
역자의 말 : 슌 차오 선생의 발표에서 언급 되었던 존 헤이블 형님의 비즈버퍼에 대한 강연 내용입니다. 정말 시간이 흘러갈 수록 알아야 할 것들이 늘어만 가는데 나이가 들 수록 머리속의 저장소는 줄어 들기만 하고 꼭 무슨 사타 하드드라이브 처럼 노후가 오면 드륵 드륵 걸리는 느낌이지 말입니다. 어찌되었건 우리는 또 지하철 몇 정거장을 숏폼이나 보는 시간으로 보내지 않고 뭐 하나라도 머리속에 넣을 수 있게 되었네요. 파트1과 파트2로 나눴습니다. 이미지 첨부가 70개를 넘어가면 티스토리가 엄청 느려지는 현상이 있는데 해결을 안하더라고요... 부득이 나눴지만~ 자 ~ 읽어 보시죠.
Abstract: 비저빌리티 버퍼 렌더링은 실시간 렌더링에 대한 대안적인 접근 방식이며, GBuffer 및 포워드 렌더링과 비교했을 때 몇 가지 장단점이 있습니다. 하지만 비저빌리티 버퍼 렌더링의 가장 흥미로운 특성은 셰이딩 속도가 네이티브 렌더링 해상도와 완전히 분리된다는 점입니다. 이 강연에서는 시각적 충실도를 유지하면서 음영 처리되는 픽셀 수를 줄이는 방법과 이 접근 방식의 장단점에 대해 설명합니다.

John Hable 그는 일렉트로닉 아츠, 너티독, 에픽게임즈, 유니티에서 경력을 쌓은 렌더링 프로그래머입니다.

안녕하세요. 강연에 오신 것을 환영합니다. 오늘은 비저빌리티 버퍼 렌더링과 가변 비율 셰이딩에 대해 알아보겠습니다.

저는 오랫동안 콘솔 게임과 엔진 분야에서 주로 일해왔지만, 영화 프리비즈용 사진 측량 리그와 VC캠 제작과 같은 다른 프로젝트도 진행했습니다. 작년 11월까지는 유니티에서 나타샤의 그래픽스 그룹에서 일했습니다. 그 시점에서 저는 스타트업의 모험을 시작하기 위해 유니티를 떠났습니다: 이제 저는 Visible Threshold 의 창업자가 되었습니다.

약간의 맥락을 알려드리자면, 가시성 임계값은 웹용 USD입니다. USD 생태계는 매우 빠르게 성숙하고 있으며, 특히 OpenPBR이 1.0 릴리스에 도달했습니다. 동시에 WebGPU가 공식적으로 출시되어 주요 브라우저에서 채택되고 있습니다. 따라서 가시 임계값의 목표는 USD 장면을 독립형 웹 경험으로 전환하는 워크플로 문제를 파악하는 것입니다.

왜 이렇게 하나요?

핵심은 우리 눈은 픽셀을 보지 않는다는 것입니다. 그보다는 그라데이션을 본다는 것입니다. 눈은 이러한 그라데이션을 조합하여 환각 이미지로 만드는 신경망입니다.

이 이미지를 향상시키고 지오메트리 테두리 중 하나에 초점을 맞춰 보겠습니다.

녹색으로 선택된 두 픽셀 중 하나는 태양으로부터 직접 조명을 받고 그 뒤에 있는 픽셀은 간접적으로 반사되는 빛만 받습니다. 결과적으로 결과 이미지에 날카로운 휘도 가장자리가 생깁니다.

노란색에서는 두 개의 픽셀이 선택됩니다. 이 그라데이션은 중요하지만 녹색으로 선택된 픽셀보다 훨씬 덜 중요합니다.

마지막으로 빨간색으로 선택된 두 개의 픽셀이 있습니다. 픽셀 간의 차이가 눈에 띄지 않으므로 이 그라데이션은 훨씬 덜 중요합니다.

가변 속도 셰이딩을 사용하면 씬에서 이러한 강한 가장자리를 유지할 수 있습니다. 그러면 지오메트리 에지 내에서 샘플 속도를 줄일 수 있으며 렌더링 시간을 단축하면서 지각적으로 유사한 이미지를 얻을 수 있습니다.

이 강연의 목표는 가시성 버퍼를 사용하여 지오메트리 속도와 셰이딩 속도를 완전히 분리하여 원하는 샘플 패턴을 사용할 수 있도록 하는 것입니다. 그런 다음 에지 인식 재구성을 사용하면 씬의 주요 에지를 항상 보존하면서 샘플링 속도와 성능을 맞바꿀 수 있습니다.

시작하기 전에 비저빌리티 버퍼를 사용한 렌더링에는 많은 작업이 필요하다는 점을 말씀드리고 싶습니다.

가변 비율 셰이딩에 대한 다양한 접근 방식도 살펴보세요.

비저빌리티 버퍼 렌더링과 VRS를 본격적으로 살펴보기 전에 먼저 쿼드 활용에 대한 확실한 이해가 필요합니다.

GPU는 마술이 아닙니다. 그리고 이를 프로그래밍하는 데 사용하는 픽셀 셰이더 인터페이스는 미묘한 세부 사항과 성능에 미치는 영향을 숨기고 있습니다.

기억해야 할 가장 중요한 점은 픽셀 셰이더는 항상 쿼드라고 하는 4개 그룹으로 호출된다는 것입니다. 메인PS 함수는 하나만 처리하지만 내부적으로는 항상 한 번에 4픽셀을 실행합니다.

삼각형을 렌더링할 때 전체 2x2 쿼드를 다 채우지 못하면 빈 픽셀이 계속 실행되어야 합니다. 화면에 표시되도록 렌더링 중인 픽셀을 "활성 레인"이라고 하고 곧 버려질 픽셀 셰이더 호출을 "헬퍼 레인"이라고 합니다.

세 개의 서로 다른 삼각형이 하나의 2x2 정사각형을 덮고 있는 예를 살펴보겠습니다.

녹색 삼각형은 활성 차선 1개와 헬퍼 차선 3개가 있는 쿼드, 파란색 삼각형은 활성 차선 2개와 헬퍼 차선 2개가 있는 쿼드, 빨간색 삼각형은 활성 차선 1개와 헬퍼 차선 3개가 있는 쿼드입니다.

이제 이렇게 생각할 수도 있습니다: "비효율적이지 않나요?"라고 생각할 수도 있습니다. 정답은 "그렇다"입니다. GPU에 대한 제 머릿속 모델에서는 쿼드를 오버드로라고 생각하는데, 픽셀이 하나만 보이는데도 GPU가 픽셀 셰이더를 여러 번 실행해야 하기 때문입니다.

이제 큰 삼각형이 있다면 추가 헬퍼 차선은 큰 문제가 되지 않습니다. 활성 차선이 너무 많고 헬퍼 차선이 너무 적기 때문에 헬퍼 차선의 비용은 미미합니다.

하지만 작은 삼각형의 경우 큰 문제가 있습니다. 하나의 픽셀만 차지하는 단일 삼각형은 여전히 전체 2x2 쿼드가 필요합니다.

물론 대부분의 게임 삼각형은 가운데에 있습니다. 다음은 10픽셀 트라이앵글의 예시이며, 헬퍼 레인의 오버헤드가 약간 있습니다.

그러나 도우미 레인의 수는 삼각형이 화면 그리드에 정렬되는 방식에 따라 달라집니다. 그리고 평균적으로 이 삼각형은 1.9배의 비용이 듭니다.

삼각형이 길고 얇은 경우 일반적으로 조금 더 심해집니다. 이 경우 L자형 8x2 삼각형은 평균 2.1배의 쿼드 오버드로가 발생합니다.

실제로 일어날 가능성은 거의 없지만 최악의 경우를 예로 들어보겠습니다. 초과 인출 비용이 3.2배가 됩니다.
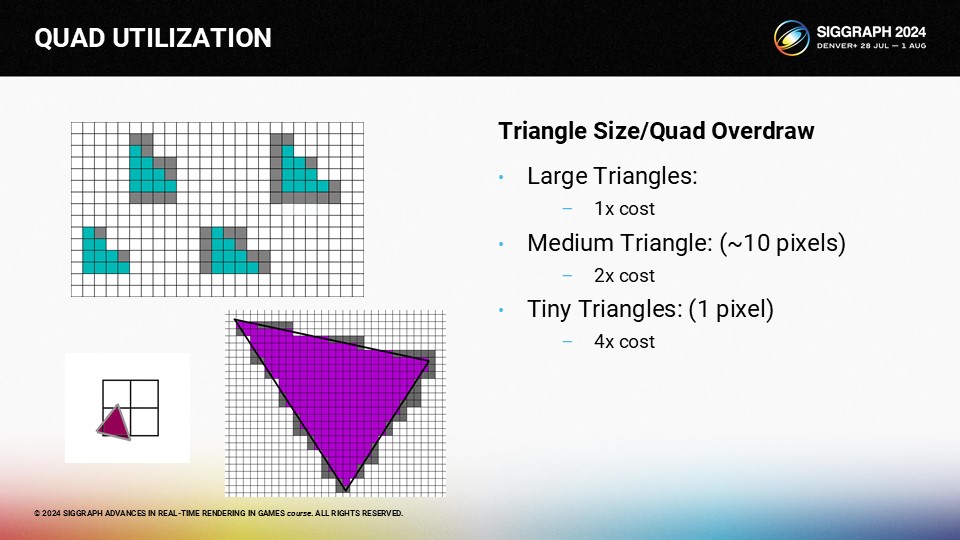
원한다면 모든 삼각형 패턴을 측정할 수 있지만 단순화해서 생각해 보세요. 큰 트라이앵글이 있다면 쿼드 오버드로는 중요하지 않습니다. 작은 1픽셀 트라이앵글이 있다면 4배의 비용을 지불해야 합니다. 그리고 10픽셀 내외의 일반적인 게임 트라이앵글의 경우 2배의 비용을 지불합니다.
이 강연에서 여러분이 기억했으면 하는 가장 중요한 점은 바로 이 점입니다. 쿼드 오버드로에 대해 이야기할 때 대부분의 사람들은 초밀도 메시를 대상으로 하는 경우에만 중요하다고 생각합니다. 하지만 2배 오버드로도 여전히 많은 양입니다. 트라이앵글의 크기가 10픽셀이라면 현재 출시 중인 게임에서 쿼드 오버드로에 상당한 비용을 지불하고 있는 것입니다.

이제 픽셀 셰이더 비용을 줄일 수 있는 옵션 중 하나인 하드웨어 VRS가 쿼드 오버드로에 어떤 영향을 미치는지 살펴보겠습니다.

앞서 언급했듯이 화면은 2x2 쿼드로 나뉩니다. 삼각형이 이 4개의 픽셀 중 하나에 닿으면 2x2 쿼드를 호출해야 합니다.

앞서 언급했듯이 화면은 2x2 쿼드로 나뉩니다. 삼각형이 이 4개의 픽셀 중 하나에 닿으면 2x2 쿼드를 호출해야 합니다.

앞서 언급했듯이 화면은 2x2 쿼드로 나뉩니다. 삼각형이 이 4개의 픽셀 중 하나에 닿으면 2x2 쿼드를 호출해야 합니다.

VRS에서도 동일한 개념이 적용되지만 쿼드가 더 크다는 점이 다릅니다. 2x2 VRS의 경우, 삼각형이 16픽셀 중 하나에 닿으면 2x2 쿼드를 호출해야 합니다.

다시 한 번 말하지만, 큰 삼각형의 경우 도우미 차선의 비용은 미미합니다. 이 경우에도 헬퍼 레인이 추가되기 시작합니다.

1픽셀 삼각형의 경우, 각 삼각형은 쿼드를 스폰합니다. 터치한 픽셀은 전체 2x2 쿼드를 스폰해야 하므로 VRS 활성화 여부는 중요하지 않습니다.

마지막으로 10픽셀 삼각형의 경우 픽셀당 약 1회의 PS 호출로 끝납니다.

대략적인 수치로 돌아가서, 큰 삼각형은 하드웨어 VRS에 적합합니다. 하지만 작은 트라이앵글은 여전히 4배의 페널티를 지불합니다. 그리고 10픽셀 트라이앵글은 1배 정도인데, 이는 VRS를 사용하지 않는 것보다는 낫지만 우리가 원하는 만큼 좋지는 않습니다.

우리가 이상적으로 바라는 것은 이와 같은 것이며, 이것이 이 프레젠테이션의 요점입니다. 삼각형 크기에 관계없이 모든 곳에서 0.25배의 비율을 얻을 수 있다면 어떨까요? 실제로는 가능하지만 약간의 오버헤드를 지불해야 합니다.


비저빌리티 버퍼 렌더링에 대해 이야기하기 위해 먼저 한 걸음 물러나 포워드 렌더링에 대해 살펴보겠습니다.
포워드 렌더링에서 픽셀 셰이더는 버텍스에서 보간기를 가져옵니다.
그런 다음 보간기를 가져와 BRDF 데이터를 계산하는 머티리얼 평가 함수가 있습니다. 또한 머티리얼 데이터를 가져와 결과 조명을 계산하는 조명 평가 함수도 있습니다.


비저빌리티 버퍼 렌더링에 대해 이야기하기 위해 먼저 한 걸음 물러나 포워드 렌더링에 대해 살펴보겠습니다.
포워드 렌더링에서 픽셀 셰이더는 버텍스에서 보간기를 가져옵니다.
그런 다음 보간기를 가져와 BRDF 데이터를 계산하는 머티리얼 평가 함수가 있습니다.
또한 머티리얼 데이터를 가져와 결과 조명을 계산하는 조명 평가 함수도 있습니다.



디퍼드 렌더링은 이를 두 개의 패스로 나눕니다. 머티리얼 데이터를 버퍼에 쓰는 첫 번째 픽셀 셰이더가 있습니다. 그리고 두 번째 패스(픽셀 셰이더 또는 컴퓨트 셰이더)가 해당 머티리얼 데이터를 가져와 조명을 평가하고 결과를 씁니다.



가시성 버퍼 렌더링은 이를 한 번 더 분할합니다. 첫 번째 패스는 트라이앵글 ID를 씁니다. 그게 다입니다. 그런 다음 머티리얼 패스는 트라이앵글 ID를 가져오고, 보간기를 가져오고, 머티리얼을 평가하고, GBuffer를 작성해야 합니다. 그런 다음 조명 패스는 이전과 동일합니다.

이제 작은 1픽셀 트라이앵글이 있는 경우 세 가지 접근 방식 모두에 대한 비용은 어떻게 될까요? 포워드의 경우 단일 패스가 있고 머티리얼과 조명 픽셀 셰이더가 결합되어 4배 오버드로로 실행됩니다. 디퍼드에서는 머티리얼 패스는 4배 오버드로로 실행해야 하지만 조명은 1배로 실행됩니다. 그리고 V버퍼를 사용하면 머티리얼과 조명 모두 픽셀당 한 번만 실행됩니다. 하지만 단점은 복잡성이 증가한다는 것입니다.

VBuffer 렌더링의 개요를 살펴보면 몇 가지 까다로운 세부 사항이 있습니다.

먼저, V버퍼를 쓰는 패스에서 트라이앵글 ID를 정확히 어떻게 구할 수 있을까요?

둘째, 보간기는 어떻게 가져올까요? 하드웨어가 더 이상 보간기를 자동으로 가져올 수 없습니다.

셋째, 재료 평가는 동일하지만 밉매핑을 위한 파생물을 계산하는 방법을 알아내야 합니다.

마지막으로 이러한 픽셀을 분할하고 정렬한 다음 최종 이미지로 다시 합쳐야 합니다.

먼저 프리미티브 ID에 대해 이야기해 보겠습니다.

첫 번째 문제는 삼각형 ID의 텍스처를 어떻게 렌더링할 것인가 하는 것입니다. 우리는 큰 성능 저하 없이 모든 곳에서 작동하는 하나의 솔루션을 원합니다.

옵션이 많으니 여기 소개해드리겠습니다.

첫 번째 옵션은 SV_Primitive ID 시맨틱 또는 glsl의 gl_PrimitiveId를 사용하는 것입니다. 말 그대로 한 줄의 코드라는 점에서 매우 쉽습니다. 하지만 모든 플랫폼에서 지원되는 것은 아니며 성능에 약간의 불이익이 있습니다.



두 번째 옵션은 비색인화입니다. 이 큐브를 렌더링한다고 가정해 보겠습니다. 이 첫 번째 삼각형의 경우 세 개의 꼭지점을 렌더링해야 하며 전체 삼각형이 분홍색 ID를 갖기를 원합니다. 이를 위해 세 개의 정점을 각각 핀을 색상으로 렌더링하면 됩니다.
단점은 다음 삼각형을 렌더링할 때 다시 세 개의 꼭지점을 다른 색상으로 렌더링해야 한다는 것입니다. 따라서 이 접근 방식은 간단하고 쉽지만 정점 재사용의 이점을 잃고 각 삼각형에 대해 3개의 고유한 정점 호출이 필요합니다.


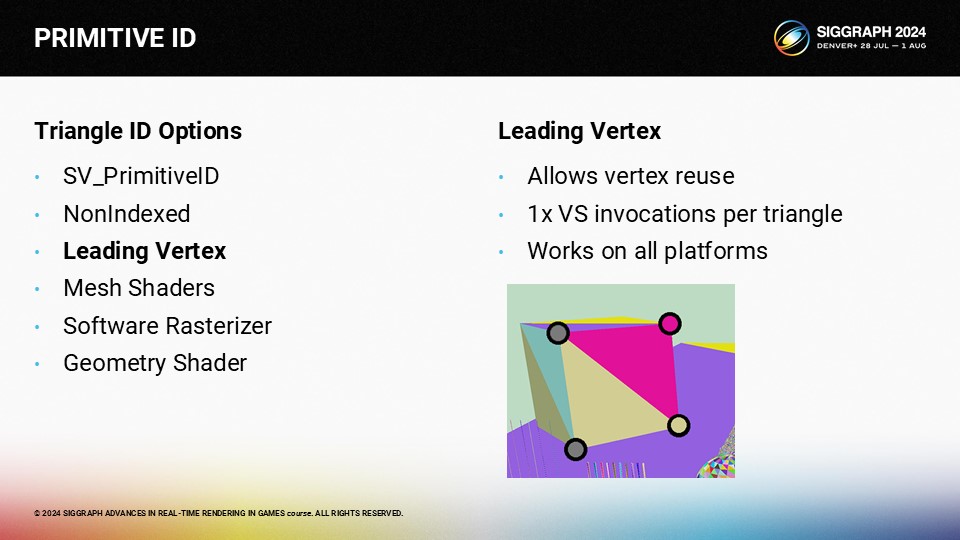
하지만 트릭이 있습니다. 보간 없음 또는 평면 음영을 사용하면 보간기는 색에 하나의 정점만 사용하고 나머지 두 정점은 무시합니다. 이 버텍스를 "자극하는" 버텍스라고 해서 이름이 붙여졌습니다.
이 경우 분홍색 삼각형의 경우 오른쪽 위 정점이 도발 정점입니다. 따라서 해당 꼭지점이 분홍색인 한 다른 두 꼭지점의 색이 무엇이든 상관없습니다.
그런 다음 노란색 삼각형의 경우 오른쪽 아래 꼭지점을 자극 꼭지점으로 사용하고 적절한 색상을 선택할 수 있습니다.
두 삼각형 모두 자극하는 꼭지점이 다르기 때문에 가장자리에서 동일한 꼭지점을 재사용할 수 있습니다. 이 접근 방식을 사용하면 삼각형당 1개의 버텍스 호출을 얻을 수 있습니다. 이론적으로 이상적인 삼각형당 버텍스 절반에는 못 미치지만, 비색인화의 삼각형당 3번의 VS 호출보다는 훨씬 낫습니다.

다음 옵션은 메시 셰이더입니다. 최소 사양이 이를 지원한다면 가장 좋은 옵션입니다. 하지만 완전한 지원과는 거리가 멀죠.

소프트웨어 래스터라이저는 일부 플랫폼에서 가장 빠른 옵션입니다. 하지만 64비트 아토믹스가 필요하고 일반적으로 큰 트라이앵글에 대한 폴백이 필요하며 모바일에서는 배터리 문제가 발생할 수 있습니다.

지오메트리 셰이더는 작동할 수 있지만 공급업체마다 성능이 매우 일관적이지 않습니다.

따라서 완전한 해결책으로 세 가지 실행 가능한 옵션이 있습니다. SV_PrimitiveID, 비색인화, 프로빙 버텍스가 작동할 수 있습니다. 메시 셰이더와 소프트웨어 래스터라이저는 나중에 최적화를 위한 좋은 후보이지만, 첫 번째 구현에는 왼쪽의 세 가지 옵션만 있습니다.

어떤 옵션을 선택할지 결정하려면 성능을 테스트해야 하는데, 이는 상당히 어려운 작업입니다. 다행히 세바스찬 알토넨이 몇 년 전에 철저한 조사를 수행하여 그 결과를 트위터에 올렸습니다. 그는 엔비디아, AMD, 인텔 컴퓨터를 각각 1대씩 테스트했습니다.

NVIDIA에서는 선행 버텍스가 가장 빠른 옵션이었습니다. SV_PrimitiveID는 약 50% 느렸고, 인덱싱되지 않은 경우 약 100% 느렸습니다.

AMD는 NVIDIA와 비슷했습니다. 선두 버텍스는 약간의 비용이 들었지만 SV_PrimitiveId와 인덱스가 없는 경우 훨씬 더 비쌌습니다.

인텔은 흥미로웠습니다. 인텔은 매우 빠른 SV_PrimitiveID를 구현했고, 선행 버텍스와 마찬가지로 거의 무료에 가까웠습니다. 인덱싱되지 않은 경우 상당한 페널티가 있었습니다.

이 모든 것을 기준선 대비 스케일 팩터로 합산한 결과, 리딩 버텍스가 확실한 승자였습니다. SV_PrimitiveID와 Non-Indexed는 다양한 성능 페널티가 있었지만, Leading Vertex는 기준선 대비 추가 비용이 기껏해야 아주 조금밖에 들지 않았습니다.

그렇다면 실제로 선행 버텍스 렌더링을 위해 클러스터의 순서를 어떻게 변경할까요? 삼각형 몇 개를 예로 들어보겠습니다.
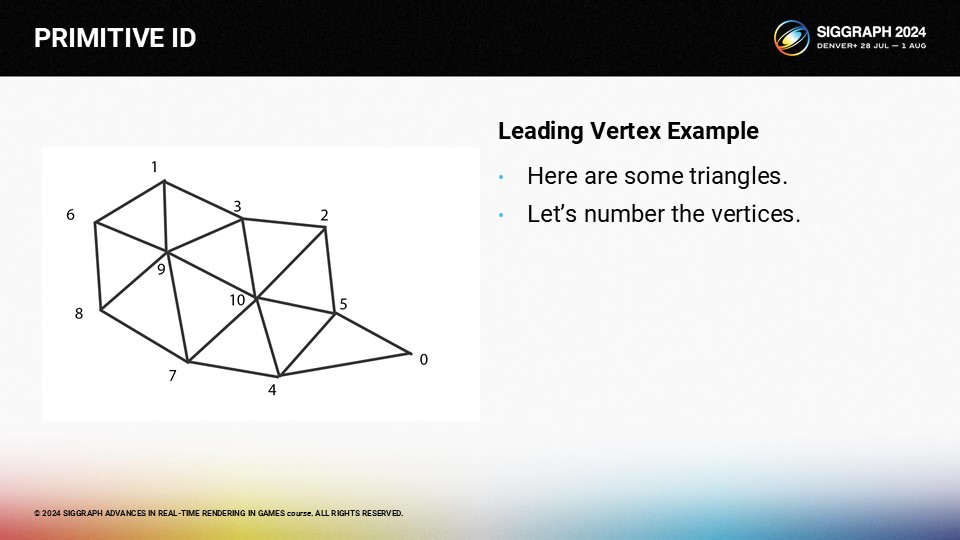
개념을 보여주기 위해 정점을 이런 식으로 정렬해 보겠습니다.

이렇게 하면 다음과 같은 색인 목록이 생성됩니다.

여기에 나열된 순서를 사용하면 이제 프리미티브 ID가 선행 버텍스 ID와 정확히 일치하도록 설정할 수 있습니다.

인덱스가 이런 식으로 배치되어 있으면 버텍스 셰이더는 매우 간단합니다. 프리미티브 아이디는 단순히 들어오는 버텍스 아이디입니다. 그리고 들어오는 인덱스를 실제 버텍스 버퍼 인덱스로 변환하려면 단일 방향이 필요합니다.

이러한 방식으로 클러스터를 최적화하는 방법은 두 단계로 나눌 수 있습니다. 첫 번째 단계는 가능한 한 많은 삼각형을 자극적인 정점으로 초기화하기 위해 빠르고 욕심스럽게 시도하는 것입니다. 그리고 두 번째 단계에서는 정점을 회전시켜 1단계에서 남은 삼각형을 채웁니다.

첫 번째 단계로 각 꼭지점에 닿는 삼각형의 수를 세는 것이 도움이 됩니다.
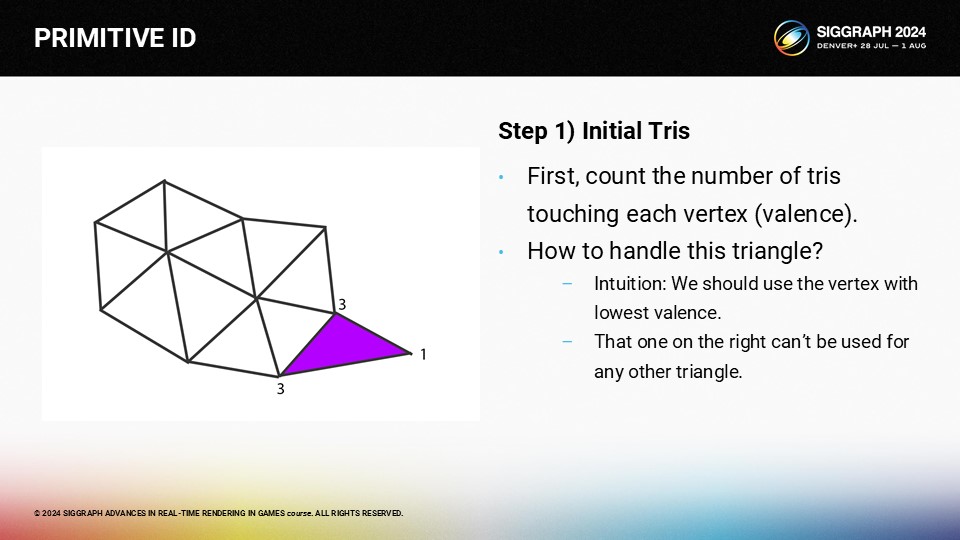
첫 번째 패스는 각 삼각형이 단순히 가장 좋은 전방 꼭지점을 선택하는 욕심 루프입니다. 직관적으로 원자가가 높은 정점은 다른 삼각형이 사용할 수 있을 가능성이 높기 때문에 가장 낮은 원자가를 가진 정점이 "최선의" 선택입니다. 또한 이 접근 방식은 테두리를 먼저 선택하는 경향이 있습니다.

따라서 이 알고리즘은 매우 간단합니다. 각 삼각형을 반복하여 사용 가능한 가장 자극적인 꼭지점을 선택합니다. 사용 가능한 것이 없으면 다음 패스를 기다립니다.

첫 번째 욕심 패스가 끝나면 일부 삼각형이 자극적인 꼭지점을 선택했을 것입니다. 여기서 보라색 점은 해당 삼각형에 대해 선택된 자극 정점을 나타냅니다.

이제 파란색으로 표시된 이 삼각형의 자극적인 꼭지점을 선택하려고 합니다.

그러나 모든 꼭지점은 다른 삼각형에 의해 선택되었습니다.

다행히도 여기에는 자유 정점이 있습니다. 삼각형 주변에서 깊이 우선 검색을 수행하면 찾을 수 있습니다.

경로를 찾았으면 자극하는 꼭지점을 회전시켜 새 삼각형에서 꼭지점을 비울 수 있습니다.
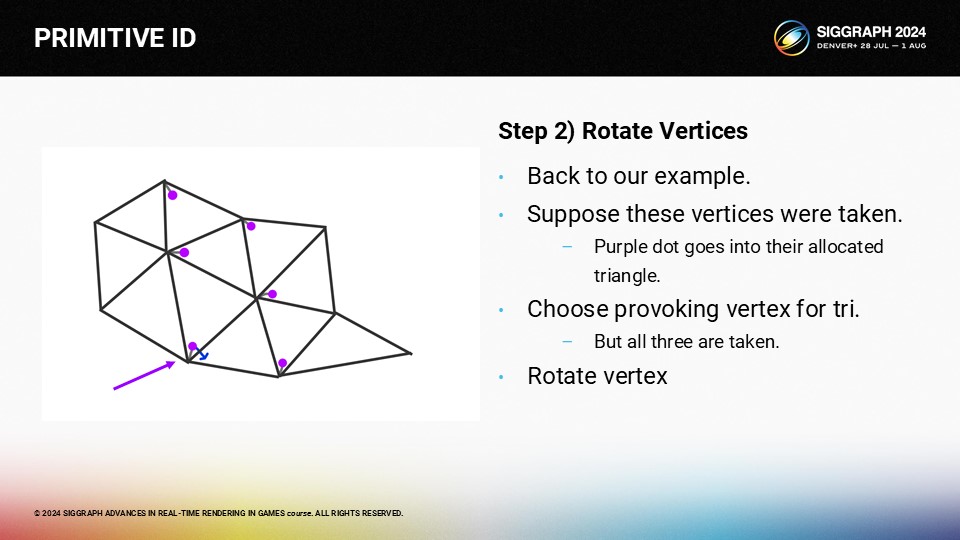
먼저 이웃 삼각형에서 자극하는 꼭지점을 회전합니다.
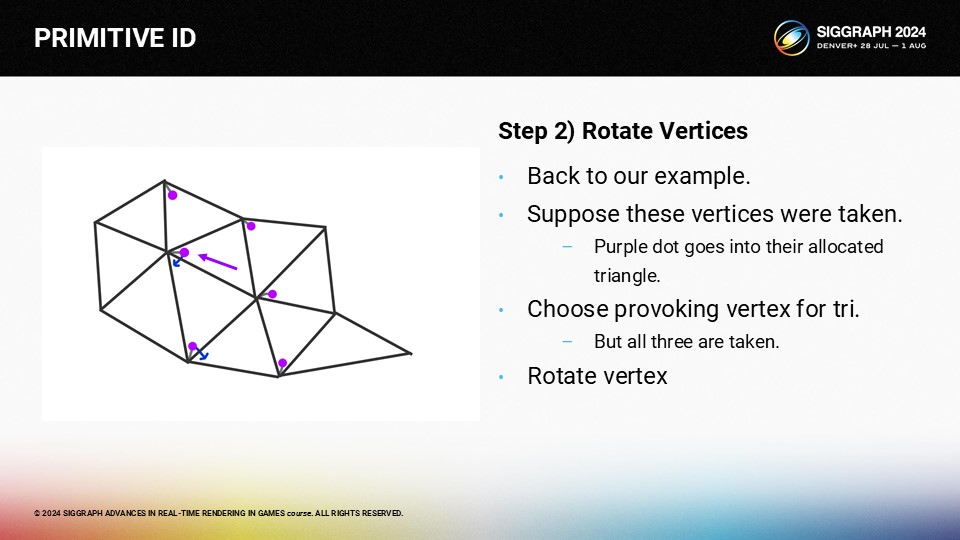
그리고 다음 삼각형은...
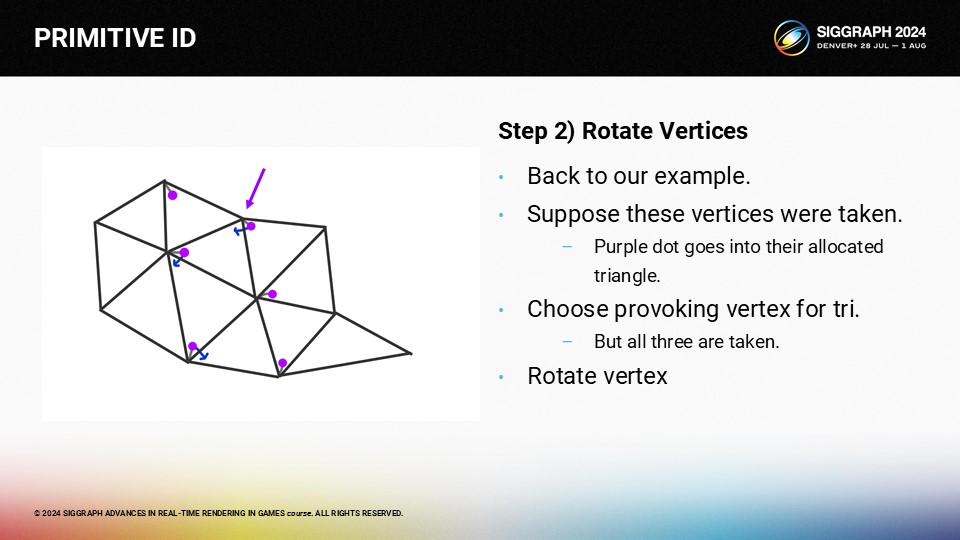
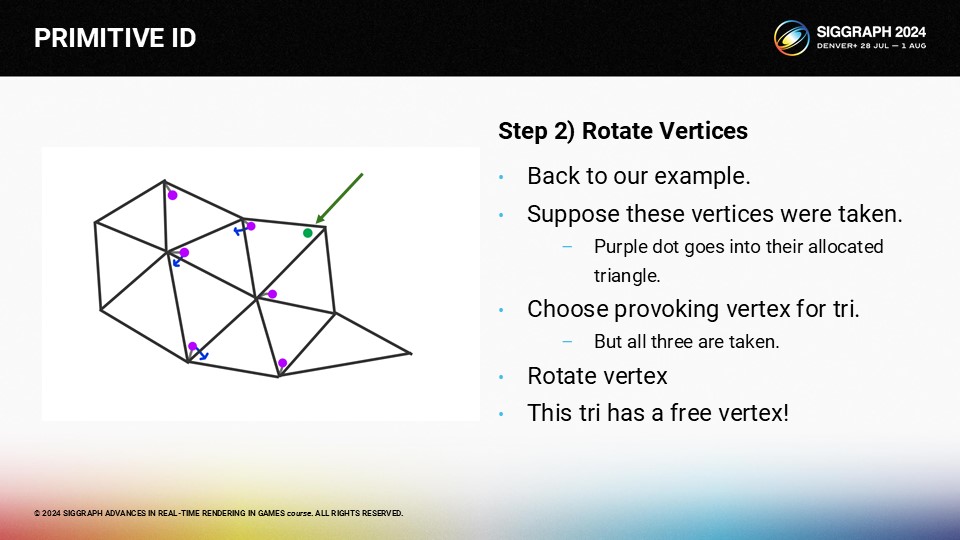
이 삼각형에는 이 삼각형의 새로운 자극 꼭지점으로 선택할 수 있는 자유 꼭지점이 있습니다.
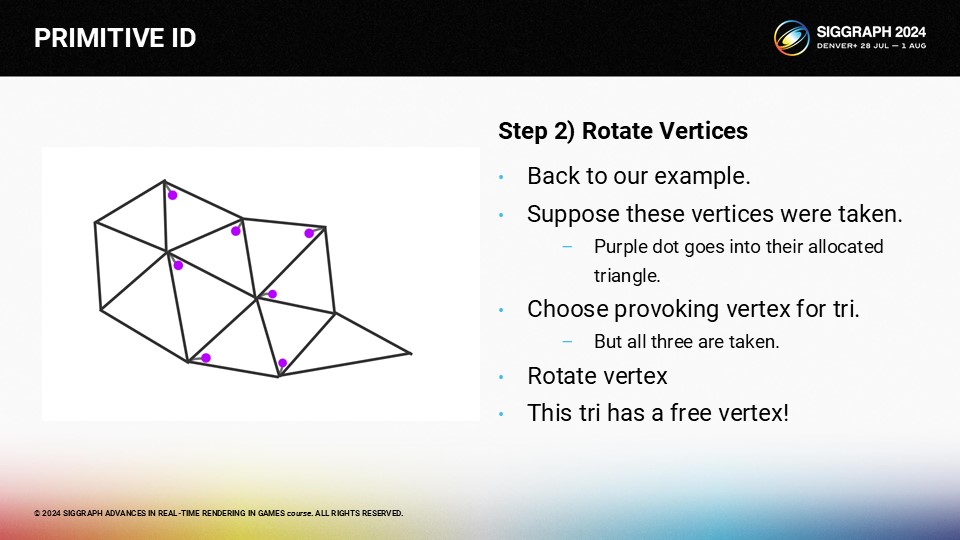
이제 지금까지 처리한 모든 삼각형에 대한 자극적인 꼭지점이 생겼습니다.

알고리즘은 두 단계로 실행됩니다. 첫 번째 단계에서는 원자가가 가장 낮은 정점을 기준으로 최적의 정점을 선택하기만 하면 됩니다. 그리고 두 번째 단계에서는 깊이 우선 검색을 수행하고 자극하는 정점을 회전합니다. 실제로 대부분의 경우 첫 번째 단계에서 각 삼각형에 대해 유효한 자극 정점을 찾기 때문에 두 번째 단계는 실행할 필요조차 없는 것으로 밝혀졌습니다.

그러나 몇 가지 실패 사례가 있습니다. 제 경우 클러스터는 항상 64개의 삼각형과 64개의 꼭지점으로 구성됩니다.

가장 일반적인 실패 사례는 하나의 삼각형이 단일 인덱스로 나머지 클러스터에 느슨하게 연결되어 있는 경우입니다. 이 경우 보라색 꼭지점을 자극하는 꼭지점으로 선택합니다. 그러나 녹색 꼭지점은 클러스터로 회전할 수 없으므로 클러스터 어딘가에 맞지 않는 삼각형이 있습니다.

이 알고리즘은 엄청나게 빠르기 때문에 제가 LOD에도 사용하는 메시 옵티마이저의 포크에 통합되어 있습니다. 메시 옵티마이저는 한 번에 하나씩 버퍼에 삼각형을 추가하는 탐욕스러운 알고리즘을 사용합니다. 버퍼가 지정한 한도(제 경우에는 64개의 트라이와 64개의 버트)를 초과하면 클러스터를 방출하고 새로운 클러스터를 시작합니다.
제가 변경한 것은 방출되는 클러스터를 살펴보고 버텍스를 유발할 트라이앵글의 순서를 다시 지정하는 것입니다. 삼각형이 자극 정점을 찾지 못하면 다음 클러스터가 생성될 때까지 버퍼에 다시 넣습니다. 실제로는 일반적으로 모든 삼각형이 맞지만, 간혹 한두 개의 삼각형이 누락되는 클러스터가 있습니다.

디스크의 실제 데이터 구조는 매우 빡빡합니다. 각 클러스터마다 소스 버텍스 버퍼에 64개의 인덱스가 필요하며 중복이 있을 가능성이 높습니다.
또한 첫 번째 버텍스가 암시되므로 세 개의 인덱스 중 두 개는 저장할 필요가 없습니다. 인덱스당 6비트로 패킹하면 32비트 인덱스 메시가 삼각형당 5.5바이트가 되므로, 압축되지 않은 인덱스를 저장하는 것보다 디스크 공간을 절약할 수 있습니다.

현실적인 문제가 하나 더 있습니다. 동일한 플랫폼에서 서로 다른 메시 구현을 지원하고자 한다고 가정해 봅시다. 예를 들어, 새로운 GPU에서는 메시 셰이더를 사용하고 싶지만 구형 GPU에서는 선행 버텍스 또는 일반 GBuffer 렌더링으로 돌아가고 싶을 수 있습니다.
이 경우 메시의 세 가지 버전을 디스크에 저장하고 싶지 않을 것입니다.
다행히도 패킹된 리딩 버텍스 클러스터에서 다른 해석으로 변환하는 것은 간단합니다. 촘촘하게 패킹된 표현은 디스크에 필요한 유일한 표현입니다. 그런 다음 필요한 경우 런타임에 인덱스 목록을 확장할 수 있습니다. 요즘 게임들은 디스크 공간이 매우 부족하기 때문에, 제 생각에는 일반 GBuffer 렌더링에 뚱뚱한 인덱스 목록만 사용하는 게임에서도 압축이 유리합니다.
- 파트 1은 여기까지...
- 파트 2는 Mesh Pool 부터 다시...