table) 은 데이터 컨테이너의 한 인스턴스로, 고정 타입의 열(column) 집합과 가변 개수의 행(row) 을 포함한다.

구조체의 모든 멤버가 하나의 열이 되며, MyObject 배열의 각 인스턴스가 테이블의 한 행이 된다. (1.2.3절)
SIG가 생성한 코드의 도움으로, C++와 HLSL에서 테이블을 쉽게 선언하고 데이터를 접근할 수 있다. (Listing 1.2) 주의할 점은 HLSL이 연산자 오버로딩에 매우 제한적이기 때문에, 인터페이스가 [Rodrigues 17] 에서 제안한 SIG 상수 버퍼 인터페이스와 유사하게 구성되어야 한다는 것이다.
// Listing 1.2.
// Listing 1.1에서 선언한 데이터를 C++과 HLSL에서 접근하는 예시.
// C++에서의 테이블/열/행 접근
MyObject::Table table;
Matrix44 transform = table.transform[15];
MyObject::Row parent = table.parent[1]
// HLSL에서의 테이블/열/행 접근
MyObjectRO myObjectTable = MyObjectRO::Create(byteAdressBuffer);
float4x4 transform = myObjectTable::GetTransformAt(15);
uint row = myObjectTable.GetParentAt(1);
구조체 배열 (Structure of Arrays, SoA)
DefaultLayout=SoA 어노테이션을 사용하면, 데이터에 접근하는 인터페이스를 변경하지 않고도 테이블의 데이터 레이아웃을 배열의 구조체(AoS)에서 구조체의 배열(SoA)로 쉽게 전환할 수 있다. (Listing 1.3) AoS와 SoA를 혼합(Hybrid) 하여 사용하는 것도 가능하다. 접근 코드에는 어떠한 차이도 없으므로, 사용하는 코드를 업데이트하지 않고도 테이블의 데이터 레이아웃을 반복적으로 최적화하여 최적의 캐시 성능을 얻을 수 있다.
// Listing 1.3
// SoA 테이블 선언 예시, Listing 1.1을 재활용.
databasetable MyObject <DefaultLayout=SoA>
{
float4x4 transform;
uint type;
uint flags;
Row<MyObject> parent;
}
보충 비교: SOA vs AOS vs Mix 【Alexandros, 20】

레이아웃 AoS SoA Hybrid
| 데이터 지역성 | 단일 인스턴스 내 필드가 연속적, 전체 접근이 빠름 | 동일 필드가 엔티티 전체에 걸쳐 연속적, 일괄 처리가 빠름 | 그룹화 전략으로 두 방식의 균형을 맞춤 |
| 메모리 사용량 | 정렬 패딩으로 인해 메모리 사용 증가 | 컴팩트, 불필요한 패딩 없음 | 두 방식의 중간 |
| 적합한 사용 사례 | 단일 인스턴스의 필드 상태 관리를 빈번히 처리 | 여러 인스턴스의 필드를 일괄 처리: 물리 시뮬레이션/파티클 시스템 | 두 경우 모두 고려해야 하는 시스템 |
분할 구조체 배열 (Paged SoA)
또 다른 데이터 레이아웃으로 분할 구조체 배열(Paged SoA) 을 지원한다. (Listing 1.4)
// Listing 1.4.
// SIG에서의 Paged SoA 테이블 선언 예시.
// RowsPerPage 어노테이션 사용에 주목.
databasetable MyObject <RowsPerPage = 16384>
{
float4x4 transform;
uint type;
uint flags;
Row<MyObject> parent;
}
GPU 리소스를 셰이더에 바인딩하는 방법에는 제한이 있기 때문에, 각 열에 임의 범위의 메모리를 사용하면(인스턴스를 동적으로 추가할 수 있으므로) 효율이 매우 낮아진다. 반대로, 테이블 당 하나의 GPU 리소스를 사용하는 것이 훨씬 적합하다. 하지만 가상 메모리를 사용하지 않으면, 테이블마다 항상 최대 메모리 값 을 미리 정의해야 하므로 매우 제한적이다.
SoA 레이아웃에서는 테이블의 각 열이 메모리 내에서 연속적이기 때문에, 대형 테이블에 가상 메모리를 사용하면 테이블이 성장할 때 각 열이 최소 하나의 메모리 페이지만큼 증가해야 한다 (주석 1). 열이 많은 테이블의 경우 이는 매우 많은 리소스를 소모한다.
따라서 우리는 각 열의 일부 블록만 연속적인 데이터 레이아웃을 지원한다. (Figure 1.7) 이렇게 하면 단일 물리 메모리 페이지로 모든 열을 동시에 증가시킬 수 있다.

주석: A page, memory page, or virtual page is a fixed-length contiguous block of virtual memory, described by a single entry in a page table. 메모리 페이지는 고정 길이의 가상 메모리이므로, 테이블이 증가할 때 SoA 구조에서는 각 필드(열)가 연속적인 블록으로 구성되어 있어 새 페이지 생성 시 각 열이 하나의 페이지씩 증가하게 된다.
1.2.3 관계 속성
관계(Relation)는 서로 다른 테이블 인스턴스 간의 링크다.
1 대 1: 단순 1:1 관계는 데이터베이스 버전의 포인터 로 볼 수 있다. (Listing 1.5) 내부적으로는 단순히 uint 인덱스에 불과하지만, C++에서는 최소한 타입 안전성이라는 장점을 제공한다. 대상 테이블(destination table)의 포인터는 테이블 인스턴스(table instance)에 저장되고, 행 인덱스(row index)는 Row 관계에 저장된다. 포인터 + 행 인덱스 × 행 크기 를 통해 대상 테이블의 특정 행 데이터 메모리 주소를 계산하고, 최종적으로 구체적인 메모리 주소 로 변환되어 해당 위치의 데이터에 직접 접근할 수 있다.
// Listing 1.5.
// Row 관계는 포인터를 시뮬레이션하는 단순 1:1 관계다.
// 행 접근 방법은 Listing 1.2에 나와 있다.
// 데이터베이스 선언
databasetable MyObject
{
Row<MyObject> parent;
uint randomProperty;
};
// C++ 유추
struct MyObject
{
MyObject* parent;
U32 randomProperty;
}
1 대 n: 1:n 관계도 지원하며, 이는 앞서 다룬 1:1 관계의 확장이다. 이를 Range 라 부르며, 크기 정보를 가진 포인터(Listing 1.6)를 시뮬레이션하여 하나의 포인터로 여러 오브젝트에 접근하는 기능을 구현한다. (N개의 오브젝트를 하나의 새로운 오브젝트로 묶고, 포인터가 그 오브젝트를 가리켜 자식 오브젝트를 통해 접근하는 방식으로 1:N을 구현한다고 이해할 수 있다.)
// Listing 1.6.
// Range 관계는 크기 정보를 가진 포인터를 시뮬레이션하는 1:N 관계다.
// 데이터베이스 선언
databasetable MyObject
{
Range<MyObject> children;
};
// C++ 유추
struct MyObject
{
MyObject* children;
U32 childCount;
};
PartialRange 는 Range와 유사하지만, Range의 크기를 "사용 크기"와 "최대 크기"로 분리하여 std::vector 의 증가 및 축소 동작을 시뮬레이션한다. (Listing 1.7)
// Listing 1.7.
// PartialRange 관계는 부분적으로만 사용되는 1:N 관계다.
// 데이터베이스 선언
databasetable MyObject
{
PartialRange<MyObjectList> children;
};
// C++ 유추
struct MyObject
{
Array<MyObject*> children;
};
소유권(Ownership): 지금까지 살펴본 것처럼, Row 와 Range 는 다른 테이블에 저장된 데이터를 가리키는 포인터에 불과하다. 여기에 소유권 개념을 <owner> 속성 선언으로 강화할 수 있다. 이는 소유자 테이블의 항목이 삭제될 때 Row나 Range가 참조하는 owned rows도 해당 테이블에서 올바르게 삭제되도록 보장한다. 즉, 소유권 이전 후 원본 데이터 참조도 삭제됨을 보장한다. (Listing 1.8 / Listing 1.9)
// Listing 1.8.
// TestRange는 Range POD가 참조하는 TestPOD 테이블의 행들을 소유한다.
// 데이터베이스 선언
databasetable TestPOD
{
int IntValue;
float FloatValue;
};
databasetable TestRange
{
Range<TestPOD> POD; <owner>
};
// 단순 테이블 범위
TestPOD::Table tablePOD(G4_KB(1));
TestPOD::Range ranges[16];
S32 intValue[16];
F32 floatValue[16];
for (U32 i = 0; i < 16; i++)
{
intValue[i] = -S32(i);
floatValue[i] = i * 0.125f;
}
// 기본 데이터
for (U32 i = 0; i < 16; i++)
ranges[i] = tablePOD.NewArray(i + 1, intValue, floatValue);
// 범위 추가
// tablePOD 참조로부터 가져오기
TestRange::Table tableRange(G4_KB(1), tablePOD.Ref());
for (U32 i = 0; i < 16; i++)
tableRange.New(ranges[15 - i]);
// 작업 수행 ...
// 소유된 범위 삭제
for (U32 i = 0; i < 16; i += 2)
tableRange.Delete(i);
// tableRange의 항목이 삭제되면,
// tableRange::POD가 참조하는 tablePOD의 모든 행도 삭제된다.
// <owner> 속성 덕분에.
주의: tableRange 생성은 먼저 tablePOD 참조를 통해 이루어지며, 이 시점에서 제어권이 이전된다. 그 후 range[]를 통해 중복 내용을 생성할 때도 제어권이 이전된다. 따라서 삭제 시 한 번만 삭제해도 대응하는 전체 삭제가 가능하다.
인덱스(Index): 가장 복잡한 관계는 인덱스 다. (Listing 1.10 / 1.11) [index()] 어노테이션을 통해 SIG는 키 열(key column)에 특정 타입의 인덱스를 자동으로 생성한다. 이 인덱스는 역방향 관계에 효율적으로 접근할 수 있게 해준다. SQL의 보조 키 인덱스(Secondary Key Index)와 유사한 방식으로 동작한다.
// Listing 1.10
// 데이터베이스 선언
databasetable Component
{
[index(dense,n)]
Row<Entity> owner;
uint randomProperty;
...
};
databasetable Entity
{
...
};
// C++ 유추
struct Component
{
Entity* owner;
uint randomProperty;
...
};
struct Entity
{
...
Array<Component> components;
};
// Listing 1.11.
// Component와 Entity 테이블 선언
Entity::Table tableEntity(G4_KB(1));
Component::Table tableComponent(G4_KB(1));
// 테이블을 채우는 코드 ...
for (U32 i = 0; i < entityCount; i++)
{
// list는 소유자 Entity i가 참조하는 모든 Component의 인덱스 목록을 보유한다
auto list = tableComponent.ownerIndex.Get(i);
// Component 목록을 순회하며 처리 ...
for(tableComponent::Row row : list)
{
U32 randomPropertyValue = tableComponent.randomProperty[row];
// 처리 ...
}
}
인덱스 관계: 컴포넌트 n의 소유자를 가져올 수 있을 뿐만 아니라, 동일한 소유자 m을 가진 모든 컴포넌트를 효율적으로 순회할 수 있다.
우리는 이러한 관계들을 배열처럼 조작할 수 있는 라이브러리를 작성했다. C++와 HLSL에서 CPU 또는 GPU에서 테이블을 쉽게 조작할 수 있도록 표준 함수 코드가 생성된다.
1.2.4 데이터 복제
서로 다른 테이블 인스턴스는 CPU 저장소 와 GPU 저장소 를 각각 처리한다. 매우 큰 테이블의 경우, 전체 CPU 테이블을 할당할 필요 없이 GPU에 플러시되기 전까지 CPU에 더티 행(dirty row)만 할당·저장하는 방식도 지원한다. 데이터가 한 인스턴스에서 다른 인스턴스로 전파되도록(일반적으로 CPU에서 GPU로) 여러 가지 데이터 복제 모드를 지원한다.
복제(Copy): 가장 단순한 데이터 복제 방식이다. 페이징 여부에 관계없이 모든 CPU/GPU 테이블 조합의 복제를 지원한다. 소스와 대상이 모두 GPU에 있으면 복제가 GPU에서 직접 수행되고, 그렇지 않으면 ByteAddressBuffer 로/에서 데이터를 복제할 때와 유사하게 동작하며(예: CPU에 버퍼를 매핑하는 등), 데이터베이스 시스템과 관련된 추가 관리 작업이 수반된다.
더티 행 업데이트(DirtyRows Update): 이 전략으로 구성된 테이블은 행 업데이트 시 해당 행의 더티 마스크를 갱신한다. 연속된 더티 행 범위가 업데이트 시 다른 테이블로 복사된다. 행 복제는 많은 소규모 복사를 유발하지만, 최소한의 복제 대역폭을 생성한다.
더티 페이지 업데이트(DirtyPages Update): 이 전략에서는 더티 페이지 범위가 복사된다. 더티 행 업데이트와 유사하지만 "더티" 마킹의 단위가 더 크다(행 단위가 아닌 페이지 단위). 더티 상태 추적에 필요한 저장 공간은 더 작지만, 요구되는 복제 대역폭은 더 높다.
더티 페이지 복사(DirtyPage Copy): 더티 행과 더티 페이지 모두 CPU 저장소에 데이터를 마킹한다. 행이나 페이지 내 값이 변경되면 전체 행 또는 페이지를 GPU에 업로드한다. 더티 페이지 복사를 사용하는 경우, 더티 페이지는 CPU 시스템 메모리의 별도 데이터 구조에 할당된 후 업데이트 시 업로드 힙으로 복사되고, 최종적으로 컴퓨트 셰이더를 사용해 최종 GPU 저장소에 기록된다. (Listing 1.12) 이 복제 전략을 통해 테이블 인스턴스가 수정되지 않은 행을 기록하기 위한 추가 CPU 저장소를 사용하지 않고도 쓰기 전용으로 지원할 수 있다.
// Listing 1.12.
// CPU에서 GPU로의 데이터베이스 테이블 복제 및 업데이트 예시.
// DirtyPages 어노테이션 사용에 주목.
// DirtyPages 업데이트 정책을 사용한 테이블 타입 선언
databasetable TestUpdatePage <RowsPerPage=64;
Instance={Persistent;DirtyPages}>
{
int IntValue;
uint UIntValue;
float FloatValue;
float4 FloatVectorValue;
};
// CPU 테이블 생성 및 데이터 초기화
TestUpdatePage::Table TestUpdatePageCPU(G4_KB(1));
for (U32 i = 0; i < 16; i++)
TestUpdatePageCPU.New(-S32(i), i, i*0.125f, Vector4(i*-0.5f));
// GPU 테이블 생성
TestUpdatePage::TableGPU TestUpdatePageGPU(G4_KB(1));
TestUpdatePageGPU.CreateGPUBuffer(device);
// CPU에서 GPU로 복사
CopyTable(device, TestUpdatePageCPU, TestUpdatePageGPU);
// CPU에서 GPU로 업데이트
UpdateTable(device, TestUpdatePageCPU, TestUpdatePageGPU);
TestUpdatePageCPU.ClearDirtyElements();
1.3 CPU 데이터 관리
GPUIR의 모든 입력은 데이터베이스 테이블로 변환되어 GPU로 빠르게 가져오고 쉽게 복사할 수 있다. 가장 중요한 세 가지 입력 테이블은 CullMeshes, CullInstances, LeafNodes 다. 이 절에서는 이 테이블들의 관리 방식, 저장하는 데이터 유형, 그리고 GPU에서 컬링 프로세스를 시작하는 데 어떻게 활용되는지를 다룬다.
1.3.1 렌더링 데이터
BatchRenderer의 LOD 선택기 는 5개의 지오메트리 세부 단계(LOD) 집합을 나타낸다. 현재 활성화된 LOD는 카메라와의 거리에 따라 선택되며, LOD 간 전환은 시간에 따라 결정된다.
- LOD (Level of Detail, 세부 단계)란?→ Level of detail (computer graphics) — Wikipedia
- 카메라와의 거리에 따라 오브젝트를 서로 다른 해상도의 메시로 교체하는 기법이다. 먼 거리에는 폴리곤 수가 적은 저해상도 메시를 사용하여 렌더링 비용을 절감한다. GPUIR에서는 CPU의 LOD 선택을 제거하고, GPU가 인스턴스별 LOD 상태와 전환 타이밍을 직접 관리한다.
GPUIR에서 인스턴스 컬렉션을 생성할 때 가장 먼저 설정해야 하는 것은 CullMeshes 와 그 렌더 배치다. CullMesh 는 LOD 선택기의 GPU 근사 표현이다. LOD 정보 외에도 렌더 가능한 패스 정보를 포함한다. 각 LOD 노드 CullLODNode 는 가변 수의 CullSubMeshes 를 가리키며, 여기에 머티리얼과 지오메트리 설명이 저장된다. CullMesh 구현에 사용된 데이터베이스 테이블에 대한 더 완전한 설명은 Figure 1.8을 참조하라.

각 드로우 콜에서 최대한 많은 인스턴스를 배칭하기 위해, 파이프라인 상태 오브젝트(PSO) 마다 하나의 배치 슬롯을 생성한다. 이 배치 슬롯에는 드로우 콜 중에 변경할 수 없는 모든 것이 포함된다: 셰이더 템플릿, 특정 셰이더 변형, 그리고 다양한 파이프라인 플래그.
- PSO (Pipeline State Object, 파이프라인 상태 오브젝트)란?→ Managing Pipeline State — Microsoft DX12 Docs | Pipeline (computing) — Wikipedia
- DirectX 12 / Vulkan에서 도입된 개념으로, 렌더링 파이프라인의 모든 고정 상태(셰이더, 블렌드·래스터라이저·깊이-스텐실 상태, 정점 레이아웃 등)를 하나의 불변(immutable) 오브젝트로 미리 컴파일하여 저장한다. DX11의 개별 상태 설정 방식보다 드라이버 오버헤드가 훨씬 적으며, 렌더링 직전 셰이더 컴파일로 인한 프레임 지연(stutter)을 방지한다.
- G-Buffer (지오메트리 버퍼 / Deferred Rendering)란?→ Deferred shading — Wikipedia
- 지연 렌더링(Deferred Shading) 에서 사용하는 중간 버퍼 세트다. Geometry Pass에서 픽셀별 위치·법선·알베도·머티리얼 파라미터를 별도 텍스처(G-Buffer)에 기록한 뒤, Lighting Pass에서 이를 읽어 조명 계산을 수행한다. 포워드 렌더링에 비해 다수의 동적 광원을 훨씬 효율적으로 처리할 수 있어 대형 게임에 널리 사용된다.
렌더 패스 마스크는 머티리얼에 의해 결정되지만, 일부 컬링 연산은 CullMesh 레벨에서 수행되므로 이 레벨에서도 정보를 집계할 필요가 있다. MergedBatchHash 는 CullMesh 내 모든 CullSubMeshes의 결합된 PassMask를 저장한다. 또한 이 CullMesh의 최대 인스턴스 수와 트라이앵글 클러스터 수도 포함한다. 이 정보는 나중에 주어진 씬에서 발행할 간접 드로우 콜의 총 수를 계산하는 데 사용된다.
1.3.2 월드 데이터
전역 렌더링 데이터가 준비되면, 각 월드별 로컬 데이터인 LeafNodes 와 CullInstances 를 생성할 수 있다. CullInstance는 트랜스폼, CullMesh, LOD 상태, 인스턴스별 머티리얼 플래그(per-instance material flags), 그리고 인스턴스별 셰이더 상수(per-instance shader constants)로 구성된다. 주 시야와 섀도우 맵에 대해 서로 다른 LOD 전환 거리를 정의할 수 있기 때문에, 각 인스턴스에는 두 세트의 LOD 상태가 저장된다.
GPUIR는 한 번에 수백만 개의 인스턴스를 컬링하고 렌더링할 수 있도록 설계되었다. 좋은 컬링 성능을 위해, 엔티티 그룹(Entity Group) 과 LeafNodes로 구성된 계층 구조에 의존한다. (Figure 1.9) 엔티티 그룹은 주어진 로드 유닛 내 특정 타입 인스턴스(예: 나무나 건물) 컬렉션을 나타낸다. 이 인스턴스들은 일반적으로 산포 규칙(scattering rules)에 따라 프로시저럴하게 생성되거나 최적화된 인스턴싱을 통해 생성되며, 로드 유닛의 모든 엔티티를 순회하면서 GPUIR와 호환 가능한 엔티티들을 선택적으로 합쳐 엔티티 그룹 을 구성한다.

인스턴스는 컬렉션 내의 LeafNodes 로 분할되며, 서로 다른 CullMeshes 의 인스턴스가 동일한 LeafNode에 포함될 수 있다. 단, 그룹화할 인스턴스를 선택할 때 몇 가지 제약이 있다. 첫째, 인스턴스 범위가 데이터베이스 테이블의 할당 페이지를 가로질러 존재할 수 없기 때문에, 각 LeafNode에는 16,384개를 초과하는 인스턴스를 포함할 수 없다. 둘째, 컬링 효율성을 높이기 위해 바운딩 볼륨을 최소화하는 방향으로, 공간적으로 가까운 인스턴스들을 동일한 LeafNode에 배치하려 한다.
LeafNode 는 계층 구조의 최하위 레벨이며 CPU에서 컬링이 수행되므로, 빈 드로우 콜을 건너뛸 수 있는 마지막 기회이기도 하다. 그래서 각 LeafNode에 대해 PassMask를 계산하고, 해당 인스턴스의 CullMesh가 제공하는 모든 배치 해시 값을 수집한다. LeafNode는 SIG 컴파일러의 <owner> 속성을 활용하여, LeafNode 삭제 시 다른 데이터베이스 테이블에서 소유된 행들을 자동으로 해제한다. 따라서 LeafNode는 인스턴스들, 그 셰이더 상수, 그리고 레퍼런스 카운팅을 위한 CullMeshes의 간접 참조를 소유한다. 월드 전용 데이터베이스 테이블 간의 관계는 Figure 1.10을 참조하라.

1.3.3 거친 단위 CPU 컬링
엔티티 그룹이 메모리에 로드되고 월드 데이터가 생성될 때, 이들은 쿼드트리 컬링 구조에도 삽입된다. (Figure 1.9) 매 프레임 시작 시 쿼드트리의 각 셀을 렌더 패스의 뷰 프러스텀과 검사하여 최소 하나의 렌더 패스에서 가시적인 엔티티 그룹을 수집한다.
이 엔티티 그룹들의 LeafNode (Figure 1.11)는 다시 각 뷰 프러스텀에 대해 테스트되며, 이 시점에서 합산된 패스 마스크를 활용해 렌더 패스에 가시 인스턴스를 생성하지 않는 LeafNode를 건너뛸 수 있다.

이를 통해 PassedLeafNodes 목록과 이에 대응하는 PassedInstanceRanges(한 패스에서 가시 인스턴스 범위를 저장) 를 얻는다. 인스턴스 범위는 다음 단계의 세밀한 컬링을 위해 GPU로 전송된다. (Figure 1.12)

PassedLeafNodes를 기반으로, 배치 슬롯 해시를 키 값으로 사용하여 각 렌더 패스에 대한 렌더 배치 해시 맵을 구성한다. 이 해시 맵을 통해 GPU는 특정 패스의 렌더 배치에 대한 간접 드로우 콜 파라미터를 어디에 기록해야 하는지 알 수 있다. 이 맵을 생성하려면 PassedLeafNodes를 순회하면서 고유한 MergedBatchHash 마다 렌더 배치를 할당하기만 하면 된다. 할당된 렌더 배치는 아직 완전히 초기화할 수 없는데, 이 렌더 배치를 참조하는 활성 CullSubMeshes 가 얼마나 되는지 알 수 없기 때문이다. 이 정보는 GPU에서 컬링 패스 완료 후 확정된다. (1.4.2절 참조)
현재 단계에서 확정할 수 있는 것은 렌더 배치에 포함될 수 있는 최대 인스턴스 수와 드로우 콜 수이며, 이는 CPU에서 간접 드로우 콜을 준비하는 데 필요하다.
1.4 GPU 컬링
계층 구조의 최상위 레벨 컬링이 완료되었으므로, 이제 개별 인스턴스 단위로 처리를 시작할 수 있다. 일반적으로 이 시점에는 수십만 개의 인스턴스를 처리해야 하므로, GPU가 진정한 역할을 발휘하는 곳이다. CPU 컬링 단계에서는 일련의 임시 데이터베이스 테이블(예: PassedInstanceRanges, BatchMap)이 생성되며, 이는 영속적 렌더링 데이터 및 월드 데이터 테이블(예: CullInstances, CullMeshes)과 함께 GPU로 복사된다.
이 모든 정보를 실제 드로우 콜로 변환하기 위해, 인스턴스 레벨에서 매 프레임·매 패스별 몇 가지 연산을 수행해야 한다. 일반적으로 GPU 컬링 패스는 비동기 큐에서 실행할 수 있지만, 실제 구현에서는 트라이앵글 컬링과 클러스터 컬링이 지오메트리 렌더링 전에 그래픽 큐에서 완료된다.
아래 각 절에서 설명하는 모든 셰이더는 그 출력을 임시 GPU 데이터베이스 테이블에 저장한다. 이 테이블의 할당은 두 단계로 이루어진다:
- 먼저 스레드 그룹이 원자적 덧셈(atomic add)을 실행하여 스레드 그룹이 요청하는 행 수를 계산한다.
- 그룹의 첫 번째 스레드가 또 다른 원자적 덧셈으로 테이블 크기를 증가시킨다.
barrier();
if(id == 0) {
offset = atomicAdd(mem, data);
} 위 연산의 반환값은 각 스레드의 로컬 오프셋과 그룹의 쓰기 오프셋을 각각 제공한다.
1.4.1 매 프레임 GPU 컬링
GPU의 매 프레임 연산(Figure 1.12)은 인스턴스의 LOD 상태를 업데이트하고, 패스별 컬링으로 넘길 서브메시 인스턴스를 생성하는 것이 목적이다.

인스턴스 범위 추출 (Extract Instance Ranges) CPU 컬링 단계에서 GPU로 전송된 인스턴스 목록은 PassedInstanceRanges로 압축되어 있다. 각 GPU 스레드에 하나의 인스턴스를 할당하려면, 이 범위들에서 개별 인스턴스 인덱스를 추출해야 한다. 이는 범위 검색 테이블 과 그룹 범위 테이블 을 구성하여, 인스턴스 컬링 셰이더가 그룹의 인스턴스 범위 경계 내에서 이진 탐색을 통해 자신의 인스턴스 인덱스를 찾을 수 있도록 한다. (Figure 1.13 a/b)

목표: 각 컬링 스레드에 하나의 통과 인스턴스를 할당하는 것. (a) (b) 단계는 다음과 같다:
- 전위 합(Prefix Sum) 계산
- 범위 경계 결정
- 전역 인덱스 할당
인스턴스 및 LOD 컬링 (Cull Instances and LODs) 인스턴스 인덱스를 확보하면, GPU 스레드는 추가적인 뷰 프러스텀 컬링을 수행할 수 있다. 각 인스턴스는 패스별 뷰 프러스텀에 대해 테스트되며, 교차하는 뷰 프러스텀은 패스 마스크에 기록된다. 인스턴스가 최소 하나의 뷰 프러스텀과 겹치면, 해당 인스턴스의 LOD 상태가 LOD 업데이트 단계로 출력된다.
앞서 언급한 대로, 각 인스턴스에 대해 두 개의 LOD 상태를 추적한다 — 주 시야용 하나와 그림자용 하나. 아래 코드는 LOD 상태 패스 마스크를 계산하는 방법을 보여준다. (Listing 1.13) LOD 상태 업데이트 에는 LOD 전환이 언제 시작되는지 감지하고 진행 중인 전환의 진행 상황을 추적하는 것이 포함된다. 이 구현에서 LOD 전환은 중단 불가능하며, 항상 고정 시간 동안 지속된다. 업데이트 후 각 LOD 상태는 전환 진행 중인지 여부에 따라 하나 또는 두 개의 PassedLODs를 배치 확장 단계로 내보낼 수 있다.
// Listing 1.13.
// LOD 상태 패스 마스크는 인스턴스가 컬링되지 않은 모든 패스의 합집합과
// 정적 그림자 패스 마스크로부터 계산된다.
uint CullSphere(in const CullingCommon common, in const float4 centerRadius, in uint rangePassMask)
{
uint overlappedMask = 0;
for(uint i = 0; i < common.GetFrustumCount(); i++)
{
uint4 frustumDesc = common.GetFrustumDescAt(i);
// 이 프러스텀을 컬링할 필요가 있는지 확인
uint passMaskOverlap = frustumDesc.z & rangePassMask;
if (passMaskOverlap == 0)
continue;
if (!CullPlanesSphere(common, frustumDesc.x, frustumDesc.y, centerRadius))
overlappedMask |= passMaskOverlap;
}
return overlappedMask;
}
void CS_CullInstances(uint3 threadID : SV_DispatchThreadID, uint3 groupID : SV_GroupID)
{
// ...
uint rangePassMask = passedInstanceRanges.GetPassMaskAt(instanceRangeRow);
uint instancePassMask = CullSphere(Common, transformedCenterAndRadius, rangePassMask);
uint mainLODStatePassMask = instancePassMask & ~SHADOW_PASS_MASK;
uint shadowLODStatePassMask = instancePassMask & SHADOW_PASS_MASK;
// ...
}
배치 생성 (Generate Batches) 이 단계에서는 최소 하나의 PassedLODs 목록을 확보한 후, 그 서브메시들을 서로 다른 렌더 패스(Pass)에 할당하려 한다. 지금까지 계산된 패스 마스크는 인스턴스 가 어떤 패스에서 렌더링될 수 있는지를 지정하지만, 인스턴스 LOD의 서브메시가 어떤 패스에서 렌더링될지 정확히 알아야 한다.
예를 들어, Z-pre Pass 에서 어떤 서브메시를 렌더링할지 결정해야 한다. 이를 위해 서브메시는 스크린 스페이스에 투영된 트라이앵글의 평균 크기를 사용해 휴리스틱하게 평가된다. 카메라에 가깝거나 더 큰 트라이앵글로 구성된 오브젝트일수록 Z-pre Pass에 포함될 가능성이 높다. 또한 서브메시를 렌더링할 셰이더 변형을 선택해야 한다. 예를 들어, 오브젝트에 어떤 형태의 알파 클리핑(디더링 또는 알파 테스트 모두 없음)도 필요하지 않다면, 클리핑 없이 최적화된 렌더링을 선택할 수 있다.
트라이앵글 크기 → 트라이앵글 투영 픽셀 면적 → 트라이앵글 수
배치 데이터를 생성하려면 Batch Map이 필요하다. 앞서 언급한 내용을 상기하면:
1.3.3에서 언급: ··· 할당된 렌더 배치는 아직 완전히 초기화할 수 없는데, 이 렌더 배치를 참조하는 활성 CullSubMeshes가 얼마나 되는지 알 수 없기 때문이다. 이 정보는 GPU에서 컬링 패스 완료 후 확정된다.
이 맵은 CPU 거친 단위 컬링 단계를 통과한 LeafNode의 MergedBatchHashes를 기반으로, 서로 다른 렌더 배치를 서로 다른 렌더 패스와 연결한다. 렌더 배치 생성의 핵심 단계는 다음과 같다:
- 서브메시 인스턴스 등록: 선택된 렌더 패스와 셰이더 변형에 따라 서브메시 인스턴스를 해당 렌더 배치에 등록한다.
- 인스턴스 재정렬: 모든 서브메시 인스턴스 등록이 완료되면 재정렬하여, 최종적으로 패스별 서브메시 인스턴스 버퍼를 생성한다. (Figure 1.14)

Figure 1.14: 전역 버퍼 구조와 기능. 이 전역 버퍼는 통과한 모든 서브메시 인스턴스를 포함하며, 이들은 자신이 속한 렌더 패스와 렌더 배치에 따라 분류 및 압축 최적화되어 있다. 컴팩트한 배열을 통해, 패스 컬링 셰이더는 스레드 ID를 기반으로 현재 스레드에 할당된 서브메시 인스턴스를 빠르게 찾을 수 있다.
1.4.2 패스별 GPU 컬링
최종 각 렌더 배치의 독립적 드로우 콜 파라미터를 생성하기 전, 아직 인스턴스를 컬링할 기회가 한 번 더 있다. 이 단계를 완료하면, 화면에 머티리얼을 올바르게 렌더링하는 데 필요한 모든 데이터(InstanceInfo 포함 — 이는 각 인스턴스에 대해 버텍스 및 픽셀 셰이더에서 해당 지오메트리와 머티리얼 정보를 가져올 수 있게 해준다)를 확보하게 된다. Figure 1.15는 나머지 컬링과 드로우 명령 준비 단계를 보여준다.

Figure 1.15: 패스별 컬링 단계 개요. 패스별 컬링 흐름은 다음 단계로 구현된다:
- 비동기 큐의 컬링 흐름 인스턴스화
- 그래픽 큐의 최종 컬링 연산 (선택 사항)
패스 서브메시 컬링 (Cull Pass Sub-meshes) 여기서 서브메시 인스턴스에 추가적인 컬링 테스트를 선택적으로 수행할 수 있다. 어떤 테스트를 수행하는지는 테스트를 수행하는 패스와 비용 대비 효과에 따라 달라진다.
예를 들어, 대부분의 주 시야 패스에 대해 서브메시의 바운딩 박스를 샘플링 영역으로 사용하여 주 시야의 계층적 Z 버퍼(HZB) 로 오클루전 컬링 테스트를 수행하기로 결정했다. (1.4.3절 참조) 태양 그림자의 경우, 화면상 어떤 픽셀에도 영향을 미치지 않는 그림자 캐스터를 컬링하기 위해 카메라 깊이 재투영 방법을 적용하기로 했다. 마지막 테스트를 통과한 모든 서브메시 인스턴스는 최종적으로 드로우 콜에 포함된다.
해시 배치 (Hash Batches) 각 렌더 배치의 드로우 콜 카운트와 모든 드로우 콜의 파라미터를 저장하기 위해 별도의 드로우 버퍼를 사용한다. 인스턴스가 어떤 드로우 콜에 속하는지 결정하기 위해, 서브메시 ID와 렌더 배치 ID를 해시한다. 기술적으로는 서브메시 ID만으로도 드로우 콜 해시를 만들기에 충분하지만(지오메트리와 머티리얼의 조합을 나타내므로), 우리의 경우 알파 클리핑이 활성화될 때 서로 다른 PSO 사이를 전환하므로 사용되는 셰이더 변형에 따라 서브메시 인스턴스를 서로 다른 드로우 콜에 등록해야 한다. (1.4.1절 참조)
- 해시 배치 구성 (첫 번째 처리)
- 해시 키 생성: 서브메시 ID(sub-mesh ID)와 렌더 배치 ID(render batch ID)를 조합하여 드로우 콜 해시 키를 생성한다.
- 해시 맵 채우기:
- 충돌 해결: 클로즈드 해싱(Closed Hashing) 과 선형 탐사(Linear Probing) 로 해시 충돌을 처리한다.
- 최초 삽입: 인스턴스가 현재 키의 최초 삽입자라면, 임시 목록에 해시 슬롯 디스크립터 항목을 생성한다.
- 카운트 업데이트: 최초가 아니라면, 해시 맵에서 해당 키의 인스턴스 카운트를 증가시킨다.
- 해시 배치 기록: 최초 삽입 여부에 관계없이 해시 배치(Hashed Batch)를 생성하여, 해시 맵 내 드로우 콜 위치와 드로우 콜 내 인스턴스 오프셋을 기록한다. (Figure 1.16)

- 전위 합 계산과 파라미터 쓰기 (두 번째 처리)
- 전위 합 할당:
- 스레드 그룹 할당: 각 스레드가 여러 해시 맵 슬롯을 처리하며, 할당해야 할 드로우 콜과 InstanceInfos 수를 집계한다.
- 전위 합 계산: 단일 스레드 그룹 전위 합(Prefix Sum)으로 각 드로우 콜의 전역 시작 위치를 결정한다.
- 파라미터 쓰기:
- 순환 탐색: 스레드가 다시 담당 해시 슬롯을 순회하며, 전위 합 결과를 활용해 메모리 위치를 결정한다.
- 파라미터 생성: 서브메시의 지오메트리 디스크립터와 해시 맵의 인스턴스 카운트를 기반으로 드로우 콜 파라미터를 기록한다.
- 오프셋 기록: 이후 단계를 위해 해시 맵에 각 드로우 콜의 첫 번째 InstanceInfo 오프셋을 저장한다.
- 전위 합 할당:
- 📖 Prefix Sum (전위 합 / 병렬 스캔)이란?→ Prefix sum — Wikipedia | Parallel Prefix Sum — GPU Gems 3, Ch.39
- 입력 배열의 각 원소를 이전 모든 원소의 합으로 대체하는 연산이다. 예: 입력 [3, 1, 4, 1] → Exclusive Scan 결과 [0, 3, 4, 8]. GPU 컴퓨트에서는 수천 개의 병렬 스레드가 공유 버퍼에 쓸 메모리 오프셋을 충돌 없이 할당할 때 핵심적으로 사용된다. 이 시스템에서는 드로우 콜별 인스턴스 수를 집계한 후 전위 합으로 각 드로우 콜의 전역 시작 오프셋을 결정한다.
InstanceInfo 쓰기 (Write InstanceInfos) 패스별 컬링 단계의 마지막 단계는, 렌더링 시 버텍스 및 픽셀 셰이더로 전달될 버퍼에 각 인스턴스에 대한 인스턴스 정보(InstanceInfo)를 기록하는 것이다. (Listing 1.14 참조) 인스턴스 정보에는 월드-뷰-투영 행렬, 관련 속성, 통합 지오메트리 버퍼(1.4.3절 참조), 통합 상수 버퍼(1.5.3절 참조), 그리고 바인드리스 머티리얼 테이블(1.5.2절 참조)에 대한 오프셋이 포함된다. 인스턴스의 InstanceInfo 인덱스는 버텍스 셰이더에 전달되는 인스턴스 ID와 일치해야 한다. 우리는 해시 맵에서 드로우 콜의 첫 번째 InstanceInfo 오프셋을 읽고, 해시 배치에 기록된 드로우 콜 내 인스턴스 오프셋을 더하여 이 인덱스를 계산한다.
// Listing 1.14.
// InstanceInfos 형식: vertexInfo는 버텍스 셰이더에서 버텍스를 가져오는 데
// 필요한 데이터를 패킹하고, materialOffsets는 픽셀 셰이더에서
// 바인드리스 머티리얼(1.5.2절)과 상수 테이블을 가져오는 오프셋을 패킹한다.
// InstanceInfo 배열
ByteAddressBuffer InstanceInfos;
struct InstanceInfo
{
uint instanceAndLODFade; // LOD 및 페이드 플래그
uint vertexInfo; // 버텍스 데이터 시작점, 형식, 보폭
uint instanceMaterialInfo; // 머티리얼 플래그
uint materialOffsets; // Texture2DOffset 및 ConstantOffset
float4x4 worldViewProj; // 트랜스폼
}
1.4.3 클러스터 컬링
Anvil 엔진에서 모든 메시는 기본적으로 클러스터(Cluster) 단위로 분할되며, 각 클러스터는 64개의 버텍스를 포함한다. (Figure 1.17) 지오메트리의 버텍스와 인덱스는 통합 버퍼(Unified Buffers) 에 저장되며, 모든 버텍스 데이터가 동일한 버퍼에 위치한다. 버텍스 셰이더는 버텍스 ID(Vertex ID) 를 기반으로 버텍스 데이터를 수동으로 가져와야 한다. 이는 API 의미의 버텍스 버퍼가 아닌, 공유 바이트 버퍼다.

실제 멀티 드로우 콜을 발행하기 전에 클러스터와 트라이앵글 컬링을 수행할 수 있다. 이 단계들은 선택 사항이며, 각 렌더 패스(예: Z프리 패스, GBuffer 패스)에서 유익한 경우 활성화할 수 있다(주로 데이터와 렌더 패스 유형에 따라 달라진다).
클러스터별 컬링은 두 단계로 나뉜다: 뷰 프러스텀 컬링 과 오클루전 컬링. 모두 컴퓨트 셰이더에서 실행된다. (Figure 1.18) 각 스레드는 하나의 클러스터를 처리한다. 각 클러스터에 대해, InstanceInfo 버퍼(1.4.2절 참조)에서 해당 월드-뷰-투영 행렬과 바운딩 박스 중심 및 반지름을 가져온다. 이 데이터를 사용해 컬링을 위한 투영 바운딩 박스를 계산한다.

뷰 프러스텀 컬링: 각 클러스터에 대해 컬링 흐름은 두 단계로 나뉜다:
- 바운딩 박스 투영: 바운딩 박스를 정규화 장치 좌표(NDC) 공간으로 투영한다.
- NDC 공간 컬링: NDC 공간 내에서 뷰 프러스텀 컬링 판정을 수행한다. (Listing 1.15)
- 📖 NDC (Normalized Device Coordinates, 정규화 장치 좌표)란?→ Coordinate Transformations — Khronos OpenGL Wiki | Clip coordinates — Wikipedia
- 모델 → 월드 → 뷰 → 클립 공간 변환 후 원근 나누기(w 나누기) 를 거쳐 얻는 좌표 공간이다. OpenGL 기준 X·Y·Z 모두 −1~1 범위이며, DirectX 기준 Z는 0~1 범위다. 래스터화 직전 단계에 해당하며, HZB 컬링처럼 화면 공간에서 빠른 판정을 수행할 때 이 좌표계를 기준으로 사용한다.
// Listing 1.15. 클러스터별 단순 뷰 프러스텀 컬링 셰이더 코드.
// 뷰 프러스텀 컬링: 바운딩 박스를 NDC 공간으로 투영한 후 컬링 수행
float3 minAABB = float3(1.0f, 1.0f, 1.0f); // NDC 공간 최대값으로 초기화
float3 maxAABB = float3(-1.0f, -1.0f, 0.0f); // NDC 공간 최소값으로 초기화 (Z축 반전 후 범위 [0,1])
// 바운딩 박스의 8개 꼭짓점(±1) 순회
for (float z = -1; z <= 1; z += 2)
for (float y = -1; y <= 1; y += 2)
for (float x = -1; x <= 1; x += 2)
{
// 1. 동차 공간 [-w, w][-w, w][0, w]으로 투영
float4 posHS = mul(float4(center + halfExtents * float3(x, y, z), 1.0f), worldViewProj);
// 2. 원근 나누기를 통해 NDC 공간 [-1,1][-1,1][0,1]로 변환
float3 posSS = (posHS.w > 0) ? posHS.xyz / posHS.w : float3(0, 0, -1);
// 반전된 Z축 처리 (Z 스케일 바이어스에 따라 조정)
posSS.z = posSS.z * ZScaleBias.x + ZScaleBias.y;
// NDC 바운딩 박스 최소/최대값 업데이트
minAABB = min(posSS, minAABB);
maxAABB = max(posSS, maxAABB);
}
// 단순화된 뷰 프러스텀 컬링 로직 (Z축 반전 후 범위 [0,1])
bool passed = (
(all(minAABB.xy < 1.0f) && all(maxAABB.xy > -1.0f)) || // XY 방향이 뷰 프러스텀 내에 있음
(minAABB.z <= 0) // Z 방향이 근거리 클리핑 평면 밖에 완전히 있음
);
오클루전 컬링 이 단계는 [Haar 및 Aaltonen 15]와 매우 유사하며, 계층적 Z 버퍼(HZB) [Hill 10, Greene et al. 93]가 필요하다. (Figure 1.19) 구체적인 흐름은 다음과 같다.
- 📖 HZB (Hierarchical Z-Buffer, 계층적 Z 버퍼) & Occlusion Culling이란?→ Z-buffering — Wikipedia | Hi-Z Occlusion Culling — GPU Gems 2, Ch.6
- 깊이 버퍼(Z-Buffer)의 밉맵 체인으로, 각 밉 레벨이 하위 레벨 2×2 텍셀의 최대 깊이값을 저장한다. 클러스터 바운딩 박스의 화면 크기에 맞는 밉 레벨을 샘플링하여, 그 영역 최대 깊이보다 오브젝트 최소 깊이가 더 멀면 "완전히 가려짐"으로 판정해 컬링한다(오클루전 컬링). GPU에서 수십만 개의 클러스터를 매우 낮은 비용으로 일괄 처리할 수 있는 핵심 기법이다.
- 깊이 사전 렌더링: 가장 가까운 오클루더의 깊이 정보만 포함하는 깊이 프리 패스 를 렌더링한다. 결과를 512×256 해상도로 다운샘플링한다.
- 깊이 병합: 다운샘플링된 깊이와 이전 프레임 깊이 재투영 결과 를 결합한다.
- 계층 구조 구축: 병합된 깊이 맵에 대해 밉맵을 생성하는데, 각 레벨에서 4개 텍셀의 최대값을 취해 다음 레벨을 생성하고, 최종적으로 GPU 컬링에 사용할 깊이 계층 구조를 형성한다.

오클루전 컬링 단계에서 수행하는 연산:
- 텍셀 이웃 샘플링: 클러스터 바운딩 박스의 화면 영역이 정확히 4개 텍셀로 매핑되도록, 해당 밉 레벨에서 2×2 텍셀 이웃을 가져온다.
- 깊이 비교: 이 4개 텍셀의 최대 깊이값(Max Z)을 추출하고, 현재 바운딩 박스의 최소 깊이값(Min Depth) 과 비교한다.
- 오클루전 판정: 바운딩 박스 최소 깊이 > 텍셀 최대 깊이 → 가려진 것으로 판정, 해당 클러스터를 컬링한다.
// 뷰포트 재스케일: NDC 좌표 [-1,1]을 텍스처 좌표 [0,1]로 매핑
float2 minUV = float2(minAABB.x, maxAABB.y) * float2(0.5f, -0.5f) + 0.5f; // 좌상단 UV
float2 maxUV = float2(maxAABB.x, minAABB.y) * float2(0.5f, -0.5f) + 0.5f; // 우하단 UV
// UV 좌표를 HZB 텍스처의 픽셀 좌표로 변환 (HZB 너비/높이 기준)
float2 minHZBPixel = minUV.xy * GetHZBWidthHeightMips().xy; // 최소 픽셀 좌표
float2 maxHZBPixel = maxUV.xy * GetHZBWidthHeightMips().xy; // 최대 픽셀 좌표
// 바운딩 박스가 2x2 텍셀 영역으로 투영되도록 밉 레벨 계산
float2 texelSize = maxHZBPixel - minHZBPixel; // 화면 공간에서의 픽셀 범위
float mipValue = ceil(log2(max(texelSize.x, texelSize.y))); // 필요한 밉 레벨 계산
float mipScale = rcp(exp2(mipValue)); // 밉 레벨의 스케일 팩터
// 정확히 2x2 텍셀에 일치하도록 밉 레벨 조정
float2 minMip = minHZBPixel * mipScale; // 스케일된 최소 픽셀 좌표
float2 maxMip = maxHZBPixel * mipScale; // 스케일된 최대 픽셀 좌표
if (all(floor(minMip) == floor(maxMip))) // 바운딩 박스 투영이 동일 텍셀 내에 있으면
{
mipValue -= 1; // 정밀도를 높이기 위해 밉 레벨 다운그레이드
minMip *= 2; // 스케일된 좌표 조정
maxMip *= 2;
}
// 요청한 밉 레벨의 유효성 검사
if (mipValue < GetHZBWidthHeightMips().z) // GetHZBWidthHeightMips().z = 최대 밉 레벨
{
// 2x2 텍셀 이웃의 오프셋 계산
uint xOffset = (floor(minMip.x) == floor(maxMip.x)) ? 0 : 1; // X 방향 오프셋 필요 여부
uint yOffset = (floor(minMip.y) == floor(maxMip.y)) ? 0 : 1; // Y 방향 오프셋 필요 여부
float4 maxDepthMask4 = float4(1, xOffset, yOffset, xOffset * yOffset); // 이웃 샘플링 마스크
// 지정된 밉 레벨에서 HZB 텍스처의 2x2 이웃 샘플링
float4 maxDepth4 = float4(
GetHZBTexture().SampleLevel(sampler_PointClamp, minUV.xy, mipValue, int2(0, 0)), // 좌상단
GetHZBTexture().SampleLevel(sampler_PointClamp, minUV.xy, mipValue, int2(1, 0)), // 우상단
GetHZBTexture().SampleLevel(sampler_PointClamp, minUV.xy, mipValue, int2(0, 1)), // 좌하단
GetHZBTexture().SampleLevel(sampler_PointClamp, minUV.xy, mipValue, int2(1, 1)) // 우하단
);
maxDepth4 = max(1 - maxDepthMask4, maxDepth4); // 유효하지 않은 샘플 영역 마스킹 (1.0으로 채움)
// 이웃 내 최대 깊이값 계산 (HZB는 역방향 깊이 저장, 1.0이 가장 가까움)
float maxDepth = max(max(maxDepth4.x, maxDepth4.y), max(maxDepth4.z, maxDepth4.w));
// 보수적 깊이 테스트: 바운딩 박스 최소 깊이 < HZB 최대 깊이 → 가시적 (가려지지 않음)
passed = (minAABB.z < maxDepth);
}
독자 질문에 대한 보충 설명: 바운딩 박스의 컬링 판정 시, 왜 밉 레벨에서 2×2 텍셀 이웃을 선택하고 바운딩 박스의 투영 영역이 정확히 4개 텍셀로 매핑되도록 보장하며, 4개 텍셀 중 최대값과 비교하는가? 더 높은 밉 레벨의 1×1 영역과 직접 비교하면 안 되는가?
우선 HZB 생성 규칙을 이해해야 한다. 각 레벨은 4개 텍셀의 최대값을 취해 다음 레벨을 생성한다.
따라서 각 밉 레벨이 저장하는 값은 상위 레벨에서 매핑된 2×2의 깊이 최대값이다. 하지만 인접한 두 개의 2×2 블록 사이에서 형성되는 2×2 블록의 값은 보장할 수 없다. 따라서 바운딩 박스의 투영이 이런 영역에 걸리면, 해당 레벨의 밉 맵에서 찾아 판정해야 한다. 더 쉽게 이해하기 위해 다음 그림을 그렸다:
가정: HZB가 Mip Level 0과 Mip Level 1을 생성했고, 지오메트리 바운딩 박스의 투영이 중간 영역에 걸려 Level 0의 중앙 약간 좌상단에 해당하는 영역에 매핑된다고 하자.
이때 Level 0에서 해당 2×2 이웃의 깊이를 샘플링하고 최대값을 찾은 후, 바운딩 박스의 최소 깊이와 2×2 영역의 최대 깊이를 비교하면 즉시 해당 바운딩 박스가 가려졌음을 판정할 수 있으며, 따라서 이 클러스터는 컬링될 수 있다.
반면 더 낮은 레벨의 1×1 영역으로 비교하면, 중심 샘플 포인트 기준으로 중앙 약간 좌상단의 5(최근접 이웃) 또는 4.x(선형 보간)를 샘플링하게 되어 가시적일 수 있음, 컬링 안 함 으로 판정된다. 고레벨에서 2×2 영역 픽셀을 샘플링해도 최종 계산 최대 깊이는 5가 되므로 마찬가지로 가시적일 수 있음, 컬링 안 함 으로 판정된다.

따라서 저레벨 2×2 이웃의 최대 깊이는 고레벨 1×1 영역과 동일하지 않으며 직접 매핑할 수 없다. 오직 해당 레벨의 2×2 이웃만이 올바른 판정 결과를 계산할 수 있다. 이것이 원문에서 "클러스터 바운딩 박스의 화면 영역이 해당 레벨의 4개 텍셀에 정확히 매핑되도록 보장" 을 강조하는 이유다.
또한 픽셀별 비교를 할 필요가 없는데, 이는 보수적 추정의 컬링이기 때문이다. 오브젝트의 가시 여부를 빠르게 확인하기만 하면 된다.
1.4.4 트라이앵글 컬링
트라이앵글 컬링은 세 단계로 나뉜다 — 제로 면적(퇴화 트라이앵글) & 후면 컬링, 뷰 프러스텀 컬링, 소형 트라이앵글 컬링 — 모두 컴퓨트 셰이더에서 실행된다. (Figure 1.20) 각 스레드는 하나의 트라이앵글을 처리한다. 각 트라이앵글에 대해, InstanceInfos 버퍼(1.4.2절)에서 해당 월드-뷰-투영 행렬을 다시 가져오고, 컬링 전에 버텍스를 변환한다. (Listing 1.17)

// Listing 1.17: 통합 지오메트리 버퍼에서 버텍스를 가져와 동차 공간으로 변환 (원근 나누기 미수행)
float4 vtx[3];
for (uint i = 0; i < 3; i++)
{
// 통합 지오메트리 버퍼에서 버텍스 위치 가져오기 (인덱스, 시작 오프셋, 보폭 기반)
float3 posOS = FetchVertexPosition(index[i], vertexStart, vertexStride);
// 월드-뷰-투영 행렬을 적용해 동차 공간으로 변환
vtx[i] = mul(float4(posOS, 1), worldViewProj);
}
제로 면적 및 후면 컬링 (첫 번째)
2D 동차 행렬의 행렬식(determinant)을 계산하여 컬링한다. ([Wihlidal 17] 및 [Olano and Greer 97] 참조) (Listing 1.18)
- 후면 컬링: 행렬식 det > 0 → 트라이앵글이 앞면을 향함.
- 제로 면적 컬링: 행렬식 det = 0 → 트라이앵글 면적이 0 (버텍스가 공선).
// Listing 1.18: 제로 면적 및 후면 컬링 셰이더 코드 (2D 동차 행렬 행렬식 테스트)
float det = determinant(float3x3(vtx[0].xyw, vtx[1].xyw, vtx[2].xyw));
passed = (det > 0) || (twoSided && det != 0); // twoSided는 양면 지오메트리의 특수 케이스 처리
뷰 프러스텀 컬링 (두 번째)
이 단계(Listing 1.19)는 클러스터 레벨 뷰 프러스텀 컬링(Listing 1.15)과 유사하지만, 2D 화면 공간만을 처리한다.
// Listing 1.19: 트라이앵글별 뷰 프러스텀 컬링 셰이더 코드
float2 minAABB = 1.0f; // 화면 공간 최대값 [1,1]로 초기화
float2 maxAABB = 0.0f; // 화면 공간 최소값 [0,0]으로 초기화
// 트라이앵글의 세 버텍스 순회
for (uint i = 0; i < 3; i++)
{
// 원근 나누기 + 뷰포트 재스케일: 동차 좌표를 화면 공간 [0,1][0,1]으로 변환
float2 posSS = (vtx[i].xy / vtx[i].w) * 0.5f + 0.5f;
// 화면 공간 바운딩 박스 범위 업데이트
minAABB = min(minAABB, posSS);
maxAABB = max(maxAABB, posSS);
}
// 단순 뷰 프러스텀 컬링: 바운딩 박스가 뷰포트 [0,1][0,1] 내에 있는지 판정
passed = all(minAABB < 1.0f) && all(maxAABB > 0.0f);
소형 트라이앵글 컬링 (세 번째)
소형 트라이앵글을 컬링하기 위해 [Wihlidal 17]과 동일한 방법을 사용한다: 트라이앵글 바운딩 박스의 최소/최대값을 가장 가까운 픽셀 모서리로 정렬하고 (Figure 1.21), 정렬된 좌표가 픽셀 중심을 덮는지 테스트하여 컬링 여부를 판정한다. (Listing 1.20)
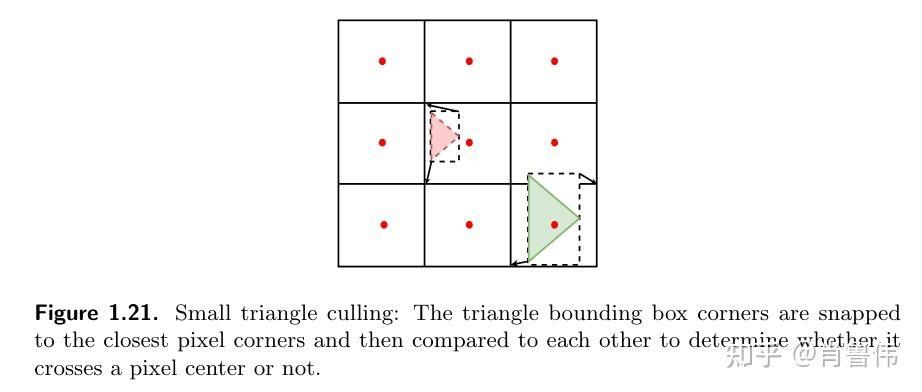
// Listing 1.20: 소형 트라이앵글 컬링 셰이더 코드
minAABB *= GetScreenWidthHeight(); // 화면 공간 좌표 → 픽셀 좌표
maxAABB *= GetScreenWidthHeight();
passed = !any(round(minAABB) == round(maxAABB)); // 반올림 후 바운딩 박스가 픽셀 중심을 덮지 않으면 → 컬링
인스턴싱 및 인덱스 버퍼 컴팩션 (Instancing and Index Buffer Compaction) 클러스터 및 트라이앵글 컬링이 활성화되면, 이 연산들은 인스턴스 레벨의 렌더 가능 지오메트리에 영향을 미친다. 컬링 단계가 인스턴싱 메커니즘을 망가뜨리기 때문에, 더 이상 원본 인덱스 버퍼를 그대로 사용할 수 없다. 대신 각 인스턴스의 가시 트라이앵글 인덱스를 저장하는 새로운 컴팩트 인덱스 버퍼를 출력하며, 구현 방식은 [Haar 및 Aaltonen 15]에 설명된 것과 유사하다. 이것이 트라이앵글 컬링 컴퓨트 태스크의 마지막 단계이며, 각 스레드는 새 인덱스 버퍼에서 자신의 쓰기 위치를 계산하고 컬링 테스트를 통과하면 트라이앵글 인덱스를 기록한다. 동일한 이유로 DrawBuffer(1.6절 참조)도 업데이트해야 하는데, ExecuteIndirect에 추가적인 드로우 엔트리 파라미터를 제공하기 위해서다. 같은 배치 내 인스턴스들이 가시 지오메트리가 다를 수 있어 여러 DrawIndexedInstanced 호출로 분할되어야 하기 때문이다. 이 새 드로우 엔트리들의 인덱스에는 인스턴스 ID가 임베딩되어 있어 InstanceInfo 파라미터(1.4.2절)에서 원본 데이터를 가져와 렌더링 시 지오메트리와 리소스에 올바르게 접근할 수 있다.
1.5 바인드리스 머티리얼 관리
1.5.1 전체 설계
우리의 머티리얼은 데이터 드리븐 방식의 노드 셰이더 시스템에 의존한다. (Figure 1.22) 최종 셰이더 코드를 출력하기 위해, 셰이더 그래프(Shader Graph)가 파싱·처리된 후 생성된 코드가 범용 머티리얼 셰이더 템플릿에 삽입된다. 이 템플릿은 버텍스 셰이더와 픽셀 셰이더로 구성된다. 두 셰이더 모두 필수적인 헤더 및 테일 코드를 포함하는데, 이 코드는 셰이더 그래프에 속하지 않지만 머티리얼 및 메시 속성(예: 디퍼드 렌더링, 포워드 렌더링, TAA 지터, 버텍스 포맷 등)에 의존한다.

1.5.2 바인드리스 디스크립터 테이블
1.3절에서 설명한 것처럼, GPU 드리븐 파이프라인에서 데이터베이스 테이블로 씬을 표현한다 (아래 참조).

씬 및 그 관계를 기술하는 데이터베이스 테이블 (1.2절)
머티리얼 바인드리스 테이블 은 한 프레임을 렌더링하는 데 필요한 모든 텍스처 리소스(2D, 3D, 큐브맵)를 포함한다. 이 테이블은 32K 항목을 포함하는 통합 리소스 디스크립터 배열이다. 세 가지 리소스 타입 모두 에일리어싱(aliasing) 메커니즘을 통해 동일한 배열에 저장되지만, 실제 3D 텍스처와 큐브맵은 상대적으로 더 작은 범위를 차지한다(실제 사용량이 적으므로). 구체적인 선언은 아래와 같다. (Listing 1.21)
// Listing 1.21: SIG에서 바인드리스 리소스 배열 선언
// (Texture2D, Texture3D, TextureCube 항목은 에일리어싱을 통해 공유 저장됨)
ShaderInputGroup MaterialBindless
<Bindless; ForceAliasingOfTextures>
{
Texture2D<float4> textures; <BindlessMaxCount = 32768>
Texture3D<float4> textures3D; <BindlessMaxCount = 32>
TextureCube<float4> texturesCube; <BindlessMaxCount = 32>
};
메시가 로드되어 씬에 추가되면, 바인드리스 머티리얼 테이블에서 해당 머티리얼 디스크립터의 할당 또는 업데이트가 트리거된다. (Figure 1.24) 모든 필요한 디스크립터가 이 테이블로 복사된다. 이후 해당 MaterialInstance 테이블 항목은 Texture2DOffset과 Texture2DCount 필드를 통해 이 디스크립터 범위를 참조하여, 렌더링 시 GPU가 올바르게 접근할 수 있게 한다.
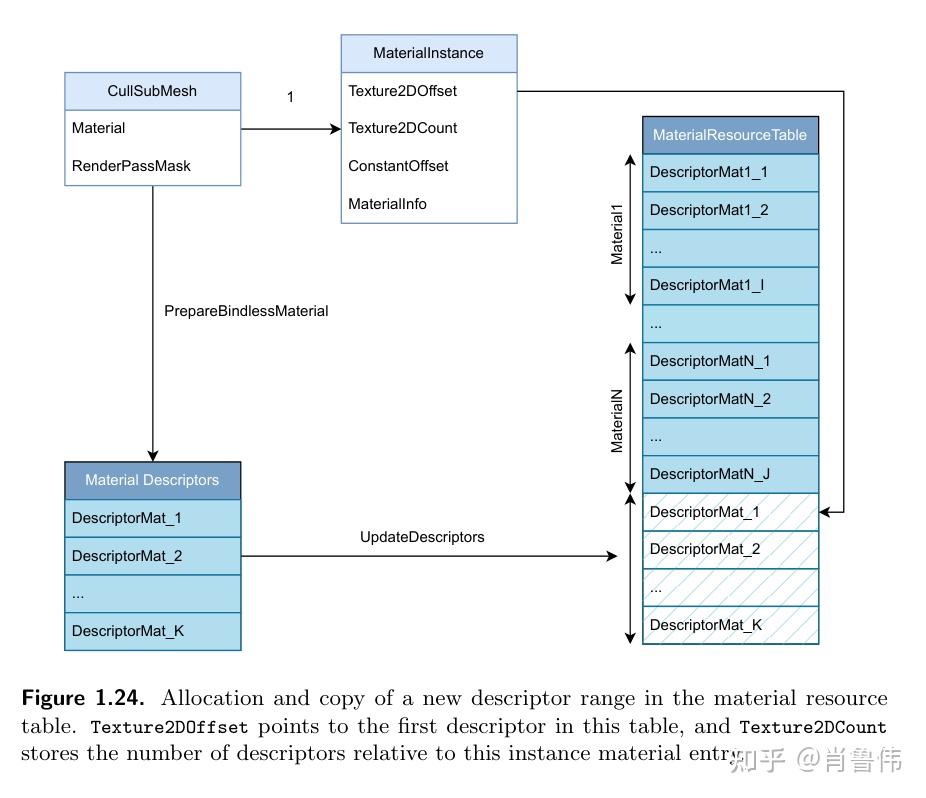
1.5.3 상수 관리
상수 버퍼(Constant buffers)는 대량의 인스턴스 파라미터 데이터를 저장하기에 적합하지 않다. GPU에서 주로 컬링 단계를 수행하기 때문에, 뷰 프러스텀 내 모든 엔티티의 인스턴스 파라미터 데이터를 업로드해야 한다(데이터 양이 매우 클 수 있다). 이를 위해 모든 렌더 패스가 공유하는 단일 바이트 버퍼(single-byte buffer) (Figure 1.25)를 사용하여 모든 인스턴스의 셰이더 파라미터를 저장한다. 할당 및 업데이트 메커니즘은 1.5.2절에서 설명한 바인드리스 머티리얼 디스크립터 테이블과 거의 동일하다.
렌더링 전에, 가시 인스턴스들의 Texture2DOffset과 ConstantOffset을 해당 MaterialInstance에서 가져와 uint materialOffsets 필드로 패킹하여 InstanceInfos에 저장한다. (1.4.2절 참조)

1.6 렌더링
렌더링 시, 컬링을 통과한 각 렌더 배치(1.3.1절)에 대해 다음 연산을 수행한다:
- 파이프라인 상태 설정: 올바른 파이프라인 상태 오브젝트(PSO) 바인딩
- 리소스 바인딩: 통합 지오메트리 버퍼 및 인덱스 버퍼(1.4.3절), 바인드리스 테이블 및 상수 테이블(1.5절)
- 간접 드로우 실행: ExecuteIndirect를 통해 일련의 DrawIndexedInstanced 호출 발행
모든 필요한 드로우 파라미터는 DrawBuffer에 저장되며, 이 버퍼의 데이터는 GPU 컬링 단계(1.4절)에서 채워진다. 이 버퍼는 드로우 카운트(draw counts)와 드로우 인자(draw arguments)를 모두 저장한다. (Figure 1.26)

1.6.1 버텍스 셰이더
렌더링 시, 버텍스 셰이더는 instance ID를 통해 해당 InstanceInfos 항목을 가져온다(1.4.2절 참조). 그런 다음 필요한 속성(버텍스 데이터 시작 위치, 포맷, 보폭)을 언패킹하고, 마찬가지로 instance ID를 사용해 통합 지오메트리 버퍼에서 버텍스 데이터를 수동으로 가져온다. (Listing 1.22)
// Listing 1.22: 버텍스 ID, 시작 위치, 보폭을 이용해 통합 지오메트리 버퍼에서 버텍스 데이터 가져오기
VS_INPUT FetchVertices(
in uint vertexStart, // 버텍스 데이터 시작 위치
in uint vertexFormat, // 버텍스 포맷
in uint vertexStride, // 버텍스 보폭
in uint vertexID // 버텍스 ID
)
{
uint vertexOffset = vertexStart + vertexStride * vertexID;
VS_INPUT output = (VS_INPUT)0;
output.m_Position = ToSHORT4(FETCH2(getClusterVertexDataStatic(), vertexOffset)); // 위치 읽기 (float2 → short4)
output.m_Normal = ToUBYTE4(FETCH1(getClusterVertexDataStatic(), vertexOffset)); // 법선 읽기 (float1 → ubyte4)
// ... 기타 버텍스 속성 (UV, 탄젠트 등)
return output;
}
Texture2DOffset(텍스처 오프셋)과 ConstantOffset(상수 오프셋)도 버텍스 셰이더에서 InstanceInfos를 통해 가져오고, uint 값으로 저장되어 보간 없이(flat) 픽셀 셰이더로 전달된다. (Figure 1.27) 이 두 오프셋은 픽셀 셰이더에서 각각 바인드리스 머티리얼 리소스 테이블(MaterialResourceTable)과 머티리얼 상수 테이블(MaterialConstantTable)에 접근하는 데 사용된다.
주: VS에서 PS로 속성이나 변수를 전달할 때 flat 수식어를 사용하여 보간을 비활성화할 수 있다.

1.6.2 픽셀 셰이더
픽셀 셰이더에서 Texture2DOffset과 ConstantOffset을 언패킹한다. 바인드리스 리소스 관리와 관련된 복잡성은 매크로 로 감춘다. 내부적으로 이 매크로는 텍스처 슬롯 인덱스를 입력으로 받아, 이를 Texture2DOffset에 더하여 bindlessMaterialInfo에서 해당 텍스처 디스크립터에 올바르게 접근한다. (Listings 1.23 및 1.24)
// Listing 1.23: 바인드리스 텍스처 및 상수 접근을 위한 HLSL 매크로
// g_BindlessTex2DOffset은 현재 머티리얼의 바인드리스 머티리얼 테이블 내 텍스처 디스크립터 범위 시작 오프셋 (1.5.2절)
// INDEX는 픽셀 셰이더가 접근하는 텍스처의 상대 인덱스
// g_BindlessConstantOffset은 머티리얼 상수 테이블 내 동일 머티리얼의 상수 범위 시작 위치 (1.5.3절)
static uint g_BindlessTex2DOffset = 0;
static uint g_BindlessConstantOffset = 0;
// 텍스처 접근 전역 매크로
#define MATERIAL_TEX2DALIAS(INDEX, NAME, SAMPLER) \\
Tex2DAndSampler Get##NAME() { \\
return GetTexture2DTypeAndSamplerStateType( \\
Get_MaterialBindless_textures(g_BindlessTex2DOffset + INDEX), \\
s##SAMPLER); \\
}
// 단일 float 상수 접근 전역 매크로
#define MATERIAL_CONSTLOADSCALAR(OFFSET, CONVERSION) \\
CONVERSION(gpuCullingInstanceParams.GetBindlessMaterialConstants().Load( \\
g_BindlessConstantOffset + (OFFSET)*4))
#define MATERIAL_CONSTALIASFLOAT(TYPE, ALIASNAME, OFFSET) \\
TYPE Get##ALIASNAME() { \\
return (TYPE)(MATERIAL_CONSTLOADSCALAR(OFFSET, asfloat)); \\
}
#define MATERIAL_FLOAT(OFFSET, NAME) \\
MATERIAL_CONSTALIASFLOAT(float, NAME, OFFSET)
// Listing 1.24: 셰이더 그래프에서 생성된 픽셀 셰이더 코드
// - 텍스처 및 상수 인덱스는 셰이더 그래프의 HLSL 코드 생성 단계에서 생성됨
MATERIAL_TEX2DALIAS(0, Layer0Diffuse0, StandardSampler);
MATERIAL_TEX2DALIAS(1, Layer0Normal1, StandardSampler);
MATERIAL_FLOAT(4, Layer0ScaleU1);
MATERIAL_FLOAT(5, Layer0ScaleV2);
#define Layer0Diffuse0 GetLayer0Diffuse0()
#define Layer0Normal1 GetLayer0Normal1()
#define Layer0ScaleU1 GetLayer0ScaleU1()
#define Layer0ScaleV2 GetLayer0ScaleV2()
// 이후 코드 ...
float2 uvScaled = uvDiffuse * float2(Layer0ScaleU1, Layer0ScaleV2);
float4 Layer0Diffuse0_sample = Sample2D(Layer0Diffuse0, uvScaled);
1.7 결과
우리가 GPU 파이프라인이라 불렀음에도, BatchRenderer 의 상당 부분은 여전히 CPU에서 처리된다. (Figure 1.4) 많은 배칭 작업이 각 렌더 패스의 CPU 쪽에서 발생하며, 마지막 인스턴스 컬링만 GPU에서 완료된다.

반면 GPU 인스턴스 렌더러(GPU Instance Renderer) 는 로드 타임에 모든 배칭을 수행하고, 매 프레임·매 패스별 컬링을 결합한다. 컬링도 각 인스턴스 단위에서 수행된 후, 인스턴스가 서로 다른 LOD, 서브메시, 렌더 패스로 분할된다. (Figure 1.5) 또한 바인드리스 머티리얼을 사용하고, GPU에서 동일한 PSO와 지오메트리를 사용하는 모든 메시를 동일한 드로우 콜로 매핑하여 버텍스 셰이딩 성능을 향상하고 빈 드로우 콜을 제거했다.

초기 단계에서 컬링을 매 프레임 컬링과 매 패스 컬링으로 분리하고 둘 다 비동기 큐에 스케줄링하기로 결정했는데, 이는 주로 GPU LOD 관리 와 시간적 블렌딩 로직(temporal blending logic) 때문이었다. 이는 일부 컬링 연산이 중복 실행됨을 의미하기도 한다. 한편으로는 매 패스 컬링 시 더 컴팩트한 바운딩 볼륨(서브메시)을 다룰 수 있어 유리하지만, 다른 한편으로는 현재 병목이 아님에도 불구하고 매 프레임 컬링 단계를 엄격한 최소치로 줄이는 가능성을 탐색하고 싶다.
1.7.1 BatchRenderer 대 GPU Instance Renderer
성능 측면에서, 모든 지오메트리 패스(GPU 및 CPU 모두)에서 상당한 가속을 달성했다. (Table 1.1) 인스턴싱이 밀집된 원거리 지오메트리의 경우, 특정 씬에서 CPU 측 성능 향상이 50배에 달하기도 했다 — 예를 들어, 특정 씬의 CPU 소요 시간이 6.8밀리초에서 0.14밀리초로 단축되었다.

PlayStation 5 기준 측정

Table 1.2. GPU 인스턴스 렌더러(GPUIR) 사용 시 컬링 태스크가 항상 더 빠른 것은 아니지만, 이 태스크들은 이제 프레임 초기 단계에서 비동기 큐를 통해 스케줄링될 수 있다. 테스트 씬에서 카메라 뷰 프러스텀 내 435K 인스턴스 중 98% 가 GPU에서 성공적으로 컬링되었다. (Table 1.3)

1.7.2 《어쌔신 크리드: 미라지》에서의 GPU 인스턴스 렌더러
《어쌔신 크리드: 미라지》 에서는 단일 프레임 내에 컬링을 위해 GPU에 제출되는 인스턴스 수가 100만 개를 초과하지만, 실제로 렌더링되는 인스턴스 수는 수만 개에 불과하다. (Table 1.4 및 Table 1.5) 이 절에서는 게임의 일반적인 프레임에서의 GPU 인스턴스 렌더러 성능 결과를 보여준다. (Figure 1.29)



1.8 결론 및 향후 작업
CPU는 《어쌔신 크리드》 시리즈 게임의 주요 병목이 되어왔다. 본 글에서는 새로운 GPU 드리븐 파이프라인인 GPU 인스턴스 렌더러(GPU Instance Renderer) 를 구현함으로써 이 병목을 줄이려는 노력을 소개했다. 주요 목표는 이전 파이프라인(BatchRenderer)의 CPU 비용을 절감하는 것이었다.
우리는 로드 타임에 인스턴스를 배칭하고, 바인드리스 리소스(1.5절)를 도입해 배칭을 최적화하며, 복잡한 씬 기술과 CPU-GPU 간 데이터 복제를 지원하는 새로운 도구 라이브러리인 데이터베이스(1.2절)를 활용함으로써 더 많은 작업을 GPU로 이전했고, 이를 통해 목표를 달성했다.
주요 목표는 GPU 실행 시간 최적화가 아니었음에도, 더 나은 배칭, 컬링 최적화, 비동기 컴퓨트 활용을 통해 상당한 개선을 이루었다. 1.7절에서 확인할 수 있듯이, 이 새로운 파이프라인은 CPU와 GPU 모두에서 현저한 성과를 가져왔다.
클러스터 및 트라이앵글 컬링의 경우, 씬과 렌더 패스에 따라 효과가 다를 수 있기 때문에 이 버전에서는 선택 사항으로 설정했다. 이 기능은 GPUIR 개발의 후기 단계에 도입되었으며, 메시 셰이더(Mesh Shader) 로 이전함으로써 성능을 크게 향상시킬 수 있다고 판단한다. 이를 통해 추가 버퍼(1.4.4절)의 필요성을 제거하고, 인스턴싱을 더 잘 처리하며, 전체 프로세스를 단순화할 수 있다. 《어쌔신 크리드: 미라지》에서 이를 구현하지 못한 주요 이유는, 해당 게임이 크로스 제너레이션 타이틀이어서 메시 셰이더가 PlayStation 4와 Xbox One을 포함한 모든 대상 플랫폼에서 지원되지 않기 때문이다.
향후에는 [Karis 21]에서 소개된 버추얼 지오메트리와 유사하게 클러스터 계층 구조로 구성된 연속적 세부 레벨(Continuous LOD) 을 지원하도록 GPU 인스턴스 렌더러를 확장할 계획이다. 또한 워크 그래프(Work Graphs) 를 탐색하여, 파이프라인 개선 및 단순화에 도움이 되는지 평가할 예정이다. 단, 현재 이 API는 우리가 개발하는 모든 주요 플랫폼에서 제공되지 않는다는 점을 주의해야 한다.
주석: Work Graph — GPU 워크플로를 그래프 구조로 표현하여 동적 작업 생성과 의존성 관리를 가능하게 하는 새로운 API 기능.
감사의 말
GPU 인스턴스 렌더러 구현에 도움을 주신 Ulrich Haar께 감사드린다.
Francis Boivin, Michel Gaudreault, Alexandre Blaquière, Daryl Teo, Mykola Naichuck, Lionel Berenguier, Jack Minnetian, Frederic Matz, Sylvain Marleau, Kaori Kato, Luc Poirier, Christian Desautels, Robert Foriel, Danny Oros, 그리고 《어쌔신 크리드: 미라지》 전체 팀과 Anvil 팀의 지원과 기여에 감사드린다.
또한 각각 [Haar and Aaltonen 15], [Rodrigues 17], [Wihlidal 17], [Karis 21]에서의 연구를 진행한 Sebastian Aaltonen, Tiago Rodrigues, Graham Wihlidal, Brian Karis께, 심도 있는 논의를 함께 해준 Michel Bouchard께, 편집 작업을 담당해주신 Wolfgang Engel께, 그리고 Manon Gomes, Joel Morange, Marc-Alexis Côté, Florence Baccard의 지원에 감사드린다.
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [번역] RenderDoc 활용법 (0) | 2026.03.06 |
|---|---|
| [번역] 어쌔신 크리드 미라지에서의 뉴럴 텍스처 압축 적용기 (0) | 2026.02.27 |
| [번역] 고성능 지형 텍스처 반복감 개선 (0) | 2026.02.20 |
| [번역] 섀도우맵 압축 테크닉 (0) | 2026.02.20 |
| [번역] 뉴럴 렌더링 탐험기 (0) | 2026.02.19 |