
현대 비디오 게임은 어쌔신 크리드와 같은 AAA 타이틀에서 기대되는 시각적 품질과 선명도를 구현하기 위해 고해상도 물리 기반 렌더링(PBR) 텍스처에 크게 의존한다. 이러한 고해상도 에셋은 디스크 및 GPU 메모리 사용량의 상당 부분(디스크 용량의 약 60%)을 차지하며, 4K 텍스처에 대한 수요 증가로 전체 게임 용량이 빠르게 커지고 있다. 널리 사용되는 텍스처 압축 포맷은 이러한 규모에서 더 이상 충분하지 않다. 각 텍스처 레이어를 독립적으로 처리하기 때문에 머티리얼 채널 간에 존재하는 상관관계를 활용하지 못하기 때문이다. 이 한계를 해결하기 위해, 머신 러닝을 활용해 채널 간 구조를 분석하고 실시간으로 완전한 PBR 머티리얼을 재구성하는 뉴럴 머티리얼 텍스처 압축 기술을 개발했다. 이를 통해 시각적 품질을 희생하지 않고도 더 높은 압축률(어쌔신 크리드 미라지에서 약 30%)을 달성할 수 있었다.
뉴럴 텍스처 압축 (Neural Texture Compression)

Figure 1
뉴럴 텍스처 압축의 핵심 아이디어는 간단하다. 기존의 레이어별 PBR 텍스처 세트를, 모든 머티리얼 채널에 걸쳐 공유되는 잠재 표현(latent representation) 과 샘플링 시점에 평가되는 소형 디코더 네트워크로 대체하는 것이다(Figure 1). 잠재 표현은 2D 텍스처 형태로 저장되며, 디코더는 셰이더 내에서 머티리얼 속성(알베도, 노멀, 러프니스/메탈니스/AO 등)을 재구성한다.
뉴럴 텍스처 인코딩 (Neural Texture Encoding)
핵심 설계 제약 조건 중 하나는, 잠재 텍스처를 표준 BC 압축 텍스처[1]로 내보낸다는 점이다. 이를 통해 렌더러가 기대하는 랜덤 액세스, 밉매핑, 이방성 필터링, 기존 스트리밍 및 잔류 시스템과의 호환성 등 모든 특성이 보존된다. 엔진 관점에서 뉴럴 텍스처는 일반 BC 텍스처처럼 동작하며, 셰이딩 단계에서 경량 디코드 단계만 추가되므로 통합이 간단하다. 그러나 학습된 잠재 공간을 단순히 압축하는 것만으로는 불충분하다. BC 압축 아티팩트가 런타임에 뉴럴 디코더에 의해 증폭될 수 있기 때문이다.

Figure 2
학습된 표현이 런타임 동작을 정확히 반영하도록, 학습 과정에서 BC 압축을 명시적으로 모델링한다(Figure 2). BC 디코딩은 학습 그래프 내에서 직접 시뮬레이션된다. 그 결과 네트워크는 학습 후 BC로 근사될 비압축 뉴럴 피처가 아닌, 렌더러가 실제로 샘플링할 정확한 신호를 기준으로 최적화된다. 필터링도 동일한 방식으로 처리된다. 각 학습 샘플에는 연속적인 LOD(Level of Detail) 값이 포함되며, 감독 신호는 GPU가 적용하는 것과 동일한 삼선형(trilinear) 또는 이중삼차(bicubic) 필터링 동작을 사용해 생성된다. 이를 통해 디코더는 필터링 연산을 암묵적으로 학습하게 된다. 런타임에서 렌더러는 하드웨어 샘플러를 사용해 잠재 BC 텍스처를 한 번만 필터링 방식으로 페치하고, 디코더는 이 필터링된 피처로부터 머티리얼 채널을 직접 재구성한다. 결과물은 밉 전환 타이밍 또는 서브픽셀 모션 하에서도 추가적인 포스트 필터링 패스 없이 안정적으로 유지된다.
런타임 재구성 (Runtime Reconstruction)
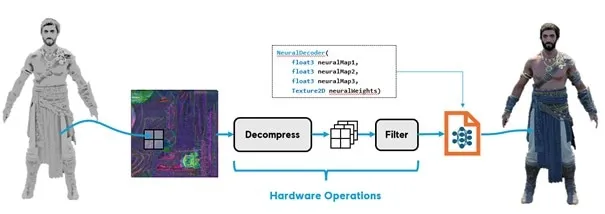
Figure 3
런타임에서 잠재 BC 텍스처는 표준 텍스처 파이프라인을 통해 샘플링된다. 필터링된 잠재 피처는 단일 은닉 레이어를 갖는 소형 MLP(다층 퍼셉트론)를 통과하며, 이 MLP는 픽셀 또는 G-버퍼 셰이더에 내장되어 머티리얼 속성을 재구성한다. 디코더 파라미터는 소형 상수 버퍼 또는 텍스처에 저장되며, 재구성 과정은 소수의 행렬 곱셈으로 구성된다. 표현 자체가 BC 네이티브이므로 렌더링 파이프라인으로의 통합은 비교적 직관적이다.
AC 미라지에서의 뉴럴 텍스처 압축 적용
어쌔신 크리드 미라지 에 실제 적용하기 위해서는 뉴럴 텍스처 압축을 엔진의 기존 텍스처 인프라와 완전히 정렬하는 추가 작업이 필요했다. 특히 해당 기술이 기존 텍스처와 동일한 스트리밍 규칙 및 밉 스킵 정책을 따르도록 업데이트하여, 다양한 플랫폼에서 올바르게 동작함을 보장했다. 또한 잠재 표현에 사용되는 저장 포맷도 수정했다. 원본 논문[1]에서 사용한 BC6 포맷 대신, 인텔 R&D 팀의 논문[2]이 제안한 대로 BC1 포맷을 채택했다.
(역자주: BC1은 RGB 데이터를 블록당 4비트로 압축하는 포맷으로, BC6H(블록당 8비트)보다 메모리 효율이 2배 높다. 인텔 연구팀은 학습된 잠재 공간이 자연 이미지보다 구조화되어 있어, 낮은 비트레이트에서도 뉴럴 디코더가 효과적으로 복원할 수 있음을 실험적으로 입증했다. 또한 BC1의 협력 벡터(cooperative vectors) 구조를 활용해 하드웨어 가속 디코딩을 최적화하는 방법도 제시했다.)
논문은 압축 효율이 최우선 제약 조건일 때 BC1이 학습된 잠재 표현에 더 적합함을 보였다. 이러한 조정을 통해, 머티리얼 모델·텍스처 스트리밍 시스템·런타임 샘플링 코드를 변경하지 않고도 엔진에서 원본 PBR 텍스처 세트를 직접 내보내 뉴럴 압축 파이프라인으로 처리할 수 있게 되었다.
뉴럴 텍스처 압축은 고해상도 학습 타겟으로부터 더 큰 효과를 얻는다. 그러나 실제 프로덕션 환경에서는 고품질 레퍼런스 텍스처를 항상 확보할 수 있는 것이 아니다. 이를 처리하기 위해 자동 머티리얼 업스케일링 단계[3]를 통합했다. 이 단계는 진정한 고품질 레퍼런스가 없는 경우, 가용한 게임 해상도 텍스처로부터 더 높은 해상도의 학습 타겟을 합성한다. 업스케일된 신호는 학습 감독에 사용되어, 네트워크가 더 깔끔하고 디테일한 재구성을 학습할 수 있게 한다. 결과로 생성된 잠재 표현은 표준 에셋과 동일한 파이프라인을 통해 BC 압축 텍스처로 내보내진다. 이를 통해 수작업으로 고해상도 에셋을 제작할 필요가 없어지며, 소스 데이터의 품질이 일정하지 않은 머티리얼 전반에 걸쳐 더 일관된 품질을 보장한다.

Figure 4
자동 업스케일링이 추가됨으로써, 이 시스템은 고품질 소스 데이터가 없는 경우에도 머티리얼 텍스처의 실효 표시 해상도를 높일 수 있는 완전한 워크플로우를 형성한다. 동시에 엔진의 기존 텍스처·스트리밍 인프라와 완전한 호환성을 유지한다.
아래는 표준 텍스처 세트와 뉴럴 텍스처를 비교한 스크린샷이다. 이 예시들에서 뉴럴 텍스처는 시각적 품질을 유지하거나 향상시키면서, 동시에 메모리 사용량을 약 30% 절감했다.

Figure 5

Figure 6

Figure 7
출시된 게임에서는 런타임 성능 제약으로 인해 적용 범위가 제한되었다. 예산 내에서 비용을 유지하기 위해 뉴럴 텍스처 압축은 인스턴스 수가 많고 메모리 압박이 큰 오브젝트에 집중하여 선별적으로 적용되었다. 이를 통해 뉴럴 디코더가 재구성하는 총 픽셀 수를 제한하면서도, 텍스처 메모리를 의미 있게 절감하고 가장 중요한 부분에서 시각적 품질을 유지할 수 있었다.
참고 문헌
[1] Weinreich, Clément, Louis De Oliveira, Antoine Houdard, and Georges Nader. "Real‐Time Neural Materials using Block‐Compressed Features." In Computer Graphics Forum, vol. 43, no. 2. → arXiv:2311.16121
[2] Laurent, Belcour, and Benyoub Anis. "Hardware Accelerated Neural Block Texture Compression with Cooperative Vectors." arXiv preprint arXiv:2506.06040 (2025). → arXiv:2506.06040
[3] Du, Xin, Maoyuan Xu, and Zhi Ying. "MUJICA: Reforming SISR Models for PBR Material Super-Resolution via Cross-Map Attention." arXiv preprint arXiv:2508.09802 (2025). → arXiv:2508.09802
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [FEAT. AI]아티스트는 왜 데이터 스팩 가이드가 존재해도 확인 없이 커밋을 하는가 (3) | 2026.03.09 |
|---|---|
| [번역] RenderDoc 활용법 (0) | 2026.03.06 |
| [번역] GPU-Driven Rendering in Assassin's Creed Mirage (3) | 2026.02.26 |
| [번역] 고성능 지형 텍스처 반복감 개선 (0) | 2026.02.20 |
| [번역] 섀도우맵 압축 테크닉 (0) | 2026.02.20 |