
역자의 말: 주말에 컨설팅 업무 중에서 좀 시간이 오래 걸리던 구현을 해결 하고나서 가뿐한 마음으로 일주일에 하나 이상의 자료를 올리기로 한 시간을 맞이해서 정리 중입니다. 아직 시그라프 2024 내용 중에서 많은 것이 다 공개된 것은 아니고 해서 ARM 자료에서 간단한 것들을 선별해서 올리고 있는데요. 2010년 부터 2024년 지금까지 모바일 게임과 PC 게임을 개발 해 오는 동안 정말 다수의 모바일 렌더링 관련 토픽을 봐왔지만 여전히도 시간이 지나고 뭔가에 집중하고 나서 다시 생각해 보면 잘 기억이 나지 않는 것은 이제 나이 때문인것 같습니다. 아무쪼록 아침에 출근 하는 시간에 슬슬 읽어볼 만한 글이라고 생각 하구요. 아마 이 글은 일곱 정거장 정도가 소요 될 예정입니다. ^^

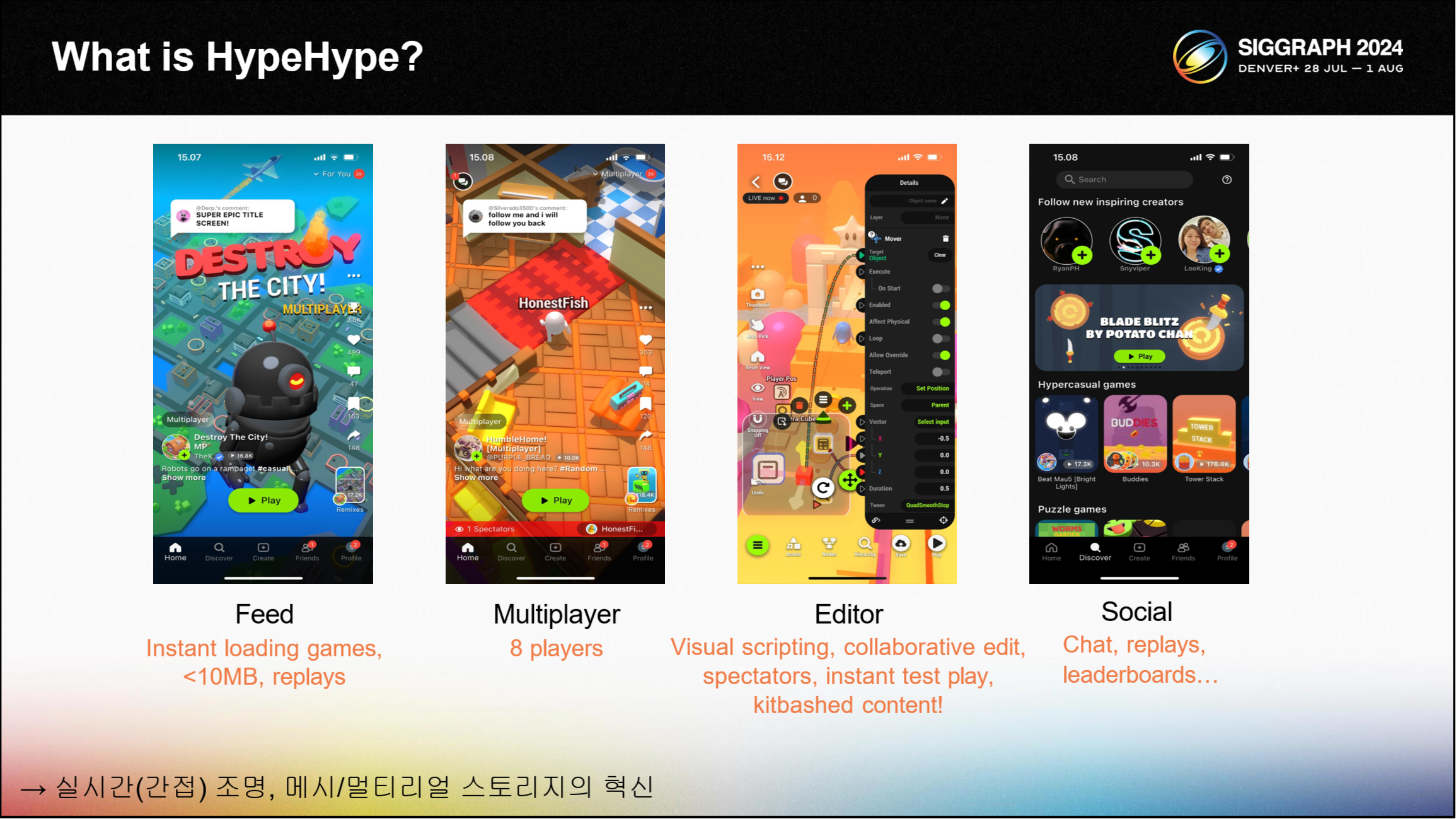
HypeHype는 소셜 모바일 게임 개발 플랫폼입니다. 터치스크린 사용자 인터페이스를 사용하여 휴대폰에서 게임을 제작할 수 있습니다.
HypeHype에는 사용자가 만든 모든 게임을 탐색할 수 있는 틱톡과 유사한 피드가 있습니다. 피드를 스와이프하면 게임이 즉시 로드되고 리플레이가 즉시 재생되기 시작합니다. 이는 소셜 미디어 동영상 앱 사용자에게 익숙한 인터페이스로, 게임에 대한 정보를 즉시 확인할 수 있습니다. 멀티플레이어 게임을 스와이프하면 진행 중인 게임 세션이 표시되고 즉시 게임에 참여할 수 있습니다. 기다릴 필요가 없습니다.
HypeHype에는 애플리케이션 내에 완전한 게임 에디터가 있습니다. 게임 로직은 노드 기반 비주얼 스크립팅 시스템을 사용하여 구현됩니다. 게임 제작도 소셜공개가 가능합니다. 관중은 제작자를 지켜볼 수 있으며, 멀티플레이어 게임에서는 제작자가 테스트 플레이 모드로 들어가면 관중은 즉시 플레이어가 됩니다.
멀티플레이어 제작에 매우 빠른 반복 작업이 가능합니다. 게임은 작은 오브젝트를 조합하여 제작합니다. 이를 킷배싱(Kit Bashing)이라고 하며, 오브젝트의 밀도가 높은 수프를 효율적으로 렌더링해야 합니다. 가장 복잡한 게임에는 100,000개 이상의 오브젝트가 포함됩니다.
인스턴트 로딩 게임과 제한된 10MB 스토리지로는 베이크된 조명을 게임 바이너리에 저장할 수 없습니다. 따라서 완전한 실시간 조명 솔루션을 사용해야 합니다. 이 솔루션은 직접 조명과 간접 조명을 모두 처리해야 합니다. 또한 제한된 스토리지는 예산에 맞는 고퀄리티 콘텐츠를 만들기 위해 메시와 머티리얼 스토리지의 혁신이 필요하다는 것을 의미합니다.

HypeHype는 주로 태블릿과 휴대폰과 같은 터치스크린 디바이스를 타겟으로 하고 있습니다. PC와 Mac 버전도 있지만 대부분의 고객이 터치스크린 기기를 사용하고 있습니다.
저는 Ubisoft에서 콘솔을 담당한 경력이 있습니다. 현재 인기 있는 휴대폰을 살펴보고 이전 세대 콘솔과 비교해 보겠습니다.
Xbox 360, PS3, Nintendo Switch는 오늘날 주류 안드로이드 휴대폰과 거의 비슷합니다. 이 콘솔은 물리 기반 조명과 전체 포스트 프로세싱 스택을 실행할 수 있는 첫 번째 세대 콘솔이었습니다. 이는 당시에는 엄청난 충실도 향상이었으며 오늘날에는 저렴한 150달러짜리 안드로이드 폰에서도 달성할 수 있습니다. 젊은 층은 일반적으로 저렴한 휴대폰을 사용하기 때문에 HypeHype와 같은 모바일 게임 플랫폼에 매우 중요한 시장입니다.
오늘날 하이엔드 휴대폰은 이미 PS4의 이론적 ALU 성능을 능가하지만 실제로는 이러한 종류의 컴퓨팅 및 대역폭 과부하 워크로드를 견딜 수 없습니다. 사용자의 휴대폰이 뜨거워지고 배터리가 너무 빨리 소모되는 것을 방지하려면 더 가벼운 워크로드를 실행하는 것이 좋습니다.
HypeHype는 99달러 미만의 구형 안드로이드 휴대폰도 지원해야 합니다. 이러한 휴대폰은 필리핀과 유사한 국가에서 여전히 인기가 높습니다.
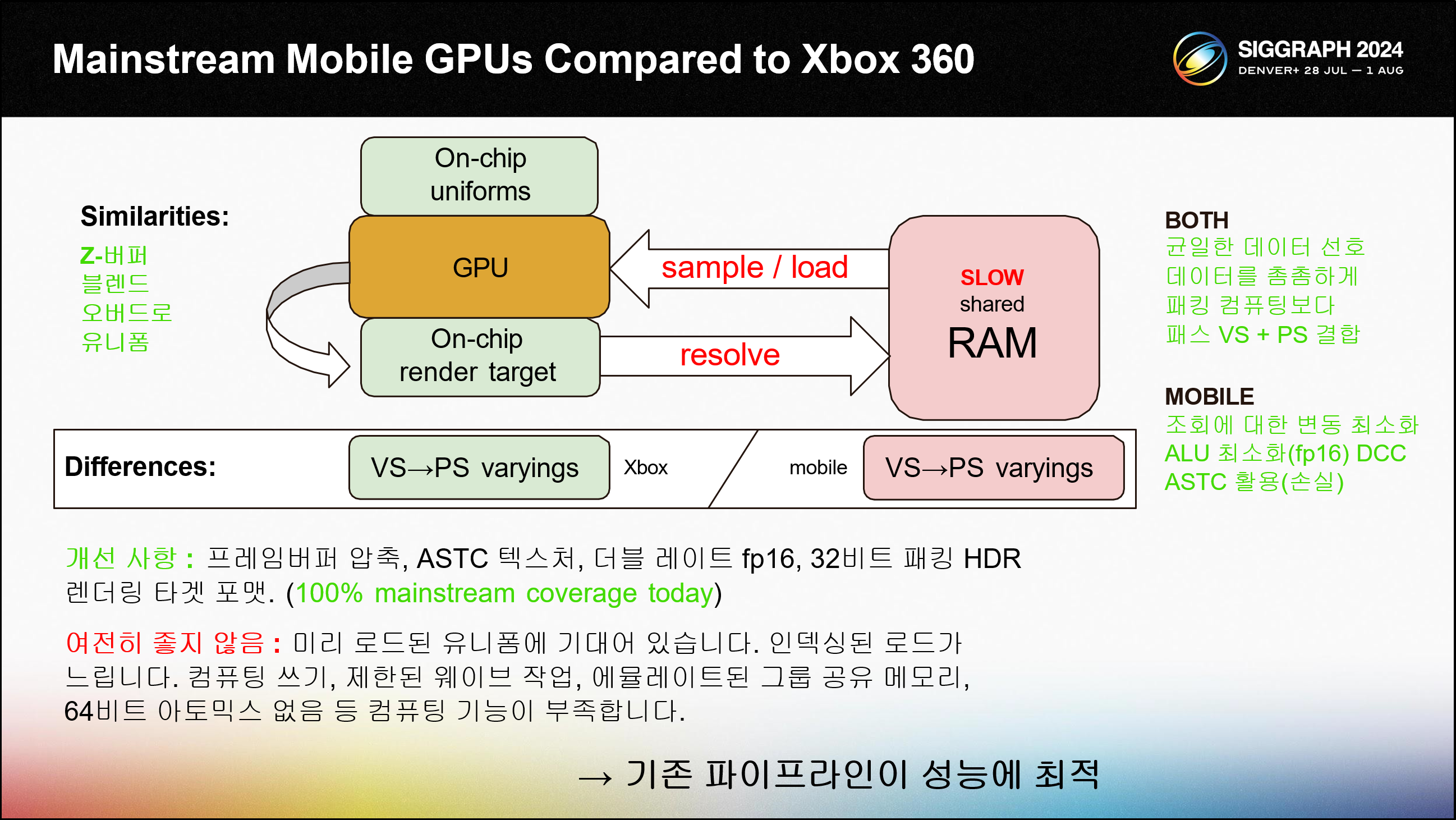
Xbox 360 세대의 비주얼을 타겟으로 하고 있으므로 일반 휴대폰과 Xbox 360을 비교하여 서로 어떻게 다른지 살펴봅시다.
Xbox 360은 GPU용 소형 EDRAM 스크래치 패드와 통합 메모리 설계를 사용했습니다. 이 디자인은 메인스트림 휴대폰과 매우 유사합니다.
느린 공유 메인 메모리와 렌더 타겟 및 Z 버퍼를 위한 빠른 소형 온칩 스토리지가 있습니다. 블렌딩과 오버드로는 메모리 대역폭을 소모하지 않습니다. 렌더 타겟은 추가 패스에서 샘플링하기 전에 메인 메모리로 해결해야 합니다.
이 리졸브 작업은 비용이 많이 듭니다. 메모리에서 해결된 비압축 텍스처를 로드하는 것도 비용이 많이 듭니다.
최상의 성능을 얻으려면 가능한 한 많은 렌더 패스를 결합하여 메모리 라운드 트립을 피하는 것이 좋습니다.메모리 로드는 느리기 때문에 이러한 GPU는 행렬과 같은 빅 데이터를 로드할 때 균일한 버퍼에 의존합니다.
Xbox 360과 모든 메인스트림 휴대폰에는 빠른 액세스를 위해 균일한 데이터를 온칩 메모리에 미리 로드하는 하드웨어 메커니즘이 있습니다.
이러한 데이터 경로는 균일한 주소 로드를 위해 최적화되어 있습니다. 레인당 주소를 사용하는 인덱싱된 메모리 로드는 상당히 느리므로 가능한 한 피해야 합니다.
모바일 GPU와 Xbox 360의 가장 큰 차이점은 타일 디퍼드 렌더링입니다. 모바일 GPU는 숨겨진 표면 제거가 더 효율적이지만 버텍스 셰이더 베리에이션을 메모리에 써야 합니다.
다양한 크기를 최적화하는 것은 성능에 매우 중요합니다. 16비트 부동 소수점이 많은 도움이 됩니다.
오늘날 모든 메인스트림 모바일 GPU는 ASTC 텍스처 압축을 지원하며, 이는 과거의 DXT5보다 더 나은 품질과 데이터 압축을 제공합니다.
또한 프레임버퍼 압축을 통해 패스 간 메모리 라운드 트립의 대역폭 비용을 절감할 수 있습니다.
최근에는 HDR 렌더 타깃을 위한 32비트 패킹 부동소수점 포맷을 강력하게 지원합니다. 이 모든 것이 매우 좋은 개선 사항입니다.
하지만 최신 PC 및 콘솔 워크로드는 여전히 모바일에 완벽하게 적합하지 않습니다: 사전 로드된 유니폼은 클래식 워크로드에는 적합하지만 최신 워크로드에는 인덱싱된 로드가 필요하며 이는 메인스트림 Android GPU에서 느립니다.
컴퓨팅 셰이더 성능도 부족합니다: 컴퓨팅 셰이더 출력을 위한 프레임버퍼 압축이 없고, 웨이브 연산이 제대로 적용되지 않으며, 일부 GPU는 그룹 공유 메모리를 에뮬레이트하고 64비트 아토믹스가 누락되어 있습니다. GPU 기반 렌더링은 오늘날의 메인스트림 휴대폰에는 적합하지 않습니다.
기존 Xbox 360 기술이 더 나은 성능을 발휘합니다.
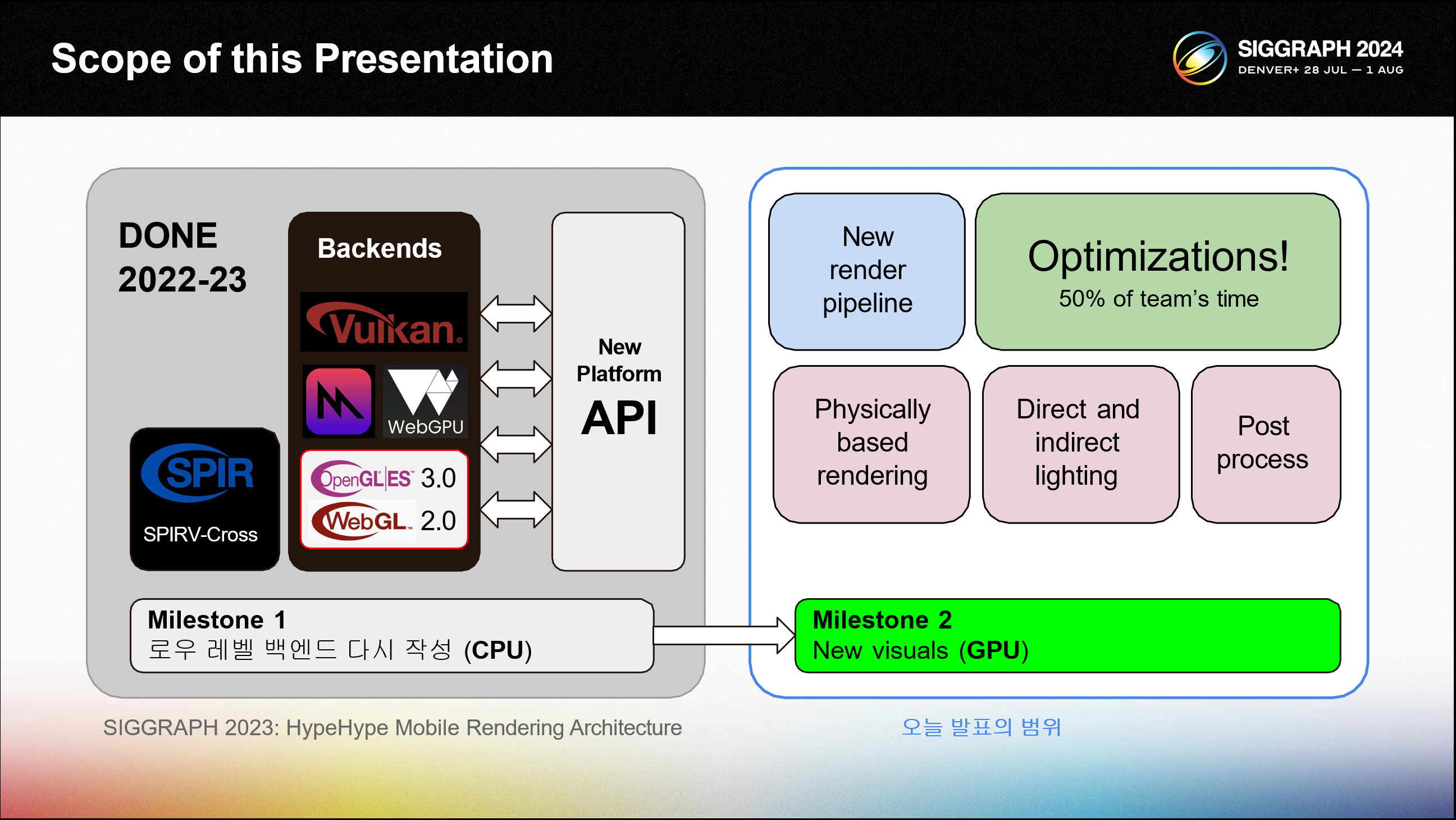
작년 시그라프에서 저는 그래픽 백엔드 재작성에 대해 이야기한 적이 있습니다. 모든 플랫폼별 코드가 새로운 코드로 대체되었습니다. 메탈, 벌칸, WebGPU를 감싸는 매우 효율적인 씬 플랫폼 API를 구축했고, SPIRV-Cross에 의존하는 새로운 셰이더 시스템을 구축했습니다.
오늘은 시각적인 측면에 대해 이야기해 보겠습니다. GPU 측면에 초점을 맞추겠습니다. 물리 기반 렌더링과 최신 포스트 프로세싱을 구현하는 새로운 렌더 파이프라인에 대해 이야기하겠습니다.
올해도 제가 논의하고 싶은 가장 큰 주제는 성능입니다. 우리 팀은 코드 최적화에 약 50%의 시간을 할애했습니다.

메인스트림 휴대전화를 타겟팅하는 경우 성능은 매우 중요한 요소입니다.
올바른 타겟에 맞게 최적화하고 있는지 확인하고자 합니다. 이를 위해 많은 분석 데이터를 수집합니다.
우리 고객의 80%는 저렴한 안드로이드 휴대폰을 사용합니다. 우리는 이러한 휴대폰에서 HypeHype가 완벽하게 실행되도록 하고 싶습니다. 게임 플레이가 가장 중요하기 때문에 60fps로 실행하는 것이 중요합니다.
비주얼 때문에 게임 플레이가 저하되어서는 안 됩니다.
현재 150달러의 메인스트림 안드로이드 휴대폰과 99달러 미만의 구형 휴대폰 간에는 5배 이상의 GPU 성능 차이가 있기 때문에 일부 시장에서는 도달 범위를 개선하기 위해 타협을 해야 합니다. 시작 시 휴대폰 GPU 성능을 감지합니다.
GPU가 느리면 내부 렌더링 해상도를 2x2로 낮추고 프레임 속도를 30fps로 고정합니다.
대부분의 크리에이터(하이프하이프 크리에티를 지칭함)가 일반 휴대전화를 사용한다는 점에 유의해야 합니다. 이들은 특별한 고사양 콘텐츠를 제작하거나 테스트할 수 없습니다.
콘텐츠는 고사양 휴대폰에 맞게 자동으로 확장되어야 합니다.코드의 성능에 따라 구현할 수 있는 그래픽 기능의 수가 결정됩니다.
아티스트와 게임 디자이너가 새로운 기능을 요청할 때 거절하는 법을 배우는 것이 중요합니다.타임 박싱은 초기 계획 단계에서 도움이 되었습니다.
우리는 이미 과거에 Xbox 360과 PS3 렌더링 기술을 구현한 적이 있습니다. 이 지식은 타임 박싱에 도움이 되었습니다.
초기 기능 세트에 도움이 되었습니다.
UGC 키트배시 콘텐츠는 예측이 매우 어렵고 테스트하거나 품질을 관리할 수 없습니다. 씬의 복잡성과 무관하게 고정 비용이 드는 기법을 선택하는 것이 좋습니다.
두 가지 기법 중에서 선택할 때는 기본 비용은 약간 높지만 씬 복잡도에 따라 추가 비용이 낮은 기법을 선호합니다.
새로운 기능을 추가할 때는 새로운 기능에 맞게 성능을 확보해야 합니다.
가장 선호되는 방법은 기존 코드를 최적화하는 것입니다. 이것이 바로 Free Performance 입니다. 오늘날의 기존 코드는 이미 매우 잘 최적화되어 있으므로 품질과 절충하고 기술에 제한을 두어 비용을 낮춰야 합니다.
비용이 너무 많이 드는 새로운 기능은 출시할 수 없습니다. 최후의 수단은 가급적 제작 초기에 기능을 줄이는 것입니다.
저희 렌더링 팀은 올 한 해 동안 50% 이상의 시간을 분석, 프로파일링, 최적화에 투자했습니다.
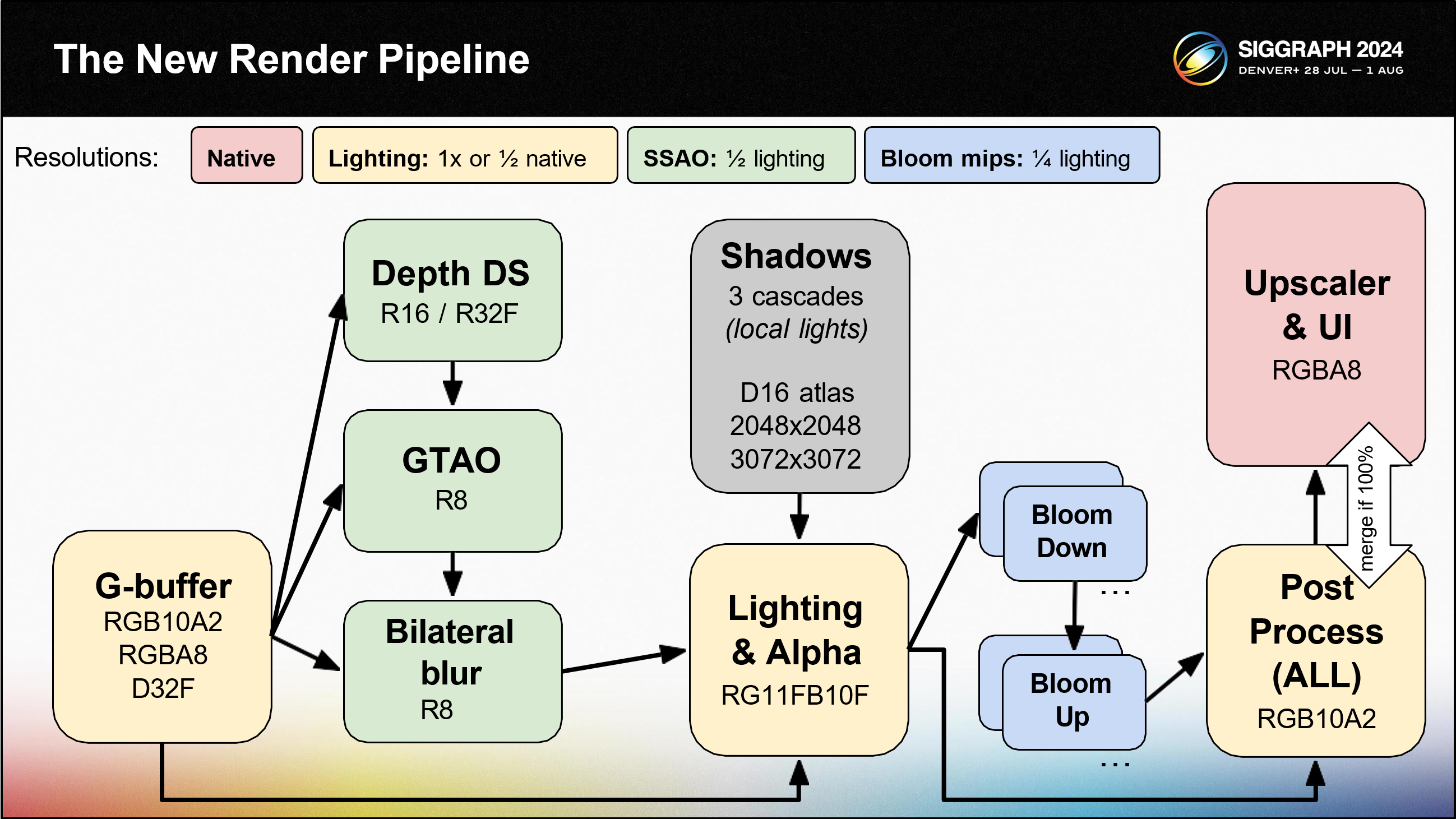
새로운 렌더링 파이프라인에 대해 이야기해 보겠습니다.이 다이어그램의 각 상자는 하나의 렌더링 패스를 나타냅니다.
모바일에서 비용이 많이 드는 메모리 라운드 트립을 최소화하기 위해 렌더링 패스 수를 최소화하려고 노력했습니다.
디퍼드 렌더링 파이프라인을 사용하므로 먼저 컴팩트한 64비트 G-버퍼를 렌더링하는 것으로 시작합니다.
그런 다음 씬 Z 버퍼를 다운샘플링하고 선형화합니다. 선형 Z 버퍼는 대역폭을 절약하기 위해 16비트입니다.
SSAO 및 양방향 블러 패스는 선형 Z를 소비하고 8비트 SSAO 기여도를 생성합니다.섀도 맵 패스가 이어집니다. 이것은 단일 패스 캐스케이드 섀도 접근 방식입니다. 모든 섀도 맵은 동일한 아틀라스에 있으며, 각 섀도 캐스케이드에 대해 뷰포트 사각형을 변경하여 아틀라스를 채웁니다. 이렇게 하면 렌더링 패스가 하나만 필요하고 캐스케이드 사이에 멈춤이 없습니다. 섀도 맵은 대역폭을 절약하기 위해 16비트입니다.
디퍼드 라이팅 패스는 섀도 맵, SSAO 및 G 버퍼를 사용하여 32비트 패킹 플로트 포맷으로 조명이 켜진 HDR 이미지를 제공합니다.
투명도와 파티클은 동일한 렌더 패스에서 조명된 씬 위에 렌더링됩니다.
블룸 패스는 쿼터 해상도에서 시작하여 밉 체인을 따라 내려가면서 재귀적으로 블러링하고 다시 위로 올라가 결과를 결합합니다. 이 고전적인 접근 방식은 메인스트림 스마트폰에는 적합하지만 하이엔드 스마트폰에서는 이미 점유율 문제가 발생하기 시작합니다.
포스트 프로세싱은 메모리 트래픽을 줄이기 위해 단일 패스 방식을 사용합니다. 모든 포스트 효과는 단일 셰이더에서 구현됩니다. 그런 다음 포스트 프로세싱된 이미지를 기본 해상도로 업스케일링하고 동일한 렌더링 패스에서 UI를 그 위에 렌더링합니다.
렌더링 스케일이 100%인 하이엔드 휴대폰에서는 추가 렌더링 패스가 필요하지 않도록 UI 패스를 시작할 때 바로 포스트 프로세스를 네이티브 해상도로 렌더링합니다.

3년 된 99달러짜리 안드로이드폰의 프로파일러 캡처(ARM Streamline)입니다. 이 휴대폰은 최소 사양의 휴대폰으로, 9년 된 플래그십인 iPhone 6s보다 약 5배 느린 GPU를 탑재하고 있습니다.
보시다시피 이 기기에서 전체 렌더 파이프라인으로 60fps를 간신히 달성할 수 있었습니다.
가장 먼저 보이는 것은 상단의 버텍스 처리입니다. 버텍스 처리는 픽셀 파이프라인이 멈추는 것을 방지하기 위해 이전 프레임과 겹칩니다.
저사양 스마트폰에서는 버텍스 처리가 프레임의 약 50% 동안 활성화될 수 있으므로 오버랩이 매우 중요합니다. 벌칸에서는 이전 렌더 패스와 겹치는 버텍스 작업을 허용하도록 배리어를 설정하는 것이 중요합니다. 그렇게 하지 않으면 GPU 성능의 약 15%가 손실됩니다.
여기서 가장 중요한 것은 섀도와 G-버퍼 패스입니다. 이 패스는 비용이 가변적인 유일한 패스입니다. 나머지 프레임은 고정 비용의 전체 화면 렌더링 패스입니다. 이는 킷베이싱된 사용자 제작 콘텐츠에 매우 중요합니다. 프레임 시간 변동을 최대한 피하고 싶기 때문입니다.
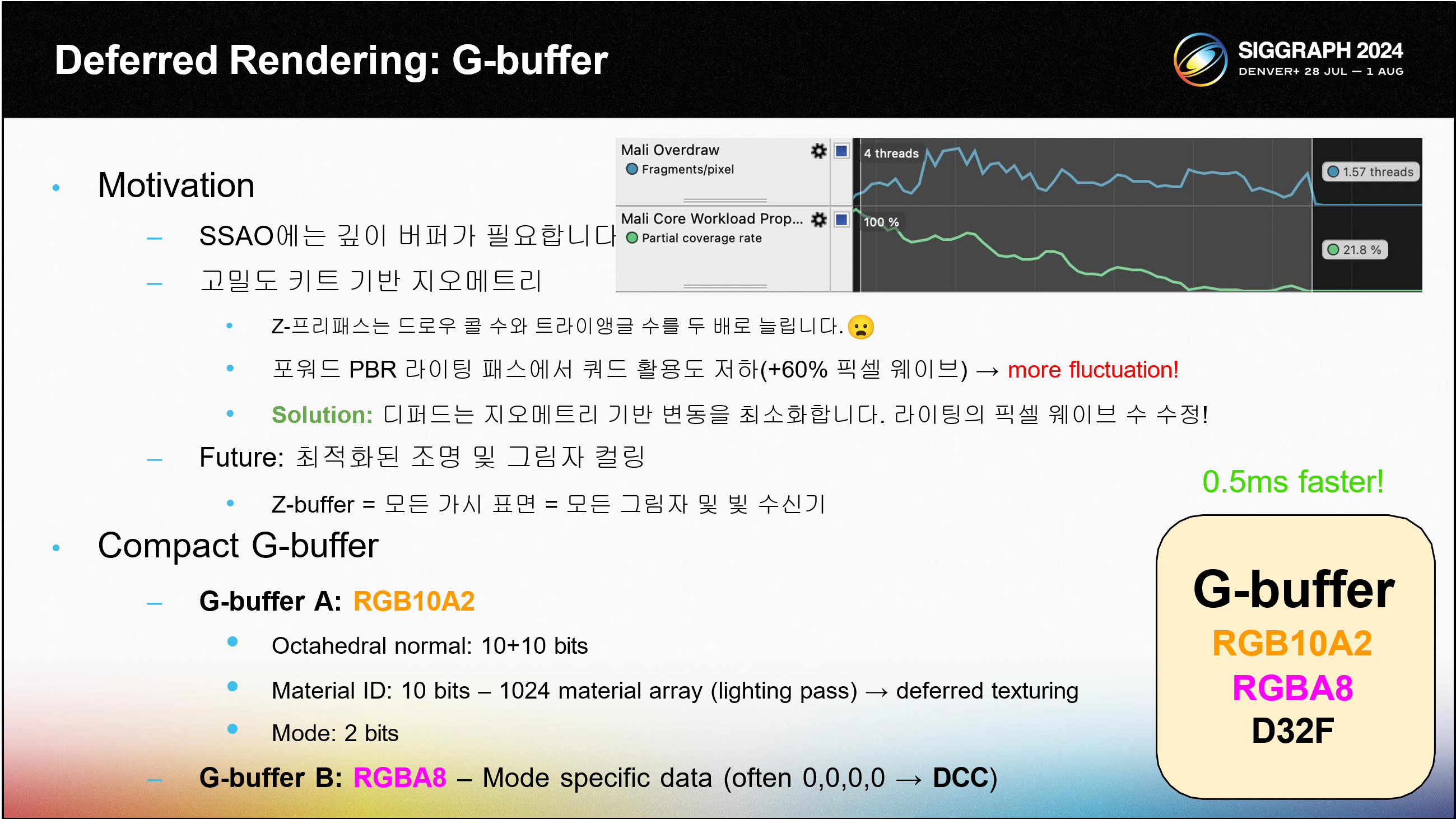
이제 모든 렌더 패스에 대해 이야기하겠습니다: 첫 번째 주제는 디퍼드 렌더링입니다.모바일 게임은 메모리 대역폭을 절약하기 위해 포워드 렌더링을 사용하는 경향이 있습니다. 하지만 포워드 렌더링은 최신 렌더링에 문제가 있습니다.
SSAO를 위해 라이팅하기 전에 뎁스 버퍼가 필요합니다.
Z-프리패스는 고밀도 키트배시 지오메트리를 사용하면 비용이 매우 많이 듭니다.드로우 콜 수가 두 배로 늘어나고 트라이앵글 수도 두 배로 늘어납니다. 저희는 이를 감당할 수 없습니다. 게다가 Z-prepass는 모바일 TBDR 렌더러에 전혀 도움이 되지 않는데, 그 이유는 TBDR 아키텍처 때문입니다.
또한 지오메트리가 상당히 밀집된 경향이 있다는 점도 발견했습니다. 오브젝트 경계를 넘나들며 최적화할 수 없기 때문에 킷베이싱된 콘텐츠에서는 LOD가 제대로 작동하지 않습니다.
쿼드 오버드로 인해 평균 60%의 픽셀 셰이더 웨이브가 추가로 발생하는 것으로 측정되었습니다.
이 픽셀 셰이더는 새로운 물리 기반 셰이딩, 라이팅 및 그림자 샘플링 기술을 구현하기 때문에 무겁습니다.
디퍼드 라이팅을 사용하면 픽셀당 하나의 스레드로 조명 웨이브의 양이 고정됩니다. 씬의 복잡도와는 무관합니다. 우리는 조명 오버드로에 대한 비용을 지불하고 싶지 않습니다.
다음으로 G-버퍼 대역폭 비용을 해결해야 합니다. 우리는 정말로 두 개의 32비트 렌더 타깃을 G-버퍼에 넣었습니다.
첫 번째 G-버퍼는 10비트 RGB 포맷을 사용하고, 첫 번째 두 채널에는 팔면체 노멀을, 세 번째 채널에는 10비트 머티리얼 ID를 저장합니다.이렇게 하면 최대 1024개의 머티리얼을 지원할 수 있어 소규모 모바일 게임에 적합합니다.
2비트 알파 채널은 모드 선택기(4개 모드) 역할을 합니다. 보조 G-버퍼는 모드별 데이터를 저장합니다. 모드 0은 디퍼드 텍스처링을 수행하며 보조 G-버퍼도 필요하지 않습니다. 이는 프레임버퍼 압축과 함께 매우 잘 압축됩니다.
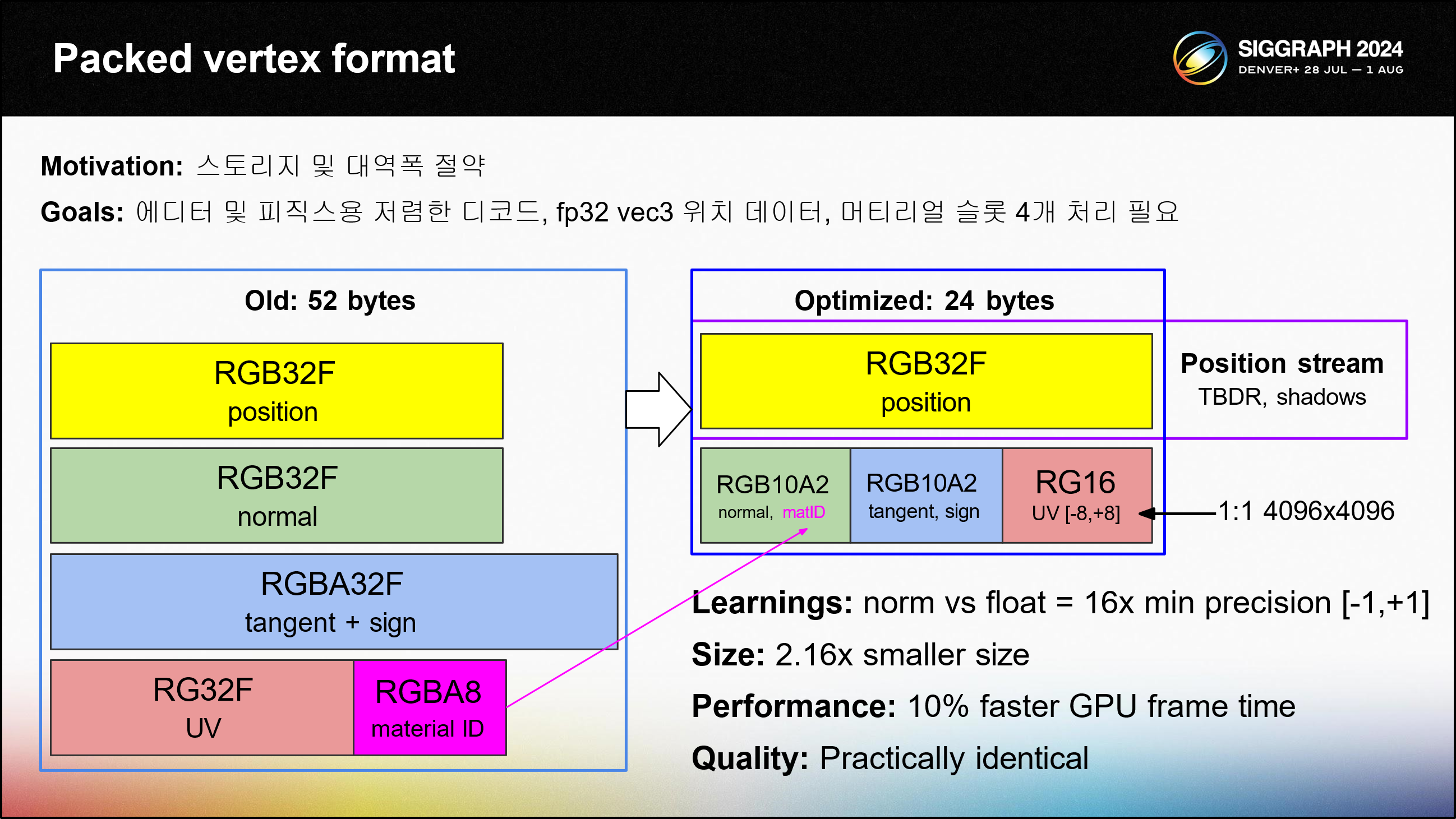
하이프하이프는 52바이트 fp32 버텍스 포맷을 사용했습니다.
스토리지와 대역폭 비용을 절감하고 싶었기 때문에 새로운 포맷을 설계했습니다.
주요 목표는 포맷을 가능한 한 작게 만들되, ALU 비용이 크게 들지 않도록 하는 것이었습니다.
또한 물리 및 에디터용 언패킹된 fp32 vec3 위치 데이터도 필요했습니다.
HypeHype의 메시는 최대 4개의 머티리얼을 지원합니다. 각 트라이앵글은 하나의 머티리얼에 속합니다. RGBA8 버텍스 컬러를 사용하여 구현했습니다.
색상은 버텍스 셰이더에서 디코딩되었고 그 결과 0에서 3 사이의 숫자를 얻었습니다.
새로운 형식에서는 로컬 머티리얼 인덱스를 2비트 값으로 직접 저장합니다. 10비트 RGB 값은 노멀과 탄젠트를 저장하는 데 사용되며, 2비트 알파 채널은 머티리얼 ID와 비트탄젠트 부호를 저장하는 데 사용됩니다.
탄젠트는 평소와 같이 교차 곱을 사용하여 계산합니다. UV는 [-8,+8] 범위로 스케일링된 16비트 정규화된 값으로 저장합니다. 이렇게 하면 트릭 없이 최대 16배의 UV 반복을 지원합니다. UV가 더 많이 반복되는 경우 메시 프리프로세서가 추가 UV 심을 추가하여 무제한 타일링을 지원할 수 있습니다.위치 데이터는 별도의 위치 스트림에 저장됩니다.
이는 비닝을 위해 간소화된 위치 전용 버텍스 셰이더를 실행하는 모바일 TBDR 아키텍처에서 유용합니다.
위치 데이터를 분리하면 캐시 활용도가 향상됩니다.
마찬가지로 별도의 위치 스트림은 섀도 맵 렌더링에도 도움이 됩니다.패킹 버텍스 포맷은 다음과 같이 평균 10%의 GPU 프레임 시간 향상을 가져왔습니다.
실질적으로 동일한 품질. 2.16배 더 작은 버텍스 크기는 우리 플랫폼에 중요한 메모리와 게임 바이너리 크기를 절약해줍니다.

다음 주제는 지오메트리 인스턴싱과 머티리얼 데이터입니다.
저는 프로토타입을 제작하는 동안 구형 저가형 휴대폰에서 인덱싱된 메모리 로드가 매우 느리다는 사실을 아주 일찍 알아차렸습니다.
Mali G57 MP2에서 프로그래밍 가능한 레인당 주소에서 단일 128비트 플로트4를 로드하는 데 기본 해상도 전체 화면 픽셀 셰이더 패스에서 0.5ms가 소요되는 것으로 측정했습니다.
HypeHype의 원래 메인 포워드 렌더링 픽셀 셰이더는 이 중 5개를 수행했습니다. 2.5ms입니다. 물론 ALU를 추가하여 이 메모리 비용을 숨길 수는 있지만, 이는 쉽게 병목 현상이 될 수 있습니다.
지오메트리 인스턴싱은 CPU와 드라이버 비용을 줄이는 좋은 방법이지만 항상 약간의 GPU 비용이 추가됩니다. 이 추가 비용의 대부분은 일정한 주소 로드 대신 인덱싱된 로드를 사용하여 매트릭스 및 머티리얼 데이터를 가져오는 데서 발생합니다. 인덱싱된 각 로드는 픽셀당 실행되어야 하며, 온칩 스토리지에 미리 로드할 필요가 없습니다.
인스턴싱 버텍스 셰이더 데이터 레이아웃은 6x float4로 패킹됩니다. 6개의 메모리 로드는 셰이딩에 필요한 오브젝트 매트릭스, 노멀 매트릭스 및 머티리얼 ID를 제공합니다. 오브젝트 매트릭스는 4x3 매트릭스로, 최적화되지 않은 4x4 매트릭스에 비해 25%의 로드(및 레지스터)를 절약합니다.
일반 매트릭스는 3x3 매트릭스입니다. 정렬을 위해 4x3으로 저장하지만 머티리얼 ID를 비롯한 다양한 용도로 패딩을 재사용합니다.하나의 32비트 정수에 8비트 머티리얼 ID 4개를 패킹합니다. 이렇게 로컬 메시를 매핑합니다.
특정 2비트 머티리얼 인덱스를 전역 머티리얼 인덱스에 매핑합니다. 올바른 머티리얼을 선택하는 것은 비트 시프트와 마스크로 간단히 구현됩니다. 매우 빠릅니다. 머티리얼 인덱스를 선택하기 위해 추가적인 인덱싱 로드가 필요하지 않습니다.
결과 머티리얼 인덱스는 G-버퍼에 저장됩니다.라이팅 패스는 G-버퍼의 머티리얼 인덱스를 읽고 그에 따라 글로벌 머티리얼 데이터 배열을 인덱싱합니다.
하나의 128비트 uint4 안에 16비트 플로트 8개를 비트 패킹합니다. 이렇게 하면 하나의 인덱싱된 로드를 사용하여 전체 머티리얼을 로드할 수 있습니다.
GLSL에는 하나의 정수에서 두 개의 반 부동 소수점을 언패킹하는 기능이 내재되어 있습니다. 이는 32비트 레지스터의 상/하반부에 16비트 값을 저장하기 때문에 많은 GPU에서 무료로 사용할 수 있습니다.
CPU 측에서는 NEON 벡터 명령어를 사용하여 머티리얼 데이터를 fp16으로 변환하고 프레임당 한 번씩 GPU에 씁니다.
그리기 호출은 더 이상 머티리얼 처리를 수행하지 않습니다. 이를 통해 복잡한 씬에서 약 1ms의 CPU 시간을 절약할 수 있었습니다.

물리 기반 렌더링(PBR) 파이프라인의 초기 주요 목표는 시각적 충실도를 개선하는 것이었습니다.
사람들은 더 사실적으로 보이고 더 성숙한 시청자를 플랫폼으로 끌어들일 수 있는 콘텐츠를 만들고 싶어했습니다. 하지만 지난 10년 동안 픽사, 디즈니 등이 여러 차례 입증한 것처럼 PBR은 사실적인 그래픽뿐만 아니라 카툰 스타일의 그래픽에도 잘 작동한다는 점에 유의하는 것이 중요합니다.
PBR은 아티스트의 워크플로와 반복 작업에 도움이 됩니다. DCC 툴은 우리는 엔진과 동일한 PBR 이미지를 렌더링합니다. 아티스트는 더 이상 게임에서 에셋을 확인하기 위해 엔진으로 에셋을 임포트할 필요가 없습니다.
우리는 인기 있는 DCC 툴을 대상으로 여러 번의 검증을 거쳐 비주얼을 매우 가깝게 일치시킬 수 있었습니다. 개발 과정에서 기준이 되는 비교 지점을 확보한 것이 매우 유용했습니다.
하이프하이프는 클라우드 서버에 에셋 라이브러리를 보유하고 있습니다. 이 라이브러리는 모든 게임에서 공유되며 사용자는 새로운 에셋을 이 라이브러리로 가져올 수 있습니다.
이전 애드혹 렌더러에서는 각 머티리얼에 조명과 주변 색상을 정의했습니다. 예를 들어 일몰 장면을 만들려면 머티리얼의 앰비언트 컬러를 노란색으로 설정해야 했습니다. 이 때문에 동일한 에셋을 다른 씬에 로드하는 것이 번거로웠습니다.
PBR은 오브젝트, 머티리얼, 조명 환경이 완전히 분리된 개념이기 때문에 콘텐츠 이식성 문제를 해결합니다. 오브젝트와 머티리얼은 모든 조명 환경에서 올바르게 보입니다. 따라서 게임 간에 콘텐츠를 훨씬 쉽게 공유할 수 있습니다.
또한 틱톡과 같은 동영상 플랫폼과 유사한 빠른 비주얼 리믹스 기능을 추가하고 싶었습니다. 틱톡의 동영상 필터는 매우 인기가 높습니다.
우리 비주얼 스타일에는 포스트 프로세스 효과, 직접 조명, 앰비언트 조명, 안개 및 배경 설정이 포함됩니다.
사용자는 비주얼 스타일을 변경하여 기존 콘텐츠를 쉽게 리믹스하거나 테마를 편집하고 각각의 개별 설정을 수동으로 수정할 수 있습니다.
향후에는 플랫폼 간 콘텐츠 이동성을 개선하고자 합니다. 인터넷에는 수많은 에셋이 있으며, AI는 더 빠르게 생성할 것입니다. GLTF2 및 이와 유사한 형식이 중요합니다. 모든 타사 도구가 PBR을 사용하므로 호환성을 확보해야 합니다.

우리의 PBR 조명 파이프라인은 일부러 표준 프리미티브로 구축했습니다. 이는 호환성을 보장하기 위한 것입니다.
D = GGX, G = 스미스, F = 슐릭.PBR 조명 연산이 복잡하기 때문에 이를 최적화하는 데 많은 시간을 할애했습니다.
모바일에서는 fp16이 두 배 속도로 실행되므로 모든 PBR 연산을 fp16으로 실행하는 것이 중요합니다.
라이팅 수학을 fp16으로 포팅하는 것은 의외로 쉬웠습니다. 가장 큰 문제는 하이라이트에서 정밀도 문제가 있는 GGX 공식이었습니다.
저희는 라그랑주의 아이덴티티를 GGX 공식에 사용해 저정밀도 부동소수점 실행에 더 안정적으로 만들자는 Filament의 아이디어를 차용했습니다. 이를 통해 몇 가지 명령어(교차 곱)가 추가되었지만 변환 없이 모든 조명 수학을 fp16으로 유지할 수 있었습니다.
언더플로우와 오버플로우를 방지하기 위해 러프니스와 HDR 출력을 클램핑해야 했지만 큰 문제는 아니었습니다. fp16 렌더 타깃의 fp32 조명은 이미 클램핑이 필요하기 때문입니다.제작 과정에서 다양한 fp16 정밀도 문제가 발생했습니다.
fp16 파이프라인은 좋은 상태를 유지하기 위해 전체 프로젝트 기간 동안 더 많은 테스트와 조정이 필요했습니다.
간접 조명의 경우 옥트 맵을 사용합니다. 이는 큐브 맵과 비슷하지만 NxN 텍스처로 패킹할 수 있습니다. 바깥쪽 가장자리에 심을 추가하면 HW 필터링이 가능합니다.
구형 PowerVR GPU에서 더 빠르게 실행할 수 있다는 장점이 있습니다. 이전 버전에서는 명시적 밉 레벨을 사용한 ¼ 비율 큐브맵 필터링이 있었습니다. 우리는 디바이스에서 전체 게임 에디터를 실행하고 레벨 로드 시 이러한 옥트맵을 생성하기 때문에 옥트맵도 신경 썼습니다. 생성, 라이팅 및 컨볼루션 성능에도 신경을 썼습니다. 옥트맵을 사용하면 이 모든 단계를 단일 렌더 패스로 실행할 수 있습니다. 큐브맵은 얼굴당 하나씩 총 6번의 패스가 필요합니다. 표준 2D 텍스처 아틀라스에서 옥트맵을 아틀라스화할 수도 있는데, 이는 WebGL2에서 중요합니다(큐브맵 어레이는 지원하지 않음).

올가을에 출시될 로컬 조명 시스템에 대해 이야기해 보겠습니다.CPU 측의 타일에 대한 조명을 32x32 타일로 비닝하고 있습니다. 타일당 64비트 라이트 마스크. CPU는 타일 맵을 채우기 위해 소프트웨어 래스터를 수행합니다. 전체 타일 맵 데이터는 CPU L1$에 들어맞기 때문에 단일 CPU 스레드를 사용하여 매우 효율적으로 수행됩니다.
렌더링: 한 번의 그리기 호출로 동일한 조명 세트(동일한 비트마스크)로 모든 타일을 한 번에 렌더링합니다. 드로 콜 사이에 새 타일 세트 조명을 UBO에 범프 할당하고 UBO 바인딩 시작 오프셋을 변경합니다.지원되는 각 광원 수 및 유형 순열에 대해 하나의 셰이더 순열이 있습니다. 이렇게 하면 느린 인덱싱 로드 경로를 피하면서 고정된 UBO 주소에서 조명 데이터를 읽을 수 있습니다. 최대 8개의 포인트 광원과 8개의 스팟 광원에 대한 조명 셰이더 순열을 컴파일한다고 가정해 봅시다.
타일에 8개보다 더 많은 광원이 있는 경우 다음 드로 콜에서 애디티브 블렌딩을 사용하여 나머지 광원을 실행합니다.
TBDR 아키텍처는 타일 메모리에서 블렌딩하므로 렌더 타깃 쓰기 및 읽기를 위한 추가 메모리 대역폭이 필요하지 않습니다.또한 언롤링된 조명 셰이더의 레지스터 부풀림을 제한합니다.
저사양 디바이스에서는 복잡한 셰이더가 문제가 될 수 있습니다.
각 조명에 대해 저장된 Z-얼리 아웃 최소/최대값이 있습니다. 픽셀이 이 바운드에 속하지 않으면 조명이 건너뛰게 됩니다. 모든 스레드가 동일한 조명을 일관되게 건너뛰는 것이 일반적입니다. 소스(예: 벽 뒤)를 일관되게 건너뛰는 것이 일반적입니다.
앞으로는 저해상도 최소/최대 Z 버퍼를 기반으로 조명을 컬링하는 패스를 계산할 것입니다.
이것이 바로 조명 전에 메모리에 Z-버퍼를 두는 이유 중 하나입니다.

간접광을 베이크할 수 없으므로 이를 위한 런타임 솔루션이 필요합니다.
앰비언트 오클루전은 좋은 출발점입니다.저희의 요구에 맞는 솔루션을 찾기 전까지 여러 가지 SSAO 알고리즘을 구현해 보았습니다.
이제 SSAO 알고리즘의 간략한 역사를 살펴보겠습니다. 크라이텍은 비디오 게임에서 SSAO를 대중화했습니다.
이 회사의 독창적인 기술은 표면에 무작위로 분포된 N개의 3D 포인트를 샘플링하는 것이었습니다. 각 샘플에 대해 NDC로 투영하고 포인트 Z 값과 포인트 위치의 Z 버퍼 값을 비교했습니다. 샘플링 포인트가 더 가까우면 해당 샘플은 보이는 것으로 간주하고 그렇지 않으면 숨겨진 것으로 간주했습니다. 이렇게 하면 각 텍스처 샘플링 작업당 단일 비트의 데이터가 제공됩니다.
그런 다음 보이는 비트의 수를 세고 샘플 수로 나누어 가시성 근사치를 구합니다.사람들은 이 원래 알고리즘의 문제를 금방 알아차렸습니다. 첫 번째 개선 사항은 픽셀의 노멀 벡터를 사용하는 것이었습니다. G-버퍼에는 이미 노멀 벡터가 포함되어 있으므로 이를 간단히 사용할 수 있습니다. 노멀 벡터 아래의 샘플(음의 점 곱)은 위쪽 반구에 미러링됩니다. 이렇게 하면 품질과 성능이 모두 향상됩니다. 표면을 벗어난 바깥쪽 가장자리 샘플링으로 인한 후광이 수정되어 샘플당 두 배의 효율성을 얻었습니다.이후 여러 저자들이 샘플링 패턴을 개선하여 이 기술을 더욱 개선했습니다.
정상 방향에 가까운 샘플이 많을수록 코사인 로브 중요도 샘플링과 유사하며 더 나은 근사치를 제공합니다. 멀리 떨어진 샘플의 메모리 액세스 패턴을 개선하기 위해 Z 버퍼에 밉 맵이 추가되었습니다.하지만 이러한 개선 사항으로는 표면의 관점에서 가려진 가시 샘플을 계산하는 문제를 해결할 수 없었습니다. 좁은 표면에서는 빛이 새어 나왔습니다.
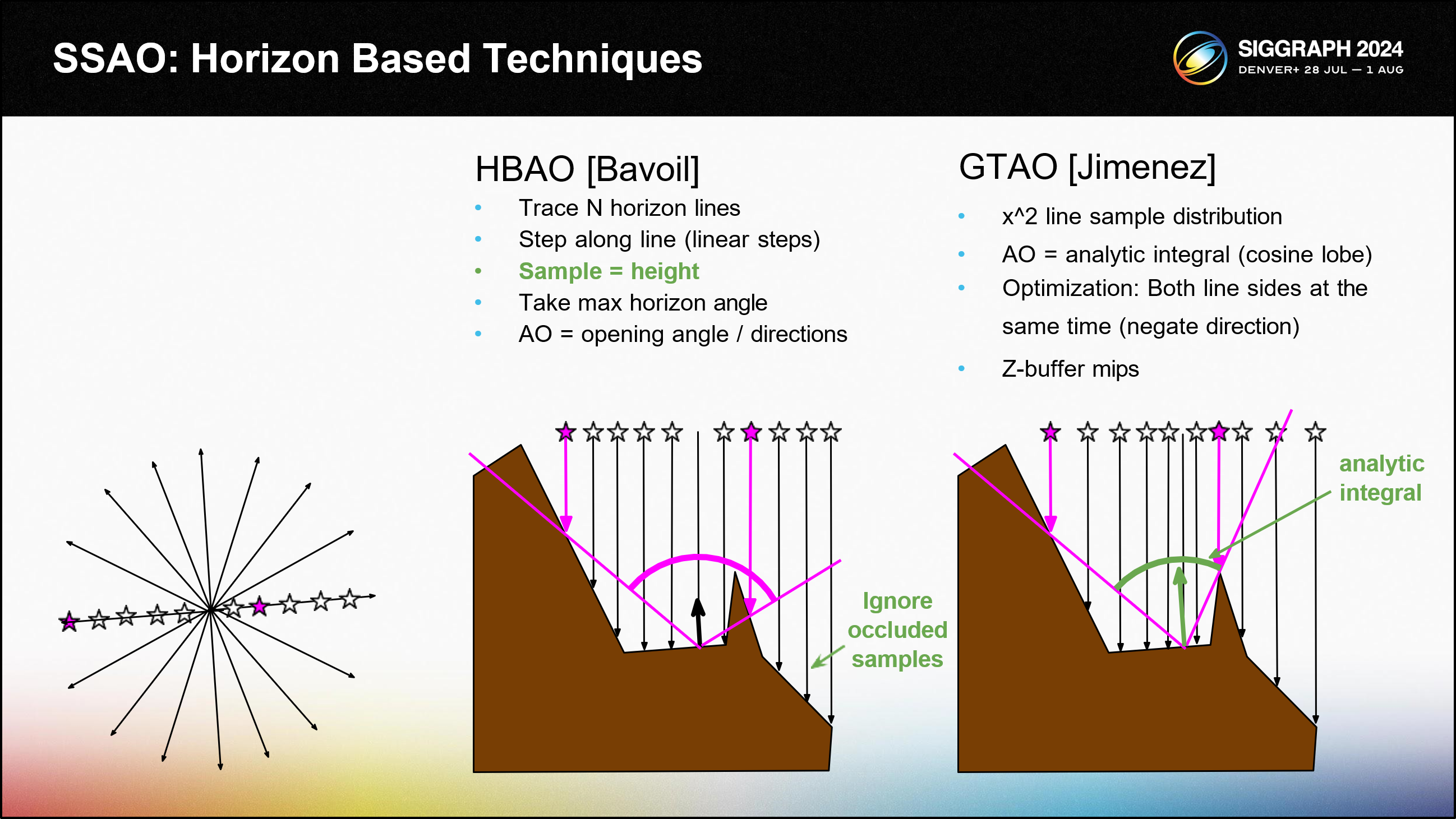
Horizontal 기반 앰비언트 오클루전(HBAO)으로 빛샘 문제를 해결했습니다. 무작위 샘플링에 의존하는 대신 화면 공간에서 N개의 수평선을 추적합니다. 각 라인은 N개의 선형 스텝으로 단계적으로 추적됩니다. 각 단계마다 Z-버퍼가 샘플링됩니다. 개방 각도는 Z-버퍼 깊이를 사용하여 계산됩니다. 그리고 최소(가장 제한적인) 각도가 사용됩니다. 이는 이전 슬라이드의 샘플당 1비트에 비해 효율성이 크게 개선된 것입니다. 이제 각 샘플에서 전체 각도를 얻습니다. 라인 트레이스가 완료되면 개방 각도를 가시성 추정치로 사용하기만 하면 됩니다.
가장 진보된 HBAO 스타일의 알고리즘은 GTAO(기준 진실 앰비언트 오클루전)라고 합니다. 이 알고리즘은 여러 가지 방식으로 개선되었습니다. 고정된 크기의 선 샘플링 단계는 깊이 차이가 각도에 더 큰 영향을 미치는 지점에 더 가까운 단계를 샘플링하는 x^2 분포로 대체되었습니다. 가시성 추정치는 노멀 벡터를 최소/최대 각도 공간에 투영하여 계산되며, 여기서 분석적 코사인 적분을 사용하여 적절한 가중치를 부여한 적분을 계산합니다.
GTAO는 또한 HBAO보다 두 가지 최적화를 도입했습니다. 가장 진보된 포인트 샘플 알고리즘(마지막 슬라이드)과 마찬가지로 Z-버퍼 밉 레벨을 사용했으며 각 선분을 양방향으로 동시에 추적했습니다. 음의 방향은 단순히 화면 공간 샘플 오프셋을 음수화하기만 하면 되며, 이는 자유롭게 계산할 수 있습니다. 이렇게 하면 다양한 라인 설정 오버헤드 비용을 절반으로 줄일 수 있습니다.

앰비언트 오클루전 알고리즘은 GTAO를 기반으로 합니다. 저는 알고리즘을 미세 최적화하기 위해 모든 지식을 습득하고 싶었기 때문에 알고리즘을 처음부터 다시 작성했습니다.
첫 번째 최적화는 내부 루프(4방향)에서 1(HBAO) 또는 2(GTAO) 대신 전체 크로스를 추적하는 것이었습니다. 이렇게 하면 라인 설치 비용이 더욱 절감됩니다.
수직선 계산은 무료(-y, x)입니다.2x2 쿼드 이웃 데이터 공유를 구현했는데 노이즈를 줄이는 데 큰 도움이 되었습니다. 저는 이를 체인화된 미세 도함수를 사용하여 구현했는데, 이는 Vulkan과 Metal에서 잘 작동했습니다. 하지만 GLES3(웹용 WebGL2 백엔드는 여전히 사용 중)는 미세 파생형을 지원하지 않습니다.
GLES에는 미세 파생물 요청에 대한 힌트가 있지만 ARM 및 Qualcomm 드라이버는 이 힌트를 무시합니다. 그 결과 아직 이 품질 및 성능 최적화를 제공하지 못하고 있습니다.
우리의 GTAO는 100% fp16 코드이며 텍스처 룩업 대신 ALU 기반 노이즈를 사용합니다. 이는 모바일에서 텍스처 샘플러가 느리기 때문입니다. SSAO는 절반 해상도로 실행되며 라인 세그먼트당 3개의 샘플만 수행합니다. 이는 각 샘플이 1비트 결과 대신 각도를 제공하기 때문에 가능합니다. 크로스에는 총 12개의 샘플이 있으며 픽셀당 하나의 크로스를 실행합니다. 각도와 오프셋에 대한 4x4 공간 노이즈는 64개 방향 샘플 커버리지를 충분히 제공합니다.
4x4 양방향 박스 블러는 결과를 흐리게 하는 데 사용됩니다. 4x4 노이즈 영역이 반복되므로 어느 위치에서든 박스 블러를 적용할 수 있습니다. 모든 샘플링 방향을 포함합니다.양방향 업스케일은 SSAO를 업스케일링할 때 품질에 매우 중요합니다. 이미지에는 양방향 업스케일링이 적용되지 않은 가장자리가 절반 해상도로 보입니다.
양방향 업스케일러는 단순히 2x2 저해상도 에지 방향에서 한 번만 수집4을 수행하므로 항상 4개의 다른 값이 생성됩니다. 사용 가능한 경우 픽셀 자체 값을 선택하고 이웃 픽셀 중 가장 가까운 픽셀로 폴백합니다.향후에는 하향식 Z 버퍼 기반의 장거리 안정적 AO를 추가하여 하늘 가시성을 더 잘 추정할 수 있도록 할 계획입니다. 또한 스페큘러 오클루전 및 일부 화면 공간 GI 근사치를 구현하기 위해 GTAO 데이터를 사용하여 실험할 예정입니다.

포스트 프로세싱은 메모리 라운드 트립을 피하기 위해 단일 패스 디자인으로 설계되었습니다. 100% fp16 코드입니다.
블룸은 (에너지 절약을 위해 애디티브 대신) 물리 기반 블렌드를 사용합니다. 톤맵은 최적화된 ACES 커브를 기반으로 합니다.
컬러 그레이딩은 16x16x16 LUT를 사용합니다. 포스트 프로세스 슬라이더가 변경될 때마다 CPU 측에서 LUT를 생성합니다. 밝기, 대비, 채도, 색조, 그림자/중조/하이라이트 등의 설정을 지원합니다. 또한 세피아, 씬 시티와 같은 사용자를 위한 프리셋도 있습니다.
비네팅은 셰이더의 끝 부분에 추가됩니다.

하이프하이프에는 아직 텍스처가 부족합니다. 텍스처 파이프라인에 대해 말씀드리고 싶었지만, 현재 상황과 내년 가을에 대한 향후 계획에 대해 이야기해 보겠습니다.
10MB 게임 바이너리 크기 제한으로 인해 기존 텍스처를 구현하기가 매우 어렵습니다. 우리는 텍스처 데이터를 최대한 압축하고 게임 로딩 중에 데이터를 더 확장하는 기술을 사용하고자 합니다.
우리는 실시간 ASTC4x4 / BC7 블록 압축기 개발에 공동 투자했습니다. 이그나시오 카스타노가 개발한 이 인코더의 이름은 Spark(https://ludicon.com/spark/)입니다. 이 인코더의 품질은 최고의 오프라인 압축기보다 약간 낮지만, 저사양 휴대폰에서 1초에 최대 천 개의 1024x1024 ASTC4x4 텍스처를 압축할 수 있을 정도로 매우 빠릅니다.
이를 통해 클라우드 서버의 텍스처 에셋에 최첨단 손실 압축기를 사용할 수 있습니다. 2bpp AVIF와 JXL로 실험해본 결과 품질이 매우 좋아 보입니다. AVIF는 최신 휴대폰에서도 HW로 디코딩할 수 있습니다(Vulkan Video API). 디코딩된 RGBA8은 실시간 GPU 압축을 위해 Spark로 전송됩니다.
KTX2/Basis와 같은 기존의 초압축 포맷을 사용하지 않는 이유는 무엇인가요? 하이프하이프에 머티리얼 컴포저를 도입할 계획이 있습니다. 머티리얼 컴포저는 기본적으로 '미니 머티리얼 페인터'로, 사용자가 휴대폰에서 자신만의 머티리얼을 만들 수 있습니다. 머티리얼은 여러 텍스처 레이어와 데칼로 구성되므로 텍스처 저장 용량이 매우 적은 경우에도 다양한 텍스처를 구현하고 타일링을 숨길 수 있습니다.

이렇게 생겼습니다. 왼쪽에는 작년 가을의 스크린샷이 있습니다. 이전 렌더링 파이프라인을 사용하고 있습니다.
오른쪽에는 새로운 기능이 모두 포함된 새로운 PBR 파이프라인이 있습니다: PBR 조명(직접 및 간접), GTAO, 캐스케이드 섀도 매핑, LOD, 인스턴스 렌더링, PBR 블룸(밉 체인), 컬러 그레이딩 및 ACES 톤 매핑. 이 모든 것을 8개월 만에 구현했습니다.
여기에 표시된 게임은 2년 된 UGC 게임입니다. 게임 콘텐츠는 전혀 변경하지 않았습니다. 100% 동일한 장면입니다. 하지만 5분 동안 이 게임의 조명 환경을 더 보기 좋게 리믹스하고, 새로운 기술이 훨씬 더 큰 장면을 실행할 수 있는 성능을 갖추었기 때문에 드로우 거리를 개선했습니다.

'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [주석번역] Variable Rate Shading with Visibility Buffer Rendering : 존헤이블|시그라프2024|파트 (1) | 2024.08.19 |
|---|---|
| [주석번역] Seamless Rendering on Mobile: The Magic of Adaptive LOD Pipeline | 시그라프 2 (1) | 2024.08.19 |
| [주석번역] Mobile Graphics 101 : Siggraph 2024 : Samsung. (0) | 2024.08.15 |
| Vulkan Study Stuff. (0) | 2024.08.10 |
| [발표번역] GDC2024. GLOBAL ILLUMINATION WITH BRIXELIZER SDK UPDATES. (0) | 2024.08.10 |