
역자 주.
최근 RDG 를 좀 더 심층적으로 복기하고 있습니다. 뭔가 언리얼엔진 렌더링 부분에서 좀 더 고도화 된 커스터마이징 처리를 하기위해서는 더욱 분명하게 RDG의 재생성, 활용, 사용자화 하는 법 그리고 그것을 관통하여 최적화하는 방안들을 심층적으로 탐색해야한다고 생각했죠. 텐센트로 이직한 옛 동료 그래픽스프로그래머도 10년간 유니티 엔진 수정에 참여하다가 언리얼엔진으로 변경 후 RHI 나 RDG 부분이 매우 귀찮?다고 하더군요. 그리고 마지막 근무지인 바이트덴스 엔진팀에서 함께 개발하던 유니티 엔진을 위한 렌더링 그래프 개발에 대한 아주 약간의 경험도 있었기 때문에 이렇게 저렇게 이 부분들에 대해서 복기해보고자 합니다. 지하철로 출근 하는 많은 개발자들이 쉽고 편히 볼 수 있길 바랍니다. 저 또한 번역 아카이브는 지하철에서 편히 읽어보려고 하는 작업이거든요.
원문
Render Graphs
Why Talking About Render Graphs In 2017 Yuriy O’Donnell, at the time working for Frostbite, presented the Frame Graph at GDC, which is considered the first application of render graph on triple A games. Frame Graph is intended to be a high-level represen
logins.github.io
2017년 당시 프로스트바이트에서 일하던 유리 오도넬은 GDC에서 프레임 그래프를 발표했는데, 이는 트리플 A 게임에 렌더 그래프를 적용한 최초의 사례로 꼽힙니다.
프레임 그래프는 씬을 렌더링하기 위한 각 그래픽 연산을 고수준(High-Level)로 표현하기 위한 것입니다. 또한 이 시스템은 렌더링 리소스의 상당 부분의 수명과 사용량을 완벽하게 제어할 수 있습니다.
결과적으로 모든 렌더링 코드에 대한 정의된 구조뿐만 아니라 자동화된 최적화 리소스 전환, 동기화 펜스 및 메모리 할당과 같은 일련의 이점을 제공합니다.
2021년 현재 렌더 그래프 사용은 트리플A 게임 엔진 개발의 표준으로 자리 잡았습니다. 가장 일반적인 예로는 Unreal Engine의 RDG가 있으며, Ubisoft의 Anvil 엔진의 프레임 그래프와 같은 다른 구현도 있습니다.

FrameGraph: Extensible Rendering Architecture in Frostbite
This talk describes how Frostbite handles rendering architecture challenges that come with having to support a wide variety of games on a single engine. Yuriy describes their new rendering abstraction design, which is based on a graph of all...
www.gdcvault.com
렌더링 그래프 역시 방대하며 때로는 복잡한 시스템이기 때문에 구현된 기능이 많은 대형 엔진을 다룰 때 가장 큰 이점을 얻을 수 있습니다.
취미용이나 인디 프로젝트에서는 많은 최적화를 수동으로 수행해야 하므로 그 잠재력을 모두 발휘하지 못할 수도 있지만, 트리플A 엔진의 작동 방식을 이해하는 것은 언제나 매우 유용할 수 있습니다.
Properties
엔진 렌더링 코드가 렌더 그래프에 의해 지시되면 여러 가지 장점이 있습니다.
우선, 각 렌더링 작업이 단일 방식으로 추상화되어 렌더링 코드를 생성하므로 그래픽 작업의 실행 순서가 훨씬 더 명확해집니다.
이 구조가 명확해지면 디버깅이 훨씬 쉬워지고 리소스 수명이나 렌더 패스 종속성 등을 표시하는 다양한 디스플레이 도구를 구축할 수 있습니다.
이는 곧 개발 시간 단축으로 이어집니다.
또한 리소스 상태 전환 및 사용자에 대한 메모리 할당과 같은 많은 저수준 작업을 숨길 수 있으므로 독립적이고 자동화된 방식으로 이러한 활동을 모두 최적화할 수 있는 공간을 확보할 수 있습니다.
이러한 모든 속성은 플랫폼 종속 코드에 많은 세부 사항과 최적화를 숨길 수 있기 때문에 엔진의 플랫폼 추상화 코드 수준을 높이는 데도 도움이 됩니다.
Resource Barriers 최소화 및 일괄 처리
Direct3D12 및 Vulkan과 같은 차세대 그래픽 API를 사용하면 수행하려는 작업에 따라 리소스 상태와 상대적인 전환을 관리해야 합니다.
렌더 그래프를 사용하면 이러한 작업의 대부분을 프로그래머의 수동 입력 없이 자동으로 처리할 수 있으므로 오류가 줄어들고 코드가 더 깔끔해지며 실제 그래픽 기능 개발에 더 집중할 수 있습니다.
각 렌더 패스마다 프로그래머는 셰이더 입력, 렌더 타깃 및 뎁스 스텐실로 사용할 리소스를 선언합니다(자세한 내용은 컴포지션 및 워크플로 섹션에서 확인할 수 있습니다). 이는 각 패스에 필요한 리소스 전환을 추론할 수 있다는 점에서 큰 장점입니다.
위 이미지는 리소스 사용의 시각적 예를 보여줍니다. 녹색 선은 읽기 작업이고 빨간색 선은 각 렌더링 패스에 대해 서로 다른 리소스에 대한 쓰기 작업입니다.
렌더 그래프에는 이러한 상호 작용에 대한 지식이 있으므로 리소스 전환을 위한 배리어의 배치도 파악할 수 있습니다.
단일 명령 대기열에서 최적의 배리어 구성을 감지하는 것은 매우 간단합니다. 리소스 A가 패스 1에서는 셰이더 리소스로 사용되지만 패스 2에서는 렌더 타깃으로 사용되는 경우, 두 패스 사이에 타깃을 렌더링하기 위한 리소스 전환이 필요합니다. 패스 1과 패스 2 모두 리소스 A를 셰이더 리소스로 사용하는 경우 전환을 수행할 필요가 없습니다.
일반적으로 한 번의 호출로 리소스 전환을 더 많이 그룹화할수록 SDK에 대한 호출이 줄어들고 프로그램 성능이 빨라집니다.
섀도 매핑 알고리즘을 예로 들어 보겠습니다. 깊이 버퍼를 계산하는 그래픽스 패스가 있고, 그 다음에는 깊이 정보를 사용하여 섀도 버퍼를 출력하는 픽셀별 계산 패스가 있으며, 마지막으로 깊이 버퍼와 섀도 버퍼를 모두 입력으로 사용하는 또 다른 그래픽스 패스가 있습니다.
이 경우 뎁스 버퍼와 섀도 버퍼의 전환은 마지막 패스의 셰이더 리소스로 사용될 때 함께 그룹화할 수 있으며, 그룹화해야 합니다.
사용되는 리소스가 서로 다른 명령 대기열에서 오는 경우에도 리소스 배리어를 일괄 처리(그룹화)할 수 있습니다.
예를 들어 트리플A 엔진의 경우 그래픽스, 컴퓨트, 복사 등 최소 3개의 커맨드 큐가 있는 것이 일반적입니다.
그래픽스 명령 목록은 "메인" 대기열이 되며, 일반적으로 모든 대기열은 서로 통신하기 위해 동기화 메커니즘(특히 D3D12의 GPU 펜스)이 필요합니다.
서로 다른 명령 대기열 간의 리소스 전환 최적화는 패스 간의 상호 작용과 사용 중인 대기열의 수에 따라 복잡해질 수 있습니다.
블로그 게시물에서 Pavlo Muratov는 이러한 작업을 완전 자동으로 만드는 데 따르는 어려움을 설명하고 무한한 수의 대기열을 처리할 때 취할 수 있는 접근 방식을 나열합니다. 일반적으로 리소스 전환을 그룹화하여 단일 대기열에서 실행하는 것이 더 나은 옵션인 것 같습니다.
리소스 메모리 관리 및 최적화
각 패스는 필요한 리소스를 선언하기 때문에 리소스의 수명을 제어할 수도 있으며, 그래프에 의해 할당도 처리됩니다.
예를 들어 위 이미지에서 리소스 A는 세 번째 패스까지만 사용됩니다. 반면에 리소스 C는 네 번째 패스부터 사용되기 시작하므로 리소스 A의 수명과 겹치지 않으므로 두 리소스에 동일한 메모리를 사용할 수 있습니다.
리소스 A와 D에도 동일한 개념이 적용되며, 일반적으로 메모리 할당을 겹치는 방법은 여러 가지가 있으므로 최상의 할당 전략을 감지할 수 있는 영리한 방법도 필요합니다.
프레임 단위로 사용되는 리소스가 있는데, 이를 일반적으로 그래프 또는 트랜지언트 리소스라고 하며 수명은 렌더 그래프에서 완전히 처리할 수 있습니다.
예를 들어 카메라 뎁스나 디퍼드 라이팅 패스의 G버퍼는 프레임 단위로 계산되므로 렌더링 그래프에서 수명을 완전히 처리할 수 있습니다.
그런 다음 윈도우 스왑체인 백 버퍼와 같이 수명이 그래프 외부의 시스템에 따라 달라지는 다른 리소스도 있으므로 그래프는 해당 리소스의 상태만 관리하도록 제한됩니다. 이를 외부 리소스라고 합니다.
Transient Resource System ( 임시 리소스 시스템 )
렌더그래프 내에서 생성되는 모든 리소스는 한 프레임 내 특정 시간 동안 지속되도록 설계되었기 때문에 메모리 재사용 가능성이 높습니다.
렌더 그래프가 소유하고 최대 한 프레임 동안 지속되는 이러한 리소스를 트랜지언트 리소스라고도 합니다.
그런 다음 리소스 수명은 배치된 리소스에 리소스 앨리어싱을 적용하는 데 사용됩니다(엄밀히 말하면 D3D12 용어를 사용함).
배치된 리소스와 리소스 앨리어싱에 대해서는 이전 글인 D3D12의 리소스 처리에 대한 글에서 설명했습니다.
배치된 리소스는 이미 생성된 GPU 메모리 힙에 상주하기 때문에 예약된 리소스에 비해 할당 및 제거가 더 빠릅니다.
이와 함께 프레임 계산 중에 수명이 겹치지 않는 여러 리소스에 동일한 GPU 메모리를 사용하는 리소스 앨리어싱이라는 개념도 종종 사용됩니다.
배치된 리소스와 에일리어싱에 대한 자세한 내용은 사용 가능한 D3D 툴 챕터에서 확인할 수 있습니다.
이미지가 아닌 오브젝트별 데이터를 포함하는 버퍼의 경우 프레임당 사용되는 크기가 작기 때문에 이 시스템이 필요하지 않으며, 선형 할당기를 사용할 수 있습니다.
텍스처의 경우 사용되는 GPU 메모리의 대부분을 차지하므로 리소스 앨리어싱 전략을 사용할 수 있습니다.
리소스 앨리어싱에 대해서는 사용 가능한 Direct3D 도구 섹션에서 자세히 설명하겠습니다.
성능 최적화에 관심이 있는 경우 Pavlo Muratorv의 블로그 게시물에서 렌더 그래프에서 에일리어싱된 리소스에 대한 최적의 스케줄링을 찾는 알고리즘을 설명합니다.
GPU Memory Aliasing
Overlapping GPU resources and saving VRAM
levelup.gitconnected.com
Parallel Command List Recording
앞서 언급했듯이 렌더 그래프가 있으면 동시에 실행 중인 여러 명령어 대기열 간의 패스 연결을 처리하는 데도 도움이 됩니다.
가장 일반적인 경우는 그래픽 + 비동기 컴퓨트 명령어 대기열 구성을 사용하는 경우입니다.
계산 패스를 비동기적으로 실행하는 명령은 다음과 같이 호출하기만 하면 됩니다.
MyGraphBuilder::ExecuteNextAsync();를 추가합니다. 그러면 그래프는 그래픽을 사용하는 대신 병렬 컴퓨팅 대기열에서 다음 패스를 시작하기 위해 이 정보를 사용합니다.
더 스마트한 그래프를 위해 흐름 구조를 검사하여 이 옵션을 결정할 수 있습니다.
그래프가 비동기 컴퓨팅 작업을 자동으로 처리하도록 할 수도 있지만 이는 최적이 아니며 수동 설정이 더 좋습니다.
비동기적으로 실행하는 모든 패스에 대해 패스 출력이 메인 렌더 스레드에서 다시 사용될 때까지 리소스 수명이 지속되는지 확인해야 합니다.
이러한 모든 메커니즘은 기본적으로 서로 다른 스레드 실행을 동기화하기 때문에 GPU 펜스를 사용하여 처리됩니다. 이러한 동기화 지점에는 타이밍 비용이 발생하므로 이러한 동기화 지점의 수를 최소화할 수 있는 최선의 방법을 찾는 것이 까다로운 부분입니다.
역자 주: GPU Fence
비동기 계산 대기열의 작업과 그래픽 대기열 간의 동기화를 관리하는 데 사용됩니다. GPU 펜스는 특정 컴퓨팅 쉐이더 디스패치 또는 드로우콜이 완료된 후 GPU 처리 중 한 지점을 나타냅니다. 하나 이상의 큐가 지정된 펜스를 지날 때까지 대기하도록 하여 비동기 컴퓨팅 큐 또는 그래픽 큐에서 실행되는 작업 간의 동기화를 달성하는 데 사용할 수 있습니다. 그래픽 큐에서 동시에 실행되는 작업과 비동기 컴퓨팅 큐가 GPU 성능 향상의 핵심이므로 비동기 컴퓨팅 작업을 수행할 때 중요한 고려 사항입니다.
D3D12 명령어 대기열 동기화에 대한 자세한 내용은 공식 문서에서 확인할 수 있습니다.
Multi-engine synchronization - Win32 apps
This topic discusses synchronizing access to the multiple independent engines found in most modern GPUs.
learn.microsoft.com
Composition And Workflow
이전 셰이더 관련 블로그 포스트에서 UE4에서 사용하는 렌더 그래프와 그 작동 방식에 대해 간략하게 설명한 적이 있습니다.
렌더 그래프는 프레임을 렌더링하기 위해 모든 정보를 먼저 수집한 다음 워크플로를 최적화하고 최종적으로 결과를 렌더링하는 리텐티드 모드 모델을 사용합니다.
이는 요소가 먼저 고려되는 대로 렌더링되는 '즉시 모드'와 직접적으로 반대되는 방식입니다. 즉시 모드가 가장 간단하게 구현할 수 있지만, 유지 모드를 사용하면 훨씬 더 많은 최적화가 가능합니다.
렌더 그래프를 사용하면 3단계로 구분할 수 있습니다:
- 설정 단계: 어떤 렌더 패스가 존재할지, 어떤 리소스에 액세스할지 선언합니다.
- 컴파일 단계: 리소스 수명을 파악하고 그에 따라 리소스를 할당합니다.
- 실행 단계: 모든 그래프 노드가 실행됩니다.
프로스트바이트 프레임 그래프는 모든 프레임에 대해 처음부터 다시 빌드되며, 코드 중심 아키텍처를 사용합니다. 이는 필요에 따라 패스를 제거하거나 추가하는 등 유연성을 높이기 위한 의식적인 선택이었습니다.
apoorvaj.io에서 설명한 것처럼 매 프레임마다 전체 그래프를 작성할 필요는 없고 그래프가 변경될 때만 작성하면 됩니다. 설정 단계 직후에 선언된 패스 조합에 대한 해시를 계산하는 것이 전략이 될 수 있습니다. 다음 프레임에서 새로 계산된 해시가 이전 프레임에서 계산된 해시와 동일하면 이미 계산된 그래프를 재사용하고, 그렇지 않으면 새로운 그래프를 구축합니다.
참고: 그래프 설정을 한 번만 실행하는 시스템에서 그래프를 정적으로 만들고, 시스템이 거의 항상 선언된 모든 패스를 필요로 한다고 확신하는 경우 명시적으로 요청하는 경우에만 그래프를 다시 빌드할 수도 있습니다.
그래프를 빌드하려면 그래프 빌더 유형 객체를 사용하여 모든 렌더 패스를 푸시하는 데 사용되는 인스턴스를 정적으로 검색할 수 있습니다.
GraphBuilder::Get().AddPass(
“MyPassName”,
Flags,
MyPassParameters,
[MyPassParameters](){
/* My lambda function body where we will use the PassParameters (and possibly other information) to send dispatch or draw commands */
} );각 패스는 다음에서 생성됩니다:
- 이름
- 플래그(예: 패스를 그래픽 또는 컴퓨팅 패스로 간주할지 여부)
- 패스 매개변수: 필요한 리소스 전환, 수명 및 앨리어싱을 이해하는 데 사용됩니다.
- 실행 람다: 드로잉 또는 디스패치 명령에 사용하기 위해 방금 선언한 매개변수를 캡처하는 곳입니다.
패스 파라미터는 적절한 전환을 감지하기 위해 최소한 셰이더 리소스와 렌더 타깃을 구분해야 합니다.
struct MyPassParameterStruct{
std::vector<ResourceRef> ShaderResources;
std::vector<ResourceRef> RenderTargets;
}이러한 렌더 패스는 렌더 파이프라인에 적용되는 특정 효과를 정의하는 패스 그룹인 렌더 피처로 더 세분화할 수 있습니다.
렌더 피처의 예로는 베이스 패스, 환경 반사, 디퍼드 조명 또는 섀도 맵이 있습니다.
예를 들어 디퍼드 라이팅이 베이스 패스에 의존하거나 섀도 맵이 섀도 깊이에 의존하는 등 피처 리소스 입력이 다른 리소스에 의존하는 경우가 발생할 수 있습니다.
따라서 이러한 종속성을 처리할 수 있는 시스템도 필요합니다.
한 가지 해결책은 맵 컨테이너를 사용하여 각 피처의 출력 데이터 참조를 저장하는 것입니다. 종속 패스에는 첫 번째 패스의 출력이 정의된 헤더가 포함되며, 필요한 경우 해당 리소스를 종속성으로 추가합니다.
// At the end of a feature an instance of this struct will be filled and inserted in the output map
struct MyFirstFeatureOutput {
ResourceRef MyFirstOutput;
}
// …
MyFirstFeatureOutput featureOutput { outputResource };
GraphBuilder::AddFeatureOutput<MyFirstFeatureOutput>(featureOutput);
// Then in code of a pass of the dependent feature
#include “MyFirstFeature.h”
MyFirstFeatureOutput& firstFeatOutput = GraphBuilder::GetFeatureOutput<MyFirstFeatureOutput>();
MyPassParameterStruct.ShaderResources.add(firstFeatOutput.MyFirstOutput);UE4에서 채택한 것과 같은 또 다른 솔루션은 그래프에서 해시된 스트링으로 리소스를 검색하는 것입니다.
ResourceRef sceneColor = GraphBuilder::GetOrCreateResource("SceneColor");
MyPassParameterStruct.ShaderResources.add(sceneColor);물론 이 방법은 다른 패스에서 어떤 문자열이 어떤 리소스에 사용될지 아는 것에 의존하기 때문에 안전성이 떨어집니다.
반면에 이 접근 방식은 특정 패스의 출력을 기대하지 않고 이전에 사용하지 않은 경우 그 자리에서 생성되는 명명된 리소스만 기대하기 때문에 더 유연할 수 있습니다.
Setup Phase
설정 단계에서 시스템은 정의된 모든 렌더 패스를 살펴보고 선언된 모든 리소스를 확인합니다. 선언된 각 리소스에는 사용 유형에 따라 플래그가 지정됩니다.
읽기, 쓰기, 컴퓨트RW, 렌더 타겟, 뎁스 스텐실
와 같은 사용 유형에 연결된 플래그가 있으며, 새 그래프 리소스를 할당하려는 경우 그래프를 전달할 수도 있습니다.
TextureRef MyGraphBuilder::CreateTexture(const TextureDesc& Desc, const char* Name, TextureFlags Flags);참조된(또는 생성된) 리소스는 가비지 데이터 읽기를 피하기 위해 패스에서 사용하기 전에 텍셀을 특정 값으로 채우고자 하는 경우 Clear와 같은 TextureFlags를 지정할 수 있습니다.
이러한 리소스의 CPU 메모리는 패스를 실행하는 동안에만 보장되며, 패스가 끝나면 (CPU와 GPU 모두) 메모리는 다음 프레임에 재사용할 수 있는 것으로 간주됩니다.
렌더 타깃 리소스의 경우, 리소스 중 하나에 쓰기를 실행할 때마다 그래프에서 이전 참조를 모두 무효화해야 현재 패스 이후에 실행되는 패스가 리소스의 이전 상태를 사용하는 것으로 생각하지 않게 됩니다.
이는 리소스에 다른 내부 업데이트 인덱스를 할당하여 런타임에 유효성을 검사할 수 있도록 함으로써 달성할 수 있습니다.
그래프 실행과 수명이 연결된 리소스 외에도 외부 시스템에서 생성된 외부 리소스(다른 방식으로 사용되거나 엔진의 다른 측면에도 필요하기 때문에)도 참조할 수 있습니다.
BufferRef MyGraphBuilder::RegisterExternalBuffer(const PooledBuffer& ExternalPooledBuffer, BufferFlags Flags);이러한 경우 리소스는 그래프에 의해 추적되어 필요할 때 상태 전환을 실행합니다.
외부 리소스의 예로는 Windows API의 윈도우 스왑 체인 백버퍼가 있습니다.
일반적으로 그래프에 등록되는 패스의 순서에 따라 단일 명령 대기열에서 패스를 실행하는 안정적인 타임라인을 확보할 수 있습니다. 다시 한 번 말씀드리자면, 단일 명령 대기열로 전송된 명령은 전송한 순서대로 실행되도록 보장됩니다.
Further Optimization
그래프 리소스는 지연 초기화로 생성할 수 있으므로 그래프 설정 내에서 생성하되 리소스가 필요한 첫 번째 패스 전에만 할당할 수 있습니다.
또한 시스템은 사용된 리소스의 상태를 추론할 수 있습니다. 예를 들어 픽셀 셰이더의 리소스로 바인딩된 텍스처를 읽기 상태로 추론할 수 있으며, 그렇지 않은 경우(예: 정렬되지 않은 액세스 뷰에서 사용하려는 경우)에는 읽기 상태로 지정할 수 있습니다.
또한 입력 버퍼 이미지에서 밉매핑된 텍스처를 생성할 때 크기와 속성을 추론하는 등 패스 입력에서 리소스 생성을 추론할 수도 있습니다.
Compile Phase ( 컴파일 단계 )
컴파일 단계는 렌더 패스 프로그래머가 영향을 미칠 수 없다는 점에서 완전히 자율적이며 "프로그래밍할 수 없는" 단계입니다.
이 단계에서는 그래프를 검사하여 가능한 모든 흐름 최적화를 찾습니다:
- 참조되지 않지만 정의된 리소스 및 패스 제외: 씬의 두 번째 디버그 뷰를 그리려면 특정 패스만 그려야 할 수 있습니다.
- 사용된 리소스 수명 계산 및 처리
- 리소스 할당
- 최적화된 리소스 전환 그래프 작성
최적화된 리소스 전환을 위해 D3D12에는 D3D12_RESOURCE_TRANSITION_BARRIER의 특정 경우를 위한 ID3D12GraphicsCommandList::ResourceBarrier 메서드가 있습니다.
이 개념을 염두에 두고 리소스 전환을 처리하는 내부 서브시스템을 구축할 수 있습니다. 아주 기본적인 예제(렌더 그래프를 사용하지 않은)는 3dgep.com의 DirectX 12 리소스 상태 추적 학 - 파트3 섹션에서 찾을 수 있으므로 여기서는 설명하지 않겠습니다.
둘 이상의 명령 대기열이 실행 중이면 상황이 더 복잡해집니다.
Build Cross-Queues Synchronization
이미 알고 있겠지만 동일한 명령어 대기열의 렌더링 작업은 순차적으로 실행되지만 여러 명령어 대기열을 사용하는 경우에는 병렬로 실행되므로 공유 리소스에 대한 경쟁 조건을 방지하기 위한 동기화 메커니즘이 필요합니다.
펜싱을 적게 사용할수록 렌더링 작업 속도가 빨라지며, 컴파일 단계는 두 개 이상의 큐 사이의 대기를 최소화하는 알고리즘을 삽입하기에 좋은 곳입니다.
참고: 언리얼 엔진과 2017년 렌더 그래프를 제시한 프로스트바이트는 최소한의 펜스 양을 계산하지 않고 워크플로를 최적화하거나 특수한 경우에 필요한 경우 수동 펜스를 넣는데, 이는 실제 트리플A 엔진 시나리오에서는 단일 알고리즘을 유지하는 것이 비현실적일 수 있는 숨겨진 에지 케이스가 많기 때문입니다.
파블로 무라토프가 블로그 글에서 병렬 명령어 큐 간의 자동 최적 펜스를 계산하는 방법에 대해 설명합니다.
제시된 주요 개념 중 하나는 D3D12와 같은 API에서 그래픽 명령 큐는 가능한 모든 종류의 리소스 상태를 전환할 수 있는 유일한 큐이므로 "가장 유능한" 큐라고 할 수 있다는 사실입니다. 이러한 이유로 적절한 동기화 후 단일 (그래픽) 대기열에서 모든 리소스 전환을 실행하는 것이 더 나은 것으로 입증되었습니다.
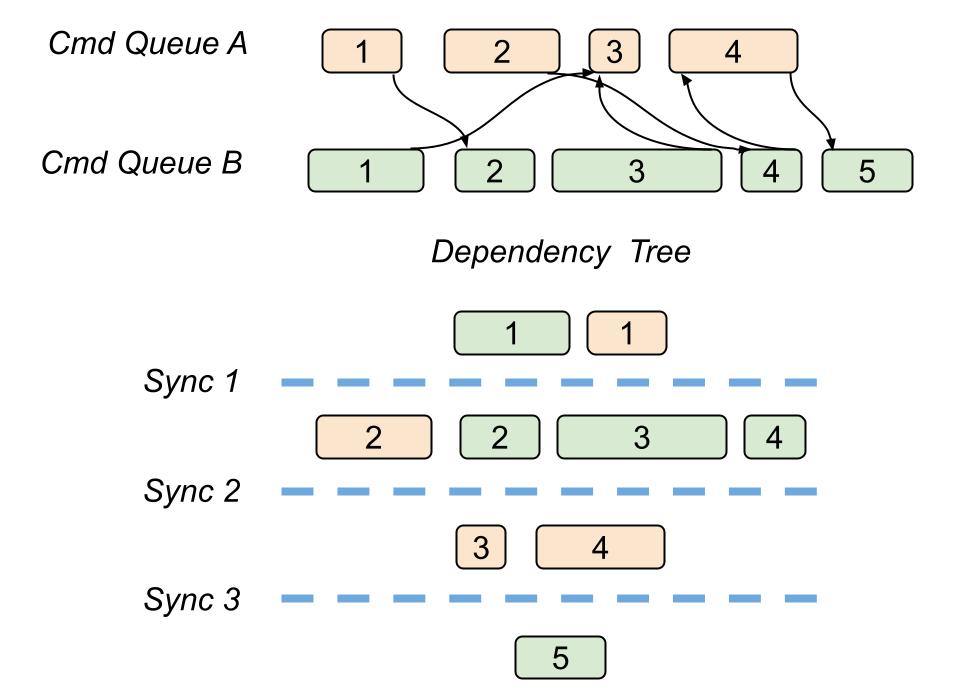
이 글에서 파블로는 종속 대기열의 모든 패스를 배치한 후 갖게 되는 렌더링 패스의 비순환 그래프에서 시작하여 종속성 트리를 구축하는 방법을 설명합니다.
종속성 수준이라고 하는 종속성 트리의 각 수준에는 리소스 사용량 측면에서 서로 독립적인 패스가 포함됩니다.
이렇게 하면 동일한 종속성 수준에 있는 모든 패스가 잠재적으로 비동기적으로 실행될 수 있습니다. 동일한 종속성 수준에서 동일한 대기열에 여러 개의 패스가 속해 있는 경우가 여전히 있을 수 있지만 이는 문제가 되지 않습니다.
결과적으로 모든 종속성 수준의 끝에 GPU 펜스를 사용하여 동기화 지점을 설정하면 단일 그래픽 명령 목록의 모든 대기열에 대해 필요한 리소스 전환을 실행할 수 있습니다.
물론 펜스를 사용하고 다른 명령어 대기열을 동기화하려면 시간 비용이 들기 때문에 이 방법은 무료로 제공되지 않습니다.
또한 항상 최적의 최소 동기화 횟수는 아니지만 허용 가능한 성능을 제공하며 가능한 모든 에지 케이스를 처리할 수 있습니다.
참고: 실제 사용 사례에서 달성할 수 있는 병렬화의 양은 현재 하드웨어에 따라 다르며(프로그래머에게 많은 세부 사항이 숨겨져 있습니다), 각 패스에 대한 워크로드의 양에 따라 달라질 수도 있습니다.
Execute Phase
실행 단계는 컴파일 단계 컬링에서 살아남은 모든 패스를 탐색하고 목록에서 드로우 및 디스패치 명령을 실행하는 것만큼 간단합니다.
실행 단계까지는 모든 리소스가 불투명하고 추상적인 참조로 처리되었지만, 실행 단계에서는 실제 GPU API 리소스에 액세스하여 파이프라인에서 설정합니다.
대부분의 경우 각 패스 명령어 목록 설정은 서로 독립적이기 때문에 CPU 측에서 명령어 목록을 준비하는 작업은 병렬화할 수 있는 가능성이 상당히 높습니다.
그 외에도 단일 명령어 대기열에 명령어 목록을 제출하는 것은 스레드 안전하지 않으며, 어떤 경우에도 병렬화를 추가하면 상당한 이득을 얻을 수 있는지 먼저 판단해야 합니다.
사용 가능한 Direct3D 도구
명령 목록 제출하기
ID3D12CommandQueue::ExecuteCommandLists 메서드를 사용하여 여러 명령 목록을 동시에 제출할 수 있습니다.
예를 들어, 각 계층에 독립적인 패스가 포함된 패스 종속성 트리를 먼저 구축한다고 가정해 보겠습니다.
동일한 "종속성 계층"에 있는 모든 패스를 다른 명령 목록에 배치한 다음 동일한 ExecuteCommandLists 호출로 모두 함께 실행할 수 있습니다.
여기서 비결은 이러한 연산 중 얼마나 많은 부분이 실제로 GPU에서 병렬로 실행될지 확신할 수 없다는 것입니다. 문서 자체에는 배치의 첫 번째 목록이 끝나기 전에 두 번째 목록의 작업이 "시작될 수 있다"고 명시되어 있지만, 하드웨어에 따라 달라질 수 있는 세부 사항이기 때문에 확실하게 알 수는 없습니다!
확실한 것은 여러 개의 명령 목록을 제출해야 하는 경우, 한꺼번에 제출할 때 발생하는 CPU 작업 부하를 줄일 수 있다는 것입니다.
배치된 리소스
커밋된 리소스를 생성하고 각 리소스마다 독립적인 리소스 힙을 만들면 많은 메모리를 사용하게 되므로, 이에 대한 간단한 해결책은 배치된 리소스를 사용하는 것입니다.
배치된 리소스는 기존의, 이상적으로는 영구적인 GPU 메모리 힙에 선형적으로 할당되기 때문에 '배치'라고 불립니다. 이러한 특성으로 인해 Direct3D11에서는 사용할 수 없었던 가장 빠르고 유연한 유형 또는 리소스를 처리할 수 있습니다.
이미 존재하는 힙과 오프셋, 할당하려는 리소스에 대한 세부 정보를 요청하는 ID3D12Device::CreatePlacedResource를 호출하여 생성할 수 있습니다.
배치된 리소스를 처리할 때 다음에 설명하는 메모리 앨리어싱을 사용할 수 있습니다.
에일리어싱 리소스
에일리어싱된 리소스의 기본 개념은 렌더링 타임라인에서 두 리소스의 사용량(따라서 수명)이 겹치지 않는다면 동일한 메모리를 사용할 수 있다는 것입니다.
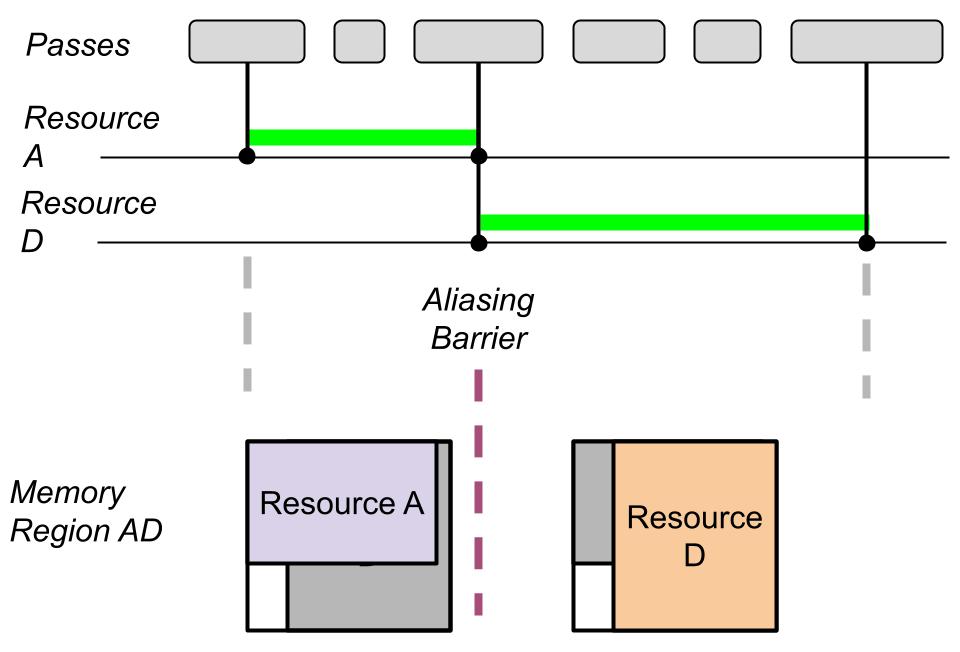
참고: 별칭이 지정된 리소스는 특히 렌더 그래프를 사용할 때 사용되는 리소스 할당 공간의 50% 이상을 절약할 수 있습니다. 씬에 리소스 관리 복잡성이 추가되지만 메모리를 절약하려는 경우 거의 항상 그만한 가치가 있습니다.
타일 리소스라고도 하는 예약 리소스에 별칭을 붙일 수도 있지만 이는 이 글의 범위를 벗어납니다.
별칭이 지정된 리소스의 간단한 모델 사용을 위해, 현재 해당 리소스 사용을 위해 공유 메모리가 할당된 경우 별칭이 지정된 리소스가 **활성 상태라고 합니다. 그 동안 이전 리소스와 메모리를 공유하는 다른 모든 리소스는 **비활성 상태로 간주되므로 사용할 수 없습니다.
비활성 리소스에 대한 GPU의 읽기 또는 쓰기는 유효하지 않은 것으로 간주되며, 배치된 리소스는 비활성 상태로 생성됩니다.
겹치는 두 개의 앨리어싱된 리소스 사용 사이에는 항상 앨리어싱 배리어가 필요합니다.
앨리어싱 배리어는 D3D12_RESOURCE_ALIASING_BARRIER 구조체에 의해 정의됩니다.
앨리어싱 배리어를 사용하는 것은 리소스 전환 배리어와 비슷하지만 앨리어싱된 리소스에 대해 만들어집니다.
에일리어싱 리소스를 다룰 때는 여러 리소스가 공유하는 메모리 공간을 참조하기 때문에 일반 리소스 배리어는 더 이상 유용하지 않습니다.
D3D12_RESOURCE_ALIASING_BARRIER myAliasingBarrier{
prevResource.Get(), resourceToActivate.Get()};
myCmdList->ResourceBarrier(1, &myAliasingBarrier);앨리어싱 배리어는 앨리어싱 이전에 존재했던 리소스와 배리어 이후 활성 리소스가 될 리소스를 인자로 받습니다.
이전 리소스는 NULL로 남겨둘 수 있으며, 이 경우 이후 리소스와 메모리를 공유하던 모든 리소스가 비활성화됩니다.
앨리어싱 배리어를 다른 전환 배리어와 함께 일괄 처리할 수 있으며, 최상의 성능을 얻으려면 그렇게 해야 합니다.
아담 사위키의 블로그 게시물에 설명된 대로, D3D12_RESOURCE_FLAGS 열거형에서 D3D12_RESOURCE_FLAG_ALLOW_RENDER_TARGET 또는 D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL로 생성된 리소스와 관련된 중요한 세부 사항이 있습니다.
렌더 타깃과 뎁스 스텐실은 텍스처와 같은 셰이더 리소스에 비해 GPU에서 다르게 처리되므로 리소스 에일리어싱에 사용할 때는 추가적인 주의가 필요합니다.
특히, 에일리어싱된 리소스가 활성 리소스가 될 때마다, 즉 에일리어싱 배리어가 에프터 리소스로 간주할 때마다 다음 작업 중 하나를 사용하여 초기화해야 합니다:
- 지우기 작업: 현재 리소스를 1, 0 또는 정의된 색상과 같은 지정된 값으로 채우는 ClearRenderTargetView 또는 ClearDepthStencilView와 같은 작업입니다. 지우기는 다음 렌더링 작업에서 현재 리소스 데이터의 하위 집합만 변경하고 나머지는 유효한 정보를 포함해야 할 때 유용합니다. 예를 들어 렌더링 대상에 큐브를 그리기 전에 렌더링 대상을 파란색으로 채우는 것을 들 수 있습니다.
- DiscardResource 작업: 현재 콘텐츠를 보존할 필요가 없음을 알려 리소스 메타데이터만 업데이트하는 매우 빠른 작업입니다. 다음 연산에서 리소스의 모든 텍셀을 계산해야 하는 경우 DiscardResource가 선호됩니다.
- 복사 작업: CopyBufferRegion, CopyTextureRegion 또는 CopyResource와 같은 복사 작업은 다른 리소스의 콘텐츠를 현재 리소스에 복사합니다.
참고: 렌더 타깃이 아닌 타깃과 뎁스 스텐실이 아닌 타깃의 경우 초기화 조건은 필수가 아니며, 가비지 데이터를 자유롭게 읽을 수 있습니다!
또한 공식 문서에 설명된 고급 사용 의미를 가진 별칭 리소스를 사용하여 특정 상황에서 최상의 성능을 얻을 수 있습니다.
고급 사용을 사용하면 다음 규칙을 충족하는 한 리소스의 활성 및 비활성 상태를 잊어버리고 언제든지 겹치는 리소스의 하위 영역에 액세스할 수 있습니다:
- 동일한 메모리 하위 영역에 있는 두 개의 서로 다른 GPU 리소스 액세스 사이에 앨리어싱 배리어가 여전히 필요합니다.
- 단순 모델에서와 같이 렌더 타깃과 뎁스 스텐실에 대한 하위 영역 초기화가 여전히 필요합니다.
Advices
펜스는 비싸다
렌더 그래프에서 펜스는 주로 리소스 액세스를 동기화하는 데 사용되며, 특히 두 명령 대기열(예: 그래픽 + 컴퓨팅) 간에 공유되는 경우 더욱 그렇습니다.
각 리소스에 대해 세분화하여 사용하는 것은 좋지 않습니다. 가능한 한 많은 리소스 사용을 동기화하도록 펜스에 신호를 보내야 합니다.
이전 섹션에서 언급했듯이 목록에 배리어를 추가하고 필요할 때까지 기다렸다가 목록을 플러시하는 지연된 배리어 시스템을 구축할 수 있습니다. 명령 대기열이 하나인 경우 이 시스템은 매우 간단하지만 대기열이 여러 개인 경우 컴파일 단계 섹션에서 이미 설명한 것처럼 매우 빠르게 복잡해질 수 있습니다.
리소스 셰이더 가시성 사용
셰이더 가시성은 루트 시그니처의 입력으로 사용되는 D3D12_ROOT_PARAMETER 구조체의 파라미터입니다.
리소스 뷰와 샘플러에 올바른 셰이더 가시성을 선언하면 그래픽 드라이버가 사용량을 최적화할 수 있습니다.
이는 렌더 그래프 기능과 함께 제공되어야 합니다. 그래프에는 특정 리소스가 어떤 방식으로 사용되는지 전체 패스 목록이 있으므로 적절한 셰이더 가시성을 결정할 수도 있습니다.
SHADER_VISIBILITY_ALL은 최적화가 덜 된 항목이므로 사용하지 마세요.
루트 시그니처 및 PSO 수정은 비용이 많이 듭니다.
루트 시그니처와 PSO를 최대한 캐시하고 해당 오브젝트에 대한 변경을 최소한으로 줄이세요.
PSO와 루트 서명에 대한 자세한 내용은 이전 문서인 파이프라인 상태 개체 및 루트 서명에서 확인할 수 있습니다.
깊이 바이어스, 뷰포트, 시저 렉트, 래스터라이저 또는 PSO의 다른 부분을 변경하면 캐시가 무효화되므로 프레임당 이러한 작업은 더 이상 수행할 수 없습니다.
예를 들어 뎁스 바이어스의 경우 PSO 파라미터를 사용하는 대신 픽셀 셰이더 내부의 바이어스를 고려하면 이 문제를 해결할 수 있습니다.
PSO 캐시는 메모리를 차지할 수 있으며 각 머티리얼 순열에 대해 많은 수의 다른 PSO를 가질 수 있지만 런타임 성능을 향상시키기 위해 감수할 수 있는 비용입니다.
디스크립터 테이블은 자주 변경되지 않는 셰이더 파라미터 그룹으로 구축할 수 있습니다. 예를 들어 머티리얼 셰이더 파라미터 그룹에 대한 정적 디스크립터는 먼저 이를 참조하는 루트 테이블 항목을 구축한 다음 해당 머티리얼을 사용해야 할 때마다 동일한 루트 테이블 항목을 참조할 수 있습니다.
Sources
- Holger Gruen - DirectX™ 12 Case Studies
https://developer.download.nvidia.com/assets/gameworks/downloads/regular/GDC17/DX12CaseStudies_GDC2017_FINAL.pdf - Yuriy O’Donnell - FrameGraph in Frostbite
https://www.gdcvault.com/play/1024612/FrameGraph-Extensible-Rendering-Architecture-in - Tiago Rodrigues - Moving To DirectX 12
https://www.gdcvault.com/play/1024656/Advanced-Graphics-Tech-Moving-to - Our Machinery - High-Level Rendering Using Render Graphs
https://ourmachinery.com/post/high-level-rendering-using-render-graphs/ - Graham Wihlidal - Halcyon: Rapid Innovation using Modern Graphics
https://media.contentapi.ea.com/content/dam/ea/seed/presentations/wihlidal2019-rebootdevelopblue-halcyon-rapid-innovation.pdf - Apoorva Joshi - Render Graphs
https://apoorvaj.io/render-graphs-1/ - Pavlo Muratov - Organizing GPU Work with Directed Acyclic Graphs
https://levelup.gitconnected.com/organizing-gpu-work-with-directed-acyclic-graphs-f3fd5f2c2af3 - Pavlo Muratov - GPU Memory Aliasing
https://levelup.gitconnected.com/gpu-memory-aliasing-45933681a15e - Adam Sawicki - Initializing DX12 Textures After Allocation and Aliasing
https://asawicki.info/news_1724_initializing_dx12_textures_after_allocation_and_aliasing - Microsoft - Memory Aliasing and Data Inheritance
https://docs.microsoft.com/en-us/windows/win32/direct3d12/memory-aliasing-and-data-inheritance - Microsoft - ID3D12Device::CreatePlacedResource
https://docs.microsoft.com/en-us/windows/win32/api/d3d12/nf-d3d12-id3d12device-createplacedresource - Microsoft - Using Resource Barriers
https://docs.microsoft.com/en-us/windows/win32/direct3d12/using-resource-barriers-to-synchronize-resource-states-in-direct3d-12
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| 바이트덴스 조석광년 SGR 테크아트팀 구조. (0) | 2023.12.14 |
|---|---|
| [주석번역] RDG 101 A Crash Course (0) | 2023.12.14 |
| [번역]Tone Mapping (0) | 2023.12.04 |
| [번역/정리]만화 얼굴 그림자 매핑 생성 렌더링 원리 (1) | 2023.12.01 |
| (참조)Lineage2m 개발 사례 언리얼 오픈데이 2019 발표. (1) | 2023.11.27 |