
역자의 말.
2010년 부터 지금(2023년)까지 직장생활을 하면서 수행 했던 전체 프로젝트의 3분의 2 정도가 모바일 게임이었습니다.
여전히 역자인 저는 모바일 게임 분야에서 더 큰 희열을 느끼곤 합니다. 차세대기 모바일 게임을 개발 해 보지 않았다면 아마 정말 이해하지 못할거라고 생각합니다. 수많은 최적화 방법 그리고 전체 구조 설계 부터 셰이더 처리의 모든 뎁스를 알아야 하기 때문이죠. 또는 회피 전략을 구상해 해는 그 과정이 재미있고 성취 했을 때의 만족도는 무척 높았습니다.
아무튼 이러한 저의 옛 경험은 다시 저를 이 발표자료를 한글화 하도록 이끌었습니다.
항상 말씀 드리지만 AI 기계학습 번역 후 전체 문장을 트리트먼트 하는 형식 입니다. 그러함에도 퇴근 후 또는 출근 시간에 천천히 복기 해 볼만 할 것입니다.
발표자 : Sebastian Aaltonen
25년간의 전문 3D 그래픽스 경력. 유니티와 유비소프트의 수석 엔지니어. 현재 HypeHype에서 렌더링 기술 개발을 주도하고 있습니다. 성능, 효율성, 그래픽 및 GPU 컴퓨팅에 관심이 많습니다.

SIGGRAPH 2023 Advances in Real-Time Rendering in Games course
Jorge Jimenez is the Director of Creative Engineering & General Manager at Striking Distance Studios Spain, where he pushes the boundaries of what is possible at the intersection of art and technology. Jorge is a passionate real-time graphics researcher wi
advances.realtimerendering.com

안녕하세요, 저는 세바스찬 알토넨입니다. 저는 그래픽 프로그래밍 분야에서 20년 이상의 경력을 보유하고 있습니다. 과거에는 Ubisoft와 Unity에서 크로스 플랫폼 렌더링 기술을 구축하는 일을 했습니다.
1년 전 모바일 렌더링 기술을 다시 쓰겠다는 사명을 가지고 HypeHype에 합류했습니다. 오늘은 그 프로젝트의 첫 번째 이정표인 로우레벨 그래픽 API와 플랫폼 백엔드 재작성에 대해 이야기하려고 합니다.

HypeHype는 모바일 게임 개발 플랫폼입니다. 터치스크린에서 직접 게임을 만들어 클라우드 서버에 업로드할 수 있습니다.
게이머는 틱톡 스타일의 피드를 사용하여 게임을 탐색합니다. 게임은 즉시 로딩됩니다. 이것은 큰 기술적 과제입니다. 게임 바이너리 크기와 로딩 코드 모두 고도로 최적화되어야 합니다. 초기 바이너리를 더 작게 만들기 위해 데이터를 고도로 압축된 형태로 저장하고 스트리밍에 의존합니다.
HypeHype는 최대 8명의 플레이어가 멀티플레이를 즐길 수 있습니다. 향후 클라우드 게임 서버 인프라가 구축되면 멀티플레이어 기능과 플레이어 수는 더 늘어날 예정입니다.
모바일 앱 내에 완전한 게임 에디터가 있습니다. 비주얼 스크립팅 시스템은 게임 로직을 작성하는 데 사용됩니다. 플레이어는 크리에이터가 게임을 만드는 과정을 지켜볼 수 있고, 여러 크리에이터가 실시간으로 함께 게임을 공동 제작할 수 있습니다. 구글 문서 도구와 비슷하지만 게임 제작을 위한 것입니다. 테스트 플레이는 즉시 가능하며 모든 관중은 멀티플레이어 테스트 세션에 플레이어로 참여합니다. 이를 통해 반복 작업 시간이 크게 단축됩니다.
물론 채팅, 리더보드, 리플레이 등 다양한 소셜 기능도 제공합니다.

HypeHype는 주로 모바일 디바이스와 태블릿을 타겟으로 합니다. 하지만 웹 클라이언트와 네이티브 PC 및 Mac 애플리케이션도 제공합니다.
저는 Ubisoft에서 콘솔 개발 경력을 쌓았기 때문에 모바일 기기를 과거 콘솔 세대와 비교하여 더 잘 이해하는 것을 좋아합니다.
Xbox 360과 PS3는 오늘날 GPU 성능 면에서 중저가 모바일 기기와 동등합니다. 이 콘솔은 지금까지 콘솔 세대 간에 가장 큰 시각적 도약을 제공했기 때문에 이는 매우 좋은 소식입니다: HD 출력 해상도를 구현할 수 있었고, 처음으로 적절한 HDR 라이팅 파이프라인, 물리 기반 머티리얼 모델, 이미지 포스트 프로세싱을 구현할 수 있었기 때문입니다. 이 모든 것이 오늘날 메인스트림 모바일 기기에서 가능합니다. 또한 업스케일링을 통해 하위 계층 디바이스에서도 30fps로 확장할 수 있습니다.
하이엔드를 살펴보면 최신 1000달러 이상의 휴대폰이 이미 Xbox One 및 PS4 수준의 성능을 발휘하는 것을 볼 수 있습니다. 하지만 이러한 휴대폰은 더 높은 기본 해상도에서 실행되고 열적 제약을 받기 때문에 실제 게임에서 모바일 기기에서 이러한 세대의 시각적 충실도에 도달하기는 아직 어렵습니다. 그리고 그렇게 하면 기기가 뜨거워지고 몇 시간 만에 배터리가 방전될 수 있기 때문에 그렇게 하고 싶지도 않습니다.

하이프하이프 게임은 단순한 비주얼에 국한되어 왔습니다: 스타일라이즈된 텍스처가 없는 오브젝트, 단순한 감마 공간 조명, 짧은 시야 거리의 작은 장면 등입니다. 이는 단순한 하이퍼 캐주얼 게임에는 괜찮았습니다.
하지만 이는 플랫폼의 큰 한계였기 때문에 유니티는 1년 전부터 새로운 렌더러를 처음부터 다시 구축하기 시작했습니다. 새로운 렌더러의 시각적 충실도 목표는 Xbox 360 및 PS3 게임에서 가장 잘 보이는 것과 일치하는 것입니다. 최신 라이팅, 섀도잉, 포스트 프로세싱 기법을 갖춘 완전한 PBR 파이프라인을 제공할 예정입니다. 더 많은 게임 장르가 플랫폼에서 제대로 구현될 수 있도록 더 큰 게임 월드와 더 긴 드로우 거리를 목표로 할 것입니다.
물론 이 모든 것이 좋은 일이지만, 이러한 새로운 개선 사항의 성능 비용에 대해서는 매우 신중해야 합니다. 저희는 여전히 중급 휴대폰에서 스로틀링 없이 60프레임으로 HypeHype 게임을 실행할 수 있기를 원합니다. 이는 유니티의 큰 관심사이며 새로운 렌더링 아키텍처에서 성능에 집중하는 주된 이유이기도 합니다.
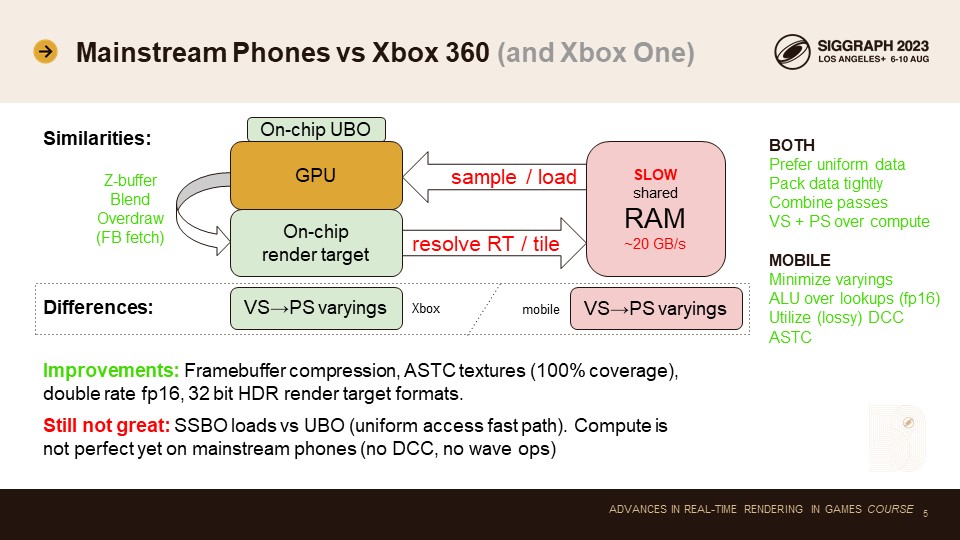
현재의 메인스트림 휴대폰과 Xbox 360을 비교하면 많은 유사점을 발견할 수 있습니다.
두 디자인 모두 느린 공유 메인 메모리를 가지고 있습니다. 대역폭이 주요 제한 요소입니다. 두 디자인 모두 메모리 대역폭 사용량을 줄이기 위한 기술을 사용합니다. 가장 중요한 것은 렌더 타깃을 위한 온칩 스토리지입니다. Xbox 360에서는 전체 렌더 타깃을 위한 10MB EDRAM 버퍼가 있었습니다.
Xbox 360 의 EDRAM 에 대해서...(첨)
특화된 H/W의 장단점. Xbox360의 EDRAM과 PS3의 ZCULL 메모리
게임 프로그래머 김포프의 블로그
kblog.popekim.com
휴대폰에서는 더 작은 온칩 타일 메모리가 있습니다. 두 기술 모두 비슷한 문제를 해결합니다. 오버드로에는 추가 메모리 대역폭이 필요하지 않으며 Z-버퍼링과 블렌딩이 칩에서 완전히 이루어집니다. 모바일에서는 프레임버퍼 페치 기능도 있어 메모리 왕복 없이 동일한 렌더링 대상 위치에서 이전 픽셀을 다시 로드할 수 있습니다. 최신 Xbox One 콘솔에도 읽기-쓰기 ESRAM이 장착되어 있어 비슷한 최적화가 가능합니다.
(역자 추가) ESRAM
ESRAM은 전용 RAM이며 32MB이며 GPU 바로 옆에 있으며 실제로 시스템의 나머지 부분과 통신하는 버스에서 GPU의 반대편에 있으므로 GPU만이 이 메모리를 볼 수 있습니다.
그리고 그것이 하는 일은 매우 높은 대역폭 출력과 GPU의 읽기 기능도 제공한다는 것입니다. 이는 많은 경우에 유용합니다. 특히 오늘날처럼 큰 콘텐츠가 있고 무언가를 렌더링하기 위해 잠재적으로 접촉할 수 있는 5기가바이트가 있을 때 대역폭이 2 정도인 메모리로 이동할 수 있는 모든 항목이 있기 때문에 유용합니다. 일반 시스템 메모리보다 10배 더 빠르다면 큰 승리가 될 것입니다.
메인 메모리는 느리기 때문에 렌더 타깃을 최대한 많이 확인하지 않으려 합니다. 렌더링 패스의 양을 최소화하고 싶을 것입니다. 한 번에 여러 작업을 수행하는 것이 좋은 성능의 핵심입니다. 최신 휴대폰에는 렌더 타겟 해상도 및 샘플링 대역폭 비용을 줄이기 위해 프레임버퍼 압축 기능도 있습니다. 이는 좋은 추가 기능이지만 문제를 완전히 해결하지는 못합니다. ASTC 텍스처 압축도 도움이 됩니다. 이 압축은 과거 DXT5보다 더 나은 품질과 더 작은 설치 공간을 제공합니다.
휴대폰은 또한 더블 레이트 fp16 를 가지고 있습니다. 대역폭이 부족한 디바이스에서 메모리 조회에 의존하지 않아도 되므로 도움이 됩니다. 그리고 이제 더 나은 저정밀 HDR 프레임버퍼 포맷을 사용할 수 있습니다.
더블-레이트 FP16 언급에 대하여...(첨)
모바일에서도 지원되는 가변 레이트 쉐이딩의 놀라운 성능
[BY 퀄컴 코리아] 이따금 우린 현실이라고 믿기 어려운 정도의 놀라운 기능을 경험하곤 합니다. 가변 레...
m.post.naver.com
하지만 몇 가지 오래된 한계는 여전히 남아 있습니다: 모바일 GPU는 여전히 균일한 버퍼를 중심으로 설계되었습니다. 동적 주소의 SSBO 로드는 여전히 느립니다. 메모리 액세스 패턴을 스칼라라이즈할 수 있다면 성능 최적점에 도달할 수 있습니다. 이는 우리가 효율적으로 구현할 수 있는 알고리즘을 제한합니다. 또한 많은 휴대폰은 버텍스 가변값을 메인 메모리에 쓰는데, 이는 상당한 양의 귀중한 대역폭을 소모합니다. 이러한 기기에서 우수한 성능을 발휘하려면 가변 변수의 크기를 최적화하는 것이 핵심입니다.
Shader Storage Buffer Object - OpenGL Wiki
A Shader Storage Buffer Object is a Buffer Object that is used to store and retrieve data from within the OpenGL Shading Language. SSBOs are a lot like Uniform Buffer Objects. Shader storage blocks are defined by Interface Block (GLSL)s in almost the same
www.khronos.org

저는 이미 8년 전 시그라프에서 GPU 기반 렌더러에 대해 이야기하면서 클러스터링 렌더링과 2패스 오클루전 컬링과 같은 핵심 아이디어를 제시했고, 이는 오늘날 사실상의 표준이 되었습니다.
최근 에픽의 나나이트는 GPU 기반 렌더링을 주류로 만들었습니다. 나나이트는 V-버퍼, 머티리얼 분류, 분석 파생 기능, 소프트웨어 래스터라이저를 결합하여 일반 엔진에서도 충분히 강력한 GPU 기반 렌더링을 구현할 수 있도록 했습니다.
하지만 메인스트림 모바일 GPU의 GPU 기반 렌더링에는 아직 해결되지 않은 성능 문제가 많이 있습니다.
모바일 GPU는 아직 SSBO 부하에 최적화되지 않았습니다. AMD와 엔비디아는 몇 세대 전에 레이 트레이싱을 추가하면서 데이터 경로를 최적화했습니다. 레이 트레이싱 액세스 패턴은 동적이며 더 이상 버텍스 속성을 작은 온칩 버퍼에 의존할 수 없습니다. 비슷한 최적화를 갖춘 모바일 GPU가 주류가 될 때까지 기다려야 합니다.
V 버퍼를 사용하려면 버텍스 셰이더를 픽셀당 3회 실행해야 하며, 여기에는 이 3개의 버텍스의 모든 버텍스 어트리뷰트를 페치하는 작업이 포함됩니다. 또한 동적 위치에서 모든 인스턴스 데이터와 머티리얼 데이터를 가져와야 합니다. 이는 픽셀 셰이더에서 20회 이상의 비균일 메모리 로드를 의미합니다. 모바일 칩은 단순히 이런 종류의 메모리 과부하 워크로드를 위해 설계되지 않았습니다.
현재 모바일 GPU는 컴퓨트 셰이더 쓰기를 위한 프레임버퍼 압축을 지원하지 않습니다. 컴퓨트 셰이더는 디퍼드 V-버퍼 셰이딩에서 전체 화면 머티리얼 패스를 구현하는 가장 효율적인 방법입니다. 모바일에서 이 작업을 수행하면 대역폭을 많이 낭비하게 됩니다.
64비트 아토믹스는 소프트웨어 래스터라이저에서 일반적으로 사용됩니다. Z값은 높은 비트로, 페이로드는 낮은 비트로 패킹하고 아토믹에서 가장 가까운 표면을 해결하도록 합니다. 모바일 GPU에는 64비트 원자 지원이 없습니다. SampleGrad도 느립니다. ⅛ 속도 또는 그보다 더 느립니다. 따라서 분석 그래디언트를 사용한 디퍼드 텍스처링은 비용이 상당히 많이 듭니다. 또한 웨이브 내재에 대한 지원이 불규칙하고 일부 저사양 디바이스에서는 그룹 공유 메모리를 에뮬레이트하기도 합니다.
따라서 오늘날 주류 휴대폰에는 여전히 전통적인 CPU 기반 렌더링이 가장 적합합니다. 과거에는 Xbox 360에서 60fps로 10,000번의 드로우 콜을 수행할 수 있었습니다. 오늘날 모바일 디바이스에서 이 목표를 달성하려면 매우 최적화된 렌더링 코드를 작성해야 합니다.
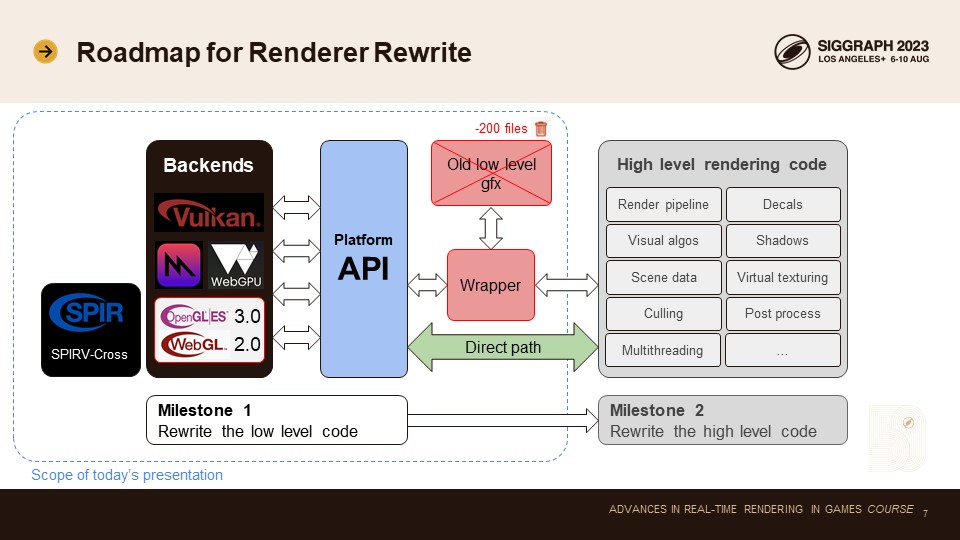
로드맵에 대해 이야기해 보겠습니다.
렌더러 재작성을 두 단계로 나누었습니다. 먼저 로우레벨 gfx API와 모든 플랫폼별 백엔드 코드를 재작성했습니다. 이전 백엔드와 새 백엔드를 함께 실행하기 위해 ifdef가 포함된 최소 래퍼를 도입하여 이전 렌더링 코드를 계속 배포하고 새 코드와 이전 코드를 전환하여 비교할 수 있도록 했습니다. 이미 200개의 이전 렌더링 코드 파일을 삭제했으며, 최근에는 래퍼를 해체하고 새로운 플랫폼 API에 대한 직접 호출로 대체하기 시작했습니다.
이 프레젠테이션에서는 로우레벨 플랫폼 API와 백엔드에 초점을 맞출 것입니다. 나중에 새로운 하이레벨 렌더링 코드에 대해 이야기하겠습니다. 우리의 설계를 통해 이러한 부분을 서로 완전히 독립적으로 리팩터링할 수 있습니다. 이 주제는 프레젠테이션 후반부에 다시 다루겠습니다.
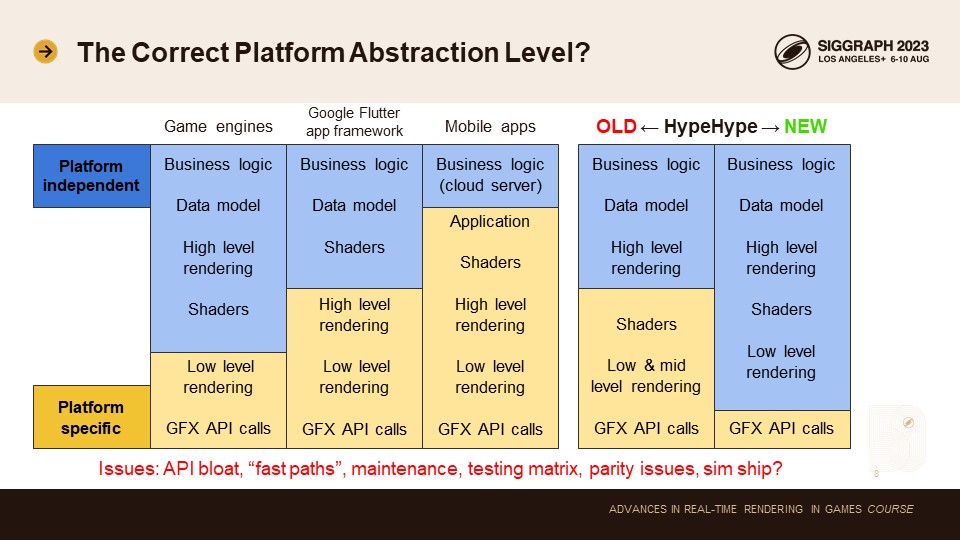
가장 먼저 결정해야 할 것은 플랫폼 추상화 수준입니다. 어떤 코드가 플랫폼에 특정되고 어떤 코드가 플랫폼에 독립적인지 결정합니다.
게임 엔진은 일반적으로 플랫폼별 코드를 스택의 가장 낮은 레벨로 제한합니다. 이렇게 하면 플랫폼별 코드의 양을 최소화하고 구현 및 유지 관리 비용을 줄일 수 있습니다. 하지만 일부 엔진과 렌더러의 경우 가장 낮은 수준의 플랫폼 코드로 유출되는 경향이 있습니다.
모바일 앱을 보면 플랫폼별 코드가 스택에서 조금 더 높은 레벨에 도달하는 경향이 있습니다. 예를 들어 널리 사용되는 Google Flutter 앱 프레임워크는 여러 플랫폼별 팀에서 개발합니다. 일반적으로 새로운 기능을 모바일에 먼저 출시하고 나중에 데스크톱에 출시합니다. Android와 iOS도 완전한 기능 패리티가 없습니다. 데스크톱과 모바일 플랫폼(Mac 및 iOS 포함)은 동일한 Metal API를 사용하지만 상위 수준의 렌더링 코드가 서로 다릅니다.
많은 모바일 앱은 코드 분리가 훨씬 더 높습니다. iOS와 안드로이드 팀이 완전히 분리되어 전용 코드 베이스를 사용하는 경우가 많습니다. 이러한 앱의 비즈니스 로직은 대부분 클라우드 서버에서 실행되는 경향이 있으며, 물론 제3의 팀에서 공유하고 유지 관리합니다.
HypeHype는 실시간 게임 엔진이기 때문에 당연히 모든 월드 상태가 로컬에 있어야 합니다. 게임은 모든 기기에서 동일하게 실행되어야 하며 크로스 플레이는 모든 기기에서 작동해야 합니다. 기존 HypeHype의 그래픽스 코드 베이스에는 Metal용 셰이더가 중복되어 있었고, 일부 상위 레벨 코드도 중복되어 있었습니다. 이로 인해 테스트 매트릭스가 부풀어 오르고 유지보수 비용이 증가했으며 새로운 기능을 추가하는 속도가 느려졌습니다. 이 문제를 가장 먼저 해결하고 싶었습니다. 목표는 플랫폼 API를 기존 게임 엔진에 비해 훨씬 더 낮은 수준으로 낮추는 것이었습니다.

유니티는 가능한 한 적은 양의 플랫폼별 코드를 원합니다. 따라서 기존의 로우 레벨 gfx API를 긴밀하게 감싸는 설계로 이어집니다.
디자인 작업은 벌칸, 메탈, 웹 GPU 문서를 상호 참조하는 것으로 시작되었습니다. 저는 이미 이 모든 API에 익숙했기 때문에 작업이 더 쉬웠고 오류도 적었습니다.
래퍼를 작성할 때는 먼저 공통된 기능 집합을 찾아야 합니다. 이러한 기능은 래핑하기 쉬운 경우가 많습니다. API 설계에 차이가 있을 때 어려움이 발생합니다. 이러한 차이를 성능에 최적화된 방식으로 추상화하려면 주의를 기울여야 합니다. 저희는 메탈 2.0을 사용하기로 결정했는데, 이는 벌칸 및 웹 GPU에 더 가깝고 배치 힙, 인수 버퍼 및 수동 펜스를 제공하여 Apple 디바이스에서도 성능을 조금 더 끌어낼 수 있기 때문입니다. 또한 크로스 플랫폼 개발이 더 쉬워지도록 MoltenVK도 지원하지만, Metal 2.0 백엔드가 CPU에서 약 40% 더 빠르기 때문에 제공하지 않습니다.
API를 더 간결하게 만들기 위해 더 이상 아무도 사용하지 않는 사용 중단된 기능을 모두 제거했습니다. 이러한 것들은 성능에 대한 기대에 부응하지 못한 실패한 실험이었습니다. 버텍스 버퍼는 흥미로운 주제입니다. Ubisoft에서는 이미 8년 전에 GPU 기반 렌더러에서 버텍스 버퍼를 더 이상 사용하지 않았습니다. 하지만 일부 모바일 GPU 셰이더 컴파일러가 버텍스 버퍼를 위한 더 나은 코드를 생성하기 때문에 HypeHype에서는 여전히 버텍스 버퍼를 지원합니다. 또한 웹GPU 커버리지가 아직 충분하지 않기 때문에 웹 클라이언트에서 여전히 WebGL2를 사용하고 있습니다. 몇 년 안에 API에서 버텍스 버퍼를 제거할 예정입니다.
단일 셰이더 세트는 테크 아티스트의 생산성을 위해 매우 중요합니다. 유니티는 모든 대상 플랫폼에 셰이더를 교차 컴파일하기 위해 SPIRV-Cross와 같은 최신 오픈 소스 툴을 사용합니다.

이 새로운 플랫폼 API의 설계 목표에 대해 이야기해 보겠습니다.
첫째, 독립형 라이브러리가 되기를 원합니다. HypeHype 엔진과 독립적으로 설계 및 유지 관리됩니다. 자주 변경되지 않는 안정적인 API여야 합니다.
저는 그래픽스 플랫폼의 추상화를 많이 봐왔는데, 대부분의 추상화에서 문제가 되는 것은 사용자 랜드 개념이 하드웨어 API에 스며든다는 점입니다. 플랫폼 코드에 메시와 머티리얼이 있는 것이 가장 일반적인 문제입니다. 메시와 머티리얼 모두 변화 압력이 있기 때문에 문제가 됩니다. 메시렛과 바인드리스 텍스처는 미래입니다. 유니티는 메시를 표현하는 특정 방식을 고집하고 싶지 않습니다. 메시는 인덱스 버퍼 바인딩 + N 버텍스 버퍼 바인딩으로 간단히 표현할 수 있고, 머티리얼은 여러 텍스처 디스크립터와 값 데이터용 버퍼를 포함하는 바인드 그룹으로 표현할 수 있습니다.
처음에는 균일한 처리를 자동으로 처리하는 것이 좋은 아이디어처럼 느껴질 수 있지만, 결국 지오메트리 인스턴싱과 같은 기능을 추가하고 데이터 레이아웃을 변경하기 위해 백엔드 코드를 리팩터링해야 합니다. 또는 더 나쁜 경우, 새로운 빠른 경로를 추가하여 API를 복잡하게 만들 수도 있습니다. 그리고 결국에는 GPU 기반 렌더링을 위한 새로운 빠른 경로도 추가하여 API를 더욱 부풀려야 합니다. 저희 설계에서는 사용자 랜드 코드가 모든 데이터 설정을 담당합니다!
추가 API 오버헤드 제로는 또 다른 중요한 설계 핵심 요소입니다. 플랫폼 인터페이스는 상당한 비용을 추가하지 않아야 합니다. DX11만큼 사용하기 쉬워야 하지만 항상 수작업으로 최적화한 DX12만큼 효율적이어야 합니다. 잘못된 해결책은 DX11 API를 그대로 복사하는 것입니다. 이렇게 하면 코드 베이스에서 DX11 드라이버를 에뮬레이트하게 되고, Nvidia와 AMD가 우리 팀보다 이 작업을 더 잘 수행하므로 안심할 수 있습니다. 따라서 최신 뱅엔드는 DX11보다 느립니다. 그 이유는 너무 세분화된 입력, 너무 세분화된 렌더링 상태, 많은 섀도 상태 및 데이터 복사본이 있기 때문입니다. PSO와 렌더링 상태 추적 및 캐싱은 성능을 크게 소모하며, 느린 소프트웨어 명령 버퍼 설계는 일반적으로 비용을 추가합니다.
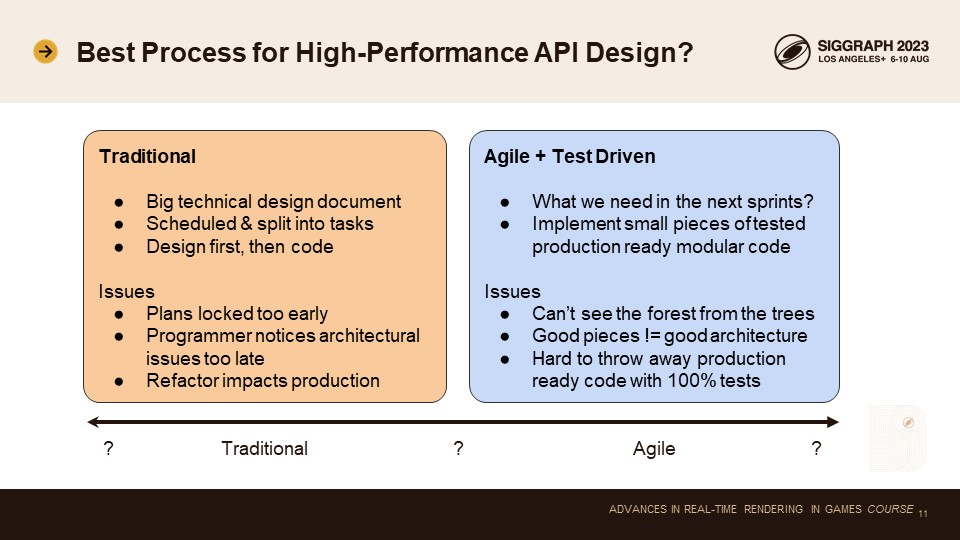
따라서 저희는 API에 대해 매우 엄격한 성능 표준을 적용하고 있지만, 동시에 DX11만큼 사용하기 쉽기를 원합니다. 이를 어떻게 달성할 수 있을까요?
API 설계를 위한 좋은 프로세스가 필요합니다.
전통적인 방식은 몇 달에 걸쳐 API 문서를 조사하고 새로운 API를 자세히 설명하는 대규모 기술 설계 문서를 작성하여 작업을 나누고 각 백엔드에 대한 각 작업의 구현 시간을 예측하는 것입니다.
이 접근 방식의 문제점은 너무 일찍 설계를 고정시켜 나중에 변경하기 어렵다는 것입니다. 플랫폼별 그래픽 코드에서는 작은 세부 사항이 매우 중요합니다. 코드를 작성하지 않고서는 모든 코너 케이스의 성능 영향을 실제로 이해할 수 없습니다. 이제 프로덕션 준비 코드가 많이 작성되면 이러한 문제를 발견할 수 있습니다. 이 시점에서 계획과 코드를 완전히 다시 작성하는 것을 정당화하기는 너무 어렵습니다.
애자일 테스트 중심 개발에는 정반대의 문제가 있습니다. 다음 스프린트에서 필요한 것에 집중할 수 있습니다. 전체 테스트 커버리지가 있는 작은 독립적인 코드 조각을 구현합니다. 이러한 조각을 조합하면 좋은 아키텍처를 갖게 된다고 가정합니다. 하지만 아키텍처 설계는 전혀 하지 않았습니다. 조각이 많을수록 인터페이스가 많아지고 통신 오버헤드가 증가합니다. 이런 프로그래밍 방식으로는 최적의 성능을 달성하기 어렵습니다. 또한 성능 목표를 달성하기 위해 아키텍처에 대대적인 개편이 필요하다는 사실을 알게 되면 전체 테스트 커버리지와 많은 스토리 포인트를 사용하여 프로덕션 준비가 완료된 코드를 버리는 것은 훨씬 더 어렵습니다.
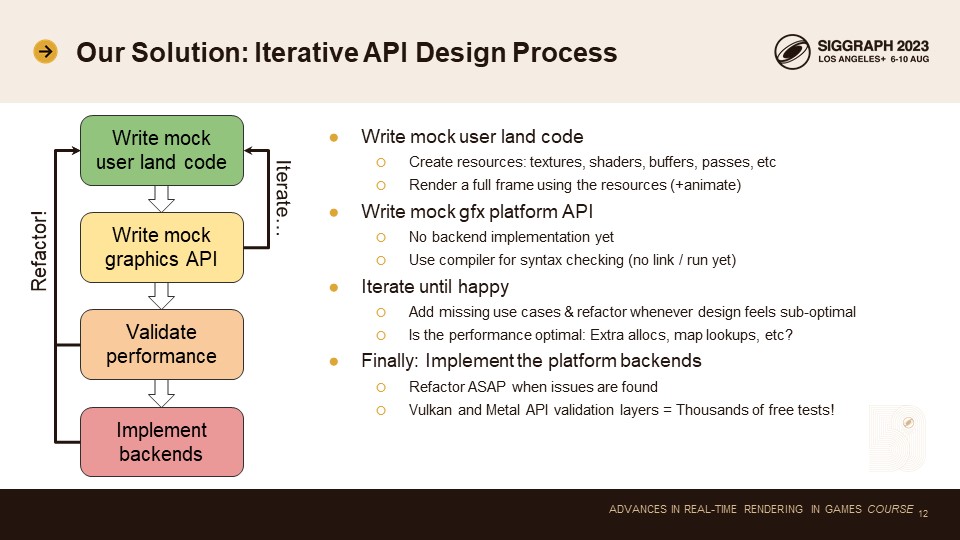
이 문제에 대한 우리의 해결책은 고도로 반복적인 디자인 프로세스를 사용하는 것입니다.
먼저 모의 사용자 랜드 코드를 작성합니다. 저는 이전에 쌓은 전문 지식을 활용하여 완벽한 API가 있다고 가정하고 제가 꿈꾸는 그래픽 코드를 작성하기 시작합니다. 그 API는 아직 존재하지 않지만 만족할 때까지 모의 코드를 계속 작성합니다. 렌더링에 필요한 모든 리소스, 텍스처, 셰이더, 버퍼 등을 생성하는 코드를 작성한 다음 이러한 리소스를 사용하여 작은 드로우 루프를 작성합니다. 드로 루프는 애니메이션을 구현하기 위해 일부 리소스를 변형하여 여러 번 호출됩니다. 동적 및 정적 데이터 경로를 모두 일찍 설계하는 것이 중요합니다.
유저 랜드 코드의 첫 번째 반복에 만족하면 모의 플랫폼 API를 작성합니다. 이 시점에서는 빈 API일 뿐입니다. 백엔드 구현이 없습니다. 하지만 컴파일러를 사용하여 구문 검사 및 자동 완성을 수행할 수 있습니다. 이제 API를 실제로 실험해보고 사용감이 얼마나 좋은지 확인할 수 있습니다. 물론 조금이라도 필요한 부분이 발견되면 항상 리팩터링합니다. 누락된 모의 사용 사례를 추가하고 중요한 사항을 놓치지 않았는지 확인하기 위해 Vulkan, Metal 및 WebGPU API 문서를 검토합니다.
그런 다음 모든 사용자 랜드 코드에 대한 성능 점검을 수행합니다. 모든 플랫폼 API가 어떻게 작동하는지 잘 이해하고 있기 때문에 각 API 호출이 Vulkan과 Metal 및 WebGPU 백엔드에서 어떤 종류의 구현이 필요할지 생각합니다. 구현이 사소한 것이라면 괜찮습니다. 구현에 추가 데이터 복사, 해시 맵 조회, 메모리 할당 또는 기타 비용이 많이 드는 작업이 필요한 경우 해당 설계를 폐기하고 더 효율적으로 API의 해당 부분을 다시 작성합니다. 아시다시피, 저희의 목표는 모든 경우에 수작업으로 최적화한 DX12만큼 빠르게 만드는 것입니다. API가 기본 하드웨어 API에 완벽하게 매핑되지 않으면 그렇게 할 수 없습니다.
모의 코드의 성능에 만족하면 백엔드 구현을 시작합니다. 물론 이 과정에서 놓친 중요한 세부 사항을 발견하고 이 경우 즉시 모의 코드와 모의 API를 리팩터링합니다. 아직은 무거운 테스트 스위트를 작성하지 않는데, 반복 시간이 느려질 수 있기 때문입니다. 대신 수천 개의 테스트 사례를 무료로 제공하는 Vulkan 및 Metal 유효성 검사 계층에 의존하고 있습니다. 유효성 검사 계층 오류 콜백을 자동화된 테스트에 연결하여 코드를 리팩터링할 때 코드가 계속 작동하도록 합니다.
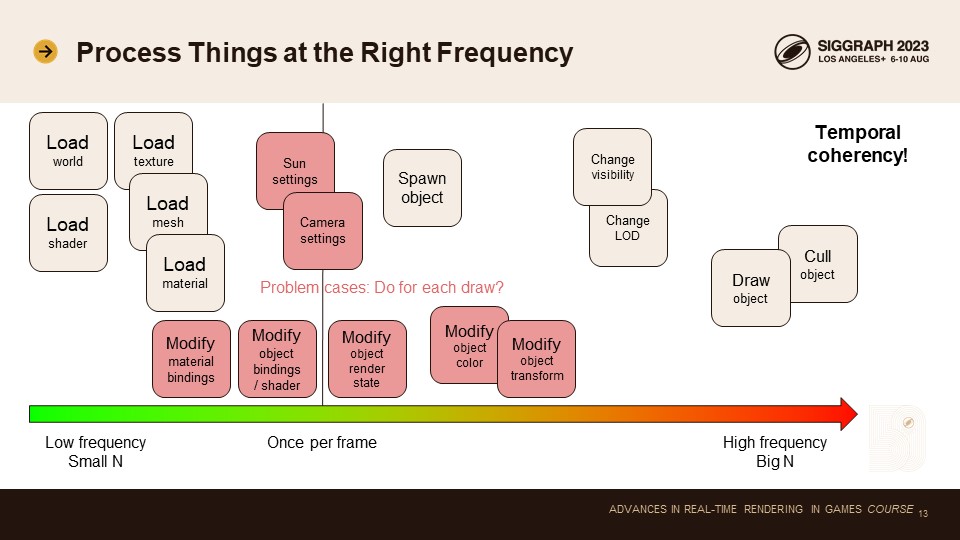
오늘 논의하고 싶은 API 설계의 마지막 주제는 적절한 빈도와 세분성으로 작업을 수행하는 것입니다.
렌더링 코드의 가장 큰 문제는 비용이 많이 드는 작업이 너무 높은 빈도로 수행되는 경향이 있다는 것입니다. 이는 또한 핫 드로 루프에 추적 비용을 추가하는 경향이 있습니다.
게임에는 시간적 일관성이 많이 있습니다. 게임 월드를 로드하고 매 프레임마다 천천히 변경합니다. 대부분의 데이터는 동일하게 유지됩니다. 또한 카메라는 대부분의 시간 동안 천천히 움직입니다. 인간의 뇌가 부드러운 움직임을 인식하려면 프레임 간의 시간적 일관성이 필요합니다. 이것은 우리에게 큰 도움이 됩니다! 우리는 이를 활용하고 싶습니다!
어떤 일이 일어나는지 살펴봅시다: 게임 월드와 모든 셰이더 PSO를 처음에 로드합니다. 레벨이 커지면 이동할 때 텍스처, 메시, 머티리얼도 로드됩니다. 대부분의 오브젝트는 처음에 스폰되지만 스트리밍 중에 레벨의 일부가 스폰될 수 있으며, 적, 전리품, 발사체 등은 일반적으로 게임 내내 스폰되지만 매 프레임마다 그렇게 많이 스폰되지는 않습니다. 정말 빈도가 높은 유일한 작업은 모든 오브젝트를 컬링하고 보이는 오브젝트를 그리는 것입니다. 컬링과 그리기 루프는 전체 코드 베이스에서 가장 시간에 민감한 루프입니다.
문제 사례를 빨간색으로 강조 표시했습니다. 사람들은 핫 드로 루프 내에서 이와 관련된 처리를 수행하는 경향이 있습니다.
머티리얼 바인딩을 수정하는 것은 일반적이지 않습니다. 이미 로드된 머티리얼의 노멀 맵을 얼마나 자주 교체하나요? 오브젝트를 렌더링하는 데 사용되는 셰이더를 얼마나 자주 변경하나요? 오브젝트를 렌더링하는 데 사용되는 렌더링 상태를 얼마나 자주 변경하나요? 일부 특수 효과를 제외하고는 거의 변경하지 않습니다. 오브젝트 색상과 오브젝트 변형에 애니메이션을 적용하는 것이 더 일반적인 작업입니다. 오브젝트의 작은 하위 집합이 매 프레임마다 애니메이션을 적용합니다. 이런 일이 발생할 때만 비용을 지불하고 싶습니다. 모든 그리기 호출에 대해 비용을 지불하는 것은 아닙니다.

이 문제에 대한 해결책은 모든 데이터 수정과 그리기를 완전히 분리하는 것입니다. 모든 데이터는 그리기 루프 전에 준비됩니다.
파이프라인 상태 객체(PSO)는 애플리케이션 시작 시 또는 레벨 로드 시 빌드해야 합니다. 런타임에 PSO를 빌드하면 버벅거림이 발생합니다. 유니티의 철학에 따라 셰이더 배리언트는 코더와 테크 아티스트가 직접 작성하고 수작업으로 최적화합니다. 수량이 한정되어 있습니다. 이는 id-Software가 하는 것과 유사하며 매우 우수한 성능을 제공합니다.
유니티는 각 오브젝트의 시각적 컴포넌트에 PSO 핸들을 직접 저장합니다. 매 프레임마다 해시 맵을 조회할 필요가 없습니다.
모든 바인드 그룹(디스크립터 세트)을 미리 생성합니다. 머티리얼 디스크립터 세트에는 모든 텍스처와 값 데이터를 위한 버퍼가 포함됩니다. 머티리얼 바인드 그룹 핸들을 오브젝트 비주얼 컴포넌트에 저장합니다. 이렇게 하면 해시맵 조회를 피할 수 있고 단일 Vulkan, Metal 및 WebGPU 명령으로 머티리얼 바인딩을 효율적으로 변경할 수 있습니다.
퍼시스턴트 데이터와 동적 데이터를 분리하는 것이 중요합니다. 퍼시스턴트 데이터는 시작 시 업로드되고 변경 시 델타가 업데이트됩니다. 2년 전 REAC 2011에서 이 주제에 대해 강연한 적이 있습니다. 해당 주제에 대한 자세한 내용은 해당 프레젠테이션을 참조하세요.
동적 데이터는 드로우 호출당 맵/맵 해제 대신 패스당 한 번씩 일괄 업로드해야 합니다. 낭비되는 대역폭 비용을 최소화하기 위해 글로벌 데이터와 드로우별 데이터를 분리해야 합니다.
리소스 동기화는 많은 엔진에서 CPU 비용을 크게 차지합니다. 유니티의 현재 솔루션은 간단합니다: 렌더 패스가 시작되면 렌더 타깃을 쓰기 가능한 레이아웃으로 전환합니다. 렌더 패스가 끝나면 다시 샘플링된 텍스처 레이아웃으로 전환합니다. 이렇게 하면 모든 텍스처(정적 및 동적 모두)가 항상 샘플러에서 읽을 수 있는 레이아웃에 있습니다. 그리기 호출마다 리소스를 추적할 필요가 전혀 없습니다. 이렇게 하면 CPU 사이클이 크게 절약됩니다.

이제 구현 세부 사항에 대해 이야기할 준비가 되었습니다.
렌더러에는 텍스처, 버퍼, 셰이더 및 기타 여러 리소스 객체가 필요합니다. 이러한 오브젝트를 저장하고 안전하게 사용할 수 있는 좋은 방법이 필요합니다.
최신 C++에서는 스마트 포인터, 참조 카운팅, RAII(리소스 획득은 초기화)를 사용하는 것이 일반적입니다.
솔직히 이 방법들은 너무 느립니다. 참조 계수 스마트 포인터는 참조와 배후 메모리의 수명을 하나로 묶습니다. 그 결과 작은 메모리 할당이 많이 발생합니다. 메모리 할당은 현재의 고도로 멀티스레드화된 시스템에서 비용이 많이 듭니다. 또한 할당은 시스템 메모리에 무작위로 흩어져 데이터 액세스 패턴을 악화시키고 캐시 누락을 증가시킵니다. 참조 카운트 스마트 포인터를 복사하려면 멀티스레드 시스템에서 두 개의 원자 연산(add, sub)이 필요합니다. 소유권은 스레드 간에 공유될 수 있습니다.
안전 문제도 있습니다. 참조 카운팅은 객체 수명을 모호하게 만듭니다. 추론하기 어렵습니다. 어떤 스레드에서든 죽을 수 있습니다. 리스너와 같은 RAII 객체는 소멸자에 부작용을 일으킵니다. 예시: 객체 참조 카운트가 다른 스레드에서 실행되면 리스너의 소멸자가 배열에서 등록을 해제합니다. 다른 스레드가 해당 배열을 반복하고 있습니다. 크래시! 이러한 충돌을 방지하려면 뮤텍스로 소멸자의 일부를 보호해야 합니다. 즉, 객체를 삭제할 때마다 뮤텍스 잠금이 필요합니다. 이것은 매우 비쌉니다. HypeHype는 피드에서 게임을 빠르게 로딩 및 언로딩하고 있습니다. 느리게 로딩하고 코드를 찢어버릴 여유가 없습니다!
이 문제(그리고 대부분의 다른 문제도 마찬가지)에 대한 해결책은 배열을 사용하는 것입니다!
같은 유형의 모든 오브젝트를 포함하는 하나의 큰 할당이 있습니다. 배열 인덱스는 놀랍도록 멋진 데이터 핸들입니다. 텍스처 배열이 있다면 인덱스 4에 있는 텍스처를 요청하면 됩니다. 인덱스는 POD 데이터입니다. 복사하는 것은 간단합니다. 워커 스레드에도 안전하게 전달할 수 있습니다. 해당 스레드가 배열에 액세스하지 않는 한 인덱스에 위험한 작업을 할 수 없습니다. 따라서 컬링과 드로우 스트림 생성 작업을 안전 문제 없이 작성할 수 있습니다. 이러한 스레드는 단순히 한 곳에서 배열 인덱스를 가져와 결합하여 그리기 호출을 생성합니다. 데이터 배열에 대한 액세스는 전혀 필요하지 않습니다.
하지만 배열 인덱스는 오브젝트 수명을 보장하지 않는다는 치명적인 결함이 있습니다. 물론 데이터 배열의 슬롯을 재사용합니다. 데이터가 죽고 슬롯이 재사용될 수 있습니다...

문제를 해결하려면 배열 인덱스를 세대 핸들로 대체해야 합니다. 이것이 무엇을 의미하는지 알아보겠습니다.
풀은 우리의 데이터 배열과 유사합니다. 유형이 지정된 객체 배열이지만 이제는 생성 카운터 배열도 추가됩니다. 생성 카운터는 슬롯이 재사용된 횟수를 알려줍니다. 해당 슬롯의 현재 데이터가 해제되면 카운터가 증가합니다.
풀에 프리리스트도 있습니다. 프리리스트는 단순히 각 사용 가능한 슬롯의 인덱스를 포함하는 선형 배열입니다. 스택 시맨틱이 있습니다. 새 개체를 할당하면 맨 위에서부터 빈 인덱스가 튀어나오게 됩니다. 객체를 삭제하면 해제된 슬롯의 인덱스가 해제 목록의 맨 위로 밀려납니다. 이 두 가지 작업은 모두 빠른 O(1) 연산입니다. 자유 목록이 부족해지면 풀의 크기가 두 배로 늘어납니다. 누구도 배열의 데이터에 대한 직접적인 포인터 참조를 가질 수 없으므로 안전합니다. 모든 참조는 핸들을 사용하여 수행됩니다.
핸들은 POD 구조체일 뿐입니다. 이전 슬라이드에서와 마찬가지로 배열 인덱스가 포함되어 있지만, 이제 그 옆에 생성 카운터도 있습니다. 이는 동시에 활성화되는 리소스 수와 객체의 수명에 따라 총 32비트(예: 16+16비트 분할) 또는 64비트(32+32비트)로 구성됩니다. HypeHype에서는 모든 그래픽 리소스에 32비트(16+16) 핸들을 사용하며, 이는 각 특정 유형의 리소스 65536개에 충분합니다.
풀은 핸들을 파라미터로 받는 게터 API를 제공합니다. 핸들 인덱스에서 풀의 생성 카운터 배열을 읽고 이를 핸들의 생성 카운터와 비교합니다. 일치하면 데이터를 가져옵니다. 일치하지 않으면 널 포인터를 얻습니다.
이로 인해 참조 시맨틱이 약해집니다. 오래된 핸들을 사용해도 완전히 안전합니다. 널 포인터를 돌려받기만 하면 됩니다. 널 검사는 예측 가능한 분기이며 최신 CPU에서는 거의 무료입니다. 브랜치 예측은 핸들이 삭제되면 한 번 실패합니다. 이 시점에서 여러분도 스스로를 정리해야 합니다. 참조가 약하면 콜백이 필요하지 않은 코딩 관행이 생깁니다. 콜백은 멀티스레드 시스템에서 경쟁 조건을 피하기 위해 버퍼링 또는 뮤텍스가 필요합니다.
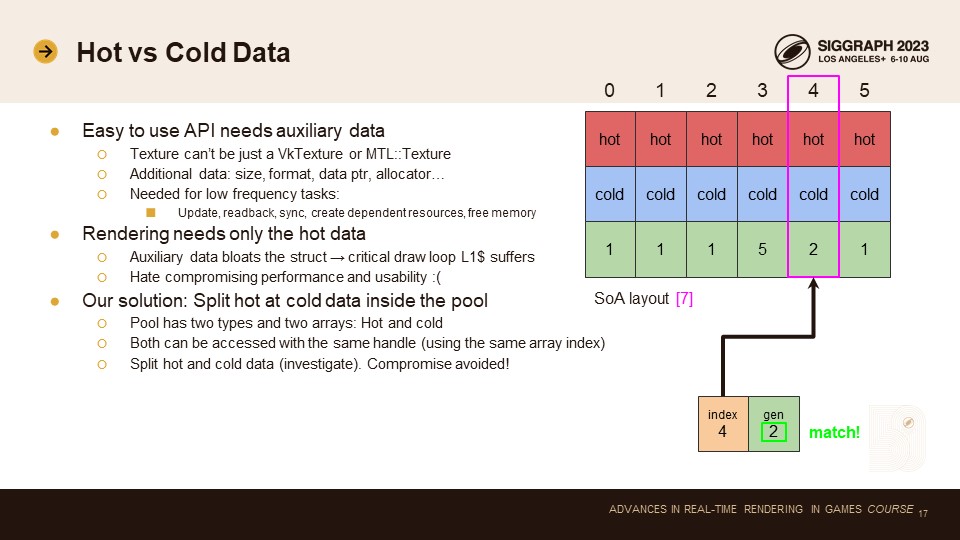
저희의 주요 목표 중 하나는 API를 DX11처럼 사용하기 쉽게 만드는 것이었습니다. 이를 위해서는 풀의 데이터 구조에 보조 데이터를 번들로 묶어야 합니다. Vulkan에서 VkTexture 핸들은 자신에 대해 아무것도 알지 못하기 때문에 순수 Vulkan으로 렌더링 코드를 작성하려고 하면 성가신 일이 벌어집니다. 텍스처 구조체가 크기, 형식, 쓰기를 위한 데이터 포인터, 삭제를 위한 얼로케이터 등을 알기를 원합니다.
이 보조 데이터는 리소스 수정 및 삭제와 같이 빈도가 낮은 작업에 필요합니다. 리소스 수정과 그리기를 분리하는 것이 설계 원칙이므로 리소스를 수정하거나 삭제할 때만 이 데이터에 액세스합니다. 즉, 보조 데이터를 핫 드로 루프에 필요한 데이터와 동일한 구조체에 넣는 것은 캐시 효율적이지 않습니다. 드로우 루프는 사용되지 않는 데이터를 L1$에 로드합니다. 저는 성능과 사용성 사이의 절충이 싫습니다.
이 문제에 대한 해결책은 풀 내부에 SoA 레이아웃을 사용하는 것입니다. 핫 드로 루프에서 매 프레임마다 필요한 데이터를 식별하여 해당 데이터는 한 구조체에, 나머지 저주파 보조 데이터는 다른 구조체에 넣습니다. 이제 풀에는 하나가 아닌 두 개의 데이터 배열이 있습니다. 핸들에서 동일한 배열 인덱스를 사용하여 데이터 배열 중 하나(또는 둘 다)에 액세스할 수 있습니다. 이렇게 하면 성능이 중요한 드로우 루프에서 캐시에 핫 데이터만 로드하면 됩니다. 보조 데이터 구조체는 낮은 빈도로만 로드되므로 L1 캐시 사용률과 관련된 성능 문제를 해결할 수 있습니다.

이제 그래픽 리소스를 저장하고 참조할 수 있는 좋은 방법이 생겼습니다. 다음 주제는 리소스를 생성하는 것입니다.
벌칸과 DX12에서 그래픽 리소스를 생성하는 것은 번거롭습니다. 다른 큰 구조체를 포함하는 큰 구조체를 채워야 합니다. 이러한 구조체 중 일부는 구조체 배열에 대한 포인터도 포함합니다. 이로 인해 임시 객체 수명으로 인해 발등을 찍을 수 있습니다.
이 문제에 대한 가장 일반적인 기존 해결책은 리소스 설명자에 빌더 패턴을 사용하는 것입니다: 빌더 객체에는 디스크립터에 대한 좋은 기본 상태가 포함되어 있습니다. 이 패턴은 변경하려는 모든 필드를 설정하기 위해 스스로 변경할 수 있는 API를 제공합니다. 준비가 완료되면 빌드 함수를 호출하여 최종 디스크립터 구조를 가져옵니다. 사용하기는 쉽지만 코드 생성, 특히 디버그 모드에서의 코드 생성은 완벽하지 않습니다. 개발 과정에서 디버그 모드를 많이 사용하므로 디버그 모드도 빠르기를 원합니다.
이 문제에 대한 해결책은 C++20 지정 구조체 이니셜라이저와 C++11 구조체 집계 초기화를 함께 사용하는 것입니다. 이 두 가지 기능을 함께 사용하면 각 구조체의 기본값을 간단하게 설정할 수 있습니다. 아래 코드 예시를 보세요. 이러한 기본값 중 하나를 재정의하려면 지정된 구조체 이니셜라이저 구문을 사용하여 명명된 필드의 값을 재정의하면 됩니다. 이 구문은 매우 깔끔하고 코드젠은 완벽합니다.
배열 데이터를 깔끔하게 해결하려면 자체 스팬 클래스를 작성해야 합니다. 이니셜라이저 리스트의 수명이 매우 짧기 때문에 C++20 내장 스팬 클래스는 이니셜라이저 리스트를 지원하지 않습니다. 이니셜라이저 리스트는 명령문 뒤에 바로 죽습니다. 일반적인 경우 스팬 안에 이니셜라이저 리스트를 넣는 것은 너무 위험했습니다. 하지만 특수한 경우에만 사용하며, 이에 대한 해결책이 있습니다: C++ 상수 && 함수 매개변수는 임시 이름 없는 객체만 허용합니다. C++는 함수 매개변수 목록의 임시 객체가 함수 호출을 완료할 때까지 충분히 오래 살도록 보장합니다. 따라서 리소스 설명자 구조체의 스팬 내에 이니셜라이저 목록을 안전하게 저장할 수 있습니다.

그리고 이것이 실제로 어떻게 보이는지입니다.
왼쪽부터 시작하겠습니다: 먼저 버텍스 버퍼와 텍스처를 생성합니다. 여기 구문은 훌륭하며 구조체 기본값과 다른 필드만 선언하고 있습니다.
왼쪽 하단을 보면 머티리얼을 선언하는 것을 볼 수 있습니다. 이것이 바인드 그룹입니다. 바인드 그룹에는 알베도, 노멀, 프로퍼티 등 다양한 텍스처 배열이 있습니다. 여기서는 이니셜라이저 목록을 사용하여 배열을 제공합니다. 이렇게 하면 구문이 매우 깔끔해집니다. 그리고 이 배열에는 힙 할당이 필요하지 않다는 점도 주목할 가치가 있습니다. 이니셜라이저 리스트와 전체 기술자 구조체는 스택에 존재합니다. 절대 복사되지 않습니다. 리소스 생성 함수 호출에서 참조를 전달하기만 하면 됩니다. 이는 원시 DX12 또는 원시 Vulkan만큼 빠릅니다.
오른쪽에는 좀 더 복잡한 리소스를 초기화하는 모습이 보입니다. 이것은 json과 비슷해 보입니다. 필드, 배열, 필드와 배열 내부에 적절한 들여쓰기를 사용하여 이름을 지정했습니다. 이는 원시 DX12 및 Vulkan에 비해 쓰기와 읽기가 훨씬 더 쉽습니다. 하지만 여전히 런타임 비용이 들지 않습니다. 메모리 할당이나 데이터 복사본도 여전히 없습니다. 모든 것이 순수한 스택 데이터입니다.

이제 리소스를 생성하고 저장하는 좋은 방법을 찾았으니 GPU 메모리를 할당해야 합니다.
저는 가능하면 임시 메모리를 사용하는 것을 선호합니다. 임시 메모리는 메모리 풀을 쪼개지 않고 할당하는 것이 카운터에 숫자를 더하는 것만큼 간단합니다.
저희는 범프 얼로케이터에 128MB 메모리 힙을 사용합니다. 힙은 링에 저장됩니다. 범프 얼로케이터가 꼬리에 도달하면 새로운 힙 블록을 할당합니다. 안정 상태에 도달하면 힙 할당이 전혀 일어나지 않습니다. 생성하는 각 GPU 힙에 대해 플랫폼별 버퍼 핸들을 생성합니다. 이 버퍼 핸들은 전체 힙을 매핑합니다. 이렇게 하면 런타임에 플랫폼별 버퍼 객체를 생성할 필요가 없습니다. 버퍼 구조체는 단순히 힙 인덱스와 오프셋을 포함합니다. 런타임에 이를 구성하고 사용자에게 전달하는 것이 매우 효율적입니다.
추가 최적화를 위해 구체적인 범프 할당자 객체를 사용자에게 제공합니다. 여기에는 N 바이트를 할당하는 함수가 있습니다. 이 함수는 호출자에게 완벽하게 인라인됩니다. 단순히 카운터를 증가시킨 다음 카운터가 힙 블록 경계를 넘었는지 여부를 테스트합니다. 이 검사는 예측 가능한 분기입니다. 블록이 부족해지면 gfx API에서 가상 함수를 호출하여 새로운 임시 할당자 블록을 가져옵니다. 이 작업은 128MB의 데이터에 대해 한 번만 발생하므로 매우 효율적입니다.
WebGPU는 아직 100% 지원되지 않기 때문에 프로젝트 중에 WebGL2 지원을 추가해야 했습니다. WebGL2에도 동일한 임시 얼로케이터 추상화를 사용합니다. 사용자 랜드 코드는 반환된 포인터가 CPU 포인터인지 GPU 포인터인지 알 필요가 없습니다. WebGL2에서는 8MB CPU 측 임시 버퍼를 사용하며 각 렌더링 패스가 시작될 때 단일 glBufferSubData를 사용하여 이러한 버퍼를 복사합니다. 이렇게 하면 데이터 업데이트 비용이 절감되고 드로우 호출마다 맵/언맵을 호출하는 것보다 성능이 크게 향상됩니다.
영구 할당은 항상 임시 할당보다 훨씬 느리기 때문에 필요할 때만 영구 할당을 수행합니다.
저는 2단계 분리 맞춤 알고리즘을 구현했습니다. 이것은 O(1) 하드 실시간 할당기입니다. 이 알고리즘은 2레벨 비트필드와 두 개의 lzcnt 명령어를 사용해 빈을 찾습니다. 빈 크기 클래스는 부동 소수점 분포를 따릅니다. 이렇게 하면 크기 클래스에 관계없이 오버헤드 비율이 항상 작아집니다. 삭제 연산은 할당과 유사합니다. 하지만 양쪽의 이웃 포인터를 확인하고 빈 메모리 영역을 병합하는 작업이 추가됩니다. 이것도 O(1)입니다.
Vulkan과 Metal 2.0(배치 힙) 모두에 동일한 얼로케이터를 사용합니다. 오프셋 얼로케이터를 오픈소스로 공개했습니다. GPU 힙이나 버퍼를 하위 할당하는 데 사용할 수 있으며, 일반적으로 연속적인 범위의 요소가 필요하고 임베디드 메타데이터를 위해 CPU 메모리 백업이 필요하지 않은 모든 요소에 사용할 수 있습니다.

저희 디자인이 다른 렌더러와 다른 가장 큰 차이점 중 하나는 사용자 랜드 바인드 그룹(벌칸 용어로 설명자 세트)입니다.
기존 방식은 각 텍스처와 버퍼에 대해 별도의 바인딩을 사용하는 것입니다. 그리기 전에 모든 바인딩을 개별적으로 설정합니다. 그래픽스 백엔드는 셰이더별 레이아웃에서 이러한 바인딩을 결합하고 각각의 바인드 그룹(WebGPU), 디스크립터 세트(Vulkan), 인수 버퍼(Metal) 또는 디스크립터 테이블(DX12)을 생성해야 합니다. 이러한 바인드 그룹 오브젝트는 GPU 오브젝트이며 생성 비용이 많이 듭니다. IHV는 중단 및 메모리 조각화 문제를 방지하기 위해 모든 GPU 객체를 미리 생성할 것을 권장합니다.
일반적인 해결 방법은 백엔드의 해시 맵에 바인드 그룹을 캐시하는 것입니다. 모든 바인딩이 해시되고 조회가 이루어집니다. 바인드 그룹이 존재하면 새로 생성되지 않고 재사용됩니다. 이 접근 방식의 문제점은 해싱 비용이 많이 들고 해시 맵 조회로 인해 메모리 액세스 패턴이 무작위화된다는 것입니다. 여러 스레드에서 렌더링하는 경우 바인드 그룹 해시를 뮤텍스로 보호해야 할 수도 있으므로 비용이 훨씬 더 많이 듭니다.
저희의 해결책은 바인드 그룹을 사용자 영역으로 직접 가져오는 것입니다: 사용자가 미리 변경 불가능한 바인드 그룹을 생성하는 것입니다. 예를 들어 머티리얼 바인드 그룹에는 5개의 텍스처와 하나의 균일 버퍼(값 데이터로 채워짐)가 포함되어 있습니다. 사용자는 머티리얼을 바인딩하는 데 사용하는 핸들을 얻습니다.
드로 콜 API는 세 개의 바인드 그룹 슬롯을 사용자 랜드에 노출합니다. 안드로이드 및 웹 GPU의 벌칸은 최소 4개의 바인드 그룹 슬롯을 요구합니다. 첫 번째 그룹 3개는 랜드 코드를 사용하기 위해 직접 노출되며, GLSL set=X 시맨틱과 일치합니다. 이는 그래픽스 프로그래머와 테크 아티스트가 쉽게 이해할 수 있습니다.
하이프하이프 상위 레벨 렌더링 코드는 바인딩 빈도에 따라 그룹을 바인딩하기 위해 데이터를 분할하는 규칙을 사용합니다. 첫 번째 그룹에는 렌더 패스 글로벌 바인딩(태양광, 카메라 매트릭스, 섀도 맵 등), 두 번째 슬롯에는 머티리얼 바인딩, 세 번째 슬롯에는 셰이더별 바인딩, 마지막 슬롯은 특수 바인딩이 있습니다.
벌칸과 웹 GPU에서는 마지막 슬롯을 동적 오프셋 바운드 버퍼에 사용합니다. 이는 균일 버퍼와 같이 범프 할당된 임시 데이터에 중요합니다. Metal API에는 인수 버퍼 버퍼 바인딩을 위한 유사한 오프셋 업데이트 API가 없습니다. 대신 Metal setBuffer API를 사용하여 이러한 동적 버퍼를 개별적으로 설정하고 setOffset API를 사용하여 오프셋을 변경합니다. 이는 모든 플랫폼 API에서 가장 효율적인 코드 경로를 사용하는 추상화를 제공합니다.
푸시 상수는 일부 모바일 GPU에서 에뮬레이션됩니다. 유니폼을 범프 할당하고 오프셋만 변경하는 것이 더 빠릅니다.

소프트웨어 명령 버퍼가 느리다고 이미 말씀드렸지만, 저희에게는 버퍼가 있습니다.)
이 소프트웨어 명령 버퍼는 대부분의 사람들이 익히 알고 있는 것과는 완전히 다릅니다. 소프트웨어 명령 버퍼에는 데이터가 없습니다. 이미 업로드된 데이터를 가리키는 메타데이터만 있습니다. 또한 메타데이터는 그룹화되어 있어 개별 바인딩이나 개별 상태보다 훨씬 작습니다. 따라서 드로우 호출을 단 64바이트의 데이터, 즉 하나의 CPU 캐시 라인으로 표현할 수 있습니다.
초기 설계는 드로 구조체 배열을 사용하는 것이었습니다. 드로 구조체에는 셰이더에 대한 핸들(모든 렌더링 상태를 포함하는 해결된 PSO 변형), 3개의 사용자 랜드 바인드 그룹, 동적 버퍼(임시 할당된 오프셋 바운드 데이터용), 인덱스 및 버텍스 버퍼, 일부 오프셋이 포함됩니다. 오프셋이 필요한 이유는 리소스를 하위 할당하면 일반적으로 성능이 크게 향상되기 때문입니다.
이 64바이트 구조체는 이미 꽤 괜찮은 수준이지만, 저는 더 개선하고 싶었습니다. 데이터를 분석한 결과 모든 필드가 32비트인 것을 발견했습니다. 최적화된 렌더링은 정렬된 순서를 사용하여 비용이 많이 드는 PSO를 최소화하고 상태 전환을 렌더링합니다. 빈 콘텐츠를 렌더링할 때 대부분의 필드가 드로우 호출 간에 변경되지 않는다는 것을 알 수 있었습니다. 평균적으로 그리기 호출 간에 변경되는 바이트는 18바이트에 불과합니다. 우리는 이 점을 활용하고자 합니다.
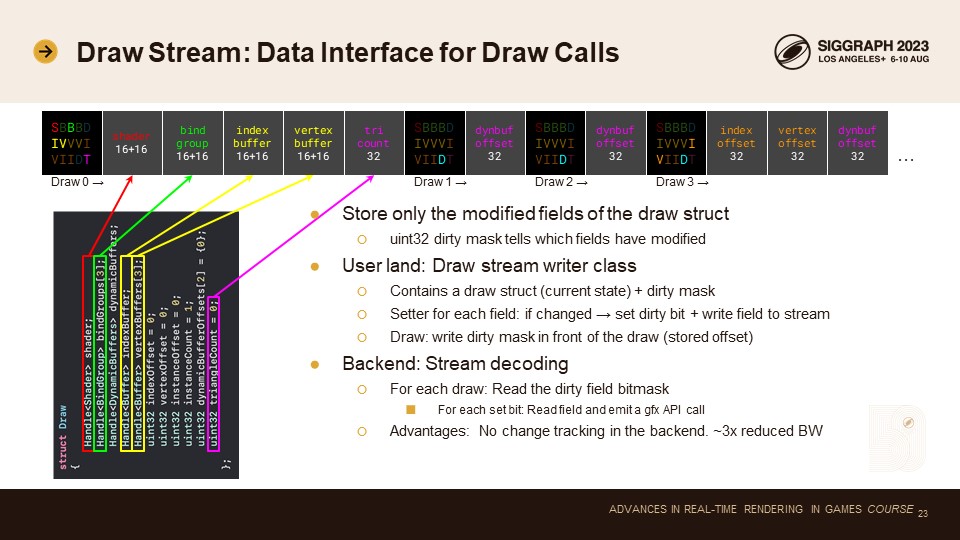
아이디어는 변경되는 필드만 저장하는 것입니다. 이것이 드로우 스트림 디자인으로 이어집니다.
각 드로우 호출 앞에 32비트 비트 마스크를 저장합니다. 이 비트 마스크는 드로우 구조체에서 어떤 필드가 변경되었는지 알려줍니다.
스트림 데이터 API 계약에 따라 데이터를 작성하는 것은 사용자 랜드 코드의 책임입니다. 이를 위해 사용자 랜드 드로우 스트림 작성자 클래스가 있습니다. 여기에는 현재 상태를 설명하는 단일 드로우 구조체와 더티 마스크가 포함되어 있습니다. 드로 스트림 작성기는 구조체의 각 필드를 설정하는 함수를 제공합니다. 이 함수는 데이터 값이 변경되었는지 여부를 확인합니다. 변경된 경우 해당 더티 비트를 설정하고 해당 필드를 스트림에 씁니다. 모든 필드를 쓴 후 사용자는 draw 함수를 호출하면 데이터 값 앞에 더티 비트 마스크를 간단히 씁니다.
백엔드는 간단합니다: 각 draw 호출마다 더티 비트마스크를 읽습니다. 그런 다음 스트림에서 각 비트에 대해 하나의 uint32를 읽고 해당 플랫폼 API 호출을 호출하여 해당 바인딩/상태/값을 설정합니다. 이 설계의 장점은 백엔드에 상태 필터링이 필요하지 않다는 것입니다. 이미 사용자 랜딩 코드에서 이 작업을 수행했습니다. 이는 보조 명령 버퍼를 사용할 수 없거나 느린 플랫폼에서 유용합니다(일부 Qualcomm GPU는 보조 명령 버퍼로 최적화를 비활성화합니다). 여러 작업자 스레드를 사용하여 드로 스트림을 생성하고 상태 필터링 비용을 오프로드할 수 있습니다. 렌더 스레드는 가능한 한 빠르며, 모바일 디바이스에서는 플랫폼 API 호출이 느리기 때문에 큰 이점이 있습니다. 또한 전체 64바이트 구조에 비해 약 3배의 대역폭을 절약할 수 있습니다.
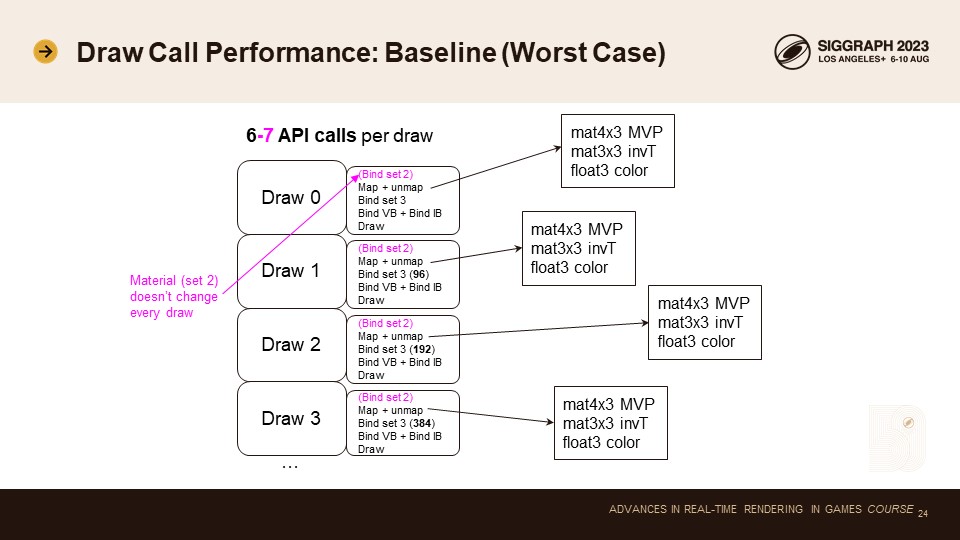
드로우 콜 성능에 대해 이야기해 보겠습니다.
이 슬라이드는 매우 전통적인 DX11 및 OpenGL 스타일의 드로우 루프를 나타냅니다. 각 드로우 호출마다 맵/맵을 호출하고 유니폼을 개별적으로 작성합니다. 또한 버텍스 버퍼와 인덱스 버퍼를 바인딩하고 텍스처와 버퍼를 바인딩합니다. 여기서는 우리가 가진 규칙에 따라 세트 2(머티리얼)와 세트 3을 바인딩하고 있습니다.
드로우 호출당 총 6~7번의 API 호출이 발생합니다. 머티리얼이 변경되지 않을 때는 6번, 그렇지 않으면 7번 호출합니다. 머티리얼별로 구분하면 그 숫자가 7보다 6에 더 가깝다고 가정할 수 있습니다.
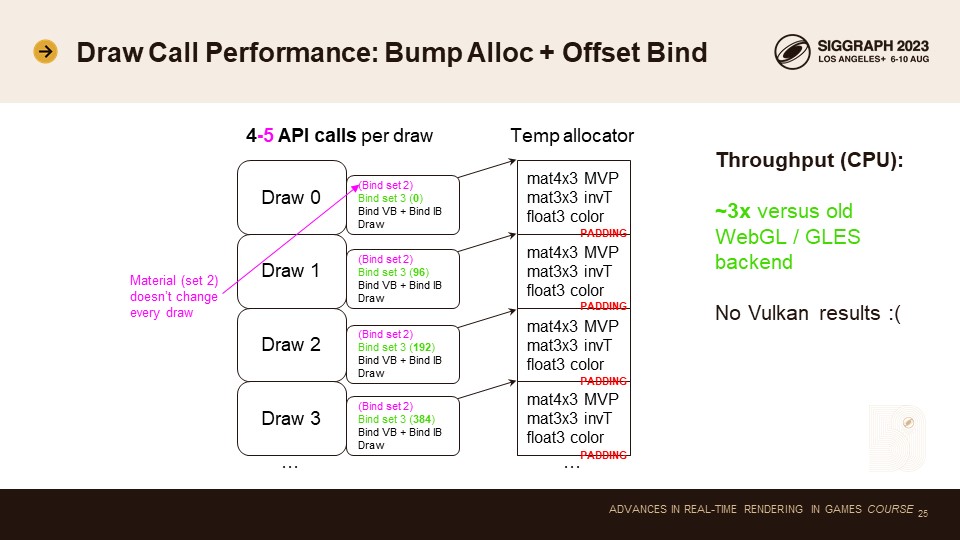
임시 할당자를 사용하여 유니폼(및 기타 동적 데이터)을 범프 할당하는 것입니다. 이제 추첨 호출마다 맵/맵 해제 호출을 할 필요가 없습니다. 이로써 API 호출 횟수가 추첨 호출당 4~5회로 줄어듭니다.
맵/맵 언맵은 의외로 비용이 많이 드는 호출입니다. 기존 GLES 백엔드는 추첨 호출당 유니폼을 업로드했습니다. 새로운 GLES3 백엔드(WebGL2)의 가장 큰 차이점은 드로우당 맵/언맵이 없다는 점이며, 이 변경만으로도 약 3배의 CPU 성능 향상을 얻을 수 있었습니다.
새로운 벌칸 백엔드에는 드로우당 매핑/매핑 해제 기능을 구현하지 않았기 때문에(벌칸은 퍼시스턴트 매핑을 지원함) 아쉽게도 벌칸 수치를 보여드리지 못했습니다.
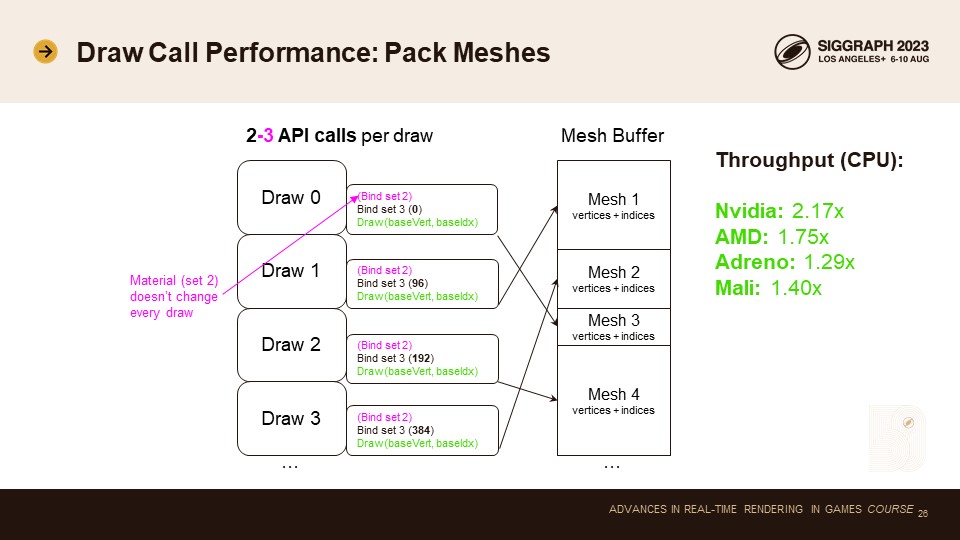
다음으로 큰 영향을 미친 최적화는 메시 패킹이었습니다. 128MB의 큰 힙 블록을 할당하고 각각에 대해 하나의 플랫폼 버퍼 핸들을 사용합니다. 이렇게 하면 메시를 쉽게 하위 할당하고 각 드로우 호출에서 기본 버텍스와 기본 인덱스를 변경하여 메시를 변경할 수 있습니다.
이렇게 하면 버텍스 버퍼 설정과 인덱스 버퍼 설정이라는 두 가지 API 호출을 제거할 수 있습니다. 드로우 당 API 호출이 2~3회로 줄어들어 매우 좋습니다!
이 최적화를 통해 모든 디바이스에서 CPU 처리량이 향상되었습니다. 데스크톱 GPU에서 가장 큰 향상(2배 가까이)을 보였지만, 모바일 GPU에서도 눈에 띄는 향상(30~40%)을 보였습니다.
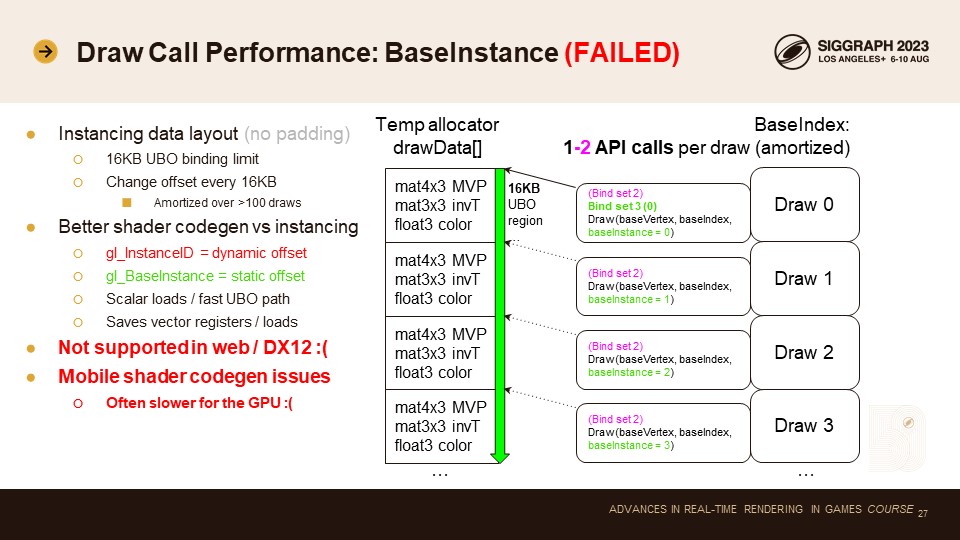
마지막으로 논의하고 싶은 최적화는 기본 인스턴스입니다.
베이스 인스턴스 드로잉은 인스턴스 사용과 동일한 데이터 레이아웃을 사용합니다. 조밀하게 패킹된 드로잉 데이터 배열을 사용합니다. 모바일 유니폼 버퍼에는 16KB 바인딩 크기 제한이 있습니다. 바인딩 오프셋을 16KB당 한 번씩 변경하여 임시 할당자 버퍼를 다른 오프셋으로 재바인딩하는 데 드는 비용을 상각하는 것입니다. 이렇게 하면 API 호출 횟수가 1로 줄어들고 이제 그리기 자체와 가능한 머티리얼 바인드 그룹 변경만으로 최적의 API 호출 수를 확보할 수 있습니다. 드로우 호출에는 기본 인스턴스 파라미터가 있는데, 이를 유니폼 버퍼 데이터 배열의 다른 슬롯을 가리키도록 변경합니다.
그렇다면 인스턴싱을 사용하지 않는 이유는 무엇일까요? 베이스 인스턴스를 사용하면 많은 플랫폼에서 더 나은 셰이더 코드 생성 결과를 얻을 수 있습니다. 그 이유는 인스턴스 ID가 동적 오프셋이기 때문입니다. GPU는 동일한 버텍스 웨이브에 여러 인스턴스를 패킹하므로 인스턴스 ID로 인덱싱된 모든 데이터는 벡터 레지스터와 벡터 로드를 사용해야 합니다. 이는 4x4 행렬 등을 로드하는 데 많은 추가 레지스터 부풀림을 유발합니다. 반면에 베이스 인스턴스는 드로우당 정적 오프셋입니다. 모든 레인은 동일한 위치에서 로드됩니다. 이는 컴파일러가 스칼라 코드 경로를 확장하거나 빠른 상수 버퍼 하드웨어를 사용할 수 있음을 의미합니다.
하지만 실제로는 다양한 문제에 직면하게 됩니다. 기본 인스턴스 코드 생성은 PC에서는 완벽하지만, 모바일 GPU에서는 여러 가지 문제가 발생합니다. 일부 드라이버는 이를 제대로 최적화하지 못합니다. 또한 이 기능은 지원 범위가 좁습니다. DX12는 베이스 인스턴스를 전혀 지원하지 않으며 WebGL과 WebGPU도 지원하지 않습니다. 따라서 데스크톱에서만 출시하는 경우가 아니라면 이 최적화를 권장하지 않습니다. 모바일에서는 그만한 가치가 없습니다.

성능 수치를 살펴봅시다.
단일 렌더 스레드를 사용하고 있습니다. 인스턴싱 트릭 없이 1만 번의 실제 드로우 콜을 수행했습니다. 각 드로 콜은 고유한 메시와 고유한 머티리얼을 사용합니다. 바인드 그룹과 패킹된 메시를 사용하면 머티리얼과 메시를 빠르게 변경할 수 있습니다.
하이프하이프에서는 아직 GPU 퍼시스턴트 씬 데이터를 구현할 시간이 없었습니다. 이 수치는 이전 슬라이드에서 설명한 대로 드로 범프별로 할당된 유니폼을 사용한 것입니다.
저희는 15년 전 Xbox 360에서 60fps로 10,000회의 드로우 콜을 목표로 하고 있습니다. 그리고 그 결과는 인상적이었습니다. 이 스트레스 테스트에서는 99달러짜리 저가형 Android 휴대폰도 60fps에 근접했습니다. 실제 키트 기반 UGC 게임 씬에서는 반복되는 메시와 머티리얼이 많기 때문에 일괄 처리와 gfx API 호출 횟수 감소가 가능합니다. 또한 렌더링을 멀티스레드화할 계획입니다.
AMD의 최신 통합 GPU(Steam Deck 및 ROG Ally 핸드헬드에도 탑재)에서 저희 렌더러는 1밀리초 이내에 10,000개의 드로우를 푸시할 수 있습니다. 멀티스레딩을 사용할 경우, 최신 AMD 및 Nvidia GPU에서 렌더러는 60fps로 최대 1백만 개의 드로우 호출을 푸시할 수 있습니다.


'TECH.ART.FLOW.IO' 카테고리의 다른 글
| [번역][역자각주]Nubis3: Methods (and madness) to model and render immersive real-time (0) | 2023.09.12 |
|---|---|
| [번역]Large-Scale Terrain Rendering in Call of Duty (0) | 2023.09.11 |
| [번역][해설]What do we want from a Diffuse BRDF? (0) | 2023.09.10 |
| [소개]SIGGRAPH 2023 Advances in Real-time Rendering in Games course.[번역] (0) | 2023.09.08 |
| 건강한 씨앗 발굴을 위한 인사. (1) | 2023.09.06 |