
역자의 말
한국에서는 테크니컬 아티스트들이 안드로이드나 IOS 등의 성능 프로파일링을 직접 회사에서 수행 하는지 정확히 알 수 없습니다만 보편적으로 신규 피처드 개발 또는 일부 개선등을 수행 한 후에 딥프로파일링을 수행 하고 평가 지표를 작성하는 것이 테크니컬 아티스트의 기본 직무에 속합니다. 주로 엔진센터 등에서 역할을 수행하는 테크니컬 아트 역할을 오래 하다보니 개인적으로는 이러한 것들이 매우 중요하다라고 생각 하는데요. 이미지텍 차이나에 소개 된 레온웨이군의 몇 가지 기사를 소개 하려고 합니다.
저자 : Leonwei

UE 기반 모바일 게임 개발에서 종종 우리가 예측 한 것보다 훨씬 더 높은 안드로이드 시스템의 실제 메모리 점유를 발견하고 메모리 점유를 최적화하려면 먼저 모든 1k 실제 메모리 점유 분포와 도구를 사용하여 메모리의 실제 구성을 효과적으로 얻는 방법을 정확히 명확히해야합니다. 이 기사에서는 프로젝트 경험과 결합하여이 부분의 세부 사항을 소개하고 그에 따라 일반적인 병목 현상과 최적화를 각각 소개 할 것입니다. 궁극적으로 안드로이드 애플리케이션의 모든 1k 메모리를 이해합니다.
안드로이드 프로그램 메모리 할당 원칙
안드로이드 메모리 관리 기초
안드로이드 메모리 관리의 핵심은 페이징과 메모리 매핑(mmap)입니다.
Paging
Andoid 시스템은 가상 메모리 주소를 사용하여 메모리를 인덱싱하고 가상 메모리는 고정 크기 페이지 페이지, 일반적인 페이지 크기 4K로 나뉩니다. 메모리 할당은 가상 메모리 할당 시작시 이 메모리에 액세스해야 할 때 물리적 메모리에 존재하지 않는 것으로 확인되면 (즉, MMU가 이 가상 주소 va의 물리적 주소에 해당하는 페이지), 즉 누락 된 페이지 (페이지 오류)를 찾을 수 없음, 몇 가지 가능성이 있습니다. 누락된 페이지(페이지 오류), 누락된 페이지에는 여러 가지 가능성이 있습니다:
1. 버그, 프로그램이 액세스해서는 안되는 가상 주소 공간에 액세스하고, 안드로이드 시스템이 액세스가 합법적이지 않다고 트리거하고, 프로세스를 종료합니다.
2. Va는 합법적이지만 pa에 해당하는이 va 조각은 할당 된 적이 없습니다 (예 : 메모리 공간을 매핑하지만 사용하지 않은 다음이 메모리 조각에 처음으로 쓰기), 이것을 지연 할당이라고하며, 시스템은 실제로 사용할 물리적 메모리 조각을 할당하고 페이지 테이블에서이 pa 및 va 조각에 해당합니다.
여기에 처음 쓰는 것은 실제로 물리적 메모리를 점유하지 않습니다. 이를 지연 할당이라고 하며, 시스템이 실제로 사용할 물리적 메모리를 할당하고 페이지 테이블에서 이 pa와 va에 대응합니다.
여기서 첫 번째 쓰기는 실제로 물리적 메모리를 처음으로 점유하는 것이며, 맵 할당은 포함되지 않습니다.
3. Va는 합법적이지만 이 va에 해당하는 pa의 내용이 현재 물리적 메모리에 있지 않고 백업 파일로 스왑된 경우 시스템은 이 페이지에 물리적 메모리를 할당하고 파일에서 이 콘텐츠의 내용을 다시 물리적 메모리로 읽어들입니다(스왑인).

스왑과 zram
일반적인 리눅스 시스템에서는 가상 메모리에 스왑 연산, 즉 물리 메모리를 일정 기간 사용하지 않을 경우 백업 파일에 백업하여 물리 메모리를 보존한 다음 일정 시간이 지나 페이지가 부족할 때 다시 스왑하는 방식이 있습니다.
그러나 안드로이드에는 이러한 스왑 메커니즘이 없는 경우가 대부분인데, 모바일의 경우 IO 비용이 너무 높기 때문에 대부분의 경우 PA에 매핑된 페이지는 스왑할 수 없습니다.
유일한 예외는 가상 주소 세그먼트에 백업 파일이 있고 pa로 스왑될 때 읽기 전용인 경우, 이 메모리 스왑 비용이 적고 물리적 메모리에서 변경되지 않기 때문에 디스크로 다시 스왑될 수 있는 가능성이 있는데, 일반적으로 다음과 같은 코드 파일에 해당합니다. mmap (예: dex so 등).
또한 안드로이드에서는 특수한 ZRAM 메커니즘을 사용하여 물리적 메모리의 일부 페이지를 압축하지만 디스크로 스왑 아웃하는 대신 압축된 페이지 섹션인 램에 남아 있으며, 시스템은 일부 페이지를 압축하여 메모리에 저장하여 물리적 메모리 공간을 확보하도록 선택합니다.
MMAP
리눅스의 중요한 기능은 메모리 매핑입니다. 위에서 언급했듯이, 페이지 오류를 통해 pa 할당을 트리거하는 mmu를 통해 va와 pa 사이에 대응이 있으며, 또한 va는 백업 파일과도 대응하며, 이는 스왑 인/아웃을 위한 백업 스토리지 역할도 합니다. va와 백업 파일 간의 이러한 대응을 메모리 매핑이라고 하며, 이 메커니즘을 사용하여 파일 읽기를 수행할 수 있습니다.
메모리 매핑을 위한 호출 함수는 다음과 같은 프로토타입을 가진 mmap입니다.
void* mmap(void *addr, size_t length, int prot, int flags, int fd, size_t offset)
void munmap(void *addr, size_t length)
addr은 미리 매핑된 가상 메모리 주소의 시작 부분입니다(시스템에서 할당하도록 하려면 null을 전달합니다).
length는 크기
offset은 오프셋
prot는 이 주소 영역이 보호되는 방식입니다.
-PROT_EXEC(실행 가능)
-PROT_READ(읽기 가능)
-PROT_WRITE(쓰기 가능)
-. PROT_NONE(액세스할 수 없음)
플래그는 이 섹션의 다양한 속성을 나타냅니다.
-MAP_FIXED:전달된 시작 주소로 매핑을 성공적으로 설정할 수 없는 경우 매핑을 포기함
-MAP_SHARED:매핑된 영역에 대한 쓰기가 백업 파일에 다시 복사되고 다른 프로세스가 해당 파일의 매핑을 공유할 수 있음
-MAP_PRIVATE:매핑된 영역에 쓰기가 생성됨. 백업 파일의 복사본을 만들고 이 영역의 변경 내용은 백업 파일에 다시 기록되지 않음(공유 및 비공개 선택해야 함)
-MAP_ANONYMOUS: 익명 매핑, 파일 fd 매개 변수 무시, 매핑된 영역은 다른 프로세스와 공유할 수 없음
-MAP_DENYWRITE : 파일에 직접 쓰지 않고 매핑된 메모리에만 쓸 수 있습니다
-MAP_LOCKED: 매핑된 영역을 잠그고 세그먼트가 스왑될 수 없음을 나타냅니다.
첫 번째는 파일을 메모리에 매핑하여 읽기 작업을 수행하는 것으로, 파일 핸들을 제공하고 파일 내용을 가상 메모리 주소 공간의 일부에 매핑하여 가상 주소 공간에 액세스하 여 수행하므로 페이지가 부족하여 백업이 이루어지지 않으며, 파일 방식으로 필요에 따라 파일을 읽을 수 있습니다. 기존 파일 읽기 방식과 비교했을 때 더 효율적이었습니다.
두 번째는 익명 매핑, 익명 매핑 백업 파일 없음, 그냥 단순히 가상 메모리 공간의 조각을 할당하는 것입니다, 실제로 호출에 안드로이드 새로운 객체 일을 할 수 있습니다, 우리는 실제로 가상 메모리 공간의 조각을 mmap에 의해 할당 될 가능성이 매우 높은 후 새로운, 그리고 첫 번째 쓰기가 페이지 미스를 트리거하고 실제 물리적 메모리를 차지하는 경우에만 int 배열의 조각을 새로운, 실제로, 새로운 후에, 안드로이드의 물리적 메모리 사용 통계는 실제 물리적 메모리를 차지합니다. 사실, 신규 이후에는 아마도 mmap을 통해 가상 메모리 조각을 할당하고 첫 번째 쓰기가 페이지 미스를 트리거하고 실제 물리적 메모리를 차지할 때만 할당할 가능성이 높기 때문에 안드로이드의 물리적 메모리 사용량 통계는 얼마나 많은 새 객체가 생성되었는지 또는 얼마나 많은 파일이 매핑되었는지보다는 실제로 가상 메모리에서 얼마나 많은 페이지가 누락되었는지가 더 중요합니다.
MMAP과 new malloc
새로운 객체를 생성할 때 new를 사용하고, 메모리 공간 할당 내에서 malloc/calloc을 사용한 다음 malloc과 mmap을 사용할 수 있다는 것을 알고 있습니다. malloc과 mmap의 관계는 무엇일까요? 우선, new와 malloc은 C++/C 언어 수준의 것이고, 실제 운영체제인 리눅스 수준에서는 사용자에게 메모리 기능의 응용을 제공하기 위해 brk/sbrk와 mmap 함수만 제공합니다.
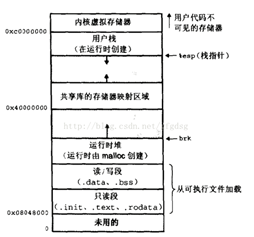
다음 그림은 일반적인 32비트 시스템에서 프로세스의 가상 주소 공간 분배 상태를 보여줍니다. sbrk는 힙 섹션의 상한을 확장하는 역할을 하며, 할당된 크기를 전달받아 새로운 brk 주소를 반환할 수 있습니다.
Malloc 함수는 적은 양의 메모리를 신청할 때는 sbrk를 사용하여 메모리를 할당하고, 많은 양의 메모리를 신청할 때는 mmap을 사용합니다. 이 시점에서 malloc은 물리적 메모리 점유에는 적용되지 않습니다. 그러나 실제로 대부분의 malloc 구현은 운영 체제 내에 다른 메모리 풀을 유지하며, 더 큰 규모의 연속 메모리 재사용을 미리 신청하고 궁극적으로 mmap은 사라집니다.
2 안드로이드 프로그램 메모리 구성
지난 안드로이드 메모리 관리의 기초에 이어 이번에는 안드로이드 프로세스의 메모리 구성에 대해 이야기하겠습니다
먼저 adb meminfo부터 시작해서 adb shell을 실행하면; dumpsys meminfo xxx.xxx.xxx를 실행하면 가장 간단한 안드로이드 프로그램 메모리 보고서를 얻을 수 있으며, 여기에 포함된 총 pss+스왑 양은 안드로이드 메모리 통계의 표준이기도 합니다.
일반적인 adb의 내용은 다음과 같습니다.
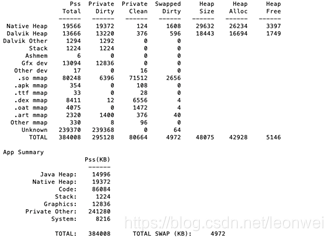
여기에서 pss privateirty privateclean swapped diry와 같은 중요한 지표를 볼 수 있습니다
여기에서 볼 수 있는 모든 값은 실제 가상 메모리의 크기가 아니라 누락된 페이지가 있는 가상 메모리의 크기인 물리적 메모리 크기입니다.
여기에 표시되는 모든 값은 실제 가상 메모리의 크기가 아니라 누락된 페이지가 있는 가상 메모리의 크기, 즉 물리적 메모리 크기입니다. 여기에 표시되는 모든 메모리 크기는 실제 물리적 메모리를 차지하는 것입니다(예: 임의로 1 int[1024]를 새로 만들면 이 메모리에 쓸 때까지 물리적 메모리는 차지하지 않고 여기에 반영됩니다).
PSS는 프로세스가 차지하는 실제 물리적 메모리 크기를 의미하는 세트 크기에 비례하지만, 안드로이드 메모리는 시스템의 다른 프로세스와 라이브러리의 일부를 공유하므로(so나 폰트 파일의 mmap 등이 될 수 있습니다), 다음과 같습니다. 프로세스가 균등하게 공유하고 있는 이 공유 라이브러리의 크기를 계산할 때 이를 고려하며, 여기서 p는 공유 후 실제 메모리를 계산한다는 의미입니다. 이것이 프로세스가 얼마나 많은 메모리를 사용하고 있는지에 대한 가장 정확한 척도입니다.
더티와 클린은 다른 프로세스와 공유한 부분을 제외하고 프로세스 자체만 사용하는 물리적 메모리이고, 클린은 앞서 언급한 것처럼 백업 파일이 있는 등 스왑될 수 있는 메모리 부분을 의미합니다. 읽기 전용 상태로 유지된 후에는 스왑 아웃될 가능성이 있습니다(예: so 라이브러리 파일). 일반적으로 프로세스 메모리에서 최적화해야 할 가장 중요한 부분은 Private Dirty이며, 가장 큰 부분이기 때문입니다.
스왑된 더티는 스왑아웃되는 메모리를 가리키는 것이 아니라 안드로이드의 zram 메커니즘에 의해 압축되는 프라이빗 더티의 일부를 가리키는데, 이는 프라이빗 더티와 동등한 중요도를 갖습니다. 더티는 어떤 더티가 압축될지 제어할 수 없기 때문에 더티의 이 부분도 일반적으로 더티의 일부입니다.
PSS에는 이미 Private Dirty와 Private Clean이 포함되어 있지만 스왑된 Dity는 포함되어 있지 않으므로, 프로세스의 물리적 메모리 사용량을 최종적으로 측정하려면 PSS+Swapped Dirty를 사용해야 합니다. 더티
아래는 카테고리별 메모리 값의 분석이며, 여전히 의미가 있습니다.
Native Heap: C/C++ 레이어에서 malloc 이 직접 할당하는 메모리입니다. UE의 프레임워크에서 이 부분을 ue 코드에서 할당하는 경우는 거의 없는데, UE의 모든 malloc 은 UE의 메모리 관리 메커니즘인 FMalloc 을 거치고, Fmalloc 의 하단에 있는 mmap 을 사용하므로 ue 코드에서 할당하는 경우는 거의 없습니다. 따라서 네이티브 힙의 값이 큰 경우 일반적으로 ue 외에 서드파티 라이브러리가 도입되었거나, 할당의 클라이언트 메모리 측에 있는 드라이버의 매우 큰 글 헤드가 있는 경우 등 몇 가지 큰 가능성만 있습니다. 메모리의이 부분은 일반적으로 일반적으로 더 크고 프로파일 링이 더 복잡하며, 비 루트 안드로이드 머신에서는 정상적인 방법으로 연결하기가 거의 매우 어렵고, 많은 UE 모바 메모리 분석가 사각 지대이며, 프로파일의이 부분은 나중에 자세히 설명 할 것입니다.
달빅 힙/기타: 이것은 안드로이드의 자바 가상 머신 메모리 할당, 즉 ue의 할당 중 자바 부분은 기본적으로 코드의 자바 계층을 직접 작성하지 않으므로 대부분의 큰 단어는 타사 SDK 할당에 대한 액세스이며이 부분은 매우 쉽게 사용할 수 있습니다! 안드로이드 스튜디오 메모리 프로파일러를 사용하여 할당 스택을 볼 수 있습니다.
Stack: 스택 할당 메모리를 매우 잘 이해합니다
Ashmem: 프로세스의 익명 공유 메모리로, 일반적으로 그리 크지 않습니다.
GFX dev: 일반적으로 비디오 메모리, 안드로이드 비디오 메모리 및 동일한 물리적 장치의 메모리로 불리므로 전체 메모리 통계는 비디오 메모리에 포함되며, 어느 것이 비디오 메모리인지 adb가 어떻게 아는지에 대해서는 비디오 메모리 할당에서 so 라이브러리의 gles 및 egl도 이진 메모리와 함께 사용되기 때문입니다. 그래서 라이브러리의 gles와 egl은 비디오 메모리를 할당할 때 백업 파일과 함께 mmap도 사용하는데, adb는 단순히 gles와 egl의 mmap을 모두 비디오 메모리로 계산하고 이 부분이 보통 GPU의 자원이고, GPU의 자원은 여러 종류의 자원으로 구성되어 있는데 가장 중요한 부분을 차지하는 것은 텍스처, 버퍼, 셰이더, 모든 게임에서 가장 중요한 부분인 프로그렘입니다.
기타: 그래픽 카드를 제외한 다른 모든 하드웨어 장치의 mmap 이후의 실제 메모리로, 사운드 카드 등이 포함될 수 있으며 일반적으로 많지 않습니다.
.so mmap: 이것은 물리 메모리가 차지하는 so 라이브러리 자체 파일 mmap으로, 게임의 진행과 함께 우리는 점차적으로 우리의 so 파일을 읽게 되고, 결과적으로 페이지 부족은 큰 부분을 차지하는 물리 메모리에서 발생하는 부분인데, 이 부분이 너무 크기 때문에 많은 부분입니다. 읽기 전용 MMAP이므로 스왑 아웃 될 가능성이 더 큽니다.
.apk .dex .oat .art .mmap: 안드로이드 프로그램 파일 자체가 mmap 메모리이기 때문에 성격이 비슷합니다.
기타 mmap: 는 위의 다른 모든 비익명 방식에 추가하여, 아래에 설명하는 명령을 통해 무엇을 볼 수 있는지 알고 싶습니다.
Unkonwn: 이 부분은 보통 UE 프로그램에서 가장 큰 부분으로, meminf에서는 모든 익명 mmap을 가리키며, 익명이기 때문에 meminf는 그것이 무엇인지 알지 못하고, unkown에 계산되며, 익명 매핑 mmap은 기본적으로 ue에서 메모리 할당 방식인 mmap입니다. ue에서 ue의 자체 Fmalloc 시스템은 mmap 메모리 할당(ansi 방식 제외)을 사용하므로 여기서 알 수 없는 메모리는 기본적으로 ue 프로그램에서 할당하는 메모리인 UE의 fmalloc 메모리와 동일합니다. ue의 fmalloc을 통해 할당된 메모리는 실제로 전체 안드로이드 프로세스의 메모리 중 일부에 불과하며, ue의 llm_full 등을 통해 추적하는 메모리도 실제로는 이 알 수 없는 메모리의 일부에 불과합니다.
RSS와 VSS
위에서 말한 것은 PSS 통계이며, 사실 메모리 통계에는 RSS와 VSS라는 두 가지가 있습니다.
adb shell top을 통해 모든 프로세스의 rss vss 정보를 볼 수 있습니다.
RSS는 다른 프로세스와 공유하는 부분 외에 프로세스 자체가 차지하는 실제 물리적 메모리를 나타내는 상주 설정 크기로, 즉, pss보다 작습니다.
VSS는 프로세스에 할당된 가상 공간의 값으로, 이론적으로는 가상 공간을 크게 할당할 수 있지만 예를 들어 많은 파일을 매핑하려는 경우 물리적 메모리에서 이러한 파일에 동시에 액세스하려는 것을 의미하지는 않기 때문에 일반적으로 이 값은 그다지 의미가 없습니다.
안드로이드의 모든 1k 메모리 이해하기& 프로세스의 전체 가상 메모리 공간 매핑 보기
여기까지 간단한 adb 명령어를 사용하여 안드로이드의 메모리 구성을 살펴본 다음, adb meminfo와 그 통계를 기반으로 실제로 adb. meminfo 코드 구현을 통해 보다 자세한 가상 메모리 매핑 정보를 확인할 수 있습니다.
adb run-as xxx.xxx.xxx cat /proc/pid/smaps 명령을 통해 전체 프로세스의 현재 가상 메모리 매핑, 즉 각 1k의 물리적 메모리가 발생하는 위치를 볼 수 있습니다. 다음 표는 그 중 일부입니다. 다음 표는 그 일부입니다.
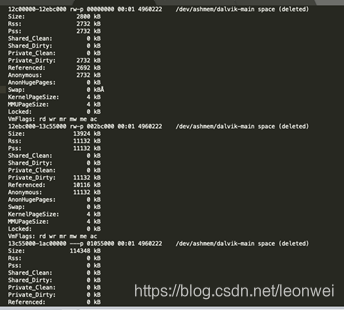
이것은 그림의 첫 번째 블록과 같은 프로세스의 각 가상 주소 공간 할당에 대한 자세한 기록이며,이 연속 가상 주소 공간 조각은 12c0000-12ebc000이라고 말하며 크기는 2800K (가상 주소 크기)이며 물리적 메모리 RS 및 pss는 2732kb이고 다음과 같이 ashemen은 다음과 같이 설명합니다. 익명의 공유 메모리로, 결국 adb minfo의 ashm에 포함될 것입니다.
이 파일은 크고 상세하며, 다음과 같은 명령으로 이 정보를 간략하게 살펴볼 수도 있습니다:
adb shell run-as xxx.xxx.xxx pmap pid; -다음과 같이 정리된 테이블을 얻을 수 있습니다.
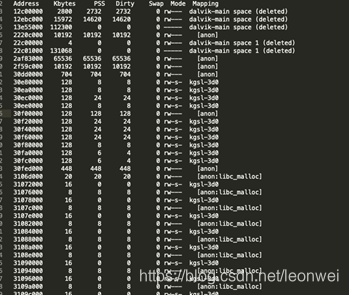
덤프 실패 재업로드 취소됨
이 표는 가상 메모리의 실제 주소, 크기, 매핑된 pss 물리적 메모리 크기, 메모리 속성, 그리고 나중에 매핑의 출처를 나열하여 훨씬 보기 쉽게 표시합니다.
매핑의 소스를 통해 메모리가 어디에서 생성되었는지 간단히 추측할 수 있습니다. 예를 들어, 몇 가지 가능성이 있습니다:
달빅-메인이 표시되면 일반적으로 자바 가상 머신의 네이티브 할당이며, 이는 결국 meminf에서 달빅으로 계산됩니다.
Anon: 이것은 익명 mmap 매핑으로, 결국 meminf의 알 수 없음으로 계산될 것이고, 이것은 UE의 모든 Fmalloc입니다
Anon: libc_malloc 이것은 malloc 메서드를 통해 들어오는 mmap, 즉 모든 새로운 . 를 호출하고, 내부적으로는 기본적으로 타사 라이브러리의 malloc 할당이며, 물론 가장 먼저 시작되는 것은 gles 드라이버의 malloc 할당입니다.
Kgsl-3d는 그래픽 하드웨어, 즉 그래픽 메모리에 대한 gles의 가상 메모리 매핑이며, 이 태그는 meminf가 gfx의 크기를 얻기 위해 계산하는 것입니다.
두 번째 후반부에는 **.SO도 보이는데, 이것은 so가 할당되는 양을 말하는 것이 아니라 물리적 메모리 크기의 누락 된 페이지 이후 가상 메모리 매핑의 so 파일 자체, 즉 현재 메모리 크기로 읽혀지는 so 파일, 이것은 액세스하는 프로그램도 동적이므로 동적으로 변경됩니다
그리고 ***.ttf, 이것은 ***.ttf의 읽기입니다. ttf 글꼴 파일을 읽는 것입니다.
사실, adb meminf도 문 앞부분에서 이 pmap 매핑에 의존하고 있음을 알 수 있습니다.
이 매핑 목록을 바탕으로 기본적으로 프로그램의 주요 메모리 사용 공간을 한눈에 파악할 수 있습니다. UE 모바 게임의 경우, 보통은
Nativeheap (주로 gl 드라이버와 타사 라이브러리, 크기가 클 수 있으며 그래픽 리소스가 너무 많은지 여부)
GFX (비디오 메모리, 텍스처, 버퍼, 셰이더, 그래픽 리소스가 너무 많은지 여부)
Unkown (UE에서 fmalloc)
So mmap (So 라이브러리가 너무 큰지)
물론 여기서는 아직 지침을 제공할 수 없으므로 이 메모리 사용을 좀 더 세분화할 필요가 있으며, UE4 엔진 기반이기 때문에 더 많은 툴을 사용할 수 있습니다.
UE 애플리케이션의 전체 메모리 구성
UE 엔진 내 메모리 할당 및 해제는 엔진 레벨에서 후킹될 것으로 예상할 수 있기 때문에, UE 엔진 내 메모리 사용량을 자세히 추적할 수 있습니다. 엔진 레벨에서 후킹할 수 있는 메모리 할당은 크게 두 가지 소스에서 비롯됩니다:
FMalloc 을 통한 메모리 할당. UE는 모든 신규/삭제 작업을 fmalloc으로 처리하므로, fmalloc 레벨에서 후킹하여 이러한 할당을 포착할 수 있습니다. 또한 malloc의 최하위 레이어는 mmap을 통해 할당하는데, 이는 UE의 fmalloc을 추적하여 전체 안드로이드 메모리의 Unkonw 부분, 즉 익명의 mmap 매핑된 부분을 추적하는 것과 동일합니다.
그래픽 API 호출을 통해 일부 GPU 리소스 생성을 트리거합니다. 예를 들어, glcreatexxx를 통해 그래픽 리소스를 생성하면 전체 프로세스에서 GPU 메모리 오버헤드인 드라이버 오버헤드가 생성되며, 많은 플랫폼에서 할당된 메모리 양을 정확하게 쿼리할 수는 없지만 적어도 그래픽 메모리 오버헤드의 그래픽 카드에서 리소스에 따라 추정할 수 있습니다. 이 메모리 오버헤드는 그래픽스 부분에 해당합니다.
따라서 UE 엔진 내부에서는 위에서 언급한 Unkonw와 GFX 부분을 쉽게 세분화할 수 있습니다. 그리고 UE 엔진은 이 메커니즘인 LLM(Low 'Level 'Memory 'Checker)을 제공합니다.
2.1 LLM
LLM은 다양한 태그를 삽입하여 특정 태그 아래에 카운트할 모든 메모리를 할당합니다. 태그 스택을 유지함으로써 fmalloc이 계산할 메모리는 현재 스택의 맨 위에 있는 태그 아래에서 계산됩니다.LLM은 현재 스택에 태그가 없으면 태그가 없는 태그 아래에서 모든 메모리가 계산되며, 코드에 범위 기반 태그를 삽입하면 다음과 같이 계산됩니다. 코드에 범위 기반 태그를 삽입하면 해당 범위의 메모리를 태그 아래에서 카운트할 수 있습니다. LLm을 사용하면 Fmalloc이 할당하는 메모리를 놓치지 않습니다.
또한 프로그램이 처음 초기화될 때 LLm은 실행 파일 자체의 메모리로 추정되는 메모리를 Program이라는 태그 아래에 기록합니다. 그리고 GPU 리소스에 대한 rhi가 생성될 때마다 LLM은 텍스처, 버퍼 등의 추가 태그 아래에도 기록합니다. 이는 fmalloc 메모리의 일부가 아니라 GPU의 메모리 풋프린트 추정치입니다.
LLM의 유형
LLM에는 2차원 통계인 기본과 플랫폼이라는 두 가지 주요 유형이 있습니다.
LLM은 각 메모리에 의사 태그를 지정하기 위해 코드에서 LLMTag를 정의하는 것을 기반으로 하며, 태그에는 최소한 유형 이름, 그룹 이름이 포함되어야 하며 매크로 LLM_ENUM_GENERIC_TAGS를 확인하여 모든 태그를 볼 수 있습니다.
태그는 기본 통계에 속하거나 플랫폼 통계에 속할 수 있습니다. 플랫폼의 통계 범주에 속하는지는 코드의 DECLARE_LLM_MEMOPRY_STAT 부분을 확인하여 어느 범주에 속하는지 확인할 수 있습니다.
기본 태그와 플랫폼 태그가 동시에 설정되어 있으므로 기본 태그와 플랫폼이 동시에 모든 메모리 사용을 계산하고 모든 메모리는 기본 태그와 플랫폼 태그 중 하나에 의해 동시에 포착됩니다.
기본 - 플랫폼에 독립적인 메모리를 계산합니다(즉, 어떤 플랫폼을 사용하든 기본 메모리는 거의 동일합니다)
통계는 stat LLM 및 stat llmfull을 통해 자세한 통계를 볼 수 있습니다. 전자는 큰 통계 그룹으로, 후자는 세분화된 통계로 제공됩니다. 주요 통계 항목은 다음과 같습니다:
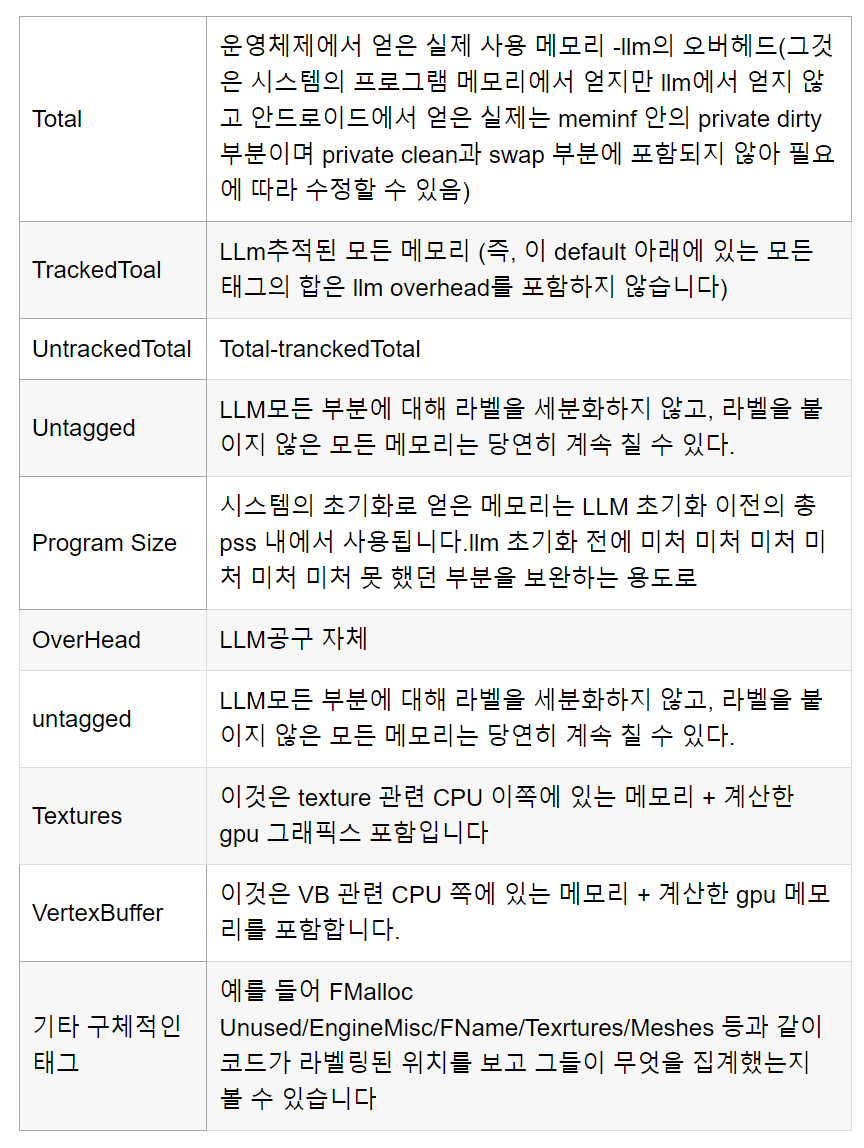
플랫폼-통계 및 플랫폼 관련
자세한 통계는 통계 llmplatform을 통해 확인할 수 있으며, 주요 항목은 다음과 같습니다.

위의 태그 중 일부가 교차하는 것을 볼 수 있는데, 예를 들어 플랫폼 구경 아래의 fmalloc에는 실제로 기본값 아래의 많은 태그의 합계가 포함되어 있습니다.
두 개의 구경이 있는 이유는 플랫폼 구경은 모델의 플랫폼과 관련이 있고 기본값은 플랫폼과 무관하게 서로 다른 차원에서 메모리의 구성을 더 쉽게 이해할 수 있도록 하기 위해서입니다. 물론 총합은 차원에 관계없이 동일합니다.
LLM을 열고 사용하는 방법은?
1. 기본 개발 및 디버그 패키지만 열려 있으며, 테스트 패키지가 열려 있는 경우 매크로 ALLOW_LOW_LEVEL_MEM_TRACKER_IN_TEST= 1을 설정해야 합니다.
2. 시작할 디버거(예: xcode 또는 안드로이드 스튜디오)를 연결해야 합니다
3. 시작 매개변수 -LLM
4. 시작 매개변수에 -LMCSV를 추가하면 결과가 주기적으로 디스크에 자동으로 저장됩니다([-LLMCSV]가 있는 경우). 디스크에 자동으로 저장됩니다.
5. 시작 매개 변수에 -LLMCSV를 사용하면 csv 안에 쓸 수 있습니다.
실행할 때 stat LLMFULL 과 stat LLMPLATFORM 명령을 입력하면 각각 기본값과 플랫폼의 두 통계 보정값을 확인할 수 있습니다. 와 플랫폼 두 가지 통계적 캘리브레이션 결과를 확인합니다
2.2 UE 애플리케이션의 안드로이드 메모리 인벤토리 구성
UE 애플리케이션을 기반으로 한 안드로이드 메모리 프로파일링 시 가장 먼저 해야 할 일은 다음의 총 pss 를 표시하는 보고서를 생성하는 것입니다. 각 k가 각각 분포되어 있는 경우, 이것은 모든 것을 해결하기 위한 전제 조건이며, 그렇지 않으면 모든 것이 추측에 불과합니다.
이제 UE 프로그램의 전체 메모리 인벤토리를 정리해야 합니다.
위에서부터 우리는 안드로이드 메모리를 meminfo에서 다음과 같이 나눌 수 있다는 것을 알고 있습니다.
Nativeheap
Davik
Gfx
.so/.dex/.oart map…
Unkonw
그리고 UE의 fmalloc은 익명 매핑을 사용하여 기본적으로 unkonwn 부분을 표현하고, ue는 대부분의 gfx를 표현한다고 볼 수 있는 tex;buffer의 명시적 메모리도 추정합니다. 그리고 LLm은 fmalloc과 명시적 메모리 부분을 해체했습니다.
그러므로 LLm을 사용하면 애초에 대부분의 gfx와 모든 unkonw를 분해한다고 가정할 수 있습니다.
그런 다음에는 약간의 작업이 필요한 몇 가지 다른 부분이 있습니다.
이 섹션은 malloc을 통해 할당된 모든 메모리입니다. ue 내의 모든 메모리 할당은 여기에 없으므로 주로 여기에 무엇이 있을까요? 대부분 다른 서드파티 소스가 malloc을 통해 메모리를 가져오고, 실제로 ue 내에 통계 fmalloc을 거치지 않고 시스템 메모리를 할당하는 일부 플러그인이 있을 수 있으며, 여기에도 해당 플러그인이 있습니다. 가장 큰 so 중 하나는 일반적으로 libgles***.so라고 불리는 것으로, 드라이버 수준에서 그래픽 카드 드라이버가 할당하는 메모리를 나타냅니다(그래픽 메모리가 아닙니다).
이 메모리의 이 부분은 일반적으로 매우 크며 이를 분석하는 방법이 있습니다. 우리는 이 메모리의 할당에 연결해야 합니다.
루팅된 경우(또는 루팅되지 않았지만 안드로이드 10 이상) 이 문서를 참조하세요 https://source. android.com/devices/tech/debug/native-memory에서 malloc debug, perfetto 및 기타 방법을 소개하는 몇 가지 방법에 대해 설명하며, 안드로이드-10은 다음 중 하나에 해당하는 경우 perfetto 이상에서 사용할 수 있는 것이 좋습니다. 일부 저가형 기기에서는 일부 해킹 방법 만 사용할 수 있습니다. 오픈 소스 프로젝트를 추천합니다. https://github.com/iqiyi/xHook, 기술 후크 라이브 임의 함수를 통해 <nbsp;plt;(procedure linkage table) 기술="" 후크="" 라이브="" 임의="" 함수를="" 통해입니다.="" <br="">
제 프로젝트에서는 이 xhook을 통합한 다음 모든 so의 malloc, relloc, calloc, free를 후킹한 다음 각 so의 네이티브 힙의 할당량을 얻을 수 있으며, 그 합은 네이티브 힙의 값과 같습니다. 네이티브 힙의 값과 같습니다.
일반적인 UE 모바일의 네이티브 힙 분해 값은 다음과 같습니다:</nbsp;plt;(procedure linkage table) >

이 방법 외에도, 각 소의 네이티브 힙의 분포를 가져오는 코드를 직접 작성하여 해당 특정 so에 대한 네이티브 힙의 분포를 가져올 수도 있습니다. 예를 들어, gles의 드라이버가 차지하는 125M 메모리가 어디에서 오는지 분석하고 싶습니다. 어떤 사람들은 gles의 드라이버는 그래픽 카드 드라이버에 의해 결정되며 우리가 개입 할 수 없다고 말하며 여기서 블랙 박스 인 것은 사실이지만 모든 드라이버 메모리 할당은 여전히 각 gl api 호출에 의해 생성되며 각 호출 전후에 입력하여 생성됩니다. 각 glapi 호출에 태그를 지정하면 해당 메모리에 어떤 종류의 API 호출이 연관되어 있는지 계산할 수 있으며, 무엇을 최적화해야 하는지 알 수 있습니다.
예를 들어, 제 프로젝트에서는 모든 글라파이 호출의 앞뒤에 몇 가지 태그를 붙여 후크의 네이티브 힙을 글라파이로 분할했고, 텍스트를 생성하거나 버퍼, 셰이더를 생성하는 등 몇몇 대규모 사용자의 드라이버 메모리 할당에 대한 매우 정확한 그림을 얻을 수 있었습니다. 또한 특정 로직으로 태그를 세분화하여 그래픽 카드 드라이버에서 어떤 유형의 버퍼가 더 많은 메모리를 차지하는지 등을 파악할 수도 있습니다.
GFX 및 디스플레이 관련 부분
디스플레이 메모리는 일반적으로 UE 프로그램에서 절대적으로 가장 큰 부분을 차지합니다. 안드로이드 프로그램에서 디스플레이 관련 리소스에 필요한 메모리는 다음과 같습니다:
A CPU 게임 엔진 측정값이 구조와 일치해야 함
B 메모리 GFX 부분의 Meminfo
C GL Mtrack 상단의 Meminfo
D EGL Mtrack 위의 Meminfo
E 그래픽 카드 드라이버 할당
구조의 CPU 쪽에서 매핑, 버퍼 등을 생성하기 위해 A가 포함하는 것, 원시 데이터 등은 LLM 통계, 그는 메모리의 일부입니다. 그는 상대적으로 잘 추적되는 메모리 부분이며 논의하지 않을 것입니다.
B는 adb meminfo에 나타나며, 그래픽 카드 액세스, 그래픽 메모리로 알려진 스토리지 리소스에 대한 우리의 전통적인 의미입니다. 이는 pmap에서 그래픽 메모리 mmap 매핑 파일(adreno에서는 kgsl-3d0 파일)의 pss 부분을 계산합니다.
C 이 항목은 안드로이드의 비디오 메모리와 메모리 관리가 가상 메모리 매핑을 사용하는 대신 페이지를 누락 한 다음 물리적 메모리로 전송하는 대신 가상 메모리 대 물리적 메모리의 크기가 동일하지 않기 때문에 최신 장치에만있는 항목이지만 가상 메모리가 얼마나 큰지 직접 할당되는지. 따라서 많은 구형 시스템에서는 통계적으로 B만 계산하고 계산된 총 PSS는 실제 물리적 메모리 점유량보다 실제로 더 작습니다. 그리고 GL'Mtracker 이 항목은 대용량의 0에 매핑된 PSS의 통계입니다. 따라서 여기에 B를 더한 것이 실제 메모리 크기이며, 안드로이드 시스템에서 C를 계산하지 않는 경우 누적 내부의 pmap으로 이동할 수 있습니다.
D는 EGL이 할당하는 하드웨어 리소스입니다. 예를 들어 백버퍼는 윈도우 시스템에서 시스템에 의해 할당되며, 이는 EGL의 할당 범주에 속하기 때문입니다. 일부 구형 시스템은 이를 계산하지 않습니다.
e opengl은 클라이언트-서버 아키텍처이며 서버는 그래픽 카드의 일부를 참조하고 클라이언트는 디버 부분의 CPU 측을 참조하며 많은 디스플레이 리소스는 동일한 필요성의 서버 부분의 메모리 할당에 대응해야 할뿐만 아니라 많은 수의 많은 디스플레이 리소스는 해당 메모리의 서버 부분에 할당되어야 할뿐만 아니라 클라이언트 부분에서 많은 드라이버 메모리를 소비해야합니다. 예를 들어, 새로운 글리버퍼를 생성하려면 이 버퍼가 아무리 크더라도 드라이버가 내부적으로 렌더링 상태와 구조를 유지해야 하기 때문에 드라이버 부분에 4096+284k의 고정 메모리를 할당해야 한다는 것을 일부 아드레노 머신에서 테스트해 보았습니다. 예를 들어, gl버퍼를 매핑하려면 일반적으로 드라이버 측에서 gl버퍼 크기의 버퍼를 할당하여 맵 결과에 대한 쓰기를 허용한 다음 적절한 시점에 드라이버를 gl버퍼의 서버 측과 동기화해야 합니다. 따라서 gl 메모리의 드라이버 부분은 무시할 수 없는 큰 덩어리이며, 이전 섹션에서 이야기할 네이티브 힙의 부분, 즉 네이티브 힙의 gles 부분입니다.
많은 구형 머신 시스템은 C와 D를 계산하지 않기 때문에 pss가 실제보다 훨씬 작게 보일 수 있습니다.
llm에는 A가 있고, 네이티브 힙에는 E가 있어서 BCD의 정확한 구성, 즉 실제 메모리의 일부를 얻을 수는 없지만 gl 문서를 보면 gl 자원의 구성은 주로 텍스처, 버퍼, 셰이더 및 프로그램, 샘플러, 쿼리 객체와 같은 종류가 포함되어 있습니다. 버퍼, 셰이더 및 프로그램, 샘플러, 쿼리 오브젝트, 그리고 큰 것은 텍스처, 버퍼, 셰이더 및 프로그램이므로 추측할 수 있습니다. 사실 텍스처와 버퍼는 이미 UE에서 추측할 수 있습니다.
GL에서 텍스처와 버퍼를 생성할 때마다 맨 아래에 UE는 프로그램 텍스처와 버퍼의 현재 속성에 따라 실제 사용되는 텍스처와 버퍼 크기를 추측하는 훅을 추가했으며, stat rhi 지시어를 통해 다양한 유형의 텍스처와 버퍼 메모리에 대한 UE 추측을 확인할 수 있습니다. 그러면 세 개의 bcd 항목의 합에서 ue로 추론한 텍스와 버퍼를 빼면 셰이더와 프로그램 메모리만 남습니다.
이것이 비디오 메모리에 대한 전체 목록입니다. 물론 현재 카드에 있는 모든 렌더링 리소스를 가로채는 프레임 커팅 소프트웨어와 같은 다른 방법도 있으며, 이를 통해 텍스트, 버퍼, 셰이더를 모두 확인하고 어떤 디스플레이 리소스가 더 많이 차지하는지 파악하는 데 도움을 받을 수 있습니다.
.so/.dex/.oart map...
프로그램 코드 파일 자체의 이 부분은 게임 코드 파일 읽기와 함께 게임 프로세스의 맵 부분을 차지하며 물리적 메모리 페이지 할당 부족으로 이어질 수 있으므로 프로젝트가 매우 큰 경우 다음을 고려해야 합니다. so 파일을 얇게 만듭니다.
달빅
이것은 메모리 할당의 자바 가상 머신 부분으로, 자바 코드를 거의 작성하지 않기 때문에 기본적으로 크지 않으며, 또한 생성 된 메모리의이 부분에 대한 안드로이드 스튜디오 프로파일러 분석도 쉽게 사용할 수 있습니다.
메모리 구성 목록
아래에서 우리는 전문적으로 안드로이드에서 UE 애플리케이션의 전체 메모리 구성 목록을 작성할 수 있으며, 이는 다음과 같은 주요 요소로 구성되어야 합니다.
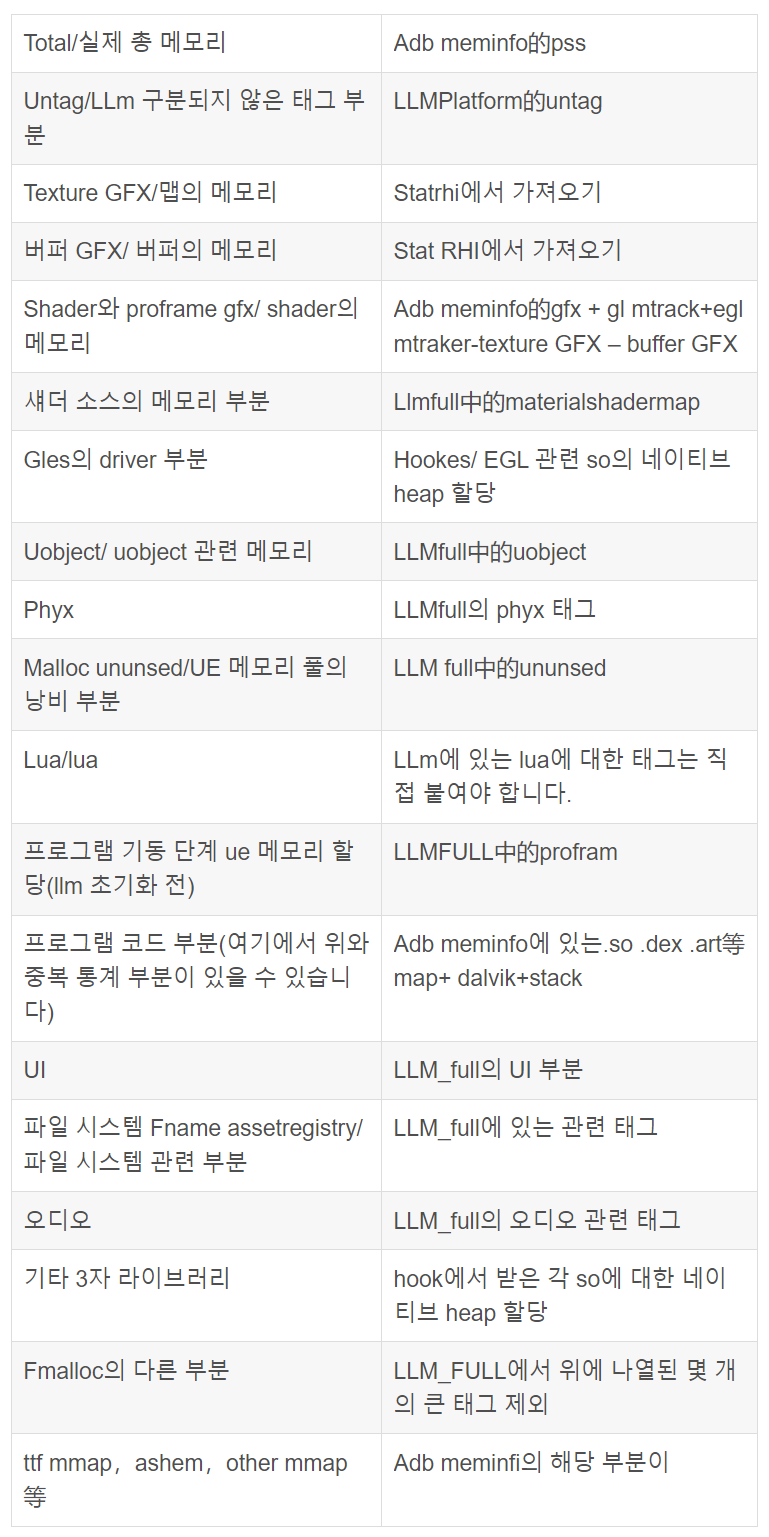
정상적인 상황에서는 하위 항목이 전체 부분에 합산되어야 하며, 명백한 불일치가 있는 경우 불일치가 어디에 있는지 분석해야 합니다.
이러한 목록을 작성하면 안드로이드 메모리 병목현상에 대한 UE 프로그램이 매우 명확해지며, 다음 단계는 이러한 병목현상을 최적화하는 것입니다.
3 UE 프로그램의 일반적인 메모리 병목 현상과 최적화
여기서는 위 섹션에서 제시한 메모리 컴포넌트 목록에 대응하여 병목 현상이 발생할 수 있는 위치와 일반적인 최적화 방법에 대해 간략하게 설명하겠습니다.
매핑을 위한 그래픽 메모리
가장 효과적인 방법은 아트를 잘라내는 것입니다! 예, 프로그램이 비디오 메모리를 너무 많이 차지한다면 과도한 아트 리소스를 어느 정도 포함하고 있습니다.
아트를 자르는 것 외에도 적절한 텍스처 압축과 품질, 텍스처 시트 수를 줄이기 위한 텍스처 병합도 있습니다. 텍스처의 크기와 형식을 사용하여 텍스처가 차지하는 메모리 양을 추정하는 경우가 많지만 이는 이상적인 상황이며, 실제로 많은 하드웨어에서 텍스처가 차지하는 메모리 양은 메모리 정렬과 같은 여러 요인에 따라 달라집니다. 저는 스냅드래곤660 머신에서 실제 메모리 pss 점유에 대한 여러 가지 형식의 해상도 맵을 실제로 측정해 본 적이 있습니다.
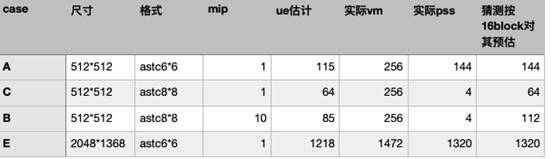
대부분의 경우 실제 pss는 추정치보다 많습니다. 여기에는 몇 가지 규칙이 있는 것 같습니다 :
astc6*6 4*4의 경우 실제 메모리 할당은 예상보다 많으며, 적어도 아드레노의 경우 16 블록에 따라 16 블록 정렬에 따라 계산하면 실제 pss 값과 동일하기 때문에 적어도 16 블록에 따라 아드레노 이미지가 있다고 추측합니다. 16블록의 경우 몇 가지 기본적인 오버헤드가 있습니다:
열린 밉 매핑: 28k, 로우 레벨 밉도 최소 16블록을 보완해야 하기 때문에
압축 크기가 매핑에 불균형한 경우: astc8 * 8은 매핑의 128배에 가장 적합합니다
. nbsp; 앤더슨. ASTC6*6은 96배율 매핑에 가장 적합합니다
<nbsp: <nbsp:  :. *6은 예상보다 86,000개(14%) 많은 수치입니다.
따라서 압축 품질에 가장 적합한 해상도를 사용해야 하며, 맵당 28k의 기본 오버헤드가 밉으로 발생하므로 가능한 한 많은 맵을 병합하는 것이 메모리 크기를 줄일 수 있는 좋은 방법입니다. <물론 사용량 추정 공식을 실제 사용량에 더 잘 맞도록 수정할 수 있습니다.
또한 적절한 로딩, GC, 캐싱, 텍스처 스트리밍 사용은 모두 텍스처 맵에 대한 최적화 전략입니다.
버퍼 메모리
매핑과 마찬가지로 아트 리소스의 과도한 사용을 먼저 고려해야 하며, 이 외에도 다음과 같은 사항도 고려해야 합니다:
uv2, color와 같이 사용하지 않는 어트리뷰터 도입 여부
인스턴스로 인한 과도한 인스턴스 배치 사용 여부
. 버퍼 등.
또한 상태 스트리밍이 켜져 있는 것으로 간주될 수 있습니다.
쉐이더 및 프로그램 메모리/메모리
쉐이더 변형은 어려운 문제의 UE이며, 대규모 프로젝트에서 거의 모든 문제의 폭발의 변형, 실제로 200M 이상의 메모리에서 누적 키의이 조각의 셰이더의 저자의 프로젝트에서 거의 모든 변형이 있습니다. 여기에는 다음과 같은 전략을 고려해야 할 수 있습니다 :
부모 재료를 줄이기 위해 가능한 한 부모 재료 파이프 라인 속성을 오버라이더의 오버라이드 (예 : 블렌드 모드가 새로운 ps와 동일 함)
재료를 줄일 수 있습니다 vertexfactory
더 많은 정의의 표시를 줄입니다. 머티리얼 셰이더 템플릿 유형
머티리얼 셰이더 내부에서 점점 더 세부적인 조정을 수행하여 불가능한 조합을 제거해야 함
현재 퀄리티 레벨의 머티리얼만 로드
배리언트 수를 줄이는 것 외에, ue의 기본값은 절대 정리하지 않는 것입니다. 이미 컴파일 된 셰이더와 프로그램, 이것은 프로그램이 더 많이 실행될수록 메모리의이 부분이 높아져 피크에 도달하고, 사용하지 않는 일부 프로그램을 동적으로 언로드하기 위해 LRU를 사용하고, 셰이더가 프로그램에 컴파일 된 후 제 시간에 언로드를 고려하고, 특히 이진 캐시를 사용하는 경우 실제로는 전혀 필요가 없습니다. 프로그램은 전적으로 바이너리에서 생성되므로 glshader를 컴파일할 필요가 전혀 없습니다.
또한, 여기에는 셰이더와 프로그램의 컴파일을 지연시키는 것도 포함됩니다. ue는 기본적으로 초기화 단계에서 glshader를 컴파일하지만 대부분의 경우 이 셰이더는 glprogram을 첨부하는 데 사용되지 않습니다. glshader, 이것은 수정이 필요한 부분입니다.
글레스의 드라이버
글레스의 네이티브 할당을 추적해 보면 대부분의 작업이 여전히 텍스트, 버퍼 및 셰이더 관련 작업이라는 것을 알 수 있습니다. 몇 가지 일반적인 문제는 다음과 같습니다.
버퍼가 아무리 크더라도 글버퍼를 생성하면 많은 머신에서 기본 오버헤드가 4K 정도이며, 게임이 많은 버퍼를 사용하는 경우, 특히 ubo를 많이 사용하는 경우 ubo의 비디오 메모리는 실제로 몇 킬로 정도밖에 추가할 수 없다는 것을 알게 될 것입니다. 따라서 대량 ubo를 많이 사용하지 말고 ue의 에뮬레이트된 ubo를 사용하거나 글로벌 ubo를 직접 병합하고 이중 버퍼를 사용하여 CPU 및 GPU 액세스 충돌을 관리해야 합니다.
또한 장기 맵버퍼를 포함하면 드라이버에서 메모리를 할당할 수 있습니다.
또한 ue에 별도로 저장된 버텍스의 어트리뷰퍼 버퍼를 ue에 저장하려고 시도할 수도 있지만, tbdr 문제로 인해 버퍼에 저장하거나 별도로 저장하려고 시도할 수도 있습니다.
U객체
개수를 줄이고 속성을 줄입니다. 씬의 오브젝트를 하나의 힙으로 합친 다음 해제하면 전체 유오브젝트 수를 크게 줄일 수 있습니다. 또한 각 유형의 유오브젝트의 수와 메모리를 오브리스트화하여 그 안에 있는 쓸모없는 멤버 변수를 대상으로 지정하여 삭제할 수 있습니다
Malloc unused
이것입니다. ue의 빈 스타일 메모리 관리는 전체 페이지의 모든 메모리 할당을 고정된 크기로 할당하기 때문에 피할 수 없는 메모리 오버헤드입니다. 이 프로세스에는 메모리 낭비와 페이지의 공백 낭비라는 두 가지 낭비가 있습니다. 이 문제를 방지하는 방법에는 몇 가지가 있습니다.
총 메모리 할당을 줄이면 이 메모리 부분도 비례하여 자연스럽게 줄어듭니다.
메모리 정렬을 잘하고, 나쁜 부분에있는 사람들을 찾기 위해, 우리는 바닥을 걸고, 그런 장소를 찾을 수 있습니다.
메모리 할당 횟수, 학위의 빈도, 특히 단기간에 많은 수의 할당을 줄이면 많은 수의 페이지를 할당하기 쉽지만 메모리 뒷면이 해제되지만 더럽습니다; 페이지가 유지되어 효과적으로 철회 할 수 없어 사용하지 않은 메모리가 많이 발생합니다. 재해 영역은 배열의 빈번한 크기 조정에서 흔히 발생하며, 배열의 모든 크기 조정 메모리 할당을 연결하여 최적화할 수 있습니다. 렌더 스레드인 경우 일반적으로 fmemstack, sceneallocater의 배열을 사용하여 빈번한 직접 메모리 할당을 피할 수 있으며, rhithread의 경우에도 이런 종류의 최적화된 메모리 할당을 위해 rhicmdlist.alloc과 유사한 것이 있습니다.
Lua
는 더 높은 메모리에 도달할 때까지 lua가 gc를 실행하지 않도록 lua의 gc 파라미터, gc의 단계 크기, 임계값 등을 적절히 설정하고, 또한 lua의 메모리로 인한 구성 테이블의 수가 많다면 sqlite와 같은 다른 방법으로 대체하는 것을 고려해야 합니다.
코드 so
지도는 메모리 양을 줄이는 것 외에도 우리의 코드의 양을 줄이는 것 외에도, 사용하지 않는 UE 기능, 플러그인 등을 컴파일하지 않을 뿐만 아니라 so 심볼을 제거해야 합니다.
자산 레지스트리
리소스 양이 너무 많으면 fname 등을 포함한 자산 레지스트리가 많은 메모리를 차지하게 됩니다. 쿠키 목록을 최소화하는 것 외에도 게임 성능에 영향을 미치지 않는 자산 레지스트리를 끄는 것을 고려할 수 있습니다.
이 글에는 10,000단어가 넘기 때문에 지면 제약(그리고 이 글을 쓰는 것이 정말 피곤하다는 사실)을 위해 이 글에서 제가 본 것 중 일부만 나열해 보겠습니다.
이 글은 지면 제약으로 인해 10,000단어가 넘기 때문에(사실 이 글을 쓰는 데 정말 지쳤습니다...), 여기서는 메모리 문제일 수 있는 큰 병목 현상 중 일부만 나열하겠습니다. 물론 각 프로젝트마다 프로젝트별 문제가 있으므로 사례별로 살펴봐야 할 것입니다. 하지만 가장 중요한 전제는 합리적이고 정확한 메모리 분석 전략을 수립하여 메모리 분포에 대한 전체 목록을 확보하면 문제를 쉽게 노출하고 위치를 파악하여 문제 해결이 가능하다는 것입니다.
요컨대, 좋은 일을 하려면 먼저 도구를 연마하고, 문제를 찾고, 문제를 분석하고, 문제를 해결하는 방법론의 최전선에 문제를 찾고, 문제를 찾기 위한 도구를 만들어야 하며, 이것이 이 글에서 집중하고자 하는 내용입니다.</nbsp: <nbsp:  :
원문
https://blog.csdn.net/leonwei/article/details/105459382?spm=1001.2014.3001.5501
'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [번역]캐릭터 카툰 렌더링(디퍼드 라이팅) 참고 사항 (1) | 2024.06.03 |
|---|---|
| [번역] Enemy AI in Unity (0) | 2024.05.26 |
| [번역] 언리얼 렌더링 시스템 해부하기 (12) - 모바일 파트 1 (UE 모바일 렌더링 분석) (0) | 2024.05.21 |
| [번역] 모바일 플랫폼을 위한 알파 테스트 효율성 재고하기 (1) | 2024.05.20 |
| [번역] 오브젝트 고유의 색상을 정확하게 복원할 수 있는 일련의 LookDev 프로세스를 실습을 통해 알려드립니다. (2) | 2024.05.15 |